# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
想象一个再普通不过的工作场景:
你的电脑里存放着两份合同、一堆客户资料、几个项目文件夹,以及一份不知何时遗留的 .env 文件。你希望 AI 协助完成三项任务:排查潜在泄露的 API Key、对比合同差异并生成报告,以及自动生成一份审计日志。
如果调用云端大模型,这些任务自然不在话下。但隐患也显而易见:你需要将本地文件、客户隐私、目录结构甚至系统状态,全盘托付给第三方服务。对个人而言,这或许只是体验上的妥协;但对企业来说,这直接触及了安全、合规以及部署边界的红线。
Liquid AI 近期推出的 LocalCowork,正是直面这一矛盾的产物:单台笔记本,无需云端 API,数据绝不离机。凭借 67 个本地工具、13 个 MCP Servers,配合最新发布的 LFM2.5-8B-A1B 模型,它通过本地调用工具、解释结果以及可审计的工作流,解决了上述难题。
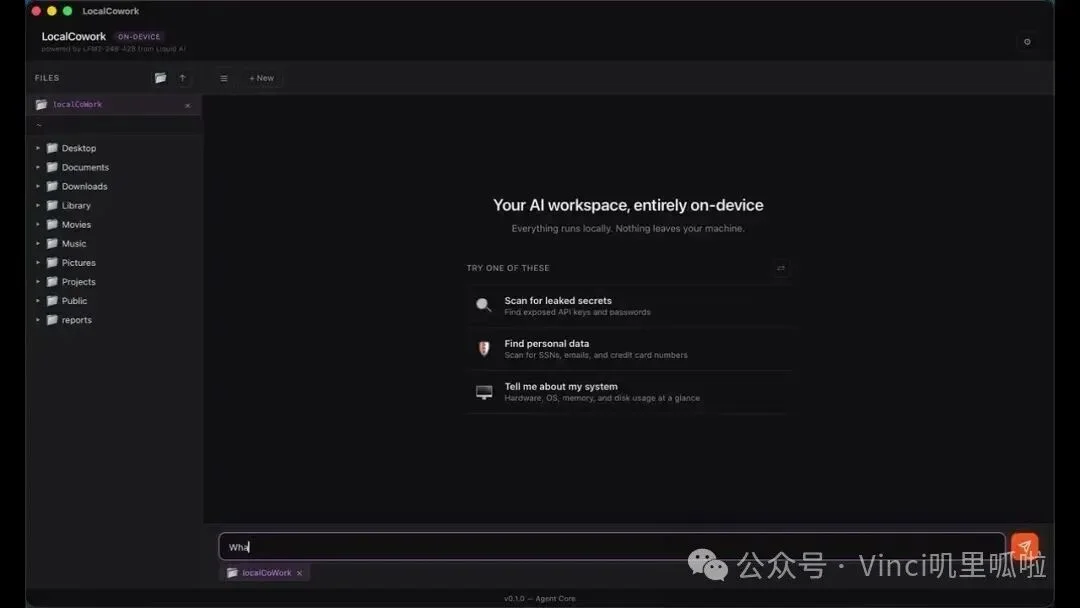
图:LocalCowork 界面,用本地模型调度工具完成私有工作流。
2026年,Liquid AI 或许不该仅仅被看作是又一家发布小模型的公司。
如果用国内读者更熟悉的语境来类比,它有些像“美国版的面壁智能”。过去两年,面壁智能的MiniCPM系列最深入人心的标签是端侧运行与强多模态——让小参数模型在手机上也能跑出惊艳的体验。乍看之下,Liquid AI 的 LFM2.5-8B-A1B 也踩在相似的叙事里:8B MoE 架构、1.5B 激活参数、128K 上下文、纯本地部署与工具调用。
面壁智能是源自清华的端侧模型独角兽,而 Liquid AI 的起点同样耀眼——孵化自顶级的 MIT CSAIL 实验室。此后,它走出了一条截然不同的路径:先是引入有别于纯 Transformer 暴力 Scaling 的全新架构,接着发布一系列 Foundation Models,随后迅速补齐开发者工具与端侧入口,最终切入 Shopify、奔驰等真实的商业级应用。
这正是 Liquid AI 故事的迷人之处。当整个行业习惯于在云端数据中心讨论 AI 的能力上限时,智能已经悄然向边缘渗透。当 AI 真正进入手机、PC、汽车、机器人和企业内网,核心命题就变成了:模型该如何适应真实的设备算力、隐私边界与业务流程? Liquid AI 过去几年的战略选择,几乎全是围绕这一底层变化展开的。
Liquid AI 的故事始于 2023 年底。
彼时,大模型行业的共识已然固化:GPT-4 验证了 Scaling Law 的统治力,资本、算力和顶尖人才都在向更大的集群与更长的训练周期聚拢。牌桌上的玩家们只关心谁能抢到更多 GPU,谁能训出更大的模型。
Liquid AI 却选择切入另一个盲区:如果 AI 终将落地于真实的物理世界与企业内网,我们的模型难道还要继续只为数据中心而设计吗?
