# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
从超级个体到超级岗位。

笔者最近一个月遇到了四位准备转型的朋友——前端、解决方案架构师、产品经理、传统算法工程师,背景、年龄、城市都不一样,却问了同一个英文缩写:FDE[2]是不是值得我去?
FDE,全称 Forward Deployed Engineer[2]。它在两年前还是 Palantir 圈子里的一个工种黑话,今天已经悄悄变成猎头的开场白、招聘启事的高频岗位、以及社交媒体上“AI 时代最值钱岗位”的候选答案之一。OpenAI 在 2026 年 5 月直接以这个名字成立了 Deployment Company[3],初始投资 40 亿美元,明确说要派工程师钻进客户的现场办公,进入客户的工作流里;Anthropic 的 Applied AI 团队也在四个时区同步招聘 FDE。这件事从圈内黑话变成显性词汇,只用了一年多一点。
笔者上一篇文章《致超级个体》[4]讨论的是“人的发动机”——好奇心、自学、自驱、动手能力,如何在完整的 Closed-loop 里被激发出来。但人不是悬浮的,人要被一个具体的岗位坐标系接住。如果说超级个体是 AI 时代生产关系的“原料”,那 FDE 就是市场在这一年里长出的、最显性的一种“岗位形态”。
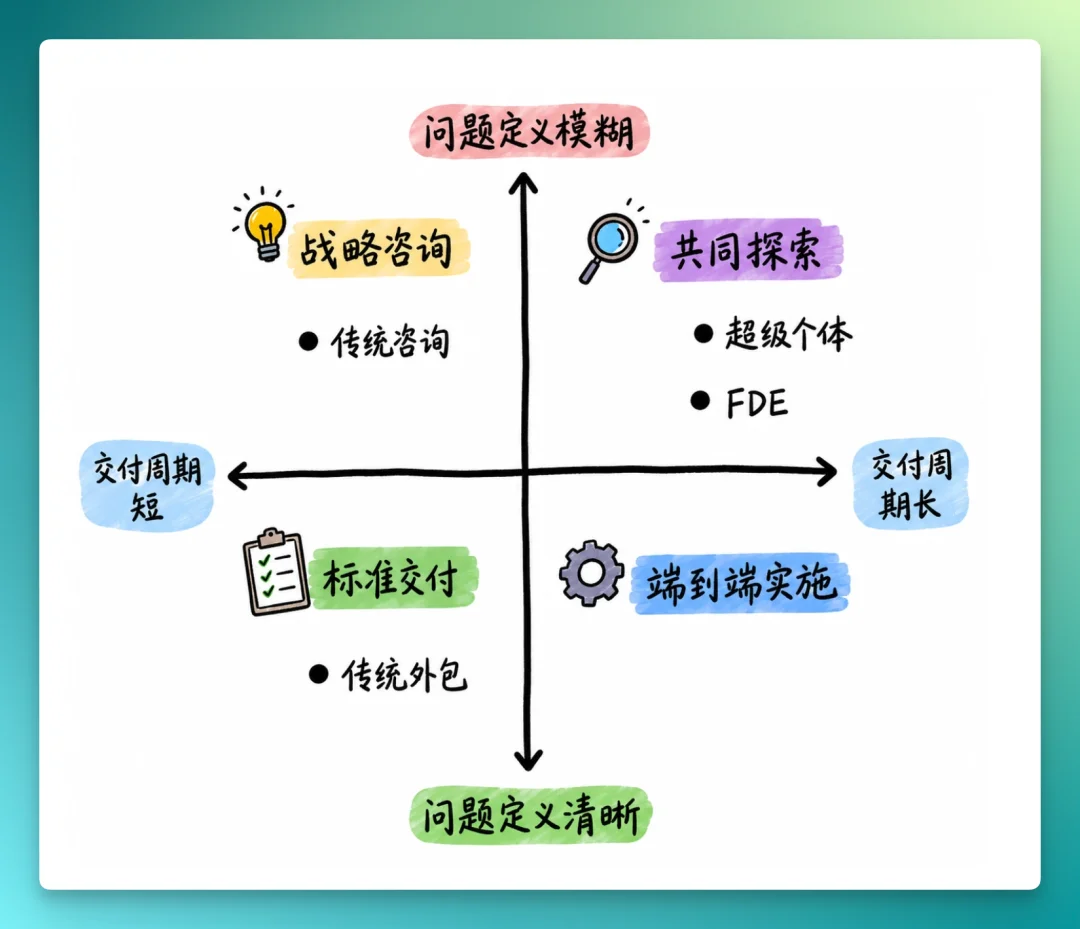
在笔者看来FDE 不在咨询那一格,也不在外包那一格。它和超级个体最近——区别只在于,FDE 是在“模型公司 × 客户”的夹缝里被组织化的超级个体。
你知道吗——Forward Deployed 这个词从哪儿来?
