# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

天下武功,唯快不破。
本周 Google I/O 大会上,谷歌发布了最新模型 Gemini 3.5 Flash。

Google I/O 大会发布 Gemini 3.5 Flash|图片来源:youtube
有趣的是,隔一天国内 Qwen3.7-Max 也发布了,并且两个模型都号称自己在 Agent 场景上做了深度优化。
我看到他们的第一反应是:又是新一轮「模型大战」,国内外厂商再次开启跑分竞赛。
但这次我花了两天时间实测之后,我发现Gemini 3.5 Flash 给我最大的感受不是它有多聪明,而是它的速度快到让我不得不重新想一个问题:
当模型的响应速度从「能用」变成「实时」,整个 Agent 的使用体验会发生什么质变?
Gemini 3.5 Flash 的定位很有意思:
Google 把它放在了 Flash 系列,但在 MCP Atlas 这个 Agent 基准测试上拿了 83.6% 的 SOTA 水平,甚至超过了 GPT-5.5 的 75.3% 和 Claude Opus 4.7 的 79.1%。
代码能力在 Terminal-Bench 2.1 上得分 76.2%,超过了自家上一代旗舰 Gemini 3.1 Pro 的 70.3%。
这意味着一个 Flash 定位的模型,在干活能力上已经逼近甚至超过了许多旗舰产品。
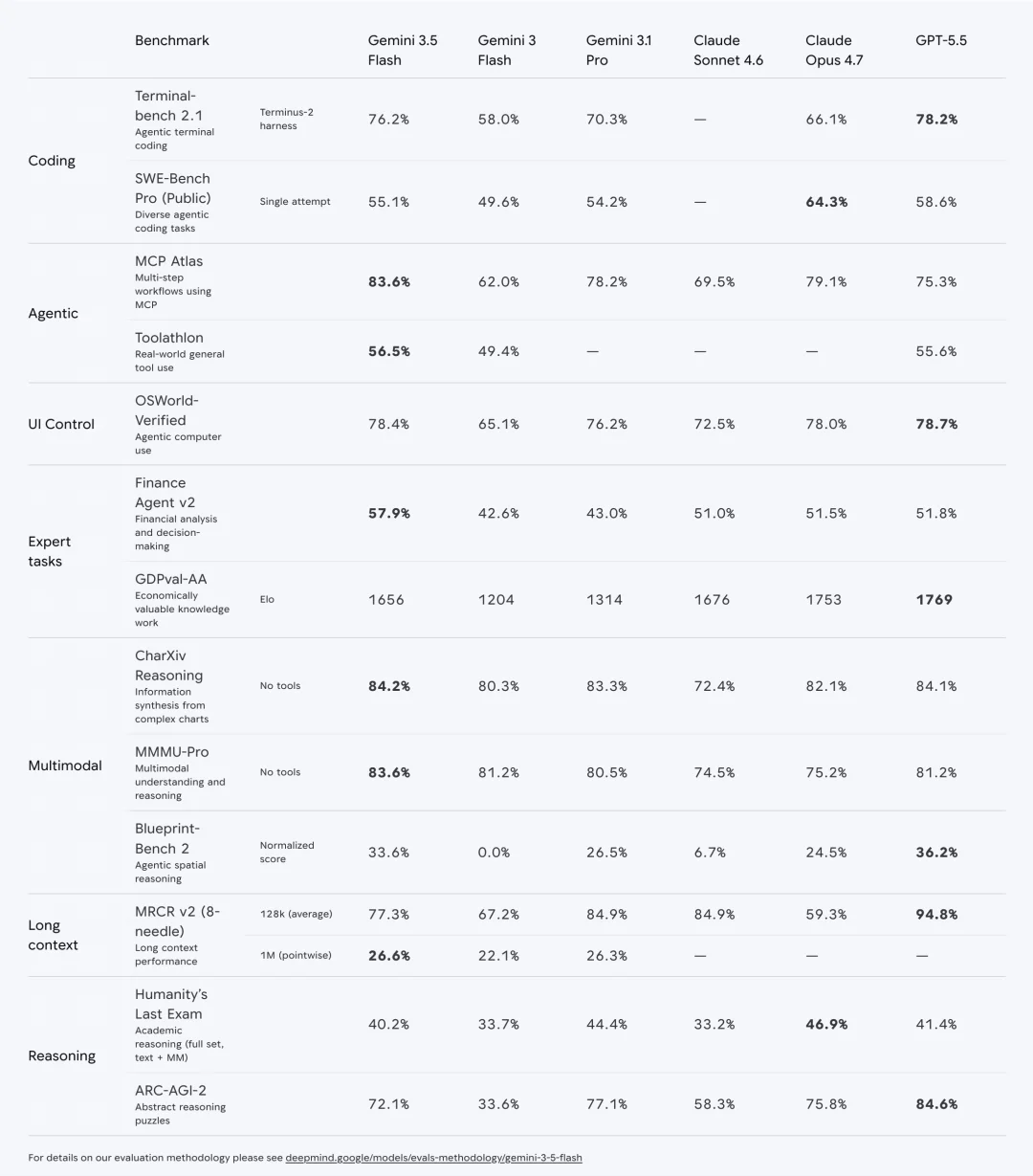
Gemini 3.5 Flash 的各项性能|图片来源:Google 播客
定价方面,输入 1.5 美元/百万 token,输出 9 美元/百万 token。它跟 Claude Opus 4.7 输入 5 美元输出 25 美元的定价比,便宜了几倍。跟 GPT-5.5 比,也有明显的价格优势。
但真正让它在一众模型中脱颖而出的,是 289 tokens/秒的输出速度:首 token 延迟大约 65 毫秒,比其他前沿模型快了 4 倍左右。
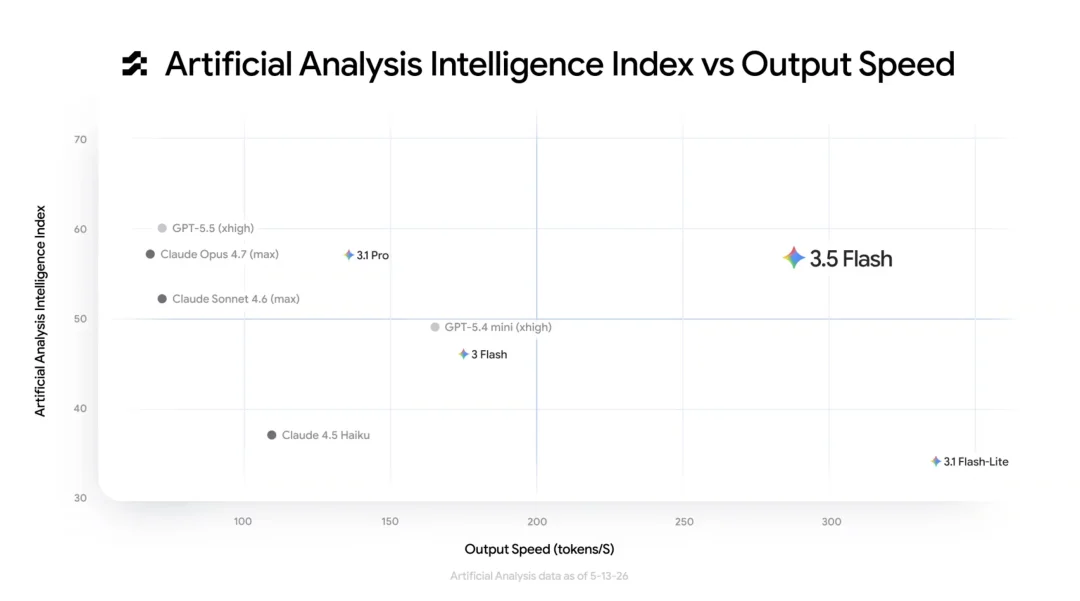
Gemini 3.5 Flash 在性能 * 速度方面独一档|图片来源:Google 播客
它在 benchmark 做到了许多维度的 SOTA,具体用起来到底怎么样?
