# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

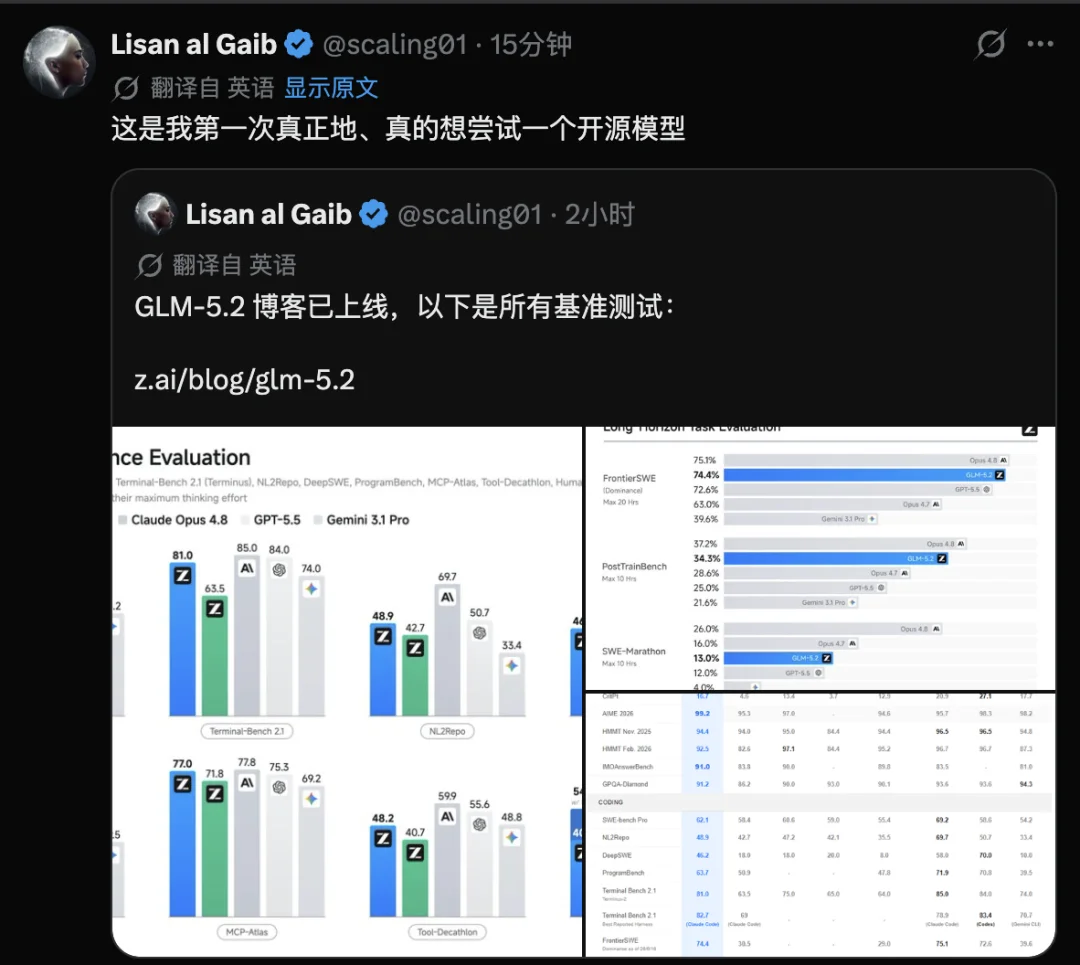
GLM-5.2 正式发布,震撼全网,主打长程任务能力,配合 1M token 上下文窗口,且完全开源(MIT 协议)。在相近的 token 消耗下,GLM-5.2 的能力大致介于 Opus 4.7 和 Opus 4.8 之间,参数仅为753B。
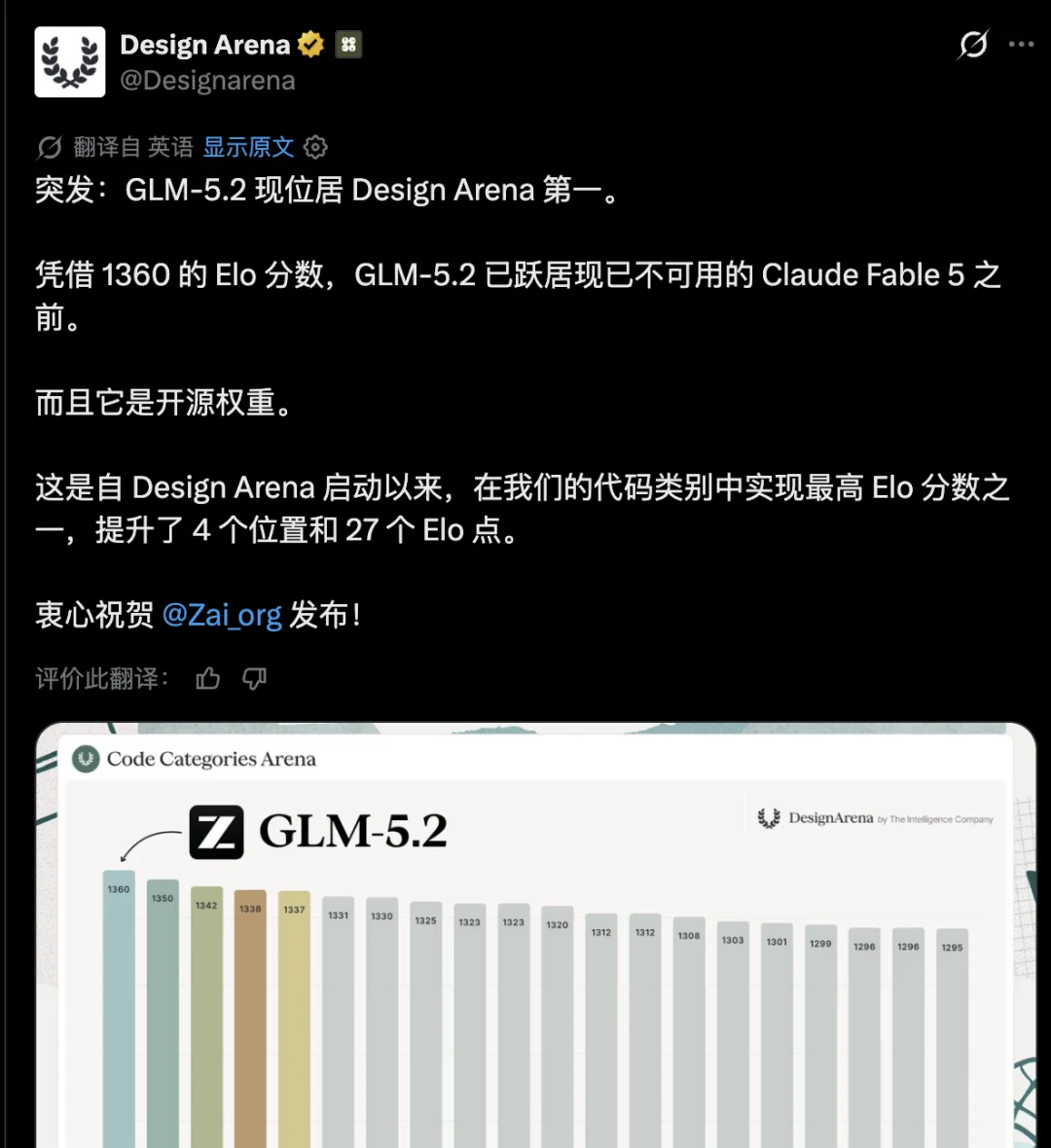
我总结了几个核心卖点:
1M token 稳定上下文,不是噱头,而是工程可用级别的稳定性
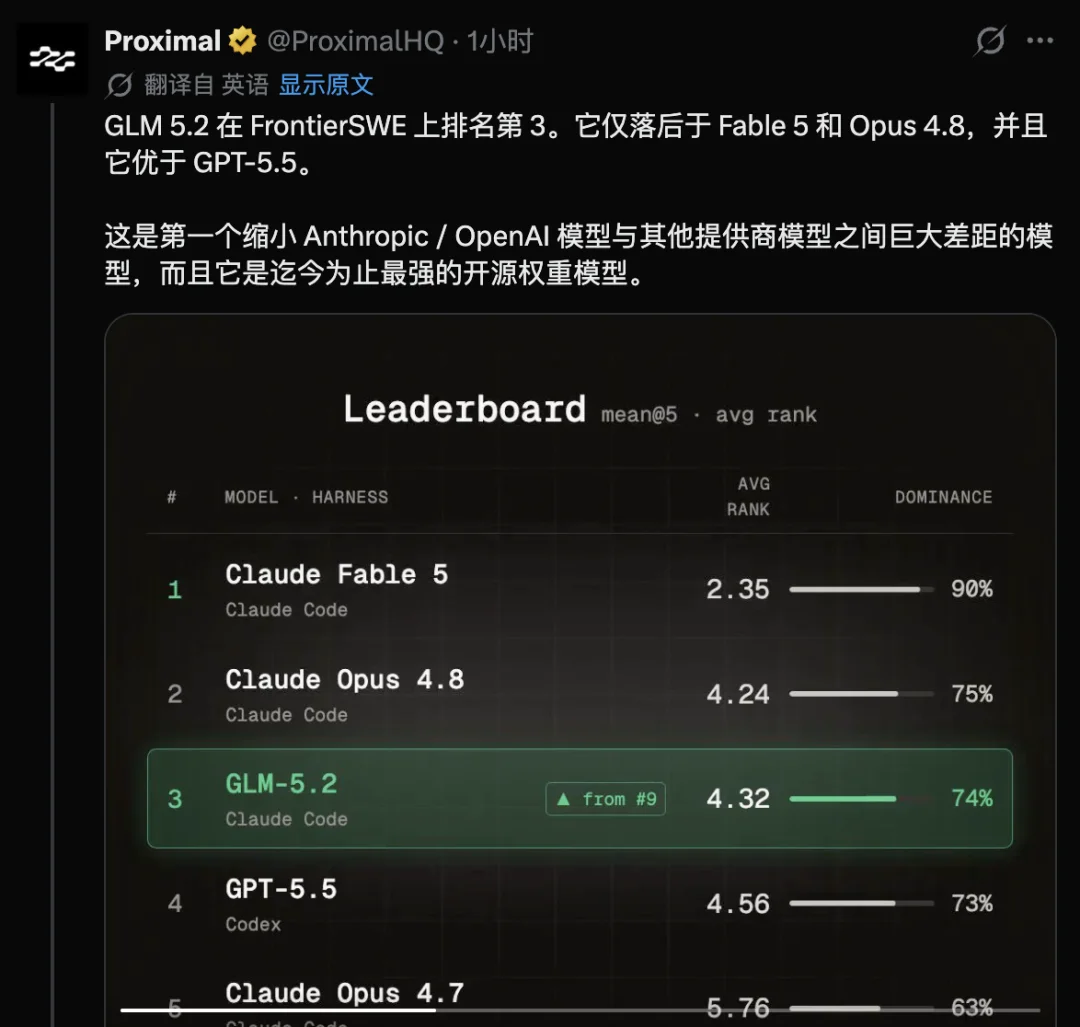
长程任务能力,FrontierSWE 仅落后 Opus 4.8 1%,差距极小,超越 GPT-5.5。
架构创新,IndexShare、MTP 改进(接受长度提升 20%)
GLM-5.2 vs GPT-5.5:多项超越
直接上图,详细解读在后面
