# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI模型在电脑上预测精度爆表,一到实验室就各种出错用不了?
本质还是训练思路没选好。
众所周知,理论计算和真实实验往往存在偏差。如果AI模型一直只在计算生成的完美数据上跑,一到“真场面”必然出问题。

尽管如此,AI4S大部分模型却还是在各种计算理论榜单上卷效果,材料领域也不例外,在Matbench Discovery或Open Catalyst Project上刷成绩的AI模型比比皆是。
其中固然有真实数据稀缺的原因。
但更重要的是,在工业实验数据集上做预测往往更难,相比用固定的输入预测固定的输出,真实实验数据集不仅存在噪声、有误差,数据要求也往往直接取决于特定工业需求。
现在,来自深度原理Deep Principle的最新材料基座模型MPA(Materials Property Axiom),走了一条截然不同的“野”路子——
把大语言模型的训练方式直接拿来用,一举在40个真实工业任务数据集上拿下SOTA。
同样是真实数据稀缺的情况,为何MPA如此优秀?
一起来看看模型到底是怎么训练的。
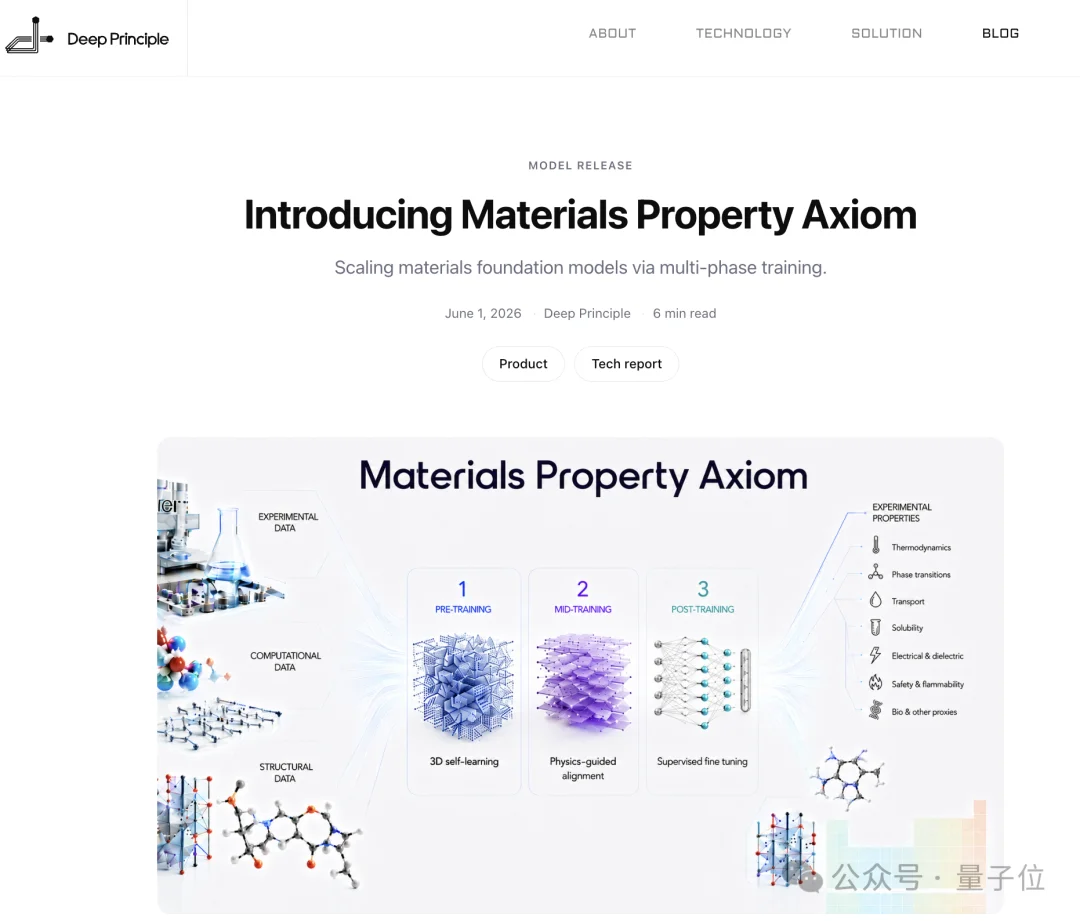
MPA架构本身基于Transformer模型,其结构可以非常直观地分为“头”和“躯干”两部分。
这次最核心的两大突破,在于训练模式的改变和后训练阶段“头”的设计上。
第一点,mid-training的加入。
之前的材料基座模型,训练模式基本分为两个阶段,预训练(pre-training)和直接微调。
其中,预训练是基于通用知识库对模型做一个当前行业的“基础通识训练”,最后通过微调“精细任务优化”。
而在大模型模型(LLM)的实践中,大家早就发现这样的训练模式还不足以“喂饱”它,因此往往要在预训练和后训练中间再叠加一层中期训练(mid-training),用来让模型在中等规模大小的通用任务(如代码调试、数学谜题等)方面取得更好的表现,最终才能在更精细的特定任务上微调取得最佳效果。
为什么要对参数量没那么大的模型也这样做?
