# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

最近到了毕业季,好多朋友来找我聊一件事:有什么办法帮他降 AIGC。
他们在做毕设,学校今年开始查 AI 率了:知网的,维普的,要求一般压到 30% 以下。有个朋友被打回来两次,急得不行,问我有没有什么办法。
我当时第一反应是:这个检测到底靠不靠谱?是不是存在很简单的方式就能绕过去?
然后我想起两年前,我用知乎的回答数据训过一个非常口语化的模型。但那个东西在这完全没法用,因为论文里的改写要求非常微妙:太口语化,导师一眼就看出不对劲。改动太小,检测系统照样标红。
我研究了下,发现比较麻烦的是,各家平台的 AI 检测模型,训练数据不公开,特征设计不公开,阈值策略也不公开,更别说提供稳定的 API 了。如果你想直接用 PPO 或者 GRPO 去对抗某一个检测器,reward 都没法设计,因为你连检测模型都拿不到。
所以我换了个思路:五一闲着也没事,能不能训一个模型,让文本在保持学术规范的前提下,把 AI 疑似占比明显降下来?
结果还真做出来了。
下面记录一些试错过程和最终可用的方案。
模型和数据都已经开源,链接在文末。
动手之前,我先试了两条最省力的路径。
第一条:找一个现成的 Prompt 或者 Skill 来改写。
我翻了一圈 GitHub,英文方向有个仓库看起来可用(github.com/blader/humanizer),但中文方向基本是空白。
有一个自动改写中文的项目用了传统 NLP 手段检测 AI 率(github.com/voidborne-d/humanize-chinese),但改写方式是规则替换,检测手段也比较粗糙,参考价值有限。
第二条:换一个冷门模型。
逻辑很简单,检测模型本质上是在判断文本的统计分布是否接近常见模型的分布。
如果用一个极其冷门的模型,它的输出分布天生远离被检测的那些模型,是不是能天然绕过?
想法很美好,但很快排除了:太冷门的模型对中文支持一般很弱,效果上不去。
而且没有做过针对性的 Post Train 调整,底层分布和主流模型的差异其实也没那么大。
两条路都走不通,只能老老实实训练了。
Step1:SFT,第一个可用但不够好的版本
数据构造上,直觉是用反向构造:
找一批人类写的文本,用 AI 改写成「AI 味」很重的版本,然后训练模型学会反向操作。
关键问题在于,原始文本用哪一类。
前期我找了互联网网页数据,踩了两个坑。一个是数据清洗很繁琐,XML 标签、网页跳转链接之类的噪音要处理掉。另一个更致命,训出来的模型太口语化了,根本没法用在学术场景。
那就得把数据范围限制在学术类文本上。
我的第一个想法是用 Wikipedia,但 Wiki 数据在 pre-train 阶段占比通常很高,效果存疑。直接从 arxiv 下载论文切分?主要是理工科英文论文,文社科和中文覆盖少,泛化能力会受限。
最后找到一个比较合适的数据集:CSL(github.com/ydli-ai/CSL),收集的是中文论文摘要。
虽然只是摘要,但和正文段落在语言分布上差异不算太大。