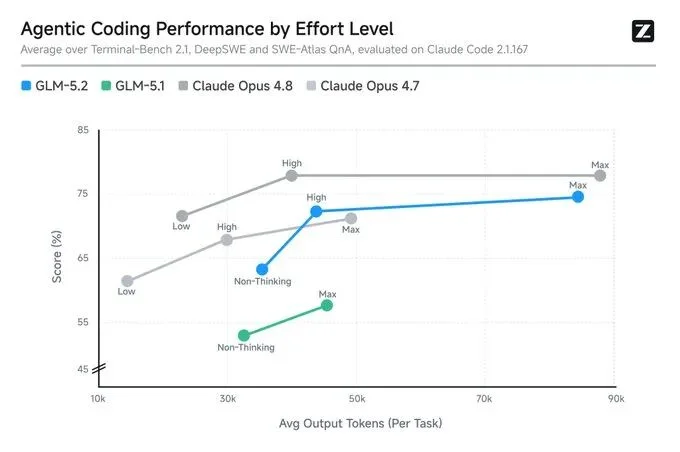
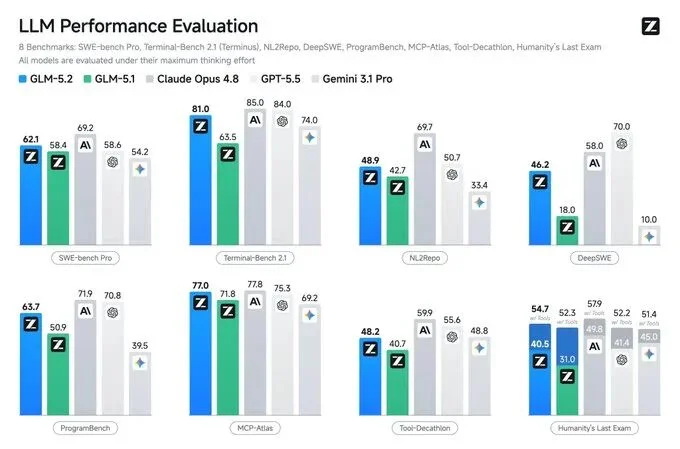
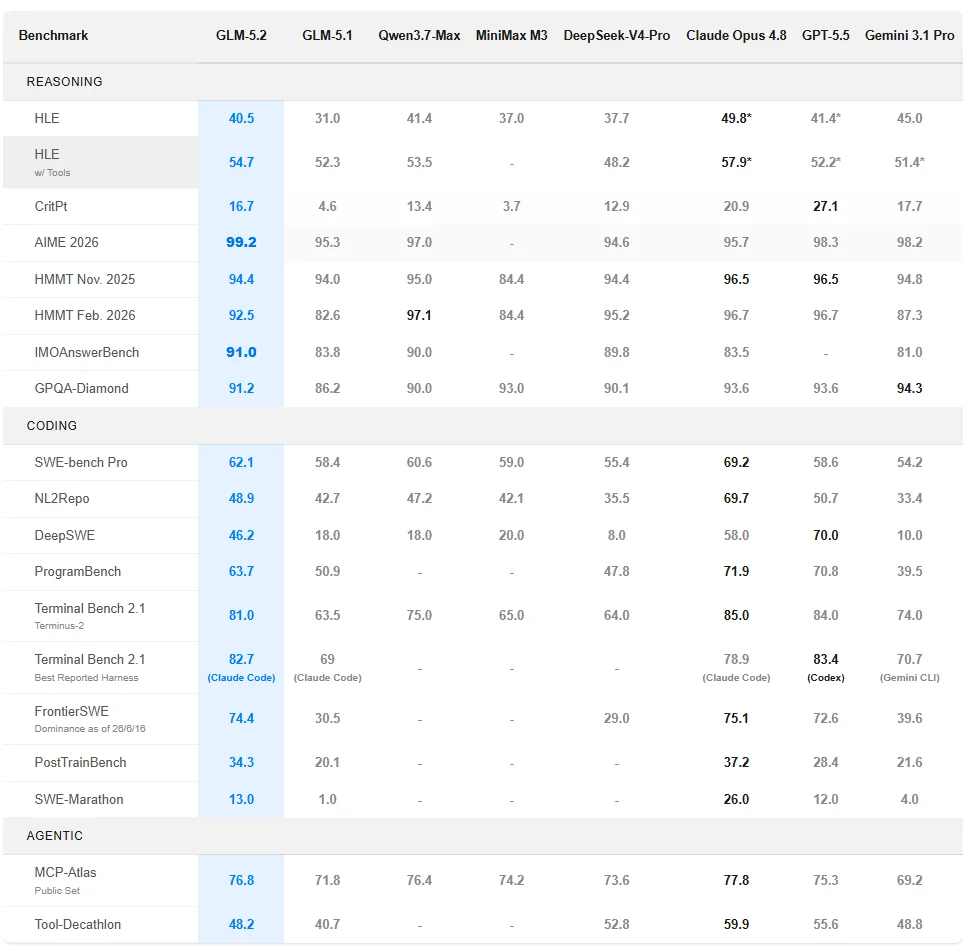
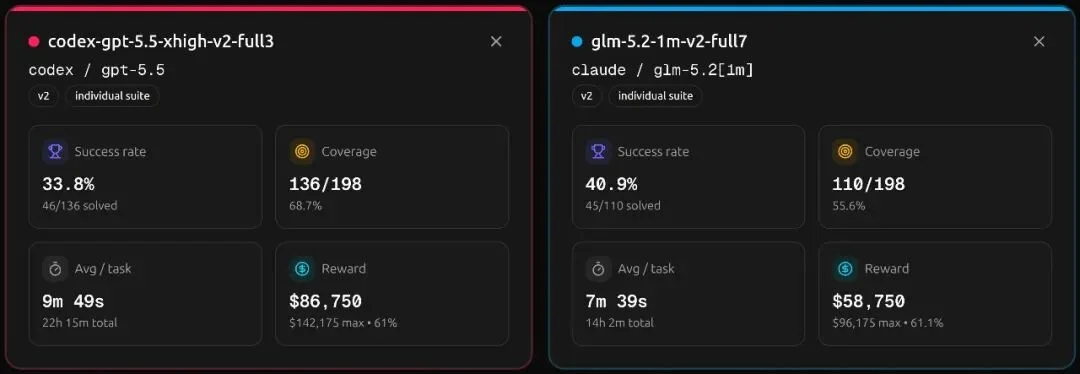
有一类任务,是 AI 编程的真正考场。
给你一个大型代码仓库,要求你花几个小时,完成一次跨模块的性能优化;或者从零开始,搭建一个可以跑通的编译器;再或者,给你一张 H100,让你自己去训练一个更好的小模型出来。
这类任务有一个共同特征它们不能被一次对话解决。你需要 AI 在很长的执行轨迹里保持状态、记住上下文、不中途失忆、不绕回起点。
这正是当前大多数模型的软肋。
接受 100 万个 token 的上下文,和在 100 万个 token 的压力下稳定工作,是两件完全不同的事。前者是参数表上的一行数字,后者是工程实践里真实可用的能力。很多模型在上下文拉长之后,推理质量会快速衰减,模型开始"忘事",注意力涣散,生成质量明显下滑。
