# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
机器之心发布
机器之心编辑部
不久前 OpenAI Sora 以其惊人的视频生成效果迅速走红,在一众文生视频模型中突出重围,成为全球瞩目的焦点。继 2 周前推出成本直降 46% 的 Sora 训练推理复现流程后,Colossal-AI 团队全面开源全球首个类 Sora 架构视频生成模型 「Open-Sora 1.0」,涵盖了整个训练流程,包括数据处理、所有训练细节和模型权重,携手全球 AI 热爱者共同推进视频创作的新纪元。
先睹为快,我们先看一段由 Colossal-AI 团队发布的「Open-Sora 1.0」模型生成的都市繁华掠影视频。

Open-Sora 1.0 生成的都市繁华掠影
这仅仅是 Sora 复现技术冰山的一角,关于以上文生视频的模型架构、训练好的模型权重、复现的所有训练细节、数据预处理过程、demo 展示和详细的上手教程,Colossal-AI 团队已经全面免费开源在 GitHub,同时笔者第一时间联系了该团队,了解到他们将不断更新 Open-Sora 的相关解决方案和最新动态,感兴趣的朋友可以持续关注 Open-Sora 的开源社区。
Open-Sora 开源地址:https://github.com/hpcaitech/Open-Sora
全面解读 Sora 复现方案
接下来,我们将深入解读 Sora 复现方案的多个关键维度,包括模型架构设计、训练复现方案、数据预处理、模型生成效果展示以及高效训练优化策略。
模型架构设计
模型采用了目前火热的 Diffusion Transformer (DiT) [1] 架构。作者团队以同样使用 DiT 架构的高质量开源文生图模型 PixArt-α [2] 为基座,在此基础上引入时间注意力层,将其扩展到了视频数据上。具体来说,整个架构包括一个预训练好的 VAE,一个文本编码器,和一个利用空间 - 时间注意力机制的 STDiT (Spatial Temporal Diffusion Transformer) 模型。其中,STDiT 每层的结构如下图所示。它采用串行的方式在二维的空间注意力模块上叠加一维的时间注意力模块,用于建模时序关系。在时间注意力模块之后,交叉注意力模块用于对齐文本的语意。与全注意力机制相比,这样的结构大大降低了训练和推理开销。与同样使用空间 - 时间注意力机制的 Latte [3] 模型相比,STDiT 可以更好的利用已经预训练好的图像 DiT 的权重,从而在视频数据上继续训练。
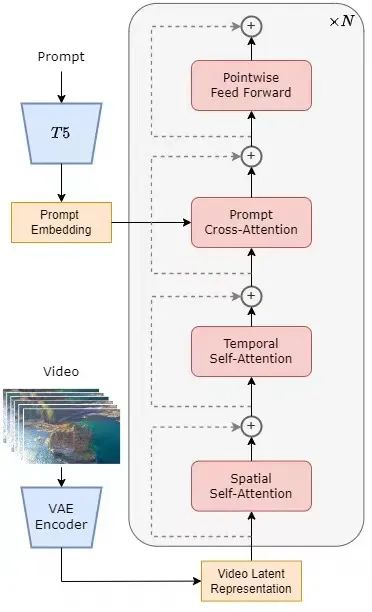
STDiT 结构示意图
整个模型的训练和推理流程如下。据了解,在训练阶段首先采用预训练好的 Variational Autoencoder (VAE) 的编码器将视频数据进行压缩,然后在压缩之后的潜在空间中与文本嵌入 (text embedding) 一起训练 STDiT 扩散模型。在推理阶段,从 VAE 的潜在空间中随机采样出一个高斯噪声,与提示词嵌入 (prompt embedding) 一起输入到 STDiT 中,得到去噪之后的特征,最后输入到 VAE 的解码器,解码得到视频。

模型的训练流程
训练复现方案
我们向该团队了解到,Open-Sora 的复现方案参考了 Stable Video Diffusion (SVD)[3] 工作,共包括三个阶段,分别是:
1) 大规模图像预训练;
2) 大规模视频预训练;
3) 高质量视频数据微调。
每个阶段都会基于前一个阶段的权重继续训练。相比于从零开始单阶段训练,多阶段训练通过逐步扩展数据,更高效地达成高质量视频生成的目标。