它原本是美军术语 Forward Deployed Forces,指部署在海外或前线、能就近响应的部队,对照的是留在本土基地的后方部队。Palantir 在 2000 年代末把这个词搬进软件行业,用来描述“派工程师离开总部、住到客户现场”的工作模式,连内部团队都按军用音标命名,叫 Delta 和 Echo。这次它被 OpenAI 和 Anthropic 重新接管,不是巧合——派工程师上前线,这件事的本质从来没变过。
本文要回答的,是笔者最近被那四位朋友问到的三个具体疑惑:
- FDE 是不是穿了 AI 外衣的咨询公司?它和传统咨询的边界在哪?
- FDE 是不是高级一点的软件外包?它和我现在做的乙方有什么区别?
- 我适不适合做 FDE?哪一类人会被这个岗位放大,哪一类会被磨碎?
笔者的态度是审慎乐观:FDE 是真的在长出来,但它远不是所有人的转型出口。把它讲清楚,比把它讲热闹更重要。
从 OpenAI 的 Deployment 团队说起
如果只能用一件事来标记 FDE 这一轮重新出圈的时间点,笔者会选 2026 年 5 月 11 日——那天 OpenAI 宣布成立 Deployment Company[5],COO Brad Lightcap 离开原来的商务条线、转任 special projects 直接向 Sam Altman 汇报,全职负责这件事。同一周,OpenAI 收购了英国 AI 咨询公司 Tomoro,一次性把 150 名 Forward Deployed Engineer 和 Deployment Specialist 装进了新公司。
值得一提的是,OpenAI 的招聘页面同时在挂出十几个 FDE 岗位:旧金山、纽约、华盛顿,外加按行业切的 Life Sciences、Semiconductor、Gov 等垂直方向,连 FDE 招聘官[6]这个岗位本身都在招。分析师估算这个团队在三年内会扩张到 2000–4000 人。这不是一个研究小组的规模,这是一支正规军。
Anthropic 这边几乎是镜像动作。Applied AI 团队下面的 Forward Deployed Engineer 岗位[7] 同时在波士顿、纽约、西雅图、旧金山、华盛顿、伦敦六地放出,要求 25%–50% 的客户现场出差。一个最近被反复引用的例子是金融科技公司 FIS——它在公告里直接写“Anthropic 的 Applied AI 团队和 forward-deployed engineers 已经嵌入到 FIS,共同设计 Financial Crimes AI Agent,并把知识转移给 FIS,让它后续能独立扩展更多 agent”。
这段话里藏着 FDE 这份工作的真实样子。它不是售前架构师,不是 SDR,也不是来给客户做培训的布道师(Evangelist)。它是带着模型、住到客户代码库里的工程师。Brad Lightcap 自己说得更直白:“我们的客户告诉我们,他们需要的是从 pilot 走到 production 的能力。Deployment Company 就是把我们的工程师塞进他们的团队,给足资源去交付。”
把这件事画成一张图,三方关系会变得非常清楚:
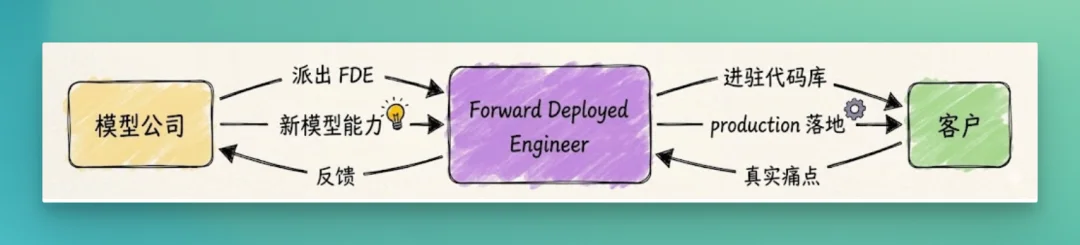
注意这张图里最有信息量的两条线,是 FDE 往两边输送的反馈。往客户方向,FDE 不是把模型当 SaaS 卖,而是把客户的数据、权限、合规、内部系统拧成一根能跑模型的管道;往模型公司方向,FDE 把客户的真实痛点和失败样本带回 product 和 research,影响 roadmap——一个反复出错的 tool calling pattern,可能就变成 SDK 的下一个内置抽象。
这就是为什么 FDE 在这一轮被两家头部模型公司同时重新启用,背后不是“我们也要学 Palantir 做咨询”那么简单。它是模型公司的一种信号采集装置——前线最稠密的客户痛点,必须有自己人在场才能抓到,靠合作伙伴翻译过来的需求总是隔了一层。Anthropic 走的是混合路径:一边自营 FDE,一边和咨询公司、PE 巨头建合资部署网络。一个偏自营、一个偏 ecosystem,但内核都一样:模型公司不再只是 API 供应商,它要直接派工程师进客户产品里。
接下来要回答的,是两个最常见的对照问题——FDE 和传统咨询(麦肯锡、埃森哲那一类)的边界在哪?它和我们熟悉的软件外包,又是不是一回事?
FDE 不是麦肯锡:模型边界 vs 流程边界
很多人第一次听 FDE 的工作描述,第一反应是:“这不就是新版麦肯锡、埃森哲吗?”