最终我构造了约 18000 条训练样本,格式是 instruction + input + output。指令统一为「将文本改写得更像自然人写作,保持原意与事实」,输入是 AI 改写后的摘要,输出是原始论文摘要。
基座选了 Qwen3.5-9B,收敛效果不错,Loss 曲线比较平滑,我做了提前停止。
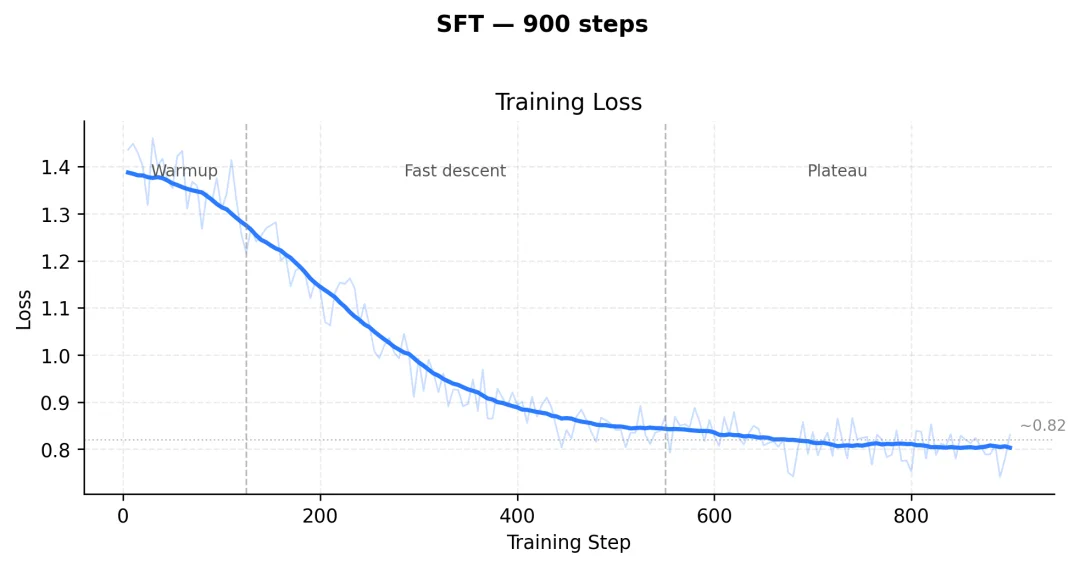
看个案例,原文类似这样:
今天没什么特别的,和平常一样。早上起床玩了会手机,中午随便吃了点东西,下午出去买了杯咖啡。桂花开了,闻着挺香的。在公园坐了十来分钟,看了一会儿狗和小孩。然后就回家了。这一天就这么过去了,不坏也不好,就是普通的一天。
处理后就变成这样:
今日平平淡淡,与往日无异。晨起时翻阅了些许手机资讯,午间随意进食,午后外出购得一杯咖啡。恰逢桂子飘香,漫步公园约莫十分钟,观览孩童嬉戏与犬只闲逛,随后便归家。一日就此落幕,并无甚波澜,既非佳日亦非恶日,不过寻常时日罢了。
这个 SFT 版本能完成改写任务,学术术语保留得也不错。
但问题在于学术场景改写太保守,毕竟改写前后的文案差异本身就小,学术类文本又天然偏严肃,而日常场景又太过文邹邹。
这直接导致两个问题:改写程度不够,检测系统还是能抓到;模型只能用在学术场景,通用性很差。
Step2:DPO 第一阶段,一个关键错误和修正
SFT 之后,我想用 DPO 来增强效果。
为什么不用 PPO?还是之前提到的问题。每家检测模型不一样,且拿不到 API。与其去 hack 某一个具体的检测器,不如找到一种让文本更接近人类分布的通用方法,这样更可能具备跨检测器的泛化性。
但 DPO 的第一次实验,我犯了个错误。
我按 SFT 的思路构造数据:chosen 是人类原文,rejected 是 AI 改写。听起来很合理对吧?但实际跑起来问题很大。因为 AI 改写后的文本通常更书面、更严谨,而人类原文相比之下反而更口语化一些。模型学到的信号变成了「越口语化越好」,而不是「越接近人类分布越好」。
这个版本直接不可用。
意识到问题之后,我把数据构造改成了双向的:
一边是 2000 条 formal-rejected,AI 改写保持正式书面的语气不变。另一边是 2000 条 casual-rejected,AI 改写加入各种口语化变体,改长改短,增减信息。
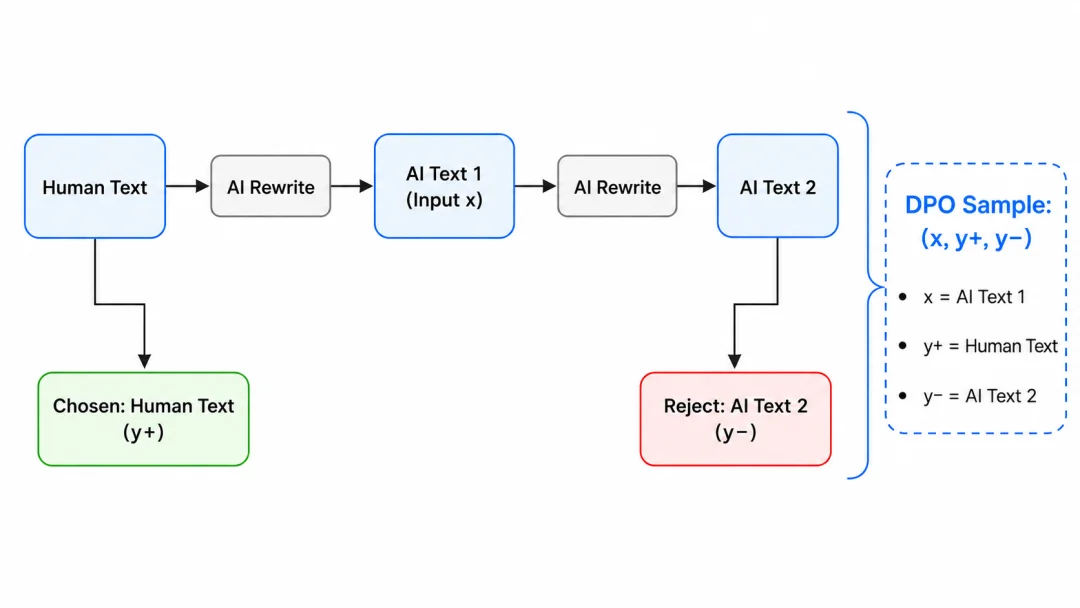
这个构造方式让模型真正学到了什么叫「人类文本」的感觉。
这次处理后的效果是这样的:
今天平平淡淡,和往常一样。早晨醒来玩了一会儿手机,中午胡乱塞了几口食物,下午出门买杯咖啡。桂花开了,闻起来很香。在公园里坐十几分钟,看了看狗和小孩。然后便回家。这一天就这样过去了,不糟糕也不出色,就是平凡的一天。
它不再简单地认为口语化就是好的,也不再认为书面化就是坏的,而是学会了一种更像人的风格。
Step3:DPO 第二阶段:自博弈与信号纯度的教训
有了更稳固的 DPO 版本,我尝试用自博弈来进一步提升。
