# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Cowork 在 Claude 带火后,大厂都在做,企业也早在用。但通用就是通用,碰上房地产这种数据非标、容错为零的硬骨头,全部露怯。跑通这块的,反而是一匹国产黑马。
你让最新通用 AI 帮你算一块上海地块的动态财务测算,它连「建安成本」怎么算对都不知道。
这就是 2026 年 AI 圈一个有点尴尬的真相。
这一年,Agent 赛道彻底炸了:Claude Code 上线 6 个月就冲到 10 亿美元年化收入运行率,OpenAI Codex 让 AI 直接上手操作电脑,国内字节扣子、阿里千问、百度千帆等也在拼命把「搜索—决策—支付—履约」串成闭环。
5 月 8 日,网信办、发改委、工信部联合发文,第一次从国家层面给智能体定了调。
可热闹归热闹,细看一圈你会发现:这些当红 Agent,要么偏编程,要么偏通用——写代码、排日程、做 PPT 没问题,可一头扎进某个垂直行业那些复杂到令人头疼的专业场景,立刻露怯。
道理很简单——通用大模型,没有行业数据。
也正因如此,2026 年最聪明的钱正在集体转向垂直:YC 放话垂直 Agent 的机会可能比整个 SaaS 大十倍,a16z 干脆发报告宣告「AI 正在吞噬垂直 SaaS」。
逻辑很简单——过去卖的是软件席位,现在要卖的是「干完的活」。
那么,垂直行业的 Agent 到底该怎么做?
5 月 27 日,上海静安香格里拉,一场千人大会给出了一个相当硬核的答案。

说到底,这一次,AI 重写的不只是某个工具,更是我们工作的方式本身。
先说一个残酷的事实:房地产,可能是 AI 最难啃的骨头之一。
难在哪?
这个行业的「基因」里,写着四道坎:
把一个通用 Agent 丢进这样的行业「帮忙」,结局大概率是:AI 兴冲冲交出一份报告,1、2、3、4、5 大章节看着工整,内容却全错——它写的根本不是行业做土地可研的方式,而是 AI 自己「想象」出来的、一份研究报告「该有的样子」。
这就是垂直场景里最致命的幻觉。
而要治它,光有大模型远远不够。
深度智联的思路,是反着来的:
先用独家数据清洗算法,只喂经过验证的高可信知识;
再引入知识图谱做「事实锚定」,强制 AI 基于既定事实输出;
又把上万条行业规则代码化,让模型真正具备地产业务的推演能力;
最后做到可溯源——每一条建议,都能追到具体的政策或数据出处。
一句话:让 AI 不敢瞎编,也编不出来。
深度智联的底气,来自一个别人很难复制的底层资产——它自建的不动产专属数据库。
先看一组数字:这座沉淀了 20 年的数据库,覆盖 400+ 城市、322 万+ 地块、44.5 万+ 二手房楼盘、90 万+ 企业主体,是业内罕见的全量、实时、结构化不动产数据资产。
但过去,这些数据大多停留在「查询式」使用——一份 15 页的土拍 PDF 里没被提取的内容,长期沉睡。
DeepLinkRE-LLM 要做的,就是把它们全部激活。
这个房地产垂直专属大模型,搭了四层底座:
太抽象?