笔者理解这种联想。穿西装、出差客户现场、坐在客户会议室里画白板、和 C 级高管对齐——从画面上看,FDE 和咨询顾问确实长得像。但只要往里走一层,两者的工作肌理就完全不同。咨询卖的是流程边界,FDE 卖的是模型边界。
把这两者并排放在一张表里,差异立刻显现。

这张表里最值得停一下的,是“资产折旧”这一行。
传统咨询最赚钱的逻辑是资产复用——一份给某家银行的方案,下一家稍微改改再卖一次;一份零售行业的数字化 playbook 可以反复套到三十家客户身上。这是过去三十年 Accenture、Deloitte、McKinsey Digital 一路做大的底层经济模型。
FDE 没有这种资产。模型能力还在快速移动——今天还需要精心设计的 Prompt 链路,下一版模型可能一句话就能搞定。咨询的“方法论沉淀”在这个速度面前会快速贬值。所以 FDE 不能用资产复用模式,必须每次跑闭环都重新跑一遍——重新评估模型边界、重新选工具栈、重新拼产品形态。看似低效,其实是唯一能跟上模型速度的方式。
你知道吗——Product Overhang 是什么?
笔者在上一篇《致超级个体》[4]里解释过这个词:模型能力已经超过现有产品形态,但没有产品入口、权限和上下文把它兑现出来。FDE 这个岗位的价值,本质上就是把客户场景里悬空的 Overhang 兑现成一个具体能跑的产品。客户买的不是模型 API 的调用配额,而是“有人能把这堆 Overhang 真正落地在我业务里”的能力。
这也解释了“项目结构”一行的差异。咨询项目的标准结构是 SOW(Statement of Work)+ WBS(Work Breakdown Structure)+ 阶段验收:合同里写清楚要交付什么、什么时候交付、按什么标准验收。这套结构的前提是目标在签合同前就已经定义清楚。
FDE 的项目走不通这一套。客户最常说的一句话是:“我知道 AI 应该能帮我做点什么,但我不知道是什么。”目标本身就是项目的一部分。所以 FDE 不接 SOW,接 mission——一个相对模糊的方向;然后用 iteration 一轮一轮把方向变清楚;最后在某一轮里,把已经积累的模型理解兑现成一个产品形态。
“交付物”这一行也值得展开。FDE 走人之后,留在客户系统里的是一个能跑的功能——可能很小、可能丑陋、可能没什么用户界面,但它每天真的在被人调用、被人改、被人骂。咨询的交付物是 PPT 和变革管理报告,哪怕项目里写过代码、配过 ERP,最后留在客户高管手里的仍然是一份方法论文档。
“护城河”一行是最微妙的。FDE 的护城河是对模型能力边界的实时手感——你这个月跑了多少个真实客户场景,你就比别人更知道哪些事 Claude 4.7 能做、哪些事必须等 Claude 5。这种手感不能写进 PPT,也不能放进知识库,它只能长在最近 90 天动过手的工程师脑子里。
