# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
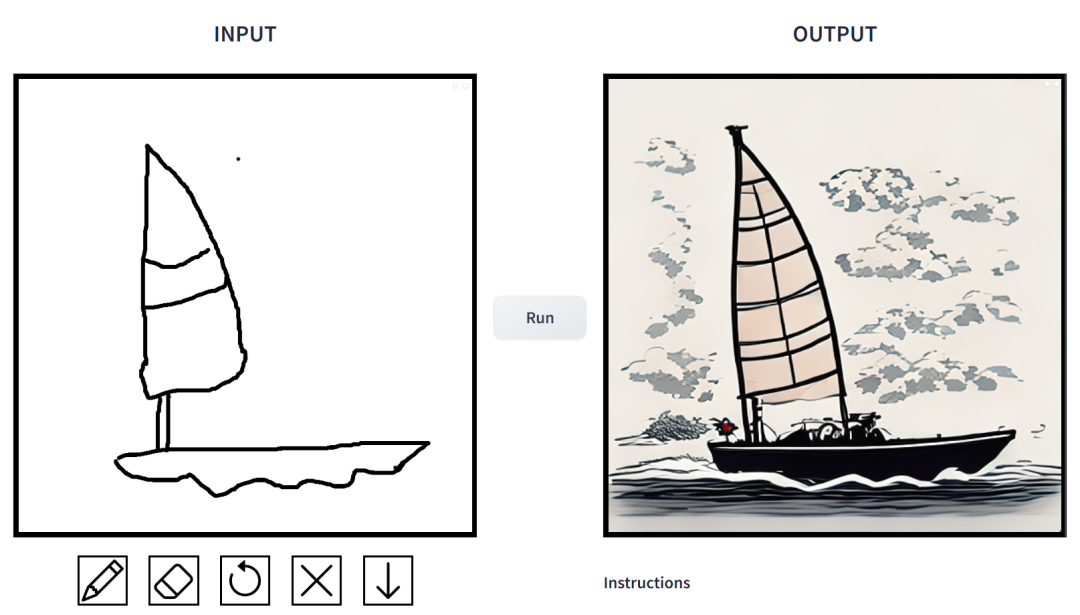
简笔素描一键变身多风格画作,还能添加额外的描述,这在 CMU、Adobe 联合推出的一项研究中实现了。
作者之一为 CMU 助理教授朱俊彦,其团队在 ICCV 2021 会议上发表过一项类似的研究:仅仅使用一个或数个手绘草图,即可以自定义一个现成的 GAN 模型,进而输出与草图匹配的图像。

效果如何?我们上手试玩了一番,得出的结论是:可玩性非常强。其中输出的图像风格多样化,包括电影风、3D 模型、动画、数字艺术、摄影风、像素艺术、奇幻画派、霓虹朋克和漫画。
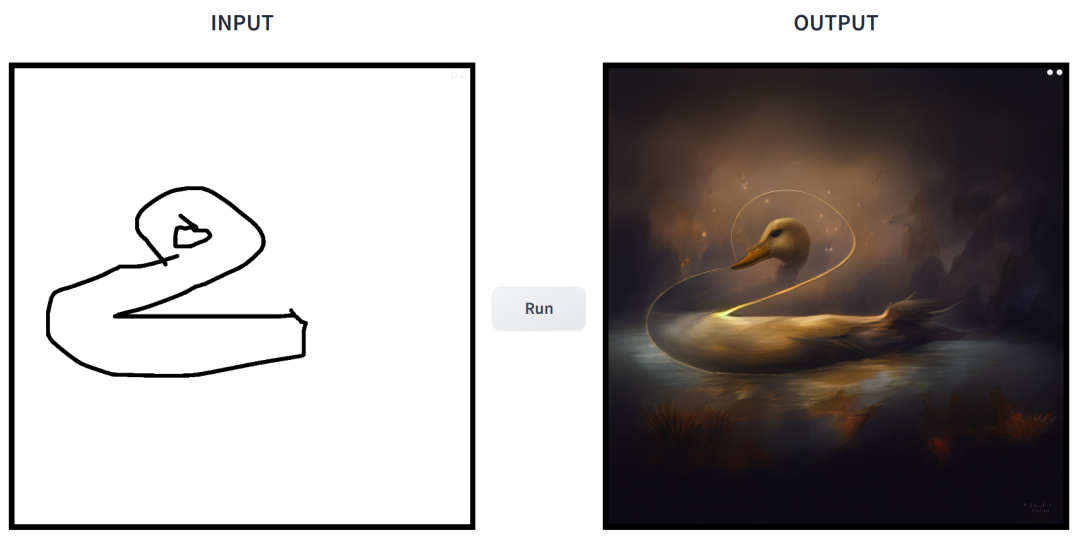

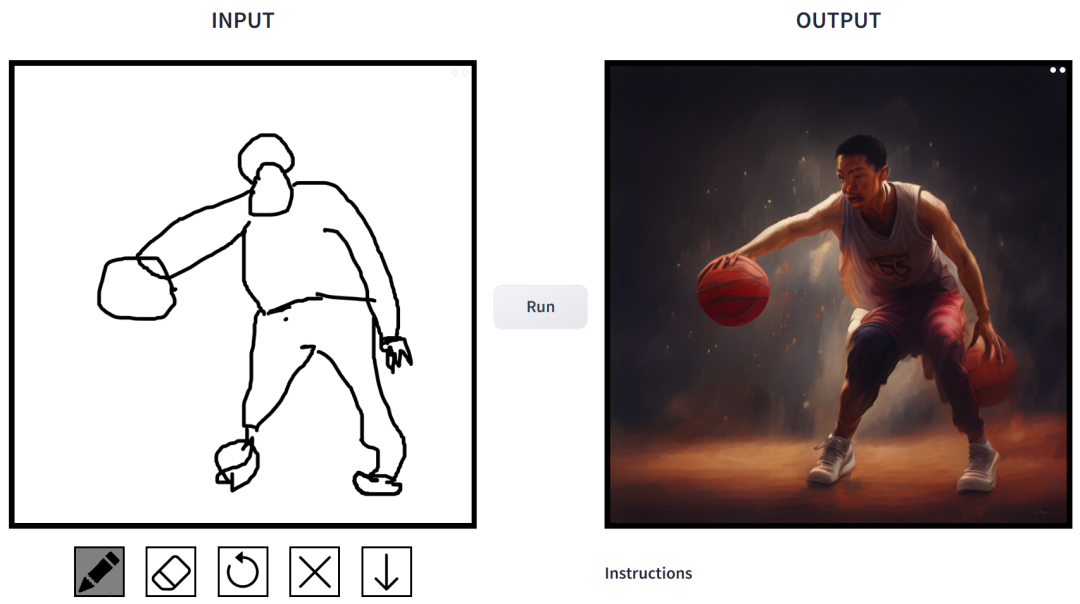
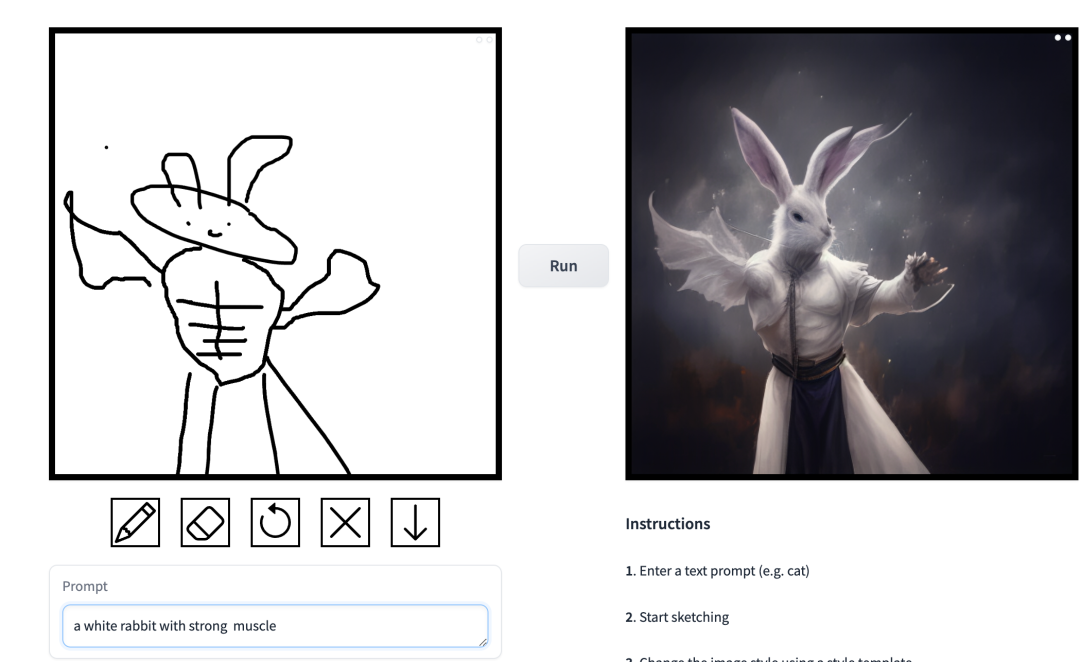
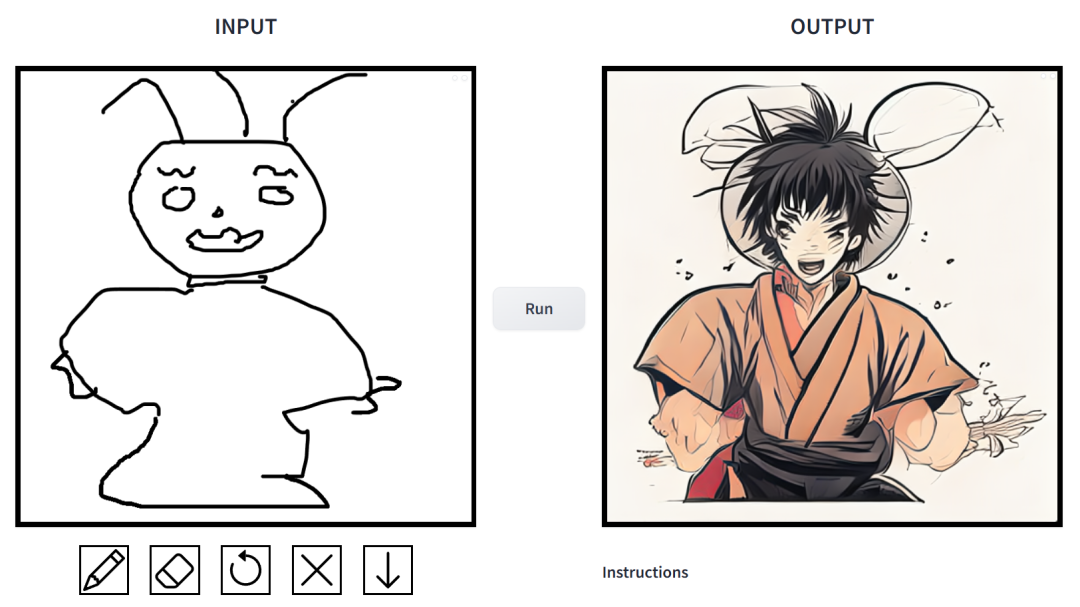