先提一下:Qwen3.7-Max 和 Gemini 3.5 Flash 在 Text Arena 上的分数比较接近。
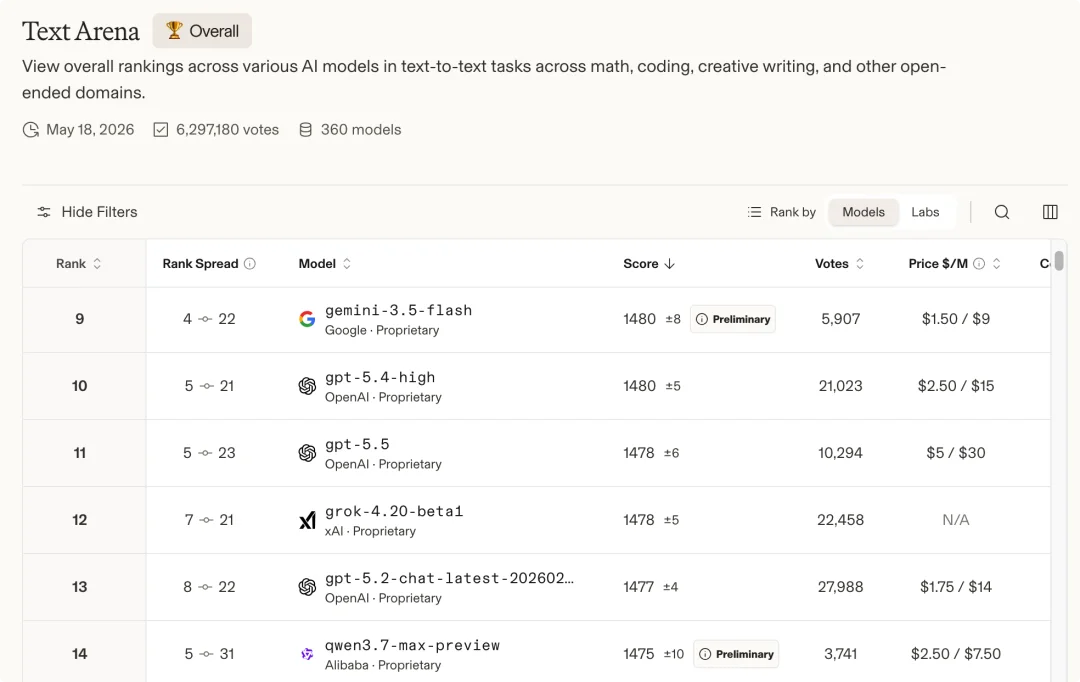
Gemini 3.5 Flash 和 qwen3.7-max 的评分很接近|图片来源:Arena
Qwen3.7-Max 这个模型,在评测集上已经超过了国内的旗舰模型 Kimi 2.6、GLM-5.1、DeepSeek-V4,是目前国内的第一水平,效果也非常接近国外的顶尖模型。
Qwen 这次也专门为 Agent 可靠性设计,支持长达 35 小时的端到端自主任务执行,推理内核经过深度 GPU 优化,速度提升达 10 倍。
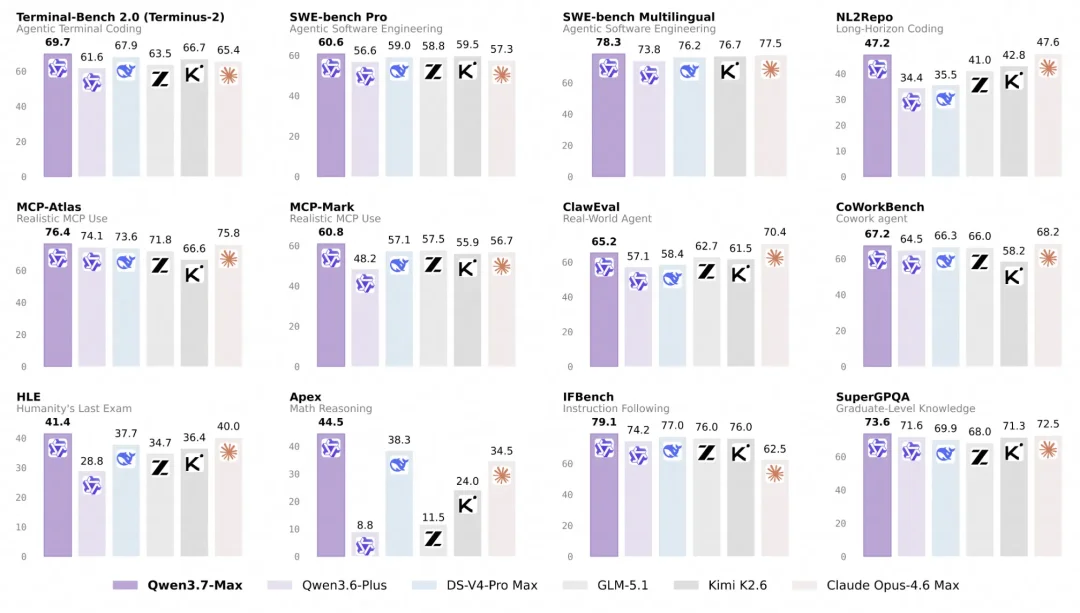
Qwen3.7-Max 的效果|图片来源:Qwen
两个面向 Agent 场景的顶级选手放在一起测,真实效果会如何呢?