这家公司的名字“Liquid”,源自创始团队在 MIT 的核心研究——液态神经网络(Liquid Neural Network)。这是一种极具“动态性”的架构,当模型面对连续变化的信号与环境时,其内部状态能够实时自适应调整。这种特性天然契合自动驾驶、机器人、传感器序列等真实世界场景。因此,Liquid AI 从一开始就将内存、延迟、能耗、硬件适配与可解释性置于核心位置。
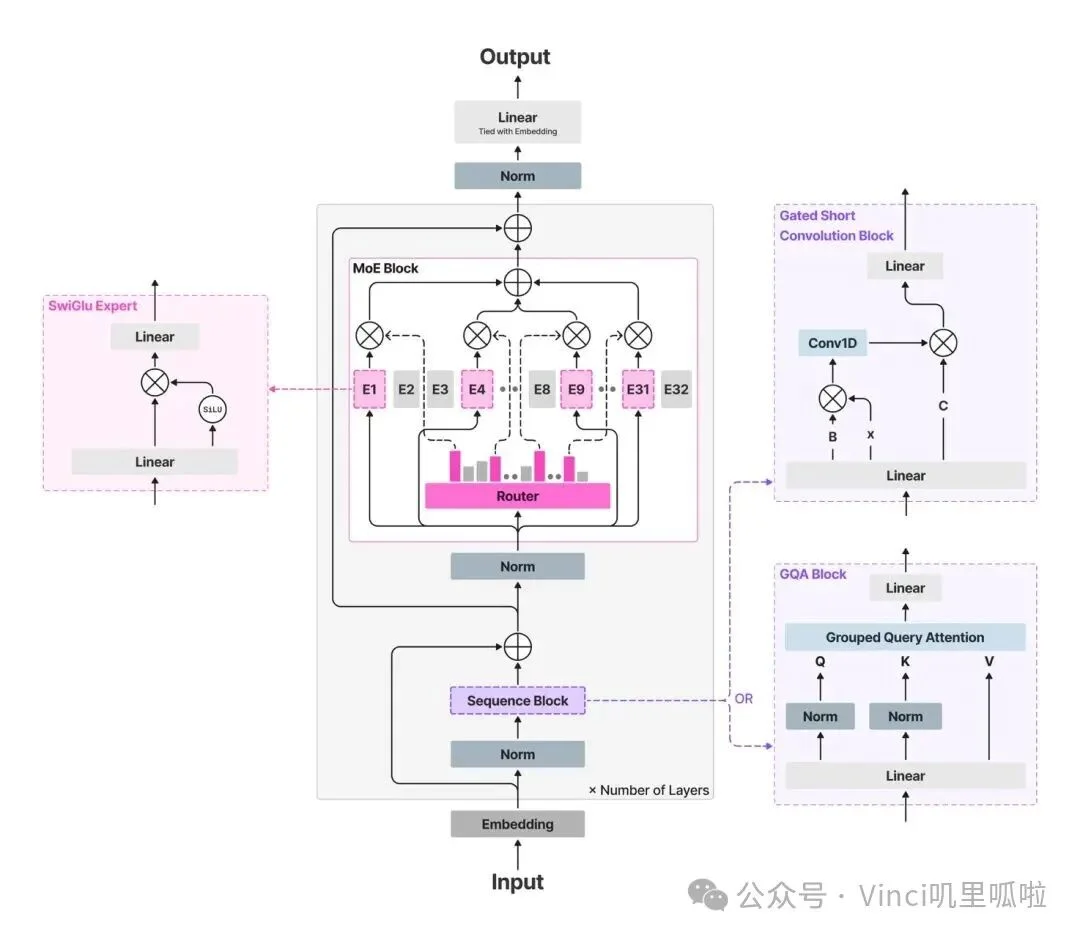
图: LFM 架构。
彼时的 Liquid AI 没有卷入“谁来训练下一个万亿参数 Transformer”的军备竞赛,而是沿着动力学系统和信号处理的底层研究,重新思考基础模型的形态。
这条路充满传播优势,却也背负着极高的信任成本。优势在于差异化足够锐利——在人人争抢“最大模型”的时代,它独占了“最高效架构”的叙事;而成本在于,外界不可避免会质疑:模型在哪?评测在哪?实验室里的论文,真的能转化为工业级产品吗?