第一阶段:大规模图像预训练
第一阶段通过大规模图像预训练,借助成熟的文生图模型,有效降低视频预训练成本。
作者团队向我们透露,通过互联网上丰富的大规模图像数据和先进的文生图技术,我们可以训练一个高质量的文生图模型,该模型将作为下一阶段视频预训练的初始化权重。同时,由于目前没有高质量的时空 VAE,他们采用了 Stable Diffusion [5] 模型预训练好的图像 VAE。该策略不仅保障了初始模型的优越性能,还显著降低了视频预训练的整体成本。
第二阶段:大规模视频预训练
第二阶段执行大规模视频预训练,增加模型泛化能力,有效掌握视频的时间序列关联。
我们了解到,这个阶段需要使用大量视频数据训练,保证视频题材的多样性,从而增加模型的泛化能力。第二阶段的模型在第一阶段文生图模型的基础上加入了时序注意力模块,用于学习视频中的时序关系。其余模块与第一阶段保持一致,并加载第一阶段权重作为初始化,同时初始化时序注意力模块输出为零,以达到更高效更快速的收敛。Colossal-AI 团队使用了 PixArt-alpha [2] 的开源权重作为第二阶段 STDiT 模型的初始化,以及采用了 T5 [6] 模型作为文本编码器。同时他们采用了 256x256 的小分辨率进行预训练,进一步增加了收敛速度,降低训练成本。
第三阶段:高质量视频数据微调
第三阶段对高质量视频数据进行微调,显著提升视频生成的质量。
作者团队提及第三阶段用到的视频数据规模比第二阶段要少一个量级,但是视频的时长、分辨率和质量都更高。通过这种方式进行微调,他们实现了视频生成从短到长、从低分辨率到高分辨率、从低保真度到高保真度的高效扩展。
作者团队表示,在 Open-Sora 的复现流程中,他们使用了 64 块 H800 进行训练。第二阶段的训练量一共是 2808 GPU hours,约合 7000 美元,第三阶段的训练量是 1920 GPU hours,大约 4500 美元。经过初步估算,整个训练方案成功把 Open-Sora 复现流程控制在了 1 万美元左右。
数据预处理
为了进一步降低 Sora 复现的门槛和复杂度,Colossal-AI 团队在代码仓库中还提供了便捷的视频数据预处理脚本,让大家可以轻松启动 Sora 复现预训练,包括公开视频数据集下载,长视频根据镜头连续性分割为短视频片段,使用开源大语言模型 LLaVA [7] 生成精细的提示词。作者团队提到他们提供的批量视频标题生成代码可以用两卡 3 秒标注一个视频,并且质量接近于 GPT-4V。最终得到的视频 / 文本对可直接用于训练。借助他们在 GitHub 上提供的开源代码,我们可以轻松地在自己的数据集上快速生成训练所需的视频 / 文本对,显著降低了启动 Sora 复现项目的技术门槛和前期准备。

基于数据预处理脚本自动生成的视频 / 文本对
模型生成效果展示
下面我们来看一下 Open-Sora 实际视频生成效果。比如让 Open-Sora 生成一段在悬崖海岸边,海水拍打着岩石的航拍画面。

再让 Open-Sora 去捕捉山川瀑布从悬崖上澎湃而下,最终汇入湖泊的宏伟鸟瞰画面。

除了上天还能入海,简单输入 prompt,让 Open-Sora 生成了一段水中世界的镜头,镜头中一只海龟在珊瑚礁间悠然游弋。

Open-Sora 还能通过延时摄影的手法,向我们展现了繁星闪烁的银河。

如果你还有更多视频生成的有趣想法,可以访问 Open-Sora 开源社区获取模型权重进行免费的体验。链接:https://github.com/hpcaitech/Open-Sora
值得注意的是,作者团队在 Github 上提到目前版本仅使用了 400K 的训练数据,模型的生成质量和遵循文本的能力都有待提升。例如在上面的乌龟视频中,生成的乌龟多了一只脚。Open-Sora 1.0 也并不擅长生成人像和复杂画面。作者团队在 Github 上列举了一系列待做规划,旨在不断解决现有缺陷,提升生成质量。
高效训练加持
除了大幅降低 Sora 复现的技术门槛,提升视频生成在时长、分辨率、内容等多个维度的质量,作者团队还提供了 Colossal-AI 加速系统进行 Sora 复现的高效训练加持。通过算子优化和混合并行等高效训练策略,在处理 64 帧、512x512 分辨率视频的训练中,实现了 1.55 倍的加速效果。同时,得益于 Colossal-AI 的异构内存管理系统,在单台服务器上(8*H800)可以无阻碍地进行 1 分钟的 1080p 高清视频训练任务。

此外,在作者团队的报告中,我们也发现 STDiT 模型架构在训练时也展现出卓越的高效性。和采用全注意力机制的 DiT 相比,随着帧数的增加,STDiT 实现了高达 5 倍的加速效果,这在处理长视频序列等现实任务中尤为关键。

一览 Open-Sora 模型视频生成效果
最后,让我们一睹Open-Sora模型在视频生成上的精彩表现。
欢迎持续关注 Open-Sora 开源项目:https://github.com/hpcaitech/Open-Sora
作者团队表示,他们将会继续维护和优化 Open-Sora 项目,预计将使用更多的视频训练数据,以生成更高质量、更长时长的视频内容,并支持多分辨率特性,切实推进 AI 技术在电影、游戏、广告等领域的落地。
参考链接:
[1] https://arxiv.org/abs/2212.09748 Scalable Diffusion Models with Transformers
[2] https://arxiv.org/abs/2310.00426 PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
[3] https://arxiv.org/abs/2311.15127 Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
[4] https://arxiv.org/abs/2401.03048 Latte: Latent Diffusion Transformer for Video Generation
[5] https://huggingface.co/stabilityai/sd-vae-ft-mse-original
[6] https://github.com/google-research/text-to-text-transfer-transformer
[7] https://github.com/haotian-liu/LLaVA
[8] https://hpc-ai.com/blog/open-sora-v1.0
本文来源于机器之心 作者 机器之心



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