第一个测试:写一首给自己的小情诗
提示词:帮我写首给自己的小情诗
这是个轻量级任务,主要看基础文本生成的速度和质量。
Qwen3.7-Max 输出用了 30 秒,Gemini 3.5 Flash 用了 11 秒。速度差距接近 3 倍。
质量上,Qwen 的中文文笔确实更好一些,遣词造句更有韵味。Gemini 虽然中文表达稍显直白,但考虑到 11 秒的响应时间,这个响应体验已经很接近即时对话了。

Qwen 3.7-max 实测 |图片来源:Zenmux

Gemini 3.5 Flash 实测 |图片来源:Zenmux
如果你只是日常聊天写文字,两者都够用。
但如果场景换成 Agent 产品,用户每说一句话都在等回复,11 秒和 30 秒的差距就是「流畅对话」和「明显在等」的区别。
第二个测试:Golden Gate Bridge 3D 体素模拟
提示词:ObjectiveBuild a visually stunning, high-fidelity 3D voxel-style simulation of the Golden Gate Bridge in Three.js.Prioritize complex visuals (not simple blocks), strong atmosphere depth, and smooth ~60FPS.Visuals & Atmosphere- Lighting: a Time-of-day slider (0–24h) that controls sun position, intensity, sky color, and fog tint.- Fog: volumetric-feeling fog using lightweight sprite particles; slider 0–100 (0 = crystal clear, 100 = dense but not pure whiteout).- Water: custom shader for waves + specular reflections; blend horizon with distance-based fog (exp2) so the far water merges naturally.- Post: ACES filmic tone mapping + optimized bloom (night lights glow but keep performance).Scene Details- Bridge: recognizable art-deco towers, main span cables + suspenders, piers/anchors consistent with suspension bridge structure.- Terrain: simple but convincing Marin Headlands + SF side peninsula silhouettes.- Skyline: procedural/instanced city blocks on the SF side to suggest depth.- Traffic: up to ~400 cars via InstancedMesh, properly aligned on the deck (avoid clipping). Headlights/taillights emissive at night.