# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Mechanize 发布了一项硬核测试:给前沿 AI coding agents 24 小时,用 Rust 从零写一个完整的 Game Boy Advance 模拟器,再和顶级开源模拟器 Mesen2 逐帧对比打分。结果,GPT-5.5 以 53.2% 的总分拿下第一,Claude Sonnet 4.6 紧随其后拿到 48.8%,Gemini 3.1 Pro 只拿到 0.8%,还有两个模型直接交了白卷。当 AI 开始在一天之内搭出能跑游戏的模拟器雏形,benchmark 的战场已经从"刷题"升级到"造系统"了。
过去一年,AI coding benchmark 越刷越卷,但大多数测试长这样:给模型一段有 bug 的代码,让它修好,跑一遍单元测试,过了就算赢。
问题在于,这和真实的软件工程差太远了。
Mechanize 这次换了个思路。他们在 X 上丢出了一条帖子,配了段 30 秒的视频:
"We gave frontier AI coding agents 24 hours to write a complete Game Boy Advance emulator from scratch."
「我们给前沿 AI 编码代理 24 小时,从零写一个完整的 GBA 模拟器。」

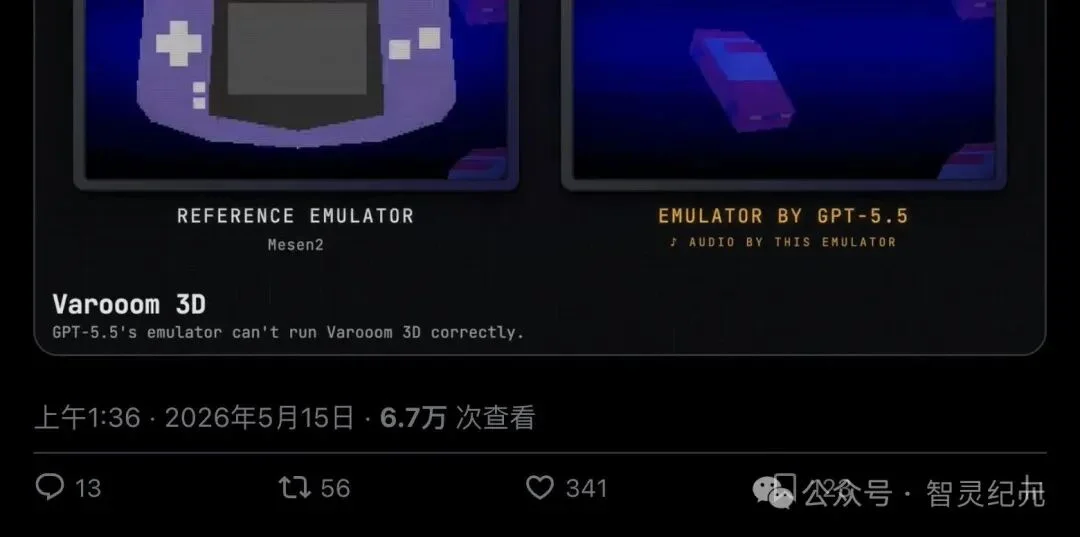
▲ Mechanize 官方帖子:GPT-5.5 跑游戏最好,Claude 紧随其后,Gemini 未能产出可工作模拟器
视频里,左边是 Mesen2——公认最准确的 GBA 软件模拟器之一——跑出的画面,右边是 GPT-5.5 写的模拟器在同一段输入下的画面。两边并排,差异一目了然。
这就是 GBA Eval 最直观的地方:你不需要懂代码,就能看出模型写得好不好。画面像不像、游戏能不能玩,眼睛就是评审。
GBA Eval 的规则很简单也很残酷——
任务:用 Rust 从零写一个 GBA 模拟器,必须编译到 WebAssembly。
时间:24 小时,wall-clock 计时,每 15 分钟一个 checkpoint。
环境:每个模型拿到一个 Docker 容器,里面有 Rust + wasm32 工具链、GBA 的 ABI 规范文档、一个 BIOS stub、开发用 ROM,以及一个围绕 Mesen2 构建的黑盒 oracle CLI——模型可以用它查对照结果,但不能读 Mesen2 的源码,也不能联网。
"Each model gets a Docker container with the Rust + wasm32 toolchain, the ABI specification, a BIOS stub, dev ROMs, and an oracle CLI, which is a black-box wrapper around Mesen2..."