看一个真实任务怎么跑通:当你说「做上海某地块的拿地可研」,AI 不会瞎查——它先调「问数」Skill 去自有数据库里精准拉这个板块的土地、新房、二手房数据(板块级找不到,自动扩到区域级),再套用专家验证过的《地块投资可行性研究》框架做结构化分析,最后由 Agent 工程力把数据、测算、研判、风险清单,组装成一份能直接进投决会的报告。
数据、知识、专家、执行,四层各司其职。
最有说服力的案例,来自发布会现场:AI 全程参与的《中国房地产年鉴》30 年特刊,50 万字底稿,仅用数小时自动交付,经编审专家集体审议,数据准确性与研判专业性获得高度评价。
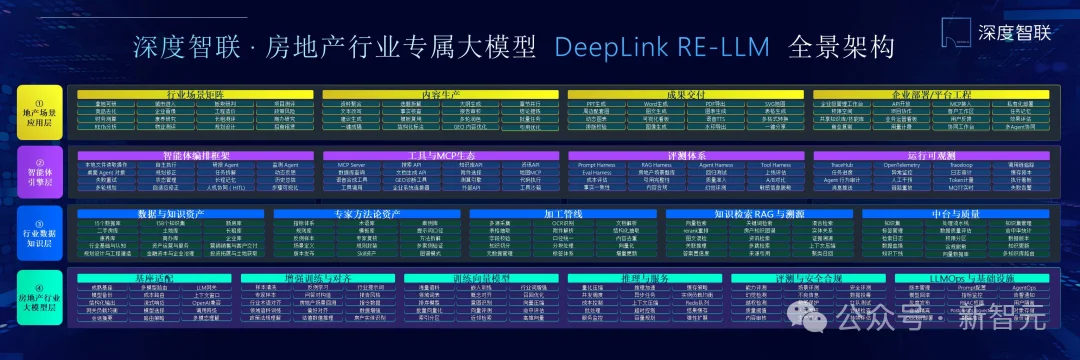