在这项工作中,研究者对条件扩散模型在图像合成应用中存在的问题进行了针对性改进。这类模型使用户可以根据空间条件和文本 prompt 生成图像,并对场景布局、用户草图和人体姿势进行精确控制。
但是问题在于,扩散模型的迭代导致推理速度变慢,限制了实时应用,比如交互式 Sketch2Photo。此外模型训练通常需要大规模成对数据集,给很多应用带来了巨大成本,对其他一些应用也不可行。
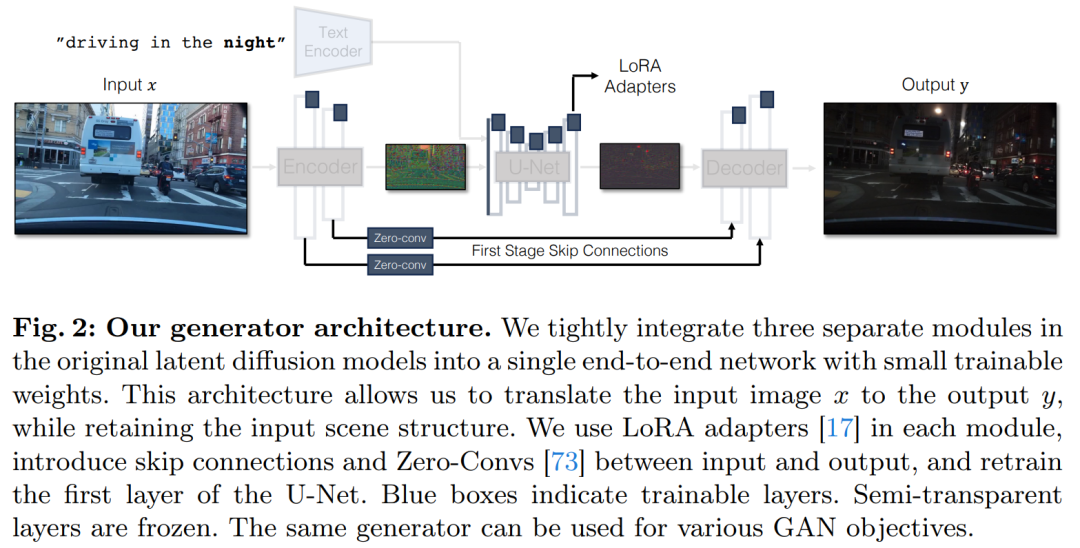
为了解决条件扩散模型存在的问题,研究者引入了一种利用对抗学习目标来使单步扩散模型适应新任务和新领域的通用方法。具体来讲,他们将 vanilla 潜在扩散模型的各个模块整合到拥有小的可训练权重的单个端到端生成器网络,从而增强模型保留输入图像结构的能力,同时减少过拟合。
研究者推出了 CycleGAN-Turbo 模型,在未成对设置下,该模型可以在各种场景转换任务中优于现有基于 GAN 和扩散的方法, 比如昼夜转换、添加或移除雾雪雨等天气效果。
同时,为了验证自身架构的通用性,研究者对成对设置进行实验。结果显示,他们的模型 pix2pix-Turbo 实现了与 Edge2Image、Sketch2Photo 不相上下的视觉效果,并将推理步骤缩减到了 1 步。