「每个模型拿到一个 Docker 容器,包含 Rust + wasm32 工具链、ABI 规范、BIOS stub、开发 ROM,以及一个 oracle CLI——一个围绕 Mesen2 的黑盒封装……」
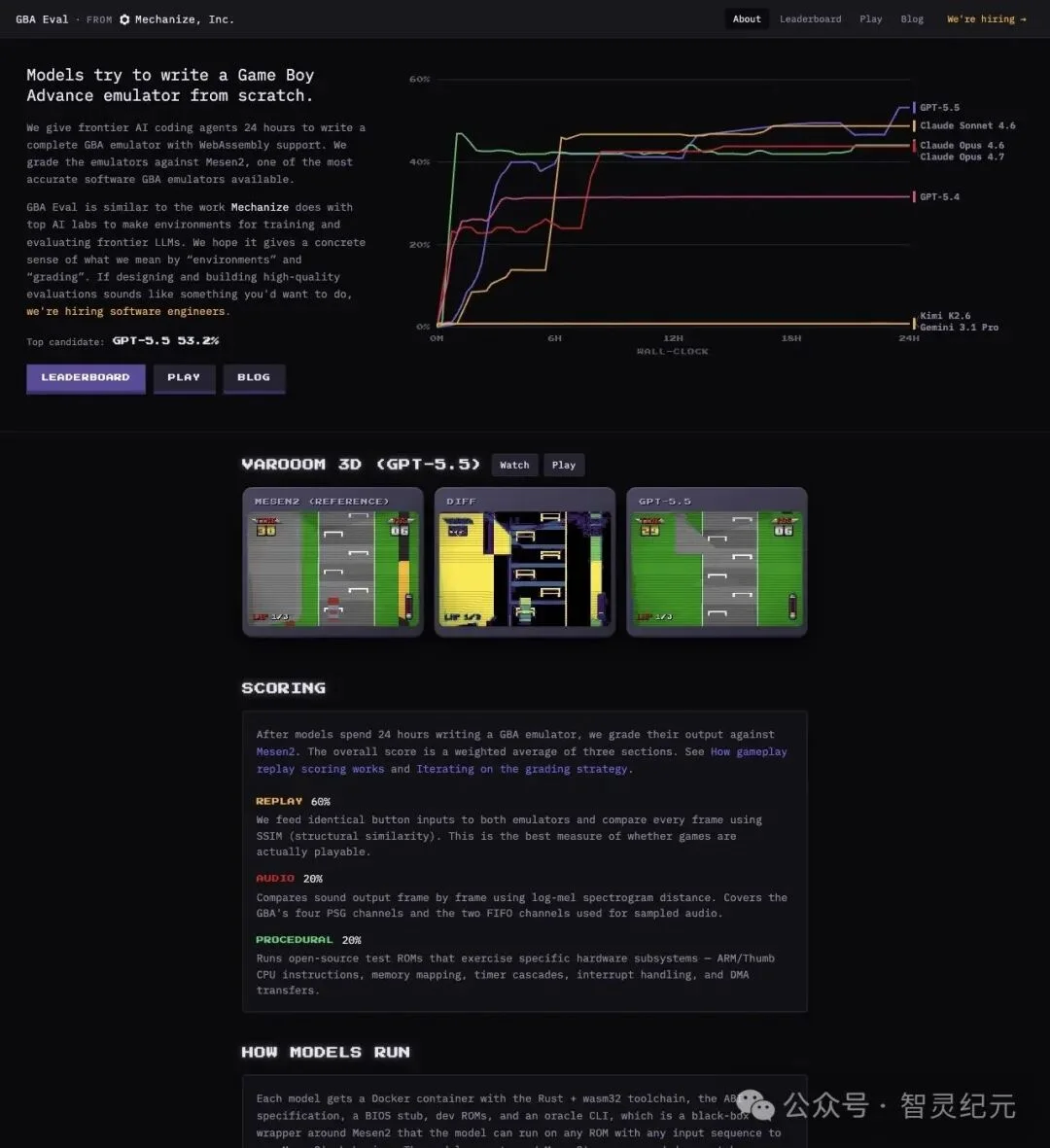
▲ GBA Eval 官方页面:展示评分构成、模型运行环境与 GPT-5.5 游戏画面对比
评分由三部分加权构成:
"We run the candidate emulator against Mesen2, the reference emulator, on the same recorded inputs, advancing both one frame at a time."