2023 年 12 月,Liquid AI 宣布完成 4660 万美元种子轮融资。值得玩味的是它的投资人阵容:除了 OSS Capital、Samsung Next,还赫然出现了 Shopify 创始人 Tobias Lutke 和 Notion 联合创始人 Chris Prucha。
这释放了一个强烈的信号:Liquid AI 的野心不仅在学术界,它要将高效模型生根于真实的商业系统与设备生态中。
2024 年 9 月,Liquid AI 发布了第一代 Liquid Foundation Models (LFMs)。当时的外部环境正处于微妙的转折期:大模型能力固然在涨,但企业算起了经济账——云端 API 的调用成本、网络延迟以及私有化部署的安全顾虑开始凸显。AI PC、手机 NPU 与车载 AI 的普及,让离线运行成为刚需。
第一代 LFM 包含了 1.3B Dense、3.1B Dense 和 40.3B MoE。它们向外界展示更优的 性能/尺寸 权衡、更低的内存占用,以及面向 NVIDIA、AMD、高通、苹果等异构硬件的优化潜力。
这一步,让 Liquid AI 从“贩卖新架构概念”正式蜕变为“交付可用模型”的企业。社区关于端侧AI的话题,也开始从概念争论,进入了真刀真枪的可行性与能力边界验证。
进入 2025 年,端侧 AI 渐渐告别边缘地位。面壁的 MiniCPM 证明了小参数的多模态能力;微软 Phi 将推理无缝接入 Windows 与 Copilot+ PC;Google Gemini Nano 深入 Android 系统底层。Liquid AI 也在 2024 年底拿下了 AMD 领投的大额融资,深度绑定芯片与推理栈生态。
此时行业也逐渐觉醒,训练出小模型只是入场券,分发、运行权限与生态闭环,才是决定其能否存活的关键。
2025 年 7 月,Liquid AI 推出 LFM2,主打混合架构与 CPU 上极速的 Decode/Prefill 效率,并释出了 350M、700M、1.2B 这类极度端侧友好的权重。
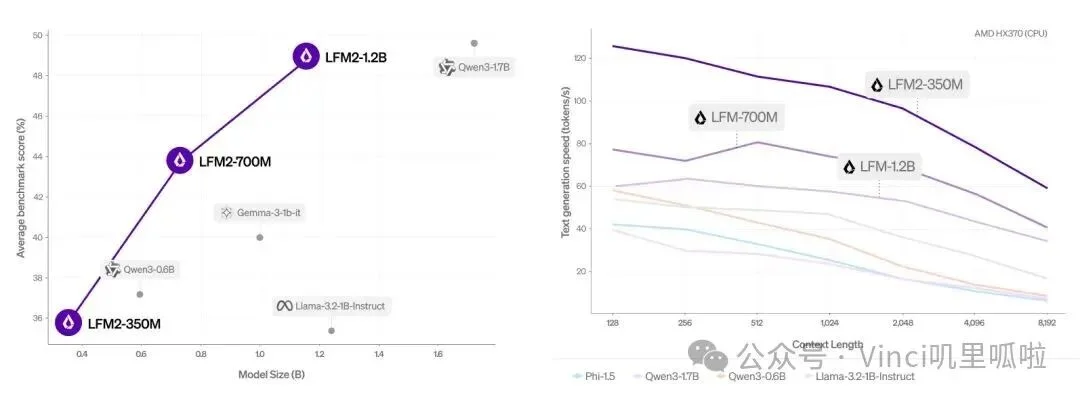
图:LFM2 端侧模型的速度与效率。