所以下次有人说“FDE 不就是新版埃森哲”,可以这样回答:埃森哲的工程师是去重新设计客户的流程,FDE 是去重新探明模型的边界。前者的资产能沉淀十年,后者的资产 90 天后就要重新长一次。
FDE 不是软件外包:共同探索 vs 需求实现
如果说“FDE 是新版埃森哲”是第一层误读,那“FDE 是贵价软件外包”就是第二层。这一层更具误导性,因为表面证据看起来非常足:FDE 真的会去客户现场写代码,真的会按客户业务定制功能,真的会被客户调用工作时间。乍一看,和外包工程师没区别。
但只要看一眼反馈回路这件事,差别就藏不住了。
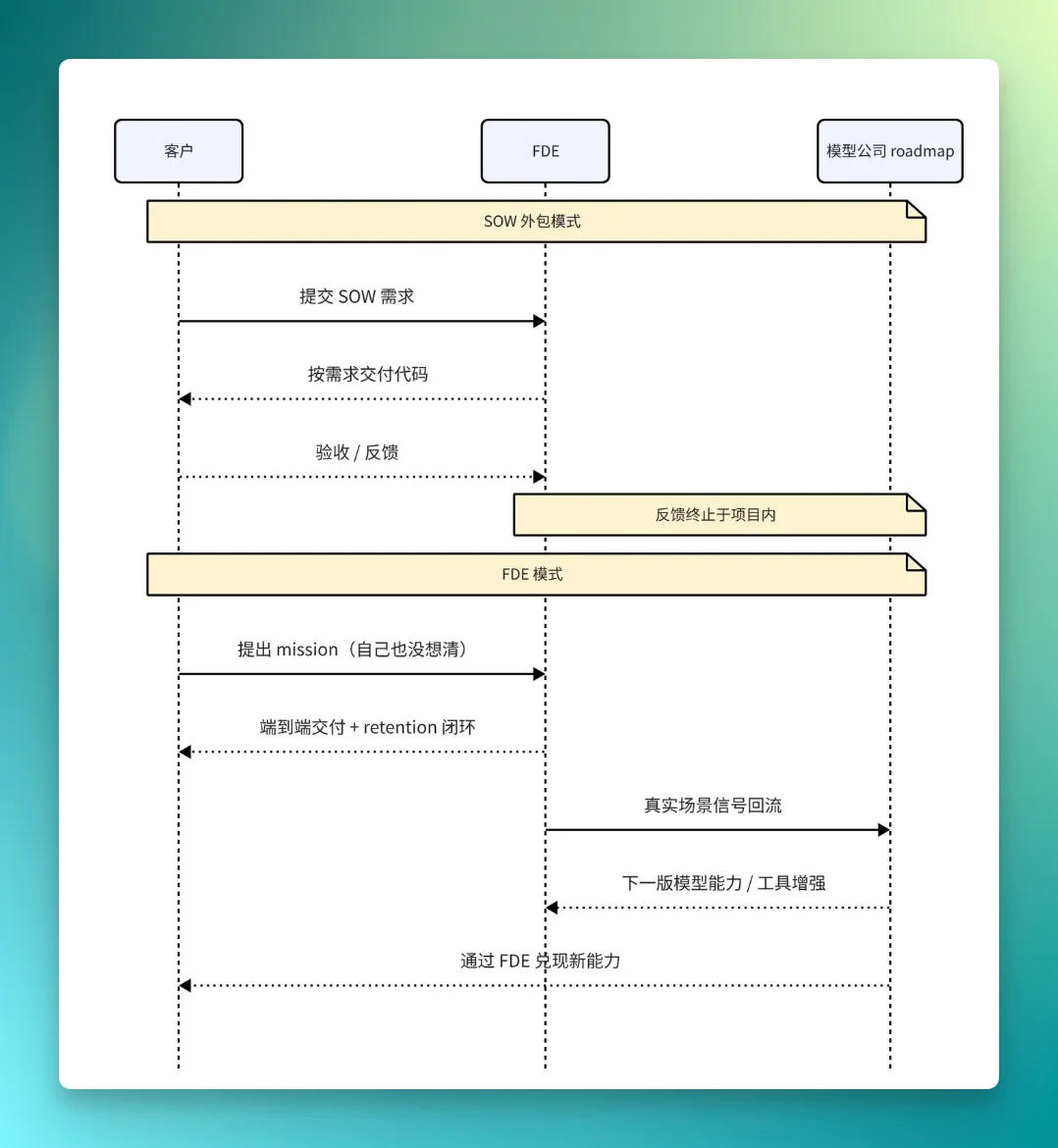
这张图里最关键的差别,不是图上半部分有多简单,而是图下半部分多了一条向模型公司延伸的反馈链。这条链不是装饰,它是 FDE 这个岗位存在的真正理由。把这层差异拆开来看,至少有四组对比。
接的东西不一样。外包接 SOW——一份在签合同前就已经定义清楚的需求清单:要做哪些功能、用什么技术栈、按什么标准验收、违约怎么赔。FDE 接的是 mission——客户自己也没想清楚要什么,只知道“AI 应该能帮我做点什么”。SOW 的前提是确定性,mission 的前提是探索。两者完全不同的项目启动姿态。
做的范围不一样。外包做的是局部交付——一个模块、一个网站、一个数据 pipeline,做完打包走人,下一家。FDE 做的是端到端——从业务痛点开始,到模型选型、到产品形态设计、到上线后真实用户的 retention 和 churn。
计费方式不一样。这一点最反直觉。一家模型公司派 FDE 进客户场,最终关心的不只是这次项目收多少咨询费,更是:这个客户接下来会消耗多少 token?会不会成为 retention 客户?会不会扩展到更多业务线?FDE 的真正 KPI,是模型 token 的长期消耗曲线,不是项目验收单上的那个数字。
反馈的去向不一样。这是四组里最深的一组。外包项目里,甲方的反馈最远只走到外包公司,不会影响外包公司未来卖给别人的产品。FDE 的反馈则回流到模型公司的 roadmap——客户在真实场景里遇到的每一个坑、每一个 Prompt 失败、每一个工具调用 bug,都会变成下一版训练数据、下一版工具设计、下一版产品功能的输入。也就是说,每个 FDE 部署的客户,对模型公司而言同时也是一个天然的 design partner。
这才是模型公司愿意付高薪招 FDE 的真正原因。他们不只是在卖一个服务,他们在客户场地里收集真实世界的产品形态信号。这些信号买不到、抓不到、问卷调研不出来——它只能由一个具体的工程师,在一个具体的客户工作流里,亲手撞过几次墙之后带回来。
你知道吗——OpenAI 和 Anthropic 的 FDE 总包能到多少?
