# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
不是问题的问题。
当地时间 6 月 2 日,Perplexity 在 Computex 2026 的 Intel 主题演讲上,做了一个很多人没太在意、但可能改变整个 AI 应用行业走向的演示。
不是新模型,不是更快的搜索,而是一套「任务路由」系统。
简单来说,就是 AI 自己决定哪些事在你的电脑上做,哪些事扔给云端——而不是让用户去选。
CEO Aravind Srinivas 和 Intel CEO Lip-Bu Tan 站在台上,在一台跑着 Intel Core Ultra Series 3 芯片的设备上演示了全程。本地模型负责判断,云端模型负责执行复杂任务,两者之间的调度对用户完全透明。
这件事听起来像是一个工程细节,但背后藏着一个更大的问题:AI 应用的架构之战,已经从「谁的模型更强」,悄悄转向了「谁能把资源调度得更聪明」。
本地 VS 云端
过去两年,AI 行业走了一条很直接的路:算力不够?加算力。模型不够大?加参数。隐私有顾虑?那就……先搁置。
但企业用户不会永远搁置隐私问题。
一个典型的场景是:你让 AI 助手帮你整理会议记录,里面可能有未公开的财务数据、客户信息、合同条款。这些东西传到云端,法务部门就会来敲门。但如果只用本地模型处理,算力撑不住,效果又打折扣。
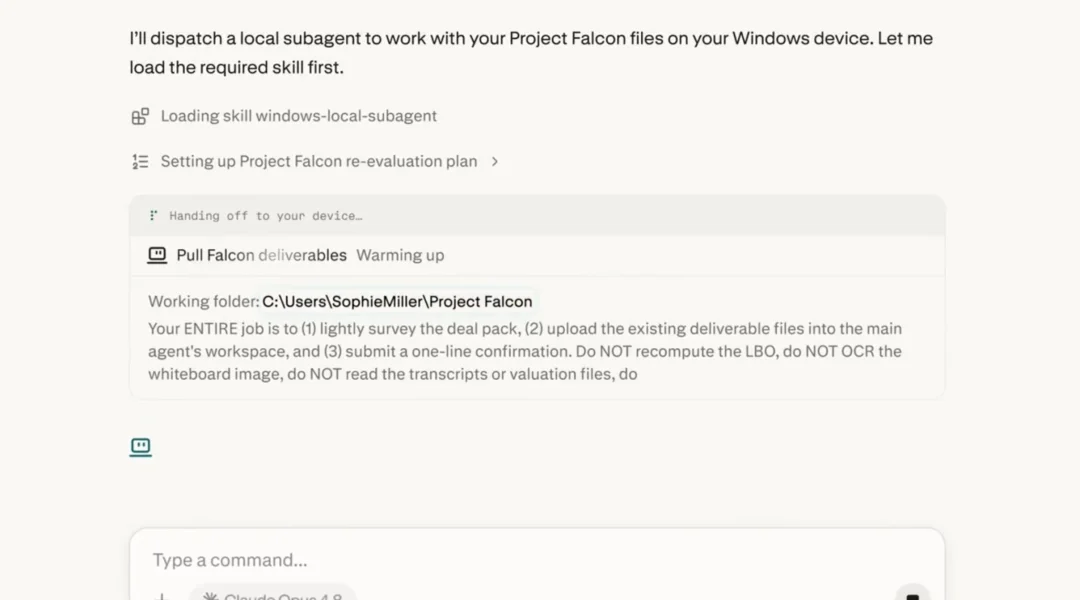
Perplexity 在跑任务时关注到了数据隐私问题|图片来源:Perplexity
这就是 Perplexity 混合推理(Hybrid Agentic Inference)试图解开的死结。
它的核心逻辑不复杂——让本地模型先做「侦察员」,判断每一个子任务的敏感程度和复杂度,然后决定是留在本地处理,还是打包发给云端的前沿模型。用户不需要做任何选择,系统自动完成路由。
据技术分析,任务分类发生在 API 层。「这是 5 个 token 的问答,还是 500 个 token 的代码生成请求?」——本地模型用 4 位量化处理前者,内存占用减少约 75%;云端模型接管后者,但在传输前会做确定性哈希处理,防止原始数据泄漏。
理论上,边缘设备的往返延迟可以因此降低 60%。
当然,「理论上」这三个字很重要。
从「AI 搜索」到任务路由
如果只看今天的演示,容易误以为这是 Perplexity 的一次突然发力。但把时间线拉长,会发现这家公司在过去半年里做的每一步,都在为这个方向铺路。
今年 3 月,Perplexity 与 CoreWeave 达成战略合作,用专属的 NVIDIA GB200 NVL72 集群跑推理工作负载,把云端算力基础设施夯实。5 月中旬,它推出了 Mac 应用,把 Personal Computer 功能开放给 Pro 和 Enterprise 用户——之前只有 Max 用户才能用。这一步很关键,相当于在正式推出混合推理之前,先把用户教育做了一遍,让大家习惯「AI 在本地跑」这件事。
Perplexity 任务路由的演示视频|图片来源:Perlexity
到今天的 Computex 演示,混合推理功能还没有正式上线,官方说会在 7 月推出。但选在这个时间点、这个舞台亮相,用意很清楚——英特尔需要一个真实的 AI PC 用例,Perplexity 需要一个比自家官网更大的曝光窗口,双方一拍即合。