同月,两大基础设施的发布,将Liquid AI产品化向前推进了一大步:
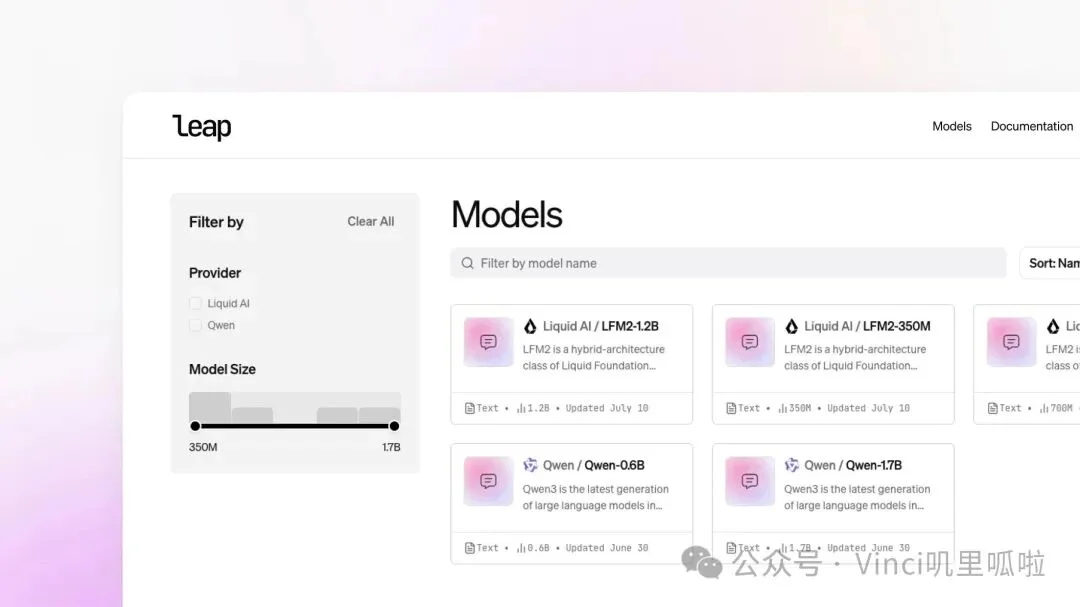
图:LEAP 试图把模型发现、测试、定制和部署串成端侧 AI 工作流。
这是 Liquid AI 的关键拐点:它不再仅仅是一个发布模型的机构,而是演变成了一个提供端侧部署解决方案的平台。
从 2025 下半年到 2026 年,Liquid AI 迎来了爆发式的产品矩阵扩张。除了文本模型,它迅速补齐了视觉语言(VL)、音频、MoE、Embedding、RAG、工具调用(Tool Use)等细分方向。LFM2-VL、LFM2.5-1.2B-Thinking、LFM2-24B-A2B 等型号相继亮相,形成了一个庞大的“端侧模型货架”。
这背后的商业逻辑极其直白:没有任何一个模型能够吞噬所有场景。手机的离线翻译、车机的语音助手、电商搜索的极速推荐,对参数大小、延迟限制和多模态能力的要求截然不同。
在这里,它与面壁智能的差异开始显现:面壁的故事更加聚焦——手机端的极致多模态;而 Liquid AI 铺设了一条极长的战线——从底层架构、模型族群,一路贯穿到部署平台与垂直行业。
2026 年前后,Liquid AI 终于在应用层交出了答卷。它跳出了写诗、翻译的常规 Demo,直接切入了高价值的业务腹地:

图:Mercedes-Benz 与 Liquid AI 合作,将嵌入式智能带入车载场景。

图:Liquid AI 与 Shopify 合作,把高效模型用于核心 commerce workflow。
这三个切面,勾勒出了 Liquid AI 真正的靶心:那些云端千亿大模型进不去、跑不快、不合规的广阔“缝隙”。
作为最新力作,LFM2.5-8B-A1B 将这条路线推向了新的高度。总参数 8.3B,激活参数仅 1.5B,训练数据量却高达 38T Tokens(与 DeepSeek V4 系列处于同一量级);支持 128K 超长上下文,专为工具调用与 Agent 工作流优化,且全面拥抱 llama.cpp、vLLM 等开源生态。
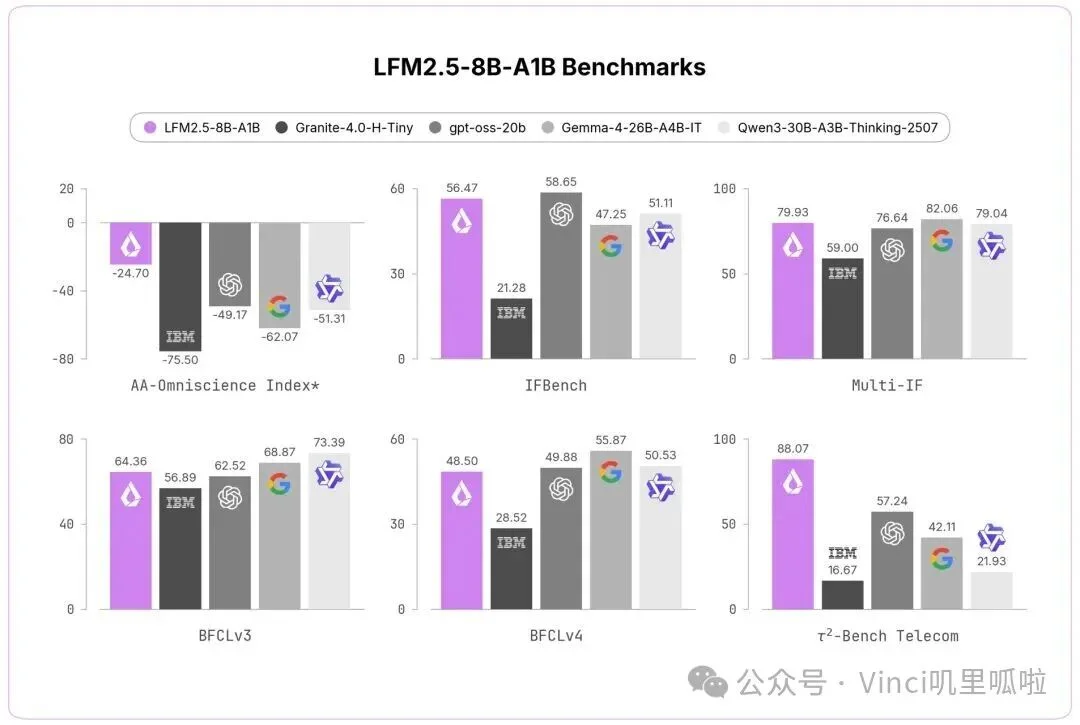
图:LFM2.5-8B-A1B benchmark,强调端侧工具调用。