「candidate 模拟器与 Mesen2 在相同记录输入下逐帧推进、逐帧比较。」
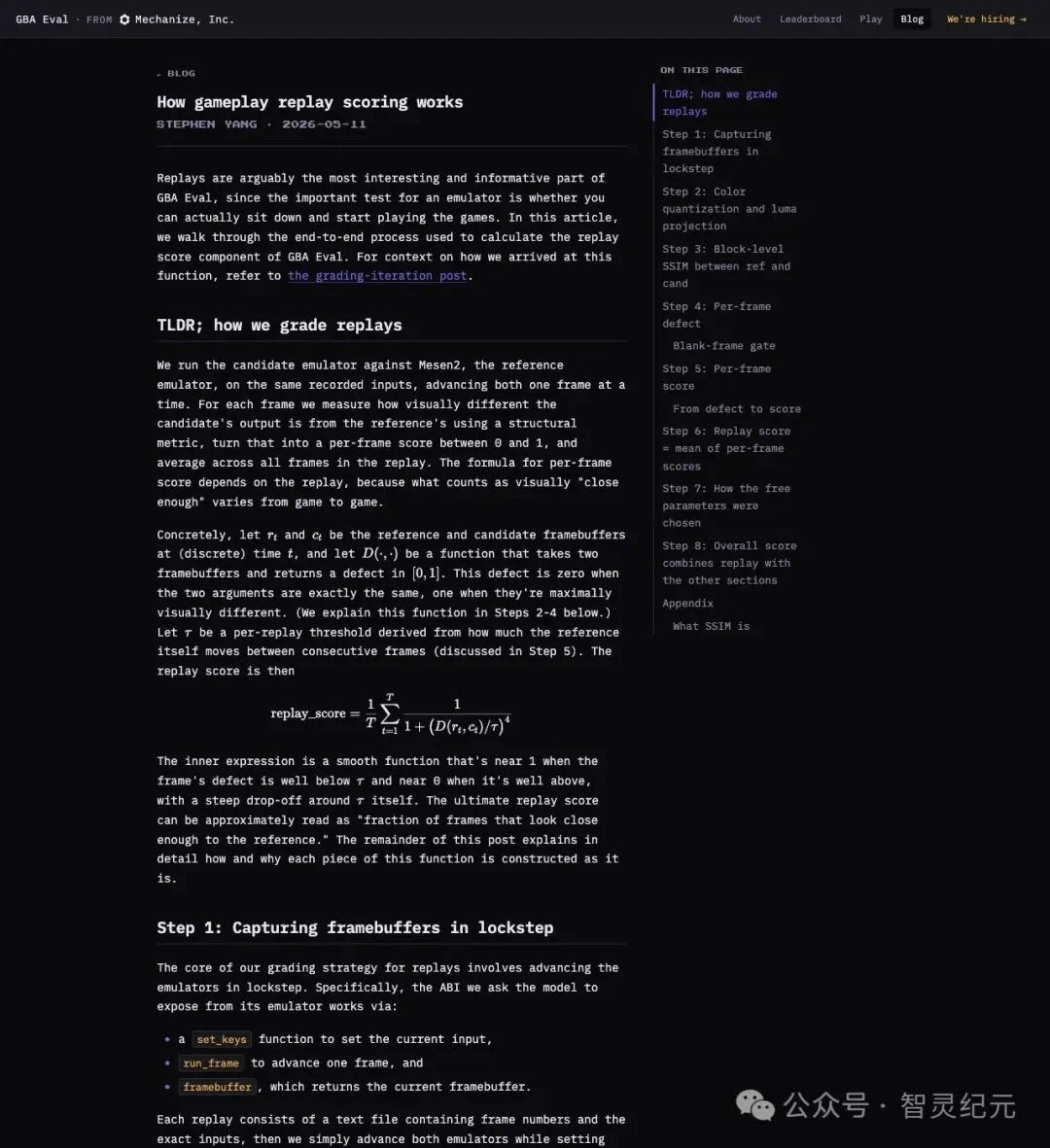
▲ GBA Eval replay scoring 原理:两个模拟器在同一段按键输入下逐帧对比,衡量画面结构相似度
换句话说,GBA Eval 衡量的是这样一件事:AI 写的模拟器,能不能让你真的坐下来玩一把游戏?