事实上,正如通用语料和特定单点任务存在鸿沟一样,材料性质预测模型,同样需要弥补从理论计算直接到实验数据预测之间的鸿沟。
这其中的关键,在于建立AI对于真实材料需求的“物理直觉”,而不只是停留在分子结构上。
从分子结构到“物理直觉”到底差了什么?
如果将各个原子类比为人类的五官,AI模型学习分子结构时,就像是在学习人类五官的位置,特定的分子有特定的五官分布,但整体仍然有规律可循。
以苯环为例,AI在看过一系列苯环架构后,就能理解“六个碳在一个平面上”、或是“C-C键长1.4Å”这样的特征信息。
然而,AI学习不同的分子结构后,却并没有认识到相似结构间隐含的物理信息,就像能识别不同人脸却无法理解共同的表情规律一样。
还是以苯环为例,虽然AI一眼认出来这是苯环,但是对于苯环的生成焓、以及苯环的偶极矩有什么特征一点头绪都没有,更别提总结出“有OH基团的分子偶极矩通常偏大”这样的规律。
这样一来,即使AI在预训练阶段堆的数据再多,实际到数据稀缺的真实场景下表现还是不好。
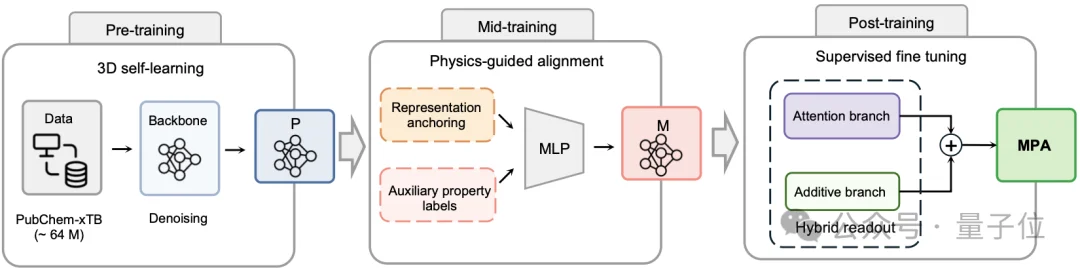
基于此,MPA特意增加了一层专门针对于“物理对齐”(physics-guided alignment)的训练,来弥补模型从分子结构的理论计算直接到下游实验任务的鸿沟。
这个过程因为模型需要在各种基本物理特性的概念对齐,因此“没有噪声”而且“容易大规模产生”的各种特性的第一性原理计算数据,就成为了首选,深度原理此前积累的大规模计算数据,这次也恰好用在了mid-training上。
第二点,就是针对实验预测任务设计的后训练“头”的创新了。