根据 Levels.fyi 上 Anthropic 软件工程师的公开数据[8],资深 SDE 总包中位数已经到 \$710K。FDE 这个岗位 risk 更高——既要面对模型能力的不确定、又要面对客户业务的不确定、还要承担产品形态的不确定,所以 行业整理[9] 中提到,前沿 AI 实验室 FDE 中高级别的总包基本落在 350K - 550K,Staff 级以上能冲到 \$630K+。这个价钱不是在为“外包工时”付费,而是在为“产品 + 客户 + 模型”三个 risk 的合成承担者付费。 > 回想 2006 年,笔者刚参加工作,就职于某央企,当时正在进行信息化转型,那个时代我们集团邀请的埃森哲顾问驻场,集团需要支付给埃森哲每天 3500 元的咨询费,一呆就是几年,被当年的媒体称为“金领”。笔者后来跳入德国 SAP 公司,SAP 更是定义了一个咨询行业的名字,SAP 咨询顾问更是“金领”的象征。这么看来,FDE 的薪水至少在 24 - 36 个月内是持续上涨的,需求量也是稳定上升的。
外包是劳动力套利,FDE 是前线感知器。混淆这两件事,会让甲方误以为可以用 SOW 的方式把 FDE 招进来,也会让候选人用外包的工作姿态对待 FDE。两边都会很快撞墙。
国外 FDE 的两条根:Palantir 与新一代模型公司
很多人误以为 FDE 这个词是 OpenAI 发明的。其实不是。它有两条历史根脉,一条来自 Palantir,一条来自 2023 之后的新一代模型公司。把这两条根并排看,能更清楚地理解 FDE 这个岗位真正在做什么。
先看一张时间线。
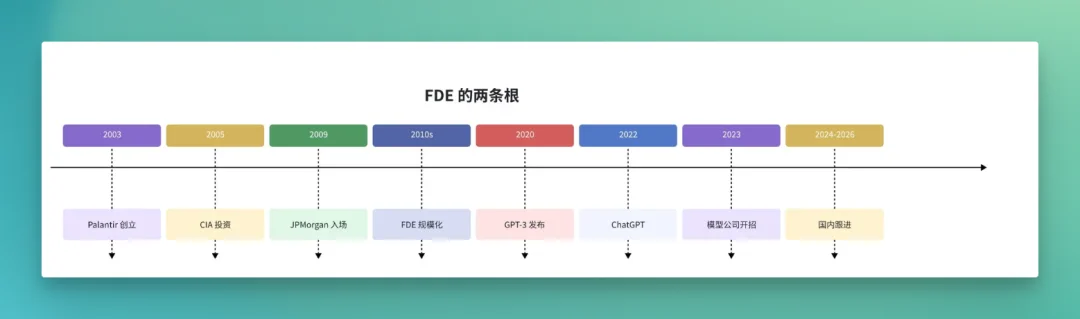
第一条根是 Palantir。
Palantir 2003 年由 Peter Thiel、Alex Karp、Joe Lonsdale 等人创立,最早的客户是美国情报机构。Karp 本人没有 CS 背景——他在法兰克福跟随哲学家 Jürgen Habermas 念博士,回到美国后才被 Thiel 拉进来做 CEO。FDE 这个岗位,恰恰是从 Karp 这种“非典型 CEO + 高度涉密客户”的组合里被逼出来的:36Kr 的回顾[10] 里写得很直白,Palantir 早期被情报机构骂得很惨,理由是工程师拿不到真实业务场景,需求层层转译之后已经走样。后来 Palantir 谈下来一件事——让自家工程师直接进客户场地,和情报分析师一起办公。这套模式后来被 Shyam Sankar 系统化,就成了 FDE 的雏形。
到 2009 年,FDE 扩展到商业领域。JPMorgan 部署 Palantir 的 Metropolis 平台时,120 名 FDE 进驻做内部威胁监控。从这时候起,FDE 就不再只是“派工程师出差”,而是一种成体系的客户嵌入打法:把 Foundry / Gotham 真正跑进客户业务流,而不是丢个 license 就走。
Palantir 的 FDE 招聘有一条反直觉标准——不要求 CS 学历。这件事可以放进“你知道吗”。
你知道吗——Palantir FDE 不要求 CS 学历?
根据 SkillScouter 整理的 Palantir 招聘标准[11] 和 Palantir 官方 careers 页面[12],Palantir 明确欢迎非 CS 专业的候选人,近期 FDE 录用者来自机械工程、经济学、哲学等专业。它真正卡的两件事是:
能在不完整信息里行动,以及能直接和 C 级客户对话。
CS 学位是加分项,不是入场券。Karp 本人就是这条标准最早的样本——一个学哲学的 CEO,带出一帮学物理、学数学、学哲学的 FDE。
第二条根是 2023 年之后的新一代模型公司。
ChatGPT 2022 年底发布之后,OpenAI 很快意识到一件事:把模型 API 挂在文档上让客户自己接,根本接不动。客户不是不想用,是不知道怎么用——他们有业务问题,但没有产品形态。于是 OpenAI、Anthropic、Cohere、Scale、Glean、Sierra、Hebbia、Decagon 这一波公司,开始大规模招 FDE。