它的发布,让社区的关注点从空泛的“参数规模”落到了实处:消费级 GPU 能否流畅运行?量化后是否会破坏 MoE 路由的稳定性?长上下文是否会出现注意力漂移?这说明,开发者已经开始用衡量生产力工具的标准(Tokens/s、内存占用、量化损耗)来审视它。
这个模型不必被神化,它的历史定位更像是一个极具价值的阶段性样本:它证明了在消费级硬件的算力与延迟边界内,本地 Agent、超长上下文与高难度工具调用,已经成为现实。
所以,Liquid AI 究竟是不是美国版的“面壁智能”?
答案是:是,也不是。
“是”的一面在于,它们并肩站立在同一股不可逆转的浪潮之巅。它们都在用行动宣告:模型的价值不只由参数量决定。在严苛的成本与算力约束下,提供有效的智能,同样是一种价值。
但如果我们尝试自顶向下地理解端侧机器学习系统,就会发现 Liquid AI 的路线是在打造一套硬件原生的基础模型技术栈。它始于 MIT 实验室里的学术狂想,穿越了 LFM 的技术自证与平台化阵痛,最终在汽车与电商的工业齿轮中咬合。它尝试证明,基础模型需要被具体的设备、隐私边界和产业场景重新重塑。
而这场关于端侧 AI 的探索远未盖棺定论。Liquid AI 仍需面对漫长的考验:新架构的护城河到底有多深?资源受限场景下的 Tool Calling 能否保持绝对的可靠?更重要的是,微软 Phi、Google Gemini Nano 与苹果 Apple Intelligence 体系背后都有操作系统、芯片和分发入口加持,Liquid AI 必须证明自己在这些平台级玩家的夹击下,仍然能靠架构效率、部署工具链和行业场景占住位置。
但至少,它撕开了一个极具想象力的切口。
过去两年的 AI 叙事,聚光灯始终打在云端大模型的能力穹顶上;而接下来的时代暗流,将属于智能如何挣脱数据中心的引力,下沉到手机、PC、汽车、机器人与每一个本地工作流之中。
无论 Liquid AI 的结果如何,都将是这部宏大史诗中的重要一章。
文章来自于微信公众号 "Vinci叽里呱啦",作者 "Vinci叽里呱啦"


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