相比于沿用前中期那套现成的“头”,MPA在后训练阶段专门设计了一种叫Hybrid Readout的“混合头”。
它的核心,是给模型准备了两条路:一条自由的,一条受约束的。
之所以这样设计,是因为分子的性质本就分成两类:
一类是沸点、生物活性这类性质,跟分子大小无关,看的是分子整体的“气质”;
另一类是生成焓、燃烧焓、热容这种标准,分子越大数值越高,逻辑更像记账,整体等于各部分之和。
让一个“头”同时管好这两类,太难了,于是MPA干脆准备了两套机制。
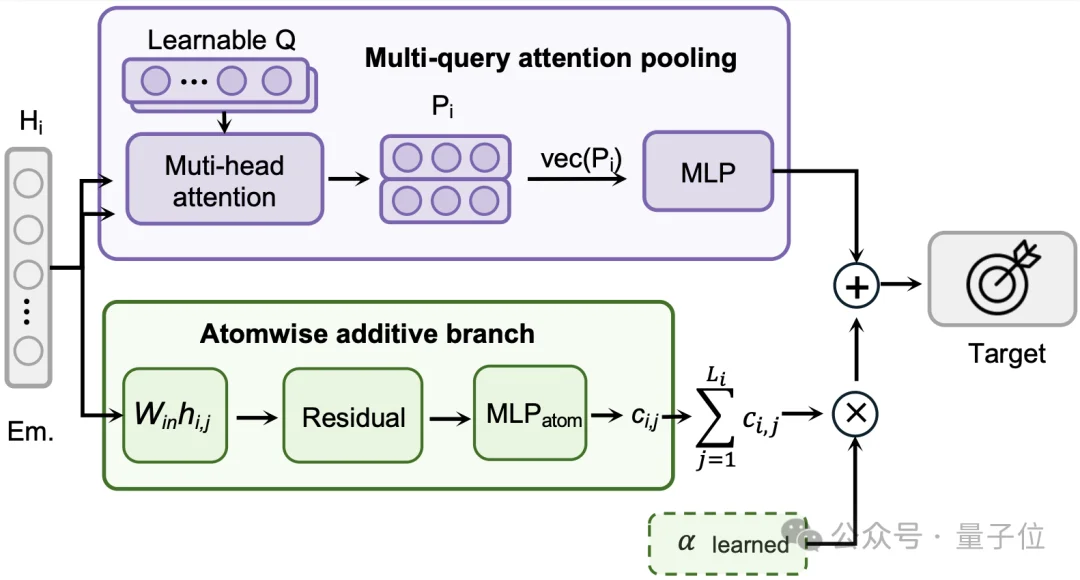
在注意力池化上,给模型足够的自由。
这条路不预设任何规则,让模型自己从全局打量分子。
它用注意力机制去问遍每一个原子,再把答案综合成一个判断,这种不设限的读法,正适合沸点、生物活性这类“气质”标准。
在原子加和上,对模型进行约束。这条路反过来,直接把一条物理规律硬塞进结构里:分子性质等于各原子贡献之和。
每个原子单独算出“我值多少”,再把所有原子加起来。对燃烧焓、热容这种本就该“逐原子累加”的标准来说,这等于直接把正确答案的形状告诉了模型,省得它从零摸索。
MPA用一个可训练参数α将二者结合起来,意思是模型自己学着决定——
眼下这个性质,该走自由的路还是约束的路,α越小,模型越倚重自由那条路;α越大,约束那条路的话语权越重。
那么,这样设计训练的模型实际效果如何呢?
MPA从两方面对模型效果进行了对比。
首先,为了证明LLM的三阶段训练方法在材料模型上同样有效,MPA和“没加料”的自己进行了对比:前面讲的中期训练和Hybrid Readout,到底有没有用?