- Ships: a few procedural cargo ships with navigation lights moving across the bay.- Nature: a small flock of animated birds (lightweight flocking).Night ModeAt night, enable city lights, bridge beacons, street lights, vehicle lights, ship nav lights.Tech & Controls (Important)- Output MUST be a single self-contained HTML file (e.g., golden_gate_bridge.html) that runs by opening in Chrome.- No build tools (no Vite/Webpack). Pure HTML + JS.- Import Three.js and addons via CDN using ES Modules + importmap.- UI: nice-looking sliders for Time (0–24), Fog Density (0–100), Traffic Density (0–100), Camera Zoom.- Optimization: use InstancedMesh for repeated items (cars/lights/birds), avoid heavy geometry, keep draw calls low.
我给了一个非常复杂的 Three.js 需求,要求生成一个带昼夜系统、雾气效果、交通流、船只和鸟群的金门大桥 3D 场景,输出必须是单文件 HTML,不能用任何构建工具。
Qwen3.7-Max 输出用了 204 秒,消耗了 14770 个 token。Gemini 3.5 Flash 用了 157 秒,但消耗了 35996 个 token。
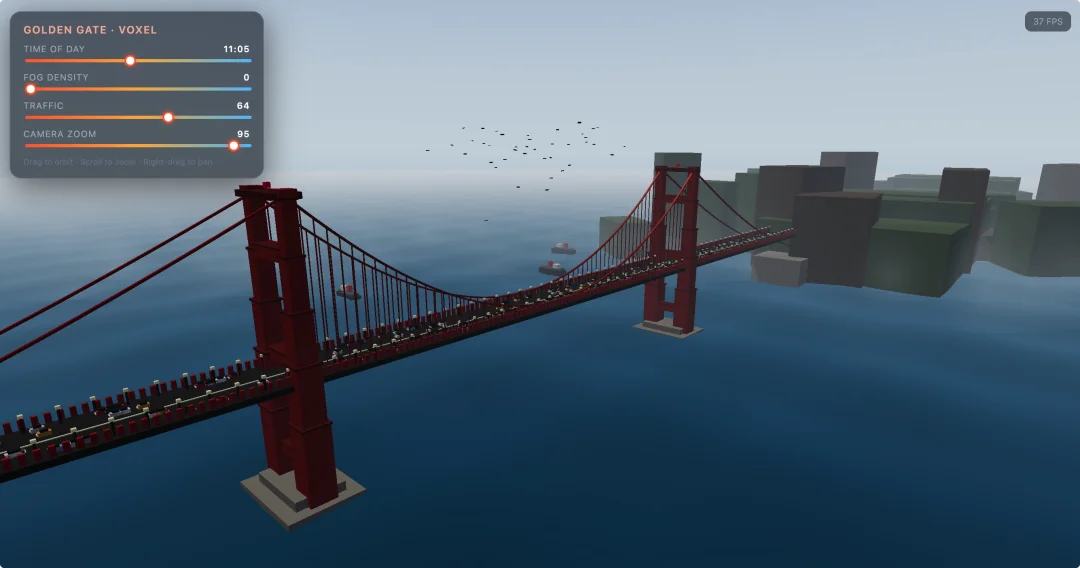
Qwen 3.7-max 实测 |图片来源:Zenmux

Gemini 3.5 Flash 实测 |图片来源:Zenmux
这里出现了一个有意思的现象:Gemini 虽然总耗时更短,但 token 消耗是 Qwen 的 2.4 倍。
换句话说,Gemini 完成同样任务写的代码消耗的 token 确实更「多」,这也意味着整体 Gemini 在执行任务的费用更贵。
不过 Gemini 3.5 Flash 因为每秒吐出的 token 数量远高于对手,所以还是能保持总时间反而更短。
视觉效果上,Qwen3.7-Max 的整体层次感更丰富,光影和氛围做得更细腻。Gemini 则胜在桥的结构细节,悬索、塔柱的比例更接近真实的金门大桥。
两者各有所长,都是高水准的输出。
第三个测试:macOS 菜单栏语音输入应用
提示词:https://github.com/yetone/voice-input-src
模型能力强不强,Agent 场景才是真正拉开差距的地方。
前两个测试本质上都是「一次性生成」——给个提示词,模型输出一段内容就结束了。但真实的 Agent 工作流不是这样的,它是一个长程任务,需要模型反复与环境交互、试错、修正。