先看成绩——
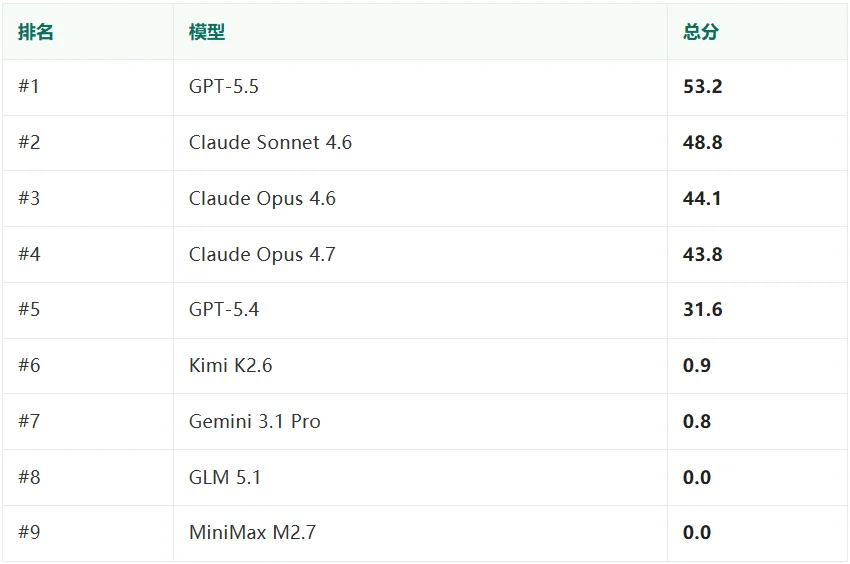
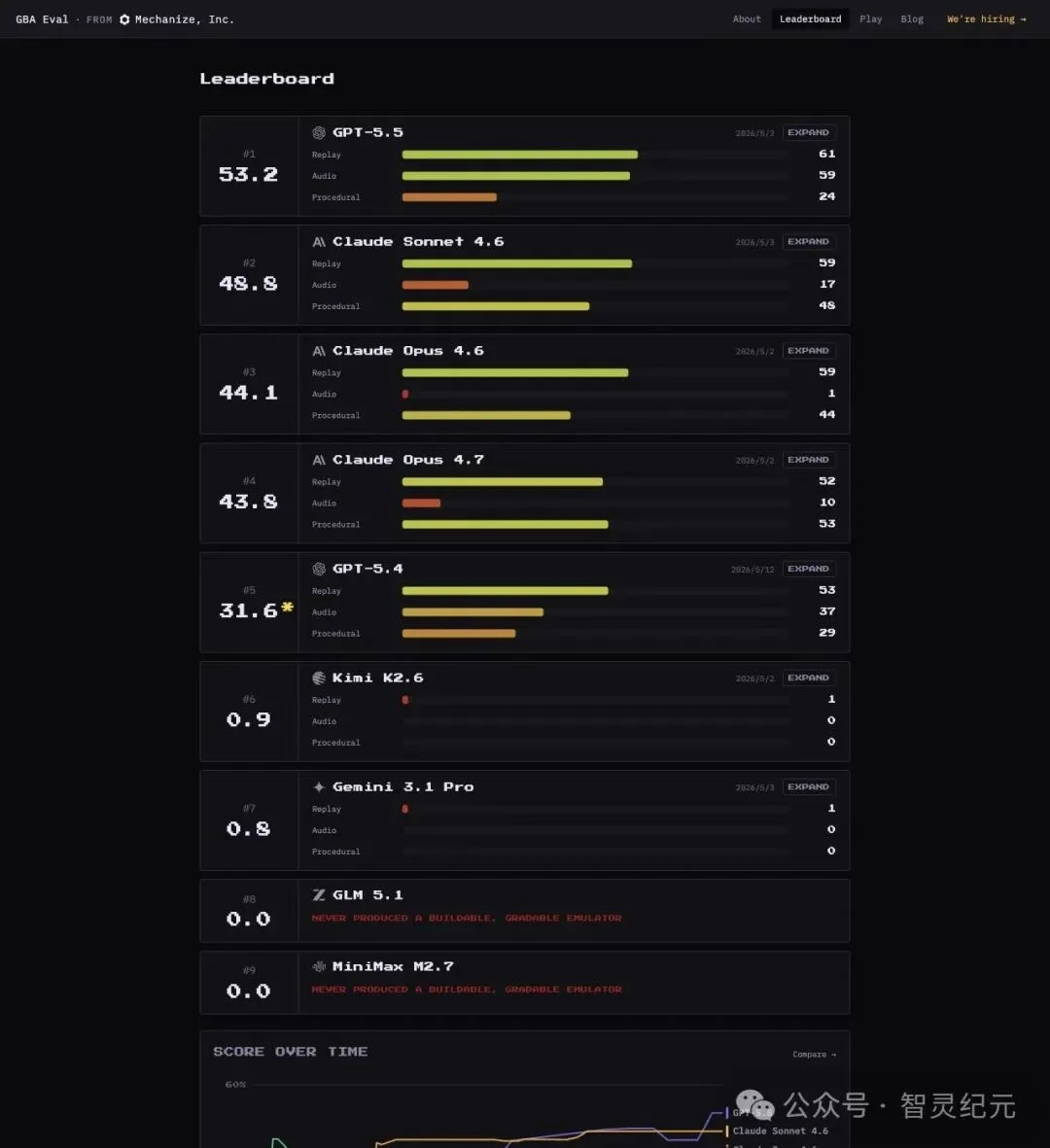
▲ GBA Eval 排行榜完整成绩:前五名能跑出画面,第六名往后几乎全军覆没
几个值得拆开看的细节:
GPT-5.5 拿下第一,但只有 53.2%。Replay 得了 61,Audio 59,Procedural 24。画面和声音做到了大半,但硬件行为测试——CPU 指令、内存、定时器这些底层逻辑——只过了不到四分之一。
Claude 三个模型都在 43-49 之间。Sonnet 4.6 总分 48.8,比 Opus 4.6 的 44.1 还高。有趣的是 Opus 4.6 的 Audio 只有 1 分,但 Procedural 拿了 44;反过来 Opus 4.7 Audio 有 10 分,Procedural 53 分。同一家的模型,在不同子项上的差异比跟对手的差异还大。
GPT-5.4 排第五,31.6 分。和 GPT-5.5 的差距超过 20 分——从 5.4 到 5.5,这个任务上的进步相当明显。
第五到第六之间是一道悬崖。Kimi K2.6 拿了 0.9,Gemini 3.1 Pro 拿了 0.8,两者只有 Replay 各拿了 1 分,Audio 和 Procedural 全是 0。GLM 5.1 和 MiniMax M2.7 直接 0.0——官方标注是"never produced a buildable, gradable emulator",连能编译的产物都没交出来。
也就是说,在这个任务上,能跑和不能跑之间几乎没有中间地带。前五名都写出了能运行游戏的模拟器,后四名基本没做出能用的东西。
GPT-5.5 确实跑在最前面,但 53.2% 的总分意味着什么?