对照组很干脆,同一个MPA预训练模型,一个直接拿去微调(什么物理直觉、什么混合头都不加),另一个走完整流程。
两者在40个真实实验性质上一一对比,绿色向外代表MPA更准,红色向内代表更差。
结果证明,在随机划分模式下,40个性质里有38个变好,平均误差降低14.0%;而在更难的骨架划分下,38个变好,平均误差降低14.6%。
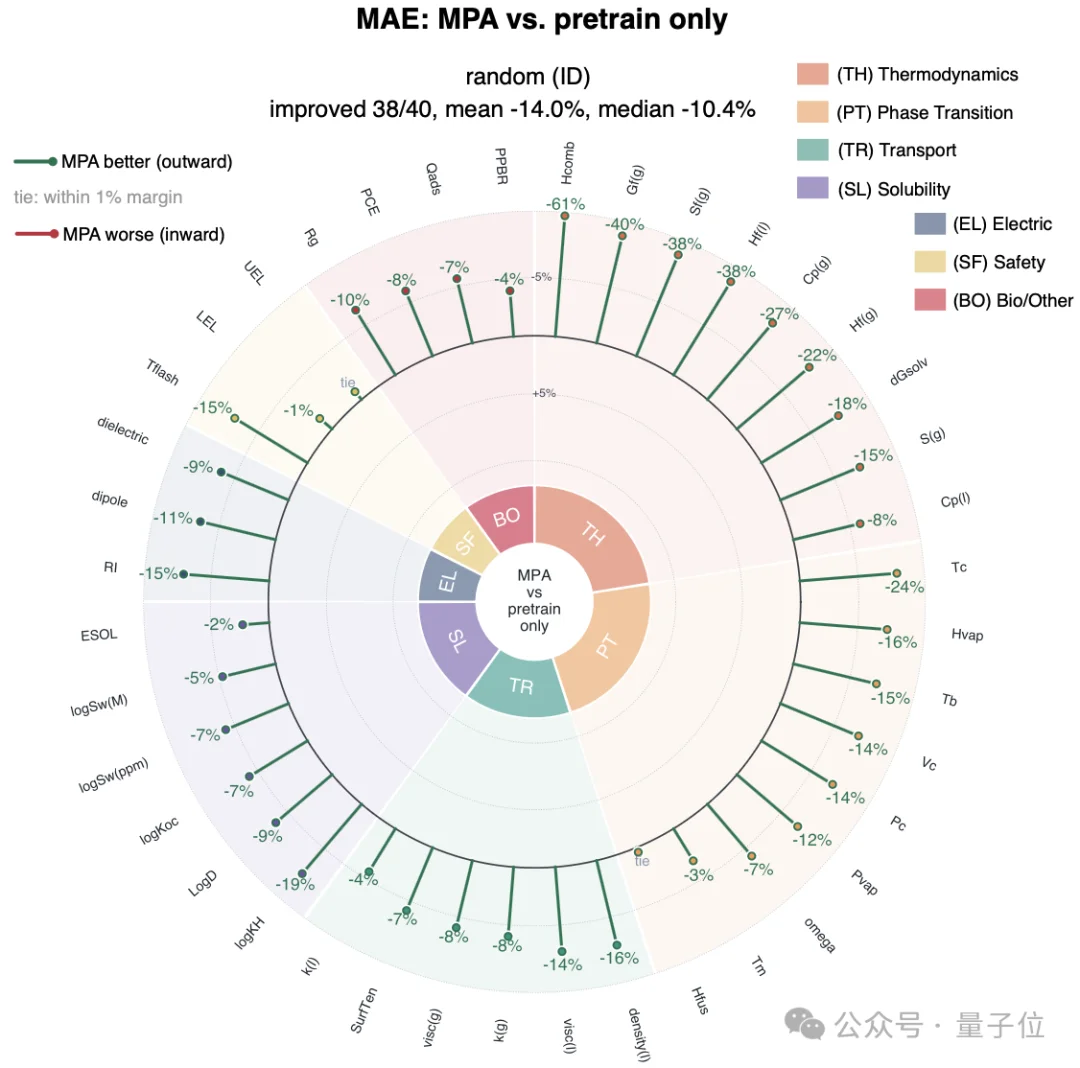
这里有个值得玩味的细节:骨架划分的提升,反而比随机划分更大。所谓骨架划分,就是让测试集里的材料空间在训练时压根没见过。
这才是真实科研里最常遇到的场景:你要预测的往往是个全新的结构。
模型在“没见过的骨架”上提升最明显,恰恰说明它学到的不是死记硬背的分子长相,而是真正可迁移的“物理直觉”(inductive bias)。
那么,整体模型设计到底有没有突破?
MPA同样和另外5个主流分子性质预测模型(ChemBERTa、ChemProp、Chemeleon、Uni-Mol2、Suiren)摆在一起进行了对比。
这里也同样分随机和骨架两种划分,每个性质上谁最准就给谁标一颗星。
结果发现,无论随机还是骨架划分,MPA的综合表现都是这一票模型里最强的,而它最大的优势,同样出现在骨架这种“分布漂移”的硬场景下,一举斩下40个实验物性中的35个SOTA。
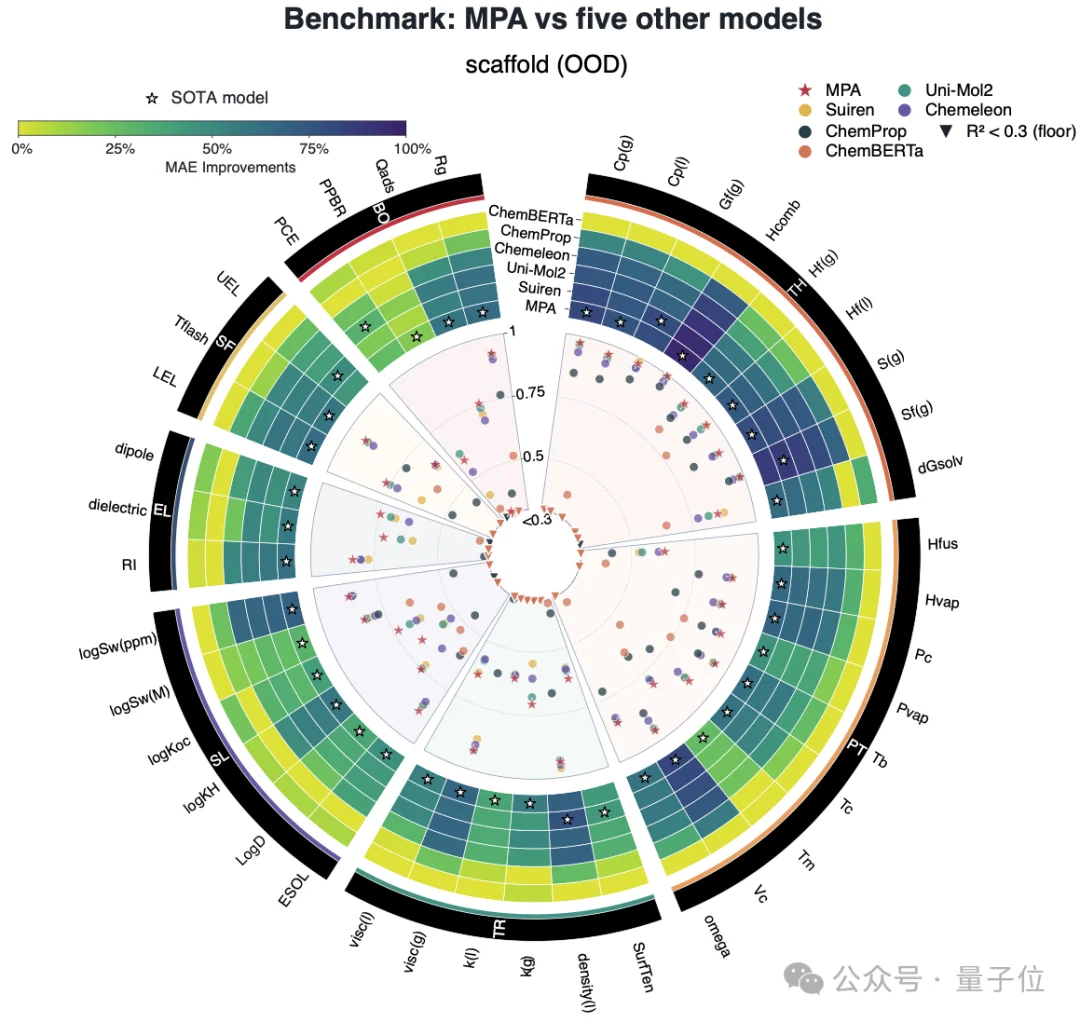
两类结果不约而同地指向同一个结论——
MPA最能打的地方,正是面对陌生结构、需要真实实验外推的时候,这也正好印证了前面所有铺垫的初衷。