这里又犯了一个错误:我把自博弈数据和一部分口语化 rejected 数据混在一起训练,本来想法是给模型加一道「围栏」,防止它跑偏,但自博弈产生的学习信号很弱,口语化 rejected 的区分信号太强。模型很快就能分辨出哪些是口语化的数据,如果一个 batch 里采样到的口语化数据多,梯度就暴涨,整个训练过程抖动得厉害。
于是,我果断放弃这个版本。
然后重新来过:去掉所有口语化数据,保证信号单一。
没有了「围栏」,我就把学习率调到之前的一半,用更慢的速度防止跑偏,然后自博弈数据扩展到 2000 条,重新开始训。
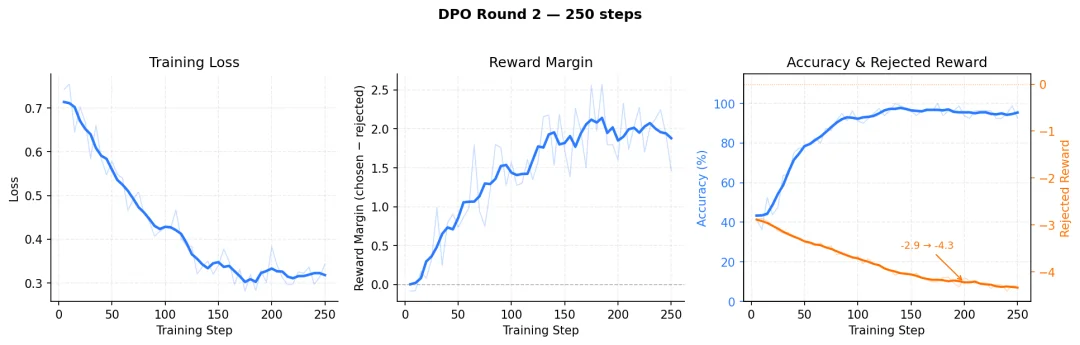
这个版本训完之后,终于接近可用状态了。
这次处理后的文本效果是这样的:
一切如常,今天没有什么特别之处。起床后玩了一会儿手机,中午胡乱吃了一些东西,下午去外面买咖啡喝。桂花开了,闻着很香。在公园里坐了一刻钟左右,看了会儿狗和小孩子。随后就回家。就这样,一天过去了,不好也不差,就是普通的一天。
我拿两篇论文做了批量改写测试:
第一篇 AI 率从 50%降到 24%,第二篇从 30%降到 8.9%。
我也人工抽查了几十段,语义和事实信息基本保留无误。

当然这个模型远谈不上完美,但作为一个可行性验证,这个已经很可以了。我相信扩展数据量和数据类型之后,效果还能进一步提升。
整个实验在一个五一假期内完成。
我用的是单张 5090,思路说清楚之后,实现本身已经不是难点了。
然后我把模型和合成数据都一起开源出来了:https://github.com/XiangJinyu/humanize-zh
模型训练完,我看了下不同版本模型的改写对比案例,发现有个现象挺有意思的:
SFT 版本在学术场景还行,但你给它一段日常文字,它会把随便一段话改成了文言文既视感。
比如「今天没什么特别的,和平常一样,早上起床玩了会手机」这种,它会改成「今日平平淡淡,与往日无异,晨起时翻阅了些许手机资讯」。
但 DPO Stage-2 的版本,即使训练数据全部来自学术论文,在日常场景里也展现出了相当好的可用性。
同一段话它会改成「一切如常,今天没有什么特别之处。起床后玩了一会儿手机」,非常自然。
这说明 DPO 阶段学到的东西,确实更接近底层的「人类分布对齐」,而不只是学术文本的表面特征。
通过学术论文上的训练,模型泛化出了一部分通用的改写能力。
这个发现让我觉得整条技术路径是值得继续投入的。
在做这个项目的过程中,我有一些感触:检测系统拦住的是谁?是那些懒得折腾的人。真正想绕过的人,花一个假期就能做出可用的方案。而随着这类工具越来越多,反检测的产业只会越来越成熟。
也许,其实更值得追问的是:教育系统到底在检测什么?
工作之后,从来没有人问过你的文档 AI 率是多少。大家只关心你能不能解决问题,能不能交付结果。
在一个 AI 工具已经无处不在的时代,与其把精力放在检测学生有没有用 AI,不如想想怎么教学生把 AI 用好。
AI 时代来了,怎么让学生在 AI 的帮助下学到更多东西,怎么设计一套新的评估体系来衡量真实的学习效果。
这也许才是,真正值得高校花时间做的事。
文章来自于"特工宇宙",作者 "特工鲸鱼"。


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