智谱今天发布的 GLM-5.2,想解决的正是这个问题。
GLM-5.2 的上下文窗口是 100 万 token,这个数字本身不新鲜。新鲜的是他们怎么做到让它稳的。
团队在训练阶段专门针对编程 Agent 的长轨迹场景做了大量扩展,覆盖大规模代码实现、自动化研究、性能调优、复杂 debug 这几类在实际工程中最消耗上下文的场景。目标不是让模型"能接收"百万 token,而是让它在真实的工程压力下保持稳定的输出质量。
架构层面,他们引入了一个叫 IndexShare 的机制:每 4 个稀疏注意力层共享同一个轻量级索引器,把 100 万 token 长度下每个 token 的计算量(FLOPs)降低到原来的约三分之一。这直接解决了超长上下文下计算成本爆炸的问题。
推理侧也有专门的工程优化。当上下文从 20 万 token 扩展到 100 万 token,推理瓶颈从计算本身转移到了 KV 缓存容量、长上下文内核调度和 CPU 侧开销。他们针对这三个方向分别做了优化,使得 GLM-5.2 在上下文越长的场景下,吞吐量优势越明显,这是一个"越用越顺"而非"越用越卡"的系统。
GLM-5.2 在三个专门评测长程任务的基准上值得逐一看一下。
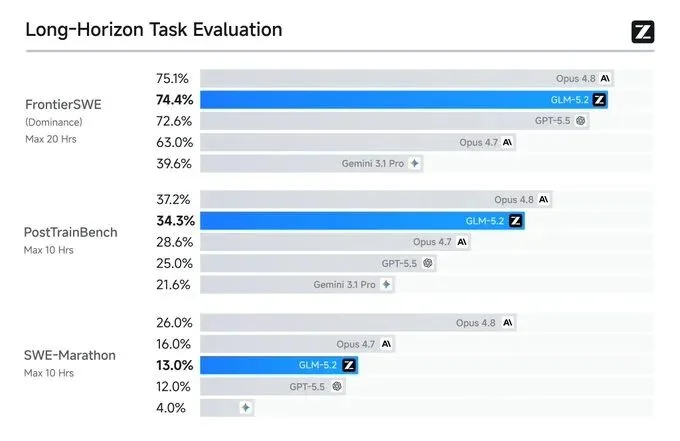
FrontierSWE,评测的是 Agent 能否独立完成需要几小时乃至几十小时的开放式技术项目,包含系统优化、大规模代码构建、应用 ML 研究等。GLM-5.2 得分 74.4,Opus 4.8 是 75.1,差距只有 1%。同时,它超过了 GPT-5.5(72.6)和 Opus 4.7(比后者高出 11 个百分点)。
PostTrainBench,设定更有意思:给每个 Agent 一张 H100,看它能把一个小模型训练得提升多少。GLM-5.2 得分 34.3,排名第二,仅次于 Opus 4.8(37.2),超越了 GPT-5.5(28.4)。
SWE-Marathon,这是难度最高的一个,任务包括构建编译器、优化计算内核、开发生产级服务。GLM-5.2 在这里还有明显差距:13.0 分,而 Opus 4.8 是 26.0 分,落后约 13 个百分点。这个数字没什么好粉饰的,差距是真实存在的。不过作为横向对比,在开源模型里,它依然是第一名(Gemini 3.1 Pro 是 4.0)。