让AI建立的,不是对材料长相的记忆,而是对真实材料的“物理直觉”。
MPA做了一件很有意思的事:它把材料基础模型的“适配问题”,重新定义成了“物理对齐问题”。
换句话说,与其不断针对不同任务打补丁、做适配,不如让模型直接对齐材料世界背后的物理规律。
为此,MPA提供了一条相当务实的技术路线:把第一性原理计算、高质量实验数据,以及面向具体任务的微调训练整合到同一个可扩展框架中,让模型既能学到理论知识,也能理解真实世界的数据反馈。
更重要的是,随着计算数据和实验数据持续增长,MPA提供了一种新的数据利用方式:这些数据不再只是一次性消耗品,而是能够不断沉淀为可复用的预测能力。
最终得到的,也不再是一堆彼此割裂、只能解决单一问题的小模型,而是具备更强泛化能力的材料基础模型。
MPA与当前主流的LLM训练模式的共振,说明多阶段训练和alignment等概念不止适用于AI“虚拟世界”,“物理世界”的模型也会因为真实测量结果背后的物理规律实现深度对齐而受益。
目前,MPA已经作为Skill之一,接入了深度原理的Agent产品。
对MPA性质预测能力和效果感兴趣的话,你可以直接上手试一试了:https://sciclaw.cn
MPA博客:https://blog.deepprinciple.com/introducing-materials-property-axiom/
MPA技术报告:https://www.deepprinciple.com/papers/mpa.pdf
文章来自于"量子位",作者 "允中"。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