这一波 FDE 学的就是 Palantir 的 playbook——把工程师派到客户场地,端到端把一个工作流跑通。但产品载体已经完全不同:Palantir 时代的 FDE 干的是数据集成和 UI 定制,新一代 FDE 干的是 Prompt 设计、Agent 编排、工具调用、工作流嵌入。
Pragmatic Engineer 关于 FDE 的专文[13] 里把这种新版本叫做“embedded with enterprises to make Claude solve real, specific, high-value problems”——表述上和 Palantir 当年几乎一致,只是把“数据”换成了“模型”。
把这两条根放在一起看,能看到一组很清晰的共同点和差异。
共同点:客户买的不是软件。客户买的是“能解决我问题的工程师 + 工具组合”。这件事在过去三十年的企业软件历史里其实是反常的。SAP、Oracle、Salesforce 卖的都是软件本身——工程师是为了“让客户用得起这个软件”存在的辅助资源。Palantir 反过来:工具是为了“让 FDE 在客户那里能解决问题”而存在的杠杆。新一代模型公司继承了这种倒置关系——OpenAI 卖的不是 GPT-4 license,是“我们 FDE 能用 GPT-4 帮你把客服自动化跑通”。
差异:Palantir 时代偏 OPS 集成——重头戏在数据集成、本体建模、权限治理。新一代偏模型能力落地——重头戏在 Prompt 设计、Agent 编排、retention 优化。前者像系统集成商的进阶版,后者像产品工程师的延伸版。
最后还有一个有趣的事实:Palantir 早期 FDE,后来很多成了创业者,或者直接加入了新一代模型公司。Anthropic、OpenAI、Sierra、Hebbia 的早期团队里,能数出一长串 ex-Palantir 名字。这不是巧合——FDE 这个岗位本身就逼着一个人同时承担产品 risk、客户 risk、工程 risk,几乎就是创业者的训练课。笔者更愿意把 Palantir 看成隐形创业训练营:它培养出的不只是工程师,而是一群知道怎么在不完整信息里推动一件事从零到一的人。两条根,最后在 2023 之后合流。
国内 FDE:从解决方案架构师到 AI 落地工程师
两条根的合流主要发生在国外。在国内,FDE 这个词出现的时间不长,但它对应的工作内容并不是凭空冒出来的。理解国内 FDE,得先看清它的两个本土前身,再看清它和美国版 FDE 的三个水土差异。
两个本土前身
第一个前身是云厂商的解决方案架构师。阿里云、腾讯云、华为云在过去十年里养出了一整套 Solution Architect(SA)队伍,对着客户讲架构、写 POC、做迁移方案、配合交付到上线。华为内部还有专门的“交付工程师”序列负责把项目落到客户机房。这套体系已经在做 FDE 工作的 80%,但重心仍然在售前和部署——端到端的产品迭代责任不在 SA 手上,需求改了要走变更流程,模型换了要等总部排期。
第二个前身是 AI 创业公司里新长出来的序列。MiniMax 在 BOSS 直聘上挂“AI 售前解决方案专家”,月之暗面、智谱、通义、混元等模型公司也都在挂类似岗位。名字略有差异,但 JD 内容高度趋同:理解客户场景、做 demo、调 Prompt、跑 RAG、写交付方案、跟客户工程团队对接到上线。这一拨岗位才是真正意义上的“国内 FDE”。
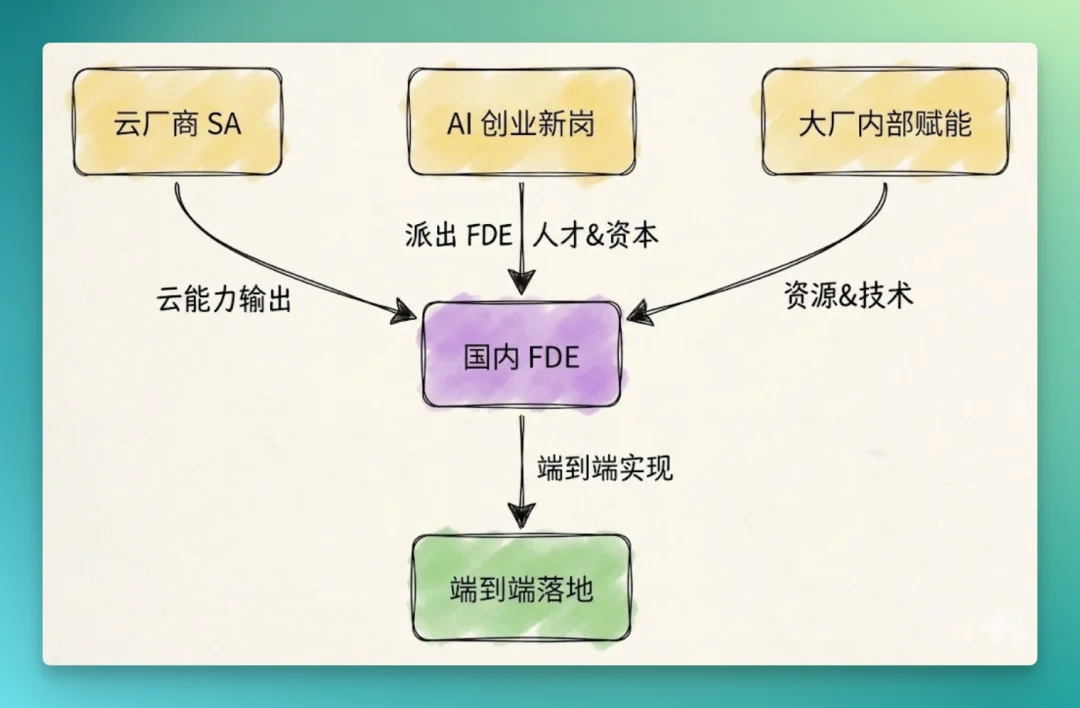
三个水土差异
私有化部署 + 数据合规压死纯模型调用模式。国内 B 端客户对数据不出域、模型权重可控、审计可追溯的要求远高于美国市场。一个 FDE 项目里,纯调 API 跑 Prompt 的工作量可能只占三成,剩下七成是把模型搬到客户机房、跑通鉴权、对接数据中台、做合规备案。
模型能力还在追赶 SOTA,发挥空间被压缩到工程层。美国 OpenAI、Anthropic 可以拿模型能力本身打动客户;国内通义、豆包、Kimi、GLM、DeepSeek 的能力差异化没那么大,客户的判断点更多落在 Agent 编排、RAG 检索质量、工具集成、Workflow 设计这些工程能力上。国内 FDE 拼的不是“我家模型多强”,而是“我能不能把这个业务真的跑通”。