与此同时,Perplexity 的商业版图也在加速扩张。从 18 亿美元估值融资 1 亿美元,到两个月后以 200 亿美元估值完成 2 亿美元融资,自成立三年来累计融资已达 15 亿美元。钱还在持续进来,说明投资人押注的不只是搜索,而是整个 AI 代理基础设施的叙事。
聪明的不是模型,是调度器
VentureBeat 的分析抓到了这件事的本质。它指出,Perplexity 这套系统的关键主张,不是「本地可以跑模型」——这件事已经有几十种工具能做到了。真正的差异化在于,Perplexity 的系统自己做路由决策,逐个任务,不需要用户提前配置。
这是一个视角的根本转变。
以前,「本地 vs 云端」是一个用户层面的选择题。你要么信任云端,要么忍受本地模型的能力上限。Perplexity 想把这道选择题从用户面前拿走,变成系统内部的一个工程问题。
但这恰恰是挑战最大的地方。
要让编排器在生产环境中可靠运行,它需要同时做对几件事:准确评估每个子任务的复杂程度,理解涉及数据的敏感级别,了解用户本地硬件的实时性能状态,还要管理跨设备-云端的任务状态同步。任何一个环节判断失误,轻则输出质量下降,重则把不该上云的数据送出去了。
MacRumors 社区里有用户的担忧更直接——「这是让 AI 出现幻觉然后删文件的好办法。」这话听起来像段子,但触到了一个真实的焦虑:当 AI 代理获得了更多系统权限,并且还要自主做路由决策的时候,「可解释性」和「可审计性」变得比任何时候都更重要。
Perplexity 任务完成提示页面|图片来源:Perplexity
企业安全专家也提出了另一层风险——如果云端模型的调用链没有经过 SOC 2 等级的验证,混合架构本身可能反而引入新的供应链安全漏洞。隐私问题还没解决,安全问题已经跟上来了。
值得一提的是,Perplexity 还在另一个战场上承受压力。
截至今年 5 月底,已有包括 CNN、纽约时报、News Corp 在内的九家媒体机构对其提起有效诉讼,指控版权和商标侵权。这是一个悬在头顶、迟迟没有定论的法律风险。混合推理是产品层的创新,但版权纠纷是商业模式层的隐患,两者并行,并不互相抵消。
一家公司可以在技术架构上做出令人印象深刻的判断,同时在商业合规上依然面临真实的挑战。这两件事不矛盾,但放在一起,会让「Perplexity 的未来」这个命题变得更复杂一些。
说白了,混合推理是 Perplexity 押注的方向,但押注能不能兑现,取决于执行层面的每一个细节,以及它能否在法律压力下保持足够的专注度。
AI 应用正在经历一次安静的架构革命。不是哪个模型又刷新了 benchmark,而是「算力在哪里跑、数据往哪里走」这个底层问题,开始被认真对待。
Perplexity 今天在 Computex 台上演示的那几分钟,可能比任何一次模型发布都更值得被记住——因为它在讲的,是 AI 应用该怎么被构建,而不只是 AI 能做什么。
至于 7 月上线之后,这套系统在真实用户手里能交出什么成绩单,那才是这个故事真正开始的地方。
文章来自于微信公众号 "极客公园",作者 "极客公园"


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