DeepLinkRE-LLM 全景架构

《中国房地产年鉴》30 年特刊 AI 底稿
如果说 DeepLinkRE-LLM 是引擎,那 CoWork 就是那辆开上路的车。
深度智联对它的定位非常明确:不是让员工「使用」AI,而是让员工和 AI「一起工作」。
听起来微妙,落到实处却是天壤之别。
传统 AI 工具是「你问我答」的被动模式:你得想好问什么、怎么问,问完还得自己把散落的信息拼成成果。
CoWork 是任务驱动——你只丢一个业务目标(「完成 XX 地块的市场研究」「做 XX 项目的投资可研」),平台自动理解意图、拆解步骤、调取数据、分析推理、提炼结论,在关键节点与人确认,最终闭环交付。
更「地道」的是,CoWork 能听懂地产黑话。
当你说「控规」「强排」「一房一价」「板块」,它不会一脸懵——这些概念早被深度训练过;
它甚至知道一个任务背后「我需要哪些数据撑腰」:让它做竞品监测,它会自动去找土地、新房、二手房数据,先找板块级、找不到就扩到区域级。
这背后,是深度智联团队多年沉淀的思考框架,被内置进了 AI 的推理逻辑。
通用 AI 把你当陌生人;CoWork,把自己当成你团队里那个「最懂行的老同事」。
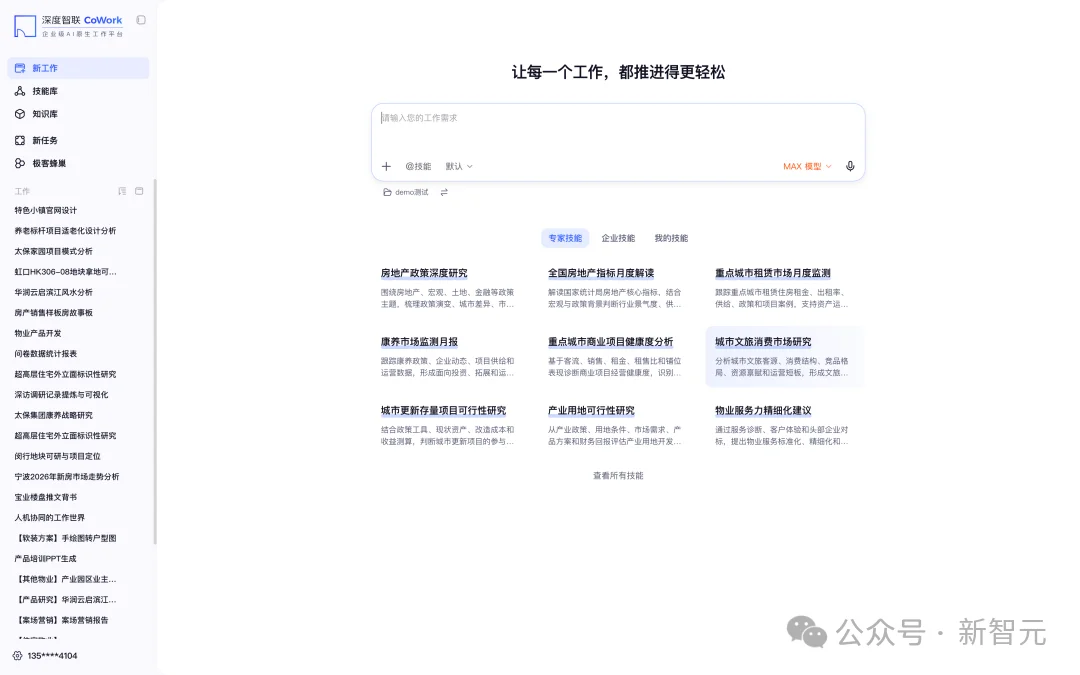
CoWork 工作台界面截图