B 端付费意愿和定价节奏与美国不一致。Palantir 那种“先派 FDE 进驻、再收高单价订阅”的模式很难直接复制。国内客户预算跟着年度采购走,付费往项目制偏,FDE 的商业模型经常是订阅 + 私有化授权 + 项目交付的混合形态。
一个独特定位:内部 FDE
很多大厂内部的 AI 团队,开始用 FDE 模式服务“内部客户”。阿里云 PAI 派工程师进驻淘宝,腾讯混元也有类似机制对接微信、广告业务侧。JD 上挂的是“行业落地工程师”“AI 应用工程师”“智能化业务专家”,本质上就是内部 FDE——把模型团队的能力端到端跑到业务侧。这给大厂 leader 一个新思路:几个内部 FDE 蹲点在业务侧、把第一个 demo 跑出来、把 ROI 数据交到业务老板手里,部门墙会比开十次对齐会消解得更快。
谁适合做 FDE,谁不适合
笔者在上一篇 《致超级个体》[4] 里讲过超级个体的五个发动机:好奇心强、探索和创新精神强、自学能力强、自驱力强、动手能力强。这五件事是 FDE 的入场券,但不是全部。FDE 这种岗位在五个发动机之外,还有一组非常具体的额外特质,也有几类人格画像明确不适合。笔者见过太多优秀工程师转 FDE 之后水土不服,问题大多不在能力,而在性格和工作偏好。
适合 FDE 的五个特质
不抗拒销售和沟通。FDE 的工作日常不是关起门写代码,而是和客户的 CTO、业务负责人、采购、合规、IT 直接打交道。一个典型节奏:客户 CTO 在 demo 中途打断你,FDE 的反应不能是“我回去改一版下周再来”,而是当场打开 IDE 改 Prompt 重跑给他看。“客户在场,我在改”是 FDE 的常态。
享受模糊地带。FDE 拿到的不是清晰的 PRD,而是一句“我们想用 AI 做点什么”。客户自己也说不清楚要什么,需要 FDE 陪他把这种模糊期望长成具体形态。如果你只在有清晰需求时才能动起来,FDE 每天都会让你焦虑。
工程力扎实但不要求 10x。FDE 不需要你是公司里代码最干净、算法最深的那个人,它需要的是端到端能跑通:前端能糊一个能点的页面,后端能搭一个能跑的服务,模型能接上业务数据源。在 FDE 的世界里,“差不多就行”不是缺点,是美德。
喜欢被反馈打磨。FDE 的工作里有大量“被客户骂回去重来”的时刻:今天的 demo 明天被业务方说“这不是我要的”;上周对齐过的方案,这周客户换了一个高管又要重做。适合 FDE 的人会把这种反馈当燃料,能承担端到端责任,不甩锅给“需求方没说清楚”。
对模型边界敏感。这是最技术性也最隐性的一条。FDE 要能判断什么任务让 LLM 做合适、什么不行、应该怎么 fallback——这种敏感度看论文看不出来,只能被失败 case 砸出来。失败样本累积下来,FDE 才会长出对模型边界的肌肉记忆:什么场景要用 RAG,什么场景要走规则,什么场景必须给人类一个 fallback 入口。
不适合 FDE 的四类人
想躲在代码里的纯技术控。FDE 大约 50% 的时间不在写代码——在客户会议、内部协调、产品讨论、合同推进上。如果你的快乐来源是连续四小时无人打扰地写代码,FDE 会让你长期处于精神耗竭状态。
需要 OKR 才能动起来的人。FDE 的目标长在客户那,不长在你的绩效表里。工作进度由客户的项目节点、模型的能力变化、自己对场景的判断共同决定。习惯“先有 OKR 才知道要做什么”的人会找不到锚点。
把“晋升”看得比“作品”重的人。FDE 在大厂晋升体系里不占便宜——客户满意度、项目签单、复用率这些指标,跟代码量、上线频次比起来在职级评审里说不响。如果你的工作动机里晋升排第一,FDE 不是好选择。
抗拒商业语境的人。FDE 必须理解客户的 P&L、ROI、采购流程、合规要求。如果你天然反感谈钱、谈合同、谈商业逻辑,FDE 的工作会让你觉得自己在出卖技术理想。
Self-Check 清单
7 个问题,每个对应 FDE 的一种真实工作场景。答 5 个以上“是”可以认真考虑 FDE,答 3 个以下建议慎重。
1. 你愿意把每天 50% 的时间从代码挪到客户会议、回消息和电话上吗?