总之,这项工作表明了,一步式预训练文本到图像模型可以作为很多下游图像生成任务的强大、通用主干。
该研究提出了一种通用方法,即通过对抗学习将单步扩散模型(例如 SD-Turbo)适配到新的任务和领域。这样做既能利用预训练扩散模型的内部知识,同时还能实现高效的推理(例如,对于 512x512 图像,在 A6000 上为 0.29 秒,在 A100 上为 0.11 秒)。
此外,单步条件模型 CycleGAN-Turbo 和 pix2pix-Turbo 可以执行各种图像到图像的转换任务,适用于成对和非成对设置。CycleGAN-Turbo 超越了现有的基于 GAN 的方法和基于扩散的方法,而 pix2pix-Turbo 与最近的研究(如 ControlNet 用于 Sketch2Photo 和 Edge2Image)不相上下,但具有单步推理的优势。
为了将文本到图像模型转换为图像转换模型,首先要做的是找到一种有效的方法将输入图像 x 合并到模型中。
将条件输入合并到 Diffusion 模型中的一种常用策略是引入额外的适配器分支(adapter branch),如图 3 所示。
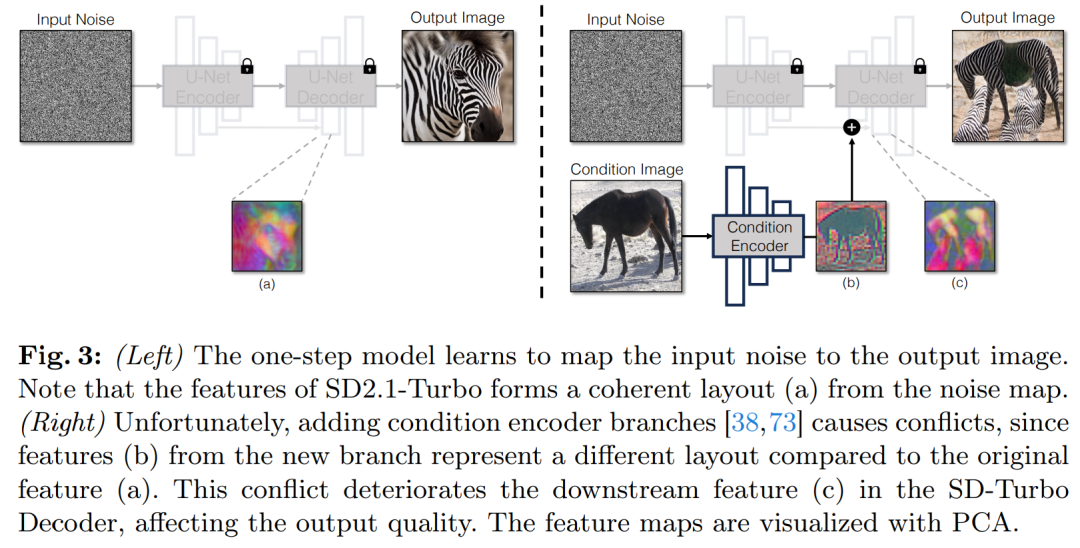
具体来说,该研究初始化第二个编码器,并标记为条件编码器(Condition Encoder)。控制编码器(Control Encoder)接受输入图像 x,并通过残差连接将多个分辨率的特征映射输出到预训练的 Stable Diffusion 模型。该方法在控制扩散模型方面取得了显著成果。
如图 3 所示,该研究在单步模型中使用两个编码器(U-Net 编码器和条件编码器)来处理噪声图像和输入图像遇到的挑战。与多步扩散模型不同,单步模型中的噪声图直接控制生成图像的布局和姿态,这往往与输入图像的结构相矛盾。因此,解码器接收到两组代表不同结构的残差特征,这使得训练过程更加具有挑战性。
直接条件输入。图 3 还说明了预训练模型生成的图像结构受到噪声图 z 的显着影响。基于这一见解,该研究建议将条件输入直接馈送到网络。为了让主干模型适应新的条件,该研究向 U-Net 的各个层添加了几个 LoRA 权重(见图 2)。
潜在扩散模型 (LDMs) 的图像编码器通过将输入图像的空间分辨率压缩 8 倍同时将通道数从 3 增加到 4 来加速扩散模型的训练和推理过程。