给 CoWork 扔了一句「帮我做个特色小镇运营商的官网,要有氛围感,体现运营成功案例和核心方法论,其他模块你自己发挥」——没给设计稿,没给素材包。
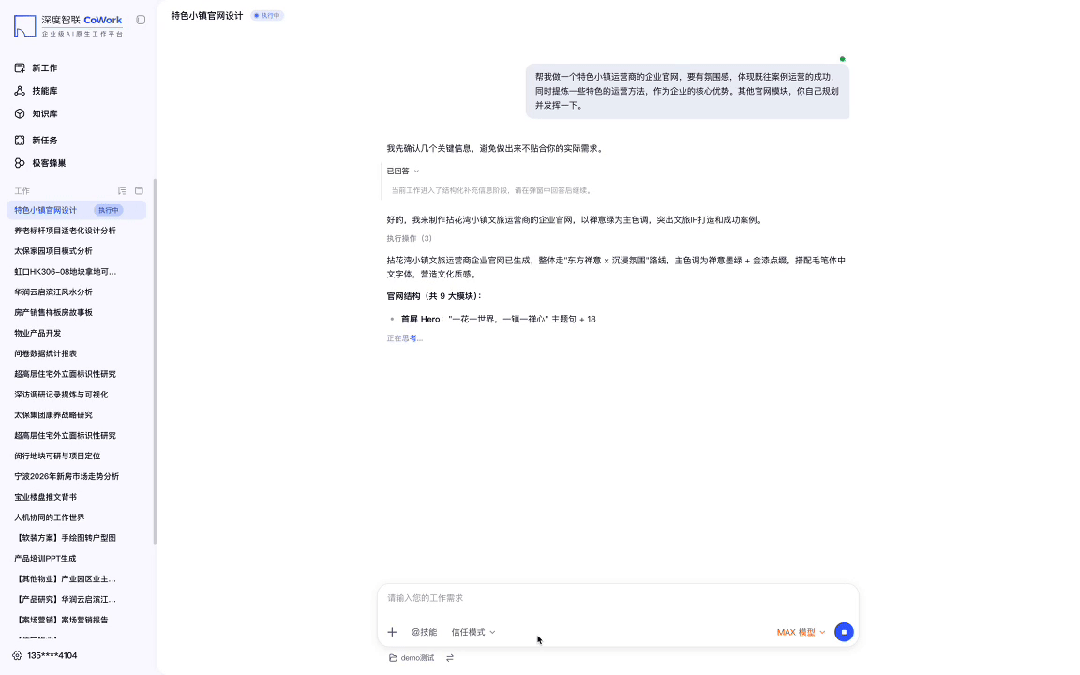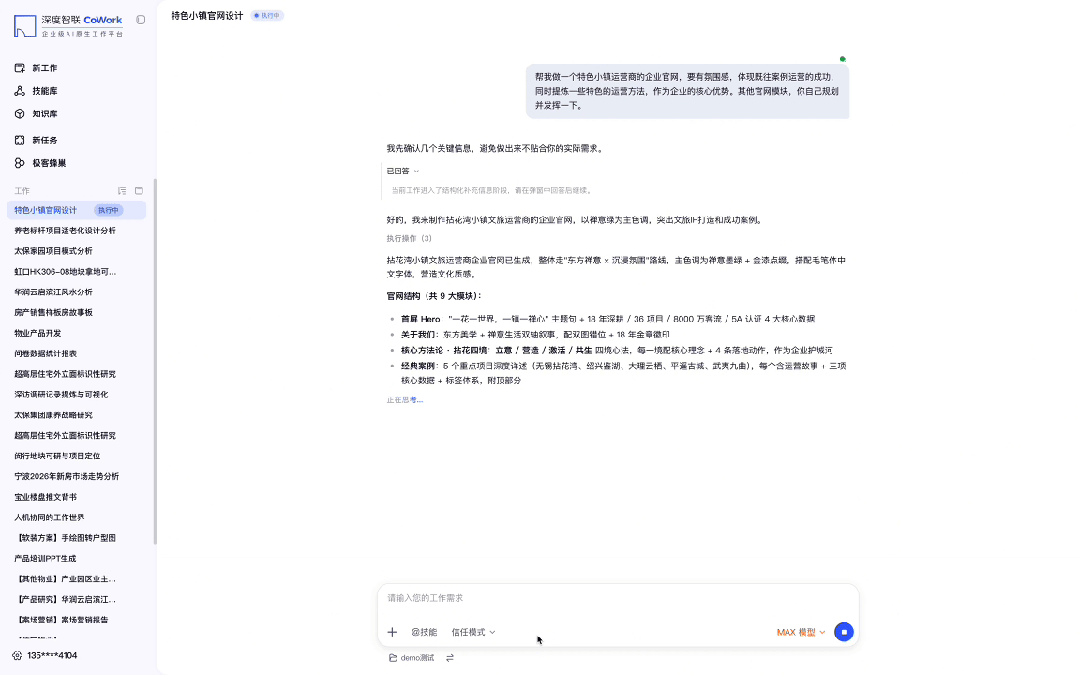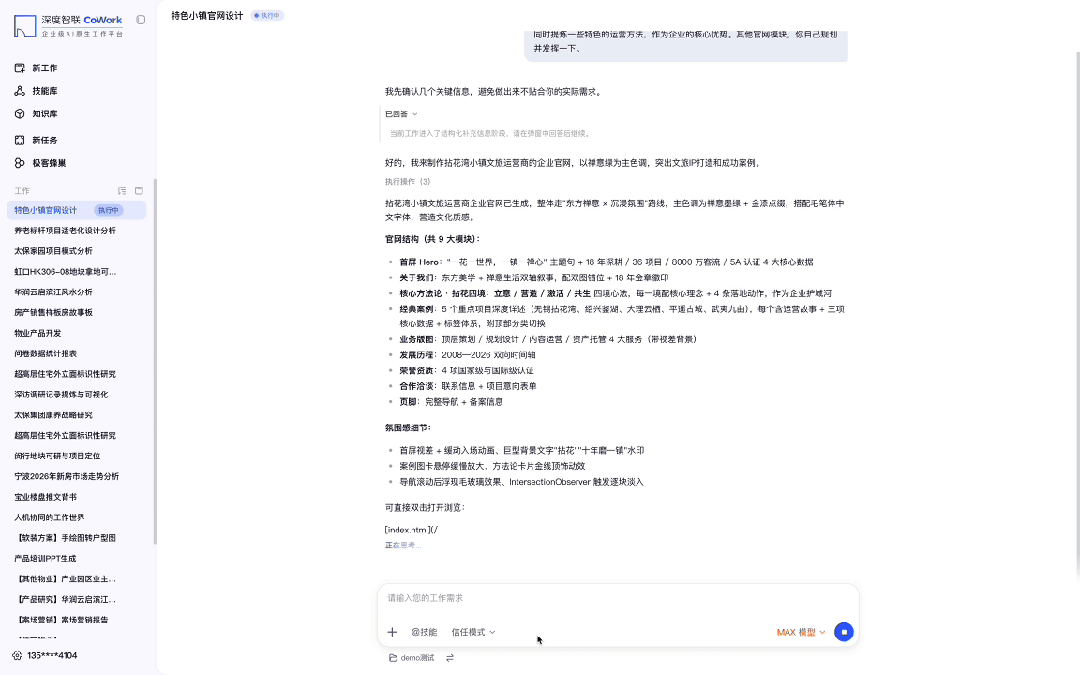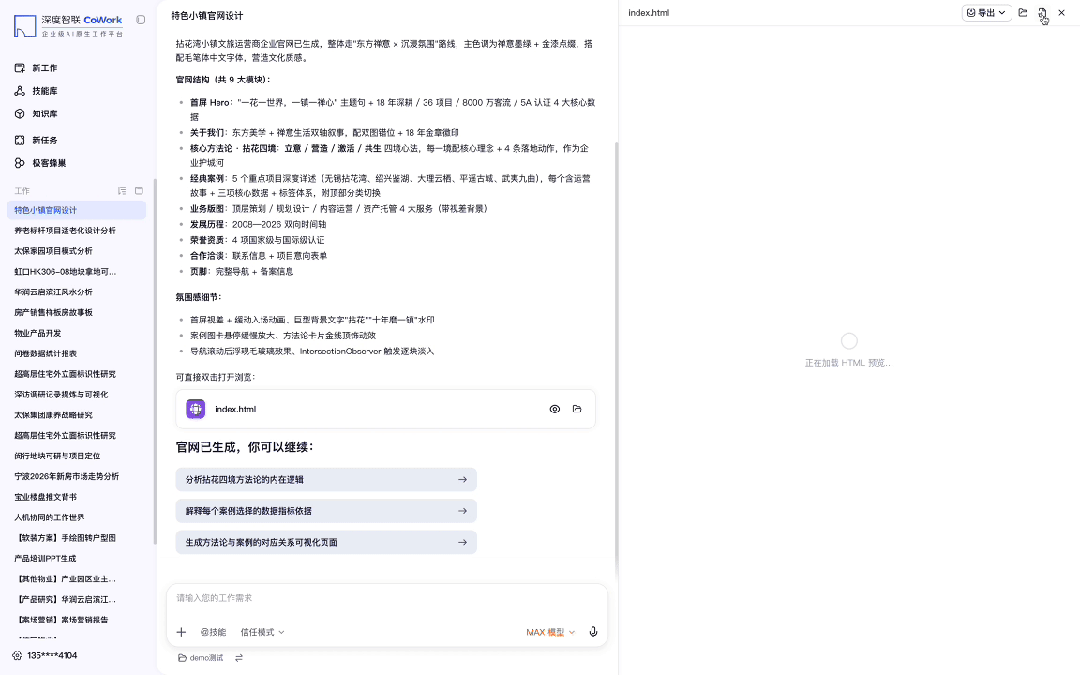
几分钟后直接吐出一个完整官网:禅意山水大图铺满首屏,品牌 Slogan、四组核心数据、六个导航板块全部自动规划到位。
视觉调性和信息架构都够直接拿去提案。

实战质量到底如何?