所以这次,我让两个模型各自实现一个完整的 macOS 语音输入应用。这个开源项目很有意思:仓库里只有一份提示词,没有任何代码。想到朋友说的那句话:在 AI 时代,文档是资产,代码是负债。
我把需求丢给两个模型,分别在 Claude Code 上跑。需求包括:Fn 键全局监听、流式语音识别、悬浮窗动画、输入法兼容处理、LLM 纠错集成、菜单栏配置界面,最终要求输出签名好的 .app 包。
结果差距非常大:
Qwen3.7-Max 跑了 55 分钟,但是程序也没能一遍过,中间出现编译错误,需要人工介入。
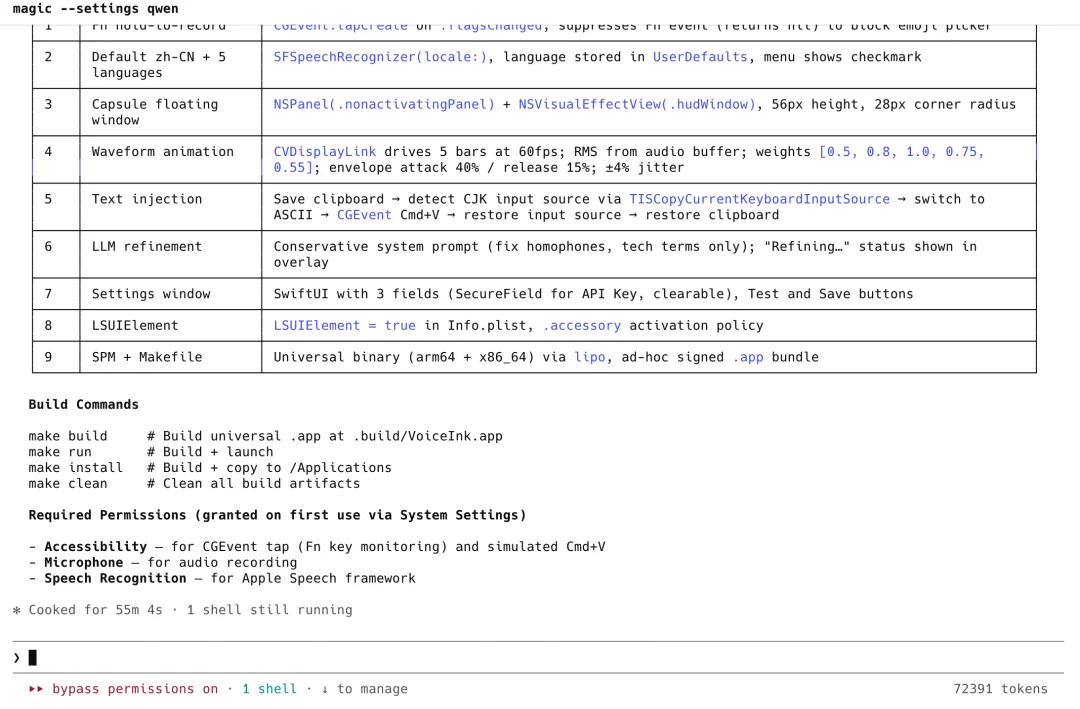
Qwen 3.7-max 实测 |图片来源:Zenmux
而 Gemini 3.5 Flash 仅跑了 10 分钟,程序直接一遍过。
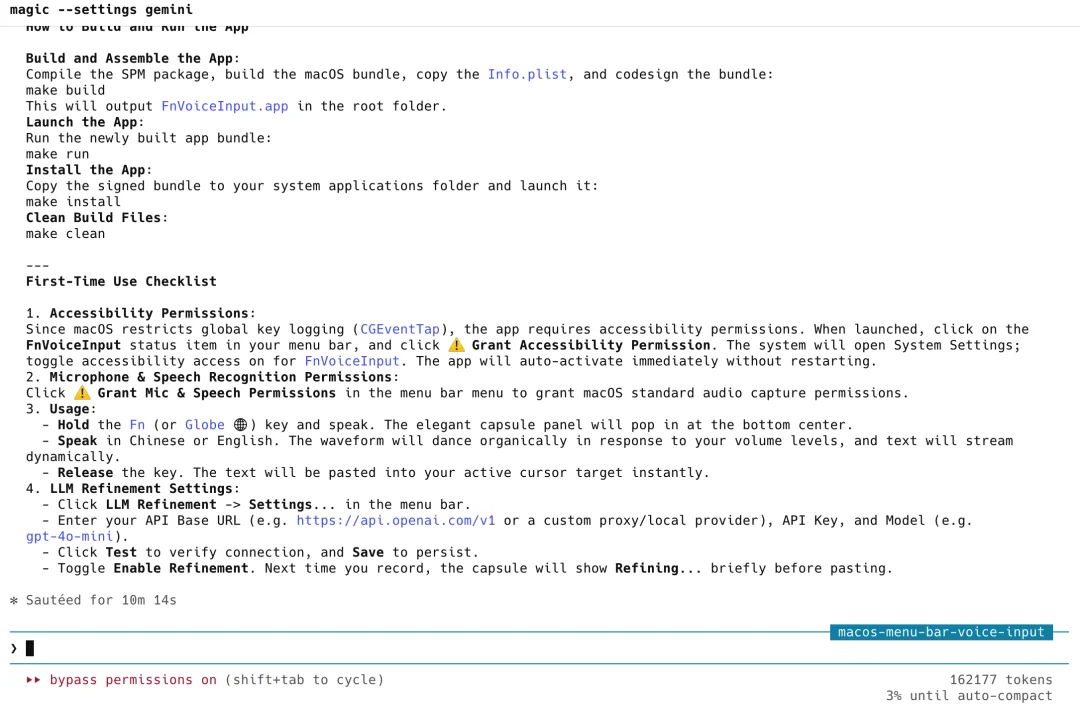
Gemini 3.5 Flash 实测 |图片来源:Zenmux
从 55 分钟到 10 分钟:将近 5 倍的效率差距,而且 Gemini 的输出是直接能用的,不需要额外调试。
这个结果让我有点意外:
之前写诗和做 3D 的测试里,两者差距并不大。但一旦进入 Agent 编程的场景,Gemini 3.5 Flash 的 Agent 能力和速度优势被急剧放大了。
原因也很好理解:Agent 执行长程编码任务,不是一次性输出一大段文字,而是要反复调用工具、读取反馈、修改代码、再次执行。每一轮交互都省下来的时间累积起来,差距就变得巨大。
我用了一个可能不太精确,但很直观的说法:
过去大模型的生成速度更接近 3G 的体验,你知道它在工作,但你需要等。
而 Gemini 3.5 Flash,让我第一次感受到了接近 4G 的流畅度。
这种速度上的变化带来的不仅仅是「快一点」的体验提升,它直接决定了某些产品形态能不能成立。
比如 AI 陪伴这个场景:最近520 EVE 火了,王登科最近也上线了 AI 陪伴产品 The One。
在陪伴场景里,用户对回应速度的敏感度极高:
如果对方两三秒就能回你,那种感觉是「在聊天」,但如果要等十几秒,那种感觉是「在等一个机器给你生成内容」。
而 Gemini 3.5 Flash 65 毫秒的首 token 延迟,289 tokens/秒的输出速度,意味着用户几乎感受不到等待。
微信里的 AI 陪伴 The One |图片来源:微信
但速度和智能之间存在一个很现实的矛盾:
GPT-5.4 刚出来的时候,编程效果超过了 Anthropic 4.5,但很多人还是选择继续用 Anthropic 4.5。
为什么?因为在实际工程任务里,稳定性和指令遵循的精度有时候比极致的聪明更重要:
模型想变得更聪明,通常意味着参数量更大、推理链更长,这就会导致速度下降。
所以行业里开始出现一种分化:有的公司死磕模型能力上限,有的公司则专注于在保持够用的智能水平的同时,把速度推到极致。
Gemini 3.5 Flash 选择了后者,而且做得相当激进:它甚至把默认推理档位从上一代 Flash 的 High 降到了 Medium,主动降低推理深度来换取速度提升。
Google 在这里做了一个关键的决策:对于 Agent 场景来说,快比聪明更重要。
这个判断对不对?从 Agent 的发展趋势来看,它很可能是对的。
回到文章开头那个问题:
当模型的响应速度从「能用」变成「实时」,Agent 的使用体验会发生什么质变?