这种设计虽然能加快训练和推理速度,但对于需要保留输入图像细节的图像转换任务来说,可能并不理想。图 4 展示了这一问题,我们拿一个白天驾驶的输入图像(左)并将其转换为对应的夜间驾驶图像,采用的架构不使用跳跃连接(中)。可以观察到,如文本、街道标志和远处的汽车等细粒度的细节没有被保留下来。相比之下,采用了包含跳跃连接的架构(右)所得到的转换图像在保留这些复杂细节方面做得更好。

为了捕捉输入图像的细粒度视觉细节,该研究在编码器和解码器网络之间添加了跳跃连接(见图 2)。具体来说,该研究在编码器内的每个下采样块之后提取四个中间激活,并通过一个 1×1 的零卷积层处理它们,然后将它们输入到解码器中对应的上采样块。这种方法确保了在图像转换过程中复杂细节的保留。
该研究将 CycleGAN-Turbo 与之前的基于 GAN 的非成对图像转换方法进行了比较。从定性分析来看,如图 5 和图 6 显示,无论是基于 GAN 的方法还是基于扩散的方法,都难以在输出图像真实感和保持结构之间达到平衡。


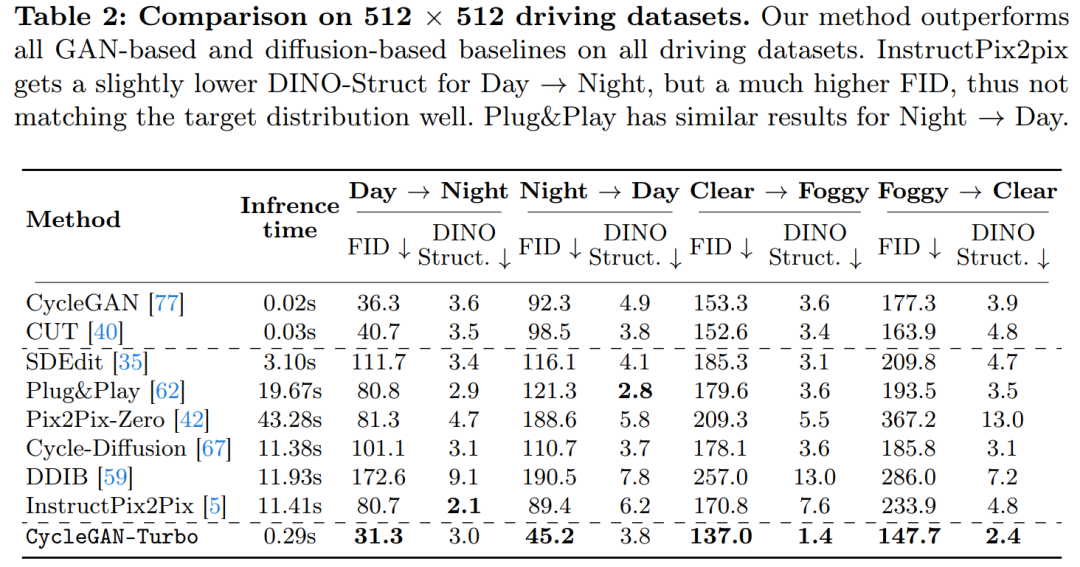
该研究还将 CycleGAN-Turbo 与 CycleGAN 和 CUT 进行了比较。表 1 和表 2 展示了在八个无成对转换任务上的定量比较结果。