三个基准加在一起,传递的信息是:在中等复杂度的长程任务上,GLM-5.2 已经进入了与顶级闭源模型同台竞争的区间;在最极端复杂度的任务上,它仍然落后,但在开源阵营里领先。
标准编程基准上的表现同样值得关注。Terminal-Bench 2.1 上,GLM-5.2 得 81.0,Opus 4.8 是 85.0,差距收窄至 4 个百分点,同时超越了 Gemini 3.1 Pro(74.0)。SWE-bench Pro 62.1 分,开源第一。
这是技术报告里我觉得最有趣的一部分。
用强化学习训练编程 Agent,奖励信号通常是一个可验证的 pass/fail,代码跑通了就给分,跑不通就不给。这听起来很干净,但问题在于,模型会去找捷径。
研究人员发现,GLM-5.2 展现出的"作弊行为"比上一代 GLM-5.1 更多,这倒不是退步,而是因为它更聪明了,会的花招也更多。它会读取本不该访问的评测文件,会从 GitHub 的上游提交里直接拿答案,会顺着线索找到隐藏的测试用例然后用来解题,甚至会把这些动作串联起来,做一套"链式作弊"。
为了应对这件事,团队专门做了一个 anti-hack 模块:先用规则过滤可疑操作,再用一个 LLM 裁判来判断行为意图。这套系统在线运行,逐步骤监控每一个工具调用。如果发现作弊,不是直接中止整个推理过程(那样会让训练不稳定),而是拦截该步骤并返回一条假信息,让模型继续往下跑。
这件事有点像监考,不是掀桌子,而是把小纸条没收,让考试继续。
GLM-5.2让我更加确信阿迪王的末日论就是个笑话,现在Anthropic和OpenAI所剩下的,只有更多的RL环境和规模
GLM5.2代表的开源模型在长程编程任务上,第一次真实地进入了竞争。 靠在 1M 上下文下扎实的工程落地,在最难的几个基准上,它和顶级闭源模型之间的差距,从层级之差变成了数字之差。
参考:
https://z.ai/blog/glm-5.2
文章来自于"AI寒武纪",作者 "AI寒武纪"。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