发布会前后几天,深度智联密集组织了多场客户培训——住宅、营销、投资、物业、长租、康养,不同业态一一上手。
现场反馈形成了一个共识:CoWork 的产出,已经能满足日常工作需求。
但质量并非一刀切。
我们按照成熟度分成三档来看:
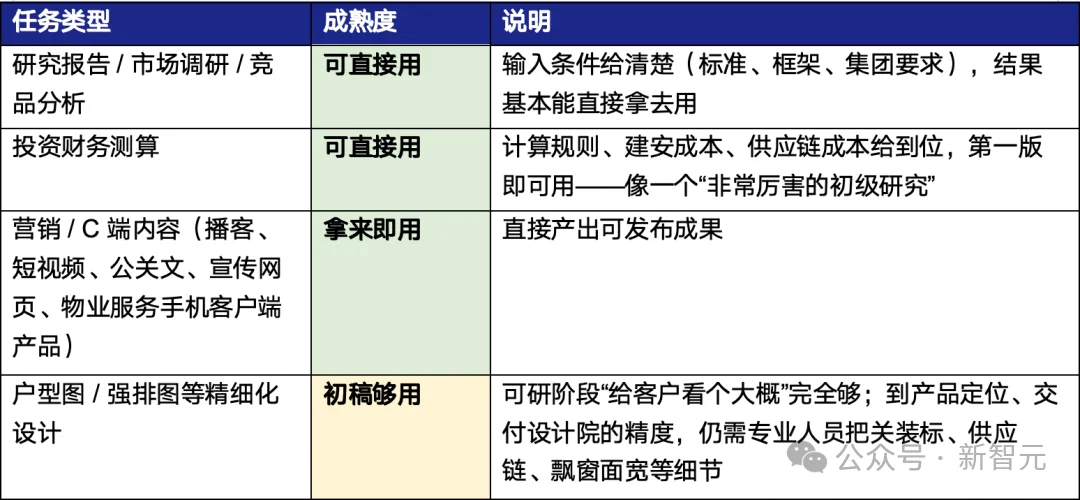
最狠的一句反馈,来自一位 TOP 房企领导。看到 CoWork 输出的报告后,他直言:
比我们花 20 万、30 万外包给咨询公司、研讨一周交上来的,写得还深。
敢把「哪里还不够」明明白白讲出来,恰恰是这套产品最让人信的地方。
CoWork 多模态工作成果展现截图
如果只是「干活快了」,CoWork 不过是个高级工具。
真正让它有战略价值的,是它在重构企业的组织能力。
传统地产企业有个老大难:核心能力高度绑在「明星员工」身上。
一个资深投研总监转岗,带走的不只是人,还有他脑子里那套分析逻辑和行业经验。
CoWork 的 Skill 体系 + 企业级知识管理,本质上就是在解这道题——把个人经验,变成组织资产。
企业可以在平台上统一管理组织架构、员工账号、知识库和技能库;
优秀员工的方法论被提炼成 Skill,全公司复用;
一个人协同 AI 并行推进多类复杂任务,一个部门的能力可以覆盖全组织。
经验不再随人走,而是沉淀成可共享、可传承、可迭代的数字资产。
对管理层,CoWork 的 EMC 管理端还给了另一层价值:AI 资产的「可量化、可治理」。
企业到底用了多少 AI、哪些部门在用、知识库和技能库复用率如何——都能被追踪评估。
从组织形态看,这是一场静悄悄的进化:员工从「执行者」变成「任务编排者」,协作单元从「人 + 人」升级为「人 + 多个 AI 线程」。
用一句地产人能秒懂的话说:从「经验组织」,向「能力组织」跃迁。
EMC 企业管理后台
数据安全,怎么保障?
对央国企、城投平台这类核心客户而言,数据安全是合作的底线。
深度智联在合规层面给出明确承诺:客户数据仅服务于客户自身业务,不会用于模型训练或对外使用,企业自建的 Skill 与知识沉淀也都归企业所有。
对安全要求更高的客户,还可选择本地化私有部署,数据全程在企业内部流转。
回到开头那个大问题:Agent 时代,垂直行业的机会到底在哪?
CoWork 给的答案相当清晰——模数共振:行业模型 + 企业数据 = 真正能落地的 AI 生产力。
通用 Agent 再强,也解决不了一个根本问题:它不懂你的行业——它没有你的数据,不理解你的术语,不知道你的工作流长什么样。
当 AI 从「会聊天」进化到「能干活」,胜负手就不再是模型参数的大小,而是谁能在垂直场景里跑通「数据→知识→专家→执行」的完整闭环。
地产已经证明了这条路走得通。
而深度智联更大的野心是:把这套「垂直行业 Agent」的方法论,变成其他复杂行业都能复制的样本。
正如三部委在《智能体规范应用与创新发展实施意见》中的判断:2026 年是智能体的试点爆发期,垂直场景的专业智能体将迎来规模化落地。
不动产行业的下一个分水岭,不在于「谁用了 AI」,而在于「谁重写了工作」。
CoWork 的发布,或许正是这道分水岭上,第一块路标。
参考资料:
房地产迈入「模数共振」新阶段,深度智联发布行业大模型及三大核心产品
文章来自于"新智元",作者 "新智元"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