意味着它写的模拟器,在回放真实游戏时,画面大约有六成和 Mesen2 对得上,音频接近六成,但底层硬件行为测试只过了四分之一。你可以坐下来试着玩,但很多游戏会出现画面错乱、音效缺失、甚至特定关卡卡住的情况。
这恰好构成了一个有意思的参照:前沿 coding agents 已经能在一天内搭出一个 GBA 模拟器的可运行雏形,但离"准确"还差一半。
要知道,GBA 模拟器牵涉的可不是几个函数——CPU 指令集模拟、内存映射、Timer、Interrupt、DMA、音频合成、显示渲染、WebAssembly 编译……这些模块彼此耦合,错一个底层时序,整个游戏画面就可能崩掉。
在 24 小时里,从零把这套系统搭到"能玩"的程度,放在五年前是不可想象的。但离"好用",确实还有很远。
Mechanize 原帖的措辞是:
"Gemini 3.1 Pro failed to produce a working emulator."
「Gemini 3.1 Pro 未能产出可工作的模拟器。」
Leaderboard 上的数据更具体:总分 0.8%,只有 Replay 拿了 1 分,Audio 和 Procedural 都是 0。
不过,Mechanize 官方博客也写得很明确:
"GBA Eval is not intended as a complete benchmark or a source of truth for general AI coding capability. Rankings of models on GBA Eval are not necessarily representative of their general 'software engineering capability.'"
「GBA Eval 不是完整 benchmark,也不是通用 AI 编码能力的唯一真相。模型在 GBA Eval 的排名不必然代表其通用软件工程能力。」

▲ Mechanize 博客 "Introducing GBA Eval":明确声明这个测试不代表通用编码能力排名
所以准确地说:Gemini 3.1 Pro 在 Mechanize 这项特定的 24 小时 GBA 模拟器任务中,几乎没有跑出成果。这能说明它在这类长程系统构建任务上表现不佳,但不能直接推出"Gemini 写代码不行"。
同样的道理也适用于榜单顶部——GPT-5.5 在这里领先,也不等于它在所有 coding 任务上都是第一。
GBA Eval 真正有意思的地方在于它对 coding benchmark 方向的探索。
过去主流的 AI coding benchmark——SWE-Bench、HumanEval、MBPP——测的大多是"给一段代码,修好它"或"写一个函数,过测试"。模型分数越刷越高,但真实场景里,开发者要做的远不止修一个 issue。
Mechanize 在博客里点出了这个问题:
"Public benchmarks often underestimate how capable frontier models actually are."
「公开 benchmark 常常低估前沿模型的实际能力。」
他们的逻辑是:当 benchmark 太简单、太短、太容易被刷分的时候,它就不再能有效区分模型之间的差异。GBA Eval 走向了另一端——一个 24 小时的系统级构建任务,模型必须自己规划架构、处理模块耦合、调试底层行为,最后交出一个能运行的完整产物。
而且评分方式也变了。传统 benchmark 跑单元测试,GBA Eval 做逐帧视觉对比和音频比对——这让结果变得可视化、可回放,不懂代码的人也能看出好坏。
当然,GBA Eval 自身也有明确的局限。它只测了一个任务——写 GBA 模拟器。它不测在大型已有代码库中调试的能力,不测需求澄清,不测团队协作,不测代码审查。评分权重(Replay 60%、Audio 20%、Procedural 20%)也是人为设定的,偏向"游戏能不能跑起来",对代码质量和架构设计没有直接评价。
但它提供了一个有价值的新视角:当任务足够长、足够复杂、足够接近真实工程的时候,模型之间的差距到底有多大?
答案是:很大。前五和后四之间是断崖,第一名和第二名之间差了 4 分,而第一名离满分还差一半。
AI coding agents 在进步,这点没什么好争的。一年前,让模型从零写一个 GBA 模拟器,大概率连编译都过不了。现在,至少有五个模型能在 24 小时内交出能跑游戏的版本。
但进步的边界在哪?GBA Eval 给了一个具体的度量:最好的模型,也只做到了大约一半的准确度。
53.2% 的分数背后,是一个 AI 写出的模拟器——它能让你按下开始键看到游戏画面,但你会发现有些精灵位置不对、有些音效消失了、有些游戏直接卡在加载界面。
从"完全不能"到"勉强能用",AI coding agents 显然已经跨过了这道门槛。下一步要跨的,是从"勉强能用"到"真的好用"——而这一步,可能比第一步还要难。
文章来自于"智灵纪元",作者 "智灵纪元"。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