我想从两个维度来回答。
第一个是实时交互的体验升级。
Claude Code 这类 Agent 产品在执行任务时,用户能明显感觉到模型在「思考」「等待」「处理」的间隙。
这些间隙加起来,一个 20 分钟的任务可能有 5 分钟是你在看它转圈。
当速度快 4 倍,这些间隙被大幅压缩,整个过程变得更像「你交代任务,它流畅执行」,而不是「你交代任务,它断断续续地干」。
第二个维度更有意思,也是我觉得 Gemini 3.5 Flash 真正的价值所在:
它让 Agent 能在相同时间内完成更多的事。
想象一下这样一个场景。假设你让一个 Agent 跑 24 小时来完成一个大型项目。如果模型输出速度是原来的 4 倍,在 Agent 调用工具的时间不变的前提下,一天内的产出可能提升 2 到 3 倍。
这个计算很粗略,因为 Agent 执行过程中有大量时间花在等待工具返回结果、读取文件、编译代码上,这些时间不会因为模型变快而缩短。但模型思考和输出代码的那部分时间确实能被大幅压缩。
而最近的趋势是,Agent 执行任务的时间越来越长:
Claude Code 在不断优化它的任务编排能力;OpenAI Codex 最近推出了 /goal 功能,可以让Agent连续运行几小时甚至几天直到任务完成;各家都在努力拉长模型的持续工作时间:从半小时的任务到几小时的项目,再到 Qwen3.7-Max 宣称支持的 35 小时端到端执行。
任务时间线被拉长的同时,模型响应速度的价值也在同步放大:
一个 10 分钟的任务,省几分钟你可能无感。
但当任务拉长到 10 小时、24 小时,省下的时间可能是小时级的。
即使只算模型输出环节快 4 倍,一天的长程任务也能多挤出好几个小时的有效产出。
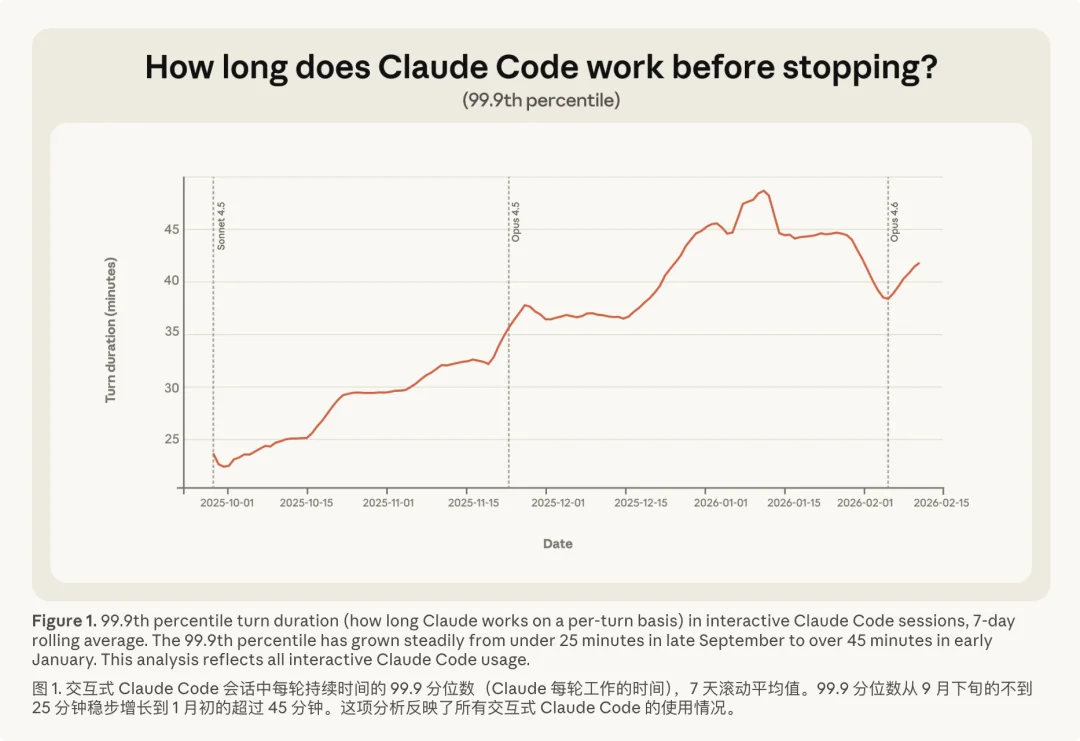
Agent 的长程工作时间越来越长 | 图片来源:Anthropic
这就是 Gemini 3.5 Flash 对 Agent 生态真正的价值:
它让 Agent 的生产效率提升了一个量级,而且这个收益会随着任务时长的增加而持续放大。
写到这里我想做个总结。
Gemini 3.5 Flash 有明显的短板:它在 Humanity's Last Exam 上只拿了 40.2%,低于自家上一代 Pro 的 44.4%。在抽象推理、长文档检索等测试中表现也不算突出。