2. 客户告诉你“这个不行,我也说不清为什么”的时候,你的第一反应是好奇心,还是不耐烦?
3. 没有人给你写 PRD,你能不能在一周内和 Claude Code 一起跑通一个能给客户看的原型?
4. 同一个交付,客户让你改了 8 个版本,你还能保持判断力,而不是机械执行?
5. 当模型给出错误答案,你的第一反应是设计 fallback,还是抱怨模型不行?
6. 你愿意签合同、写汇报、跑客户验收、跟法务对合规条款吗?
7. 你能接受快速原型和快速失败吗?
五个特质、四类反向画像、七道自测题,最终是同一个问题:你愿不愿意让自己的产品感、工程力和商业判断三件事,在同一个工作流里被同时打磨。
结语:从超级个体到超级岗位
笔者在上一篇文章里讨论的是“人的发动机”:好奇心、探索精神、自学能力、自驱力、动手能力,怎么在大厂内部被完整闭环激发出来。这一篇讨论的是另一件事——岗位形态。FDE 是 AI 工业革命里第一个有名字、有薪资带、有招聘 JD、有客户付费验证的新岗位形态。它不是“超级个体”概念的同义词,而是这一波重构里第一个从虚到实落地的坐标。
FDE 不是终点。笔者的判断是,FDE 只是新分工里第一个长出名字的形态。后面还会有 Forward Deployed PM、Forward Deployed Designer、Forward Deployed Researcher——所有跟客户场景紧密耦合、需要在模糊地带把产品长出来的工种,都会冒出自己的“前置部署”版本。岗位名字会变,但底层逻辑是一样的:模型能力跑在前面,产品形态在后面追,岗位结构跟着工作流重新切分。
给三类读者各留一句话。
给技术人:FDE 不要求你是公司里代码最强的那个人,但它要求你愿意把一半时间从代码挪到客户那边。如果你的回答是“愿意”,市场窗口刚开,国内头部模型公司、云厂商和大厂内部 AI 团队的招聘都在加速。如果回答是“不愿意”,那也没什么问题,新分工里还会长出别的位置给你。
给 HR 和 OD:警惕“名实分离”。你公司可能已经有一批 FDE 在跑了,只是岗位编码上挂着“解决方案专家”“行业架构师”“AI 应用工程师”。识别他们、重新分类、给他们一条对得上工作内容的成长通道,比从零招新人更高效。
给管理者:FDE 模式不只能对外,也能对内。在公司内部设几个“内部 FDE”蹲点在业务侧,把模型团队的能力端到端跑到业务流程里,可能比新建一个 AI 部门、再开十次跨团队对齐会要高效得多。部门墙不是被组织设计消解的,是被一个能跑通的 demo 消解的。
AI 时代的职业转型已经打响,FDE 是第一发信号弹,它告诉我们:模型能力变化的速度,已经快到逼出新岗位的程度。笔者想留给读者一个具体的问题——如果三年后你的公司组织架构图上多了三个新岗位,你猜会是哪三个?想清楚这个问题,比读完这篇文章本身更有用。
参考资料
[1]Henry(DeerFlow 团队):https://xhslink.com/m/AyUHaIeXWic
[2]FDE:https://www.linkedin.com/jobs/view/%E8%B1%86%E5%8C%85ai%E5%A4%A7%E6%A8%A1%E5%9E%8Bfde%EF%BC%88forward-deployed-engineer%EF%BC%89-%E7%81%AB%E5%B1%B1%E6%96%B9%E8%88%9Fmaas-at-bytedance-4330374800/
[3]Deployment Company:https://www.primeai.solutions/blog/openai-deployment-company-forward-deployed-engineers-uk
[4]《致超级个体》:https://my.feishu.cn/wiki/AfvNwnZiEirKPSkmUz7cfDlYnM1
[5]Deployment Company:https://finance.biggo.com/news/202605141021_OpenAI-Launches-$4-Billion-Deployment-Company
[6]**FDE 招聘官**:https://openai.com/careers/recruiter-forward-deployed-engineering-remote-us/
[7]Forward Deployed Engineer 岗位:https://job-boards.greenhouse.io/anthropic/jobs/4985877008
[8]Levels.fyi 上 Anthropic 软件工程师的公开数据:https://www.levels.fyi/companies/anthropic/salaries/software-engineer
[9]行业整理:https://hashnode.com/blog/a-complete-2026-guide-to-the-forward-deployed-engineer
[10]36Kr 的回顾:https://eu.36kr.com/en/p/3568217567575174
[11]SkillScouter 整理的 Palantir 招聘标准:https://skillscouter.com/how-to-become-a-forward-deployed-engineer/
[12]Palantir 官方 careers 页面:https://www.palantir.com/careers/students-and-early-talent/
[13]Pragmatic Engineer 关于 FDE 的专文:https://newsletter.pragmaticengineer.com/p/forward-deployed-engineers
文章来自于微信公众号 “十字路口Crossing”,作者 “十字路口Crossing”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