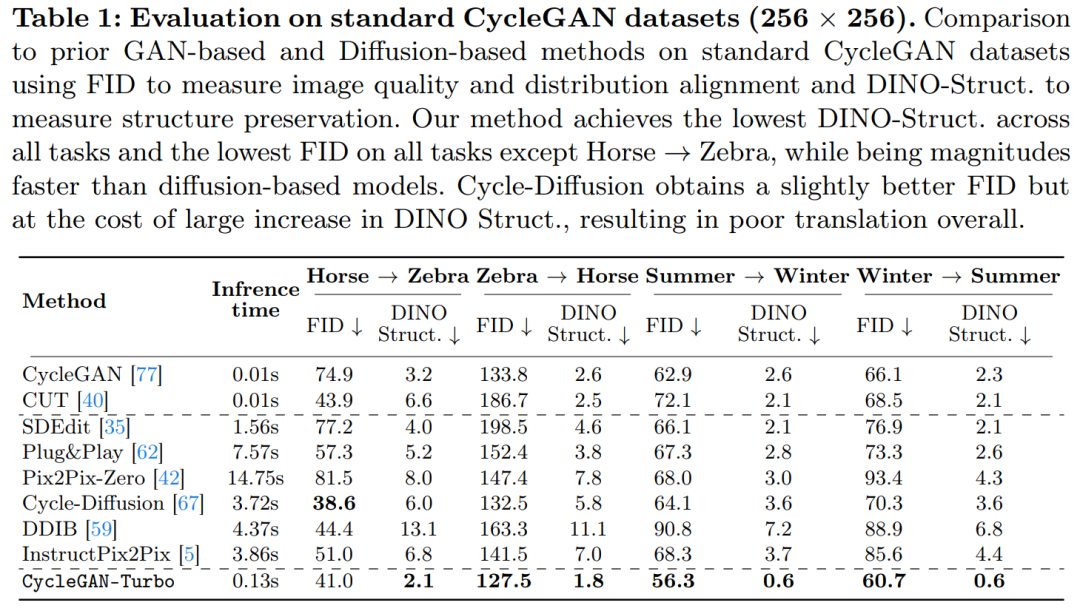
CycleGAN 和 CUT 在较简单的、以对象为中心的数据集上,如马→斑马(图 13),展现出有效的性能,实现了低 FID 和 DINO-Structure 分数。本文方法在 FID 和 DINO-Structure 距离指标上略微优于这些方法。

如表 1 和图 14 所示,在以对象为中心的数据集(如马→斑马)上,这些方法可以生成逼真的斑马,但在精确匹配对象姿势上存在困难。
在驾驶数据集上,这些编辑方法的表现明显更差,原因有三:(1)模型难以生成包含多个对象的复杂场景,(2)这些方法(除了 Instruct-pix2pix)需要先将图像反转为噪声图,引入潜在的人为误差,(3)预训练模型无法合成类似于驾驶数据集捕获的街景图像。表 2 和图 16 显示,在所有四个驾驶转换任务上,这些方法输出的图像质量较差,并且不遵循输入图像的结构。


本文来源于公众号机器之心,作者陈萍、杜伟




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