它确实「偏科」,这是有意而为之,Google 主动在某些能力上做了取舍:
Gemini 3.5 Flash 选择了 Coding 和 长程 Agent 能力,比如在 APEX 基准测试上(评估模型在真实工作场景中执行跨应用、长跨度任务的能力),Gemini 3.5 Flash 排名全球第一。
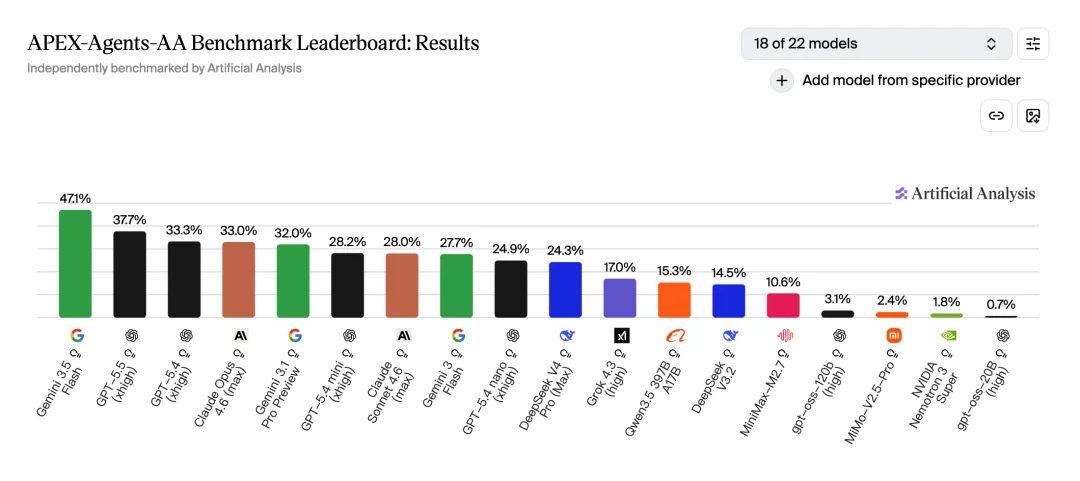
Gemini 3.5 Flash 在 APEX 独一档 | 图片来源:artificialanalysis
但如果你把视角从「模型对比」切换到「Agent 工具选型」,你会发现这些短板在很多实际场景里并不致命:
大部分 Agent 任务不需要模型去回答「人类最后一考」那种综合知识题,它需要的是快速生成代码、准确调用工具、高效处理多步骤工作流。
而在这些场景上,Gemini 3.5 Flash 做到了又快又好。
前两天听了一期播客,张小珺对姚顺宇的四小时访谈,姚顺宇是从 Anthropic 跳到 Google DeepMind 的研究科学家,参与过 Claude 3.7 和 Gemini 3 的开发。
张小珺和姚顺宇对谈 | 图片来源:小宇宙
他有句话让我印象很深:现在模型在纸面上看着都差不多,benchmark 高一个点低一个点,那些差距主要是噪声而不是信号,实际用起来,区别依然明显。
然后他聊到自己现在的研究重心,两件事:AI 自己做研究,以及 long horizon。Long horizon 就是让模型在更长的时间跨度里持续工作,完成那些一句提示词搞不定的复杂任务。
Gemini 3.5 Flash 无疑是这个观点印证,它的发布标志着一个新阶段的开始:
以前我们选模型看的是「谁最聪明」。但当Agent成为主要的调用方式,答案可能要改成「谁能让Agent跑得最快、最远、最稳」。它也是第一个让我明确感知到这个拐点的产品。
如果你正在用 Claude Code 或者其他 Agent 工具做开发,我建议试试把底层模型切到 Gemini 3.5 Flash 跑几个项目。
你会发现:那种 10 分钟交付一个完整应用的体验,用过之后很难回去。
毕竟,天下武功,唯快不破。
*头图来源:youtube
文章来自于"极客公园",作者 "金光浩"。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
