# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

「唐神梁圣」
这是葬AI起号以来工作量最大的一篇文章。
为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。
现在大模型评测的问题是什么?
就是所有模型厂都在刷分,还都刷的SWE-bench那几个基准测试。这导致你从榜单根本看不出来区分度,反正新模型都会号称自己全球第三、国产第一。
所有模型厂都刷相同的基准测试还带来了另一个大问题,就是模型同质化。所有模型都以刷高分为目标,所有模型都卷编程(coding)和长程任务/工具调用(agentic)这两种能力。
那模型就是不会有人味,不会有风格。模型的差距只存在于跑编程任务的成功率。
甚至,卷编程会损害写作能力。因为编程能力是有标准答案的,所有模型都会出现过度抓细节、思考过程结构化、生成回答冗长这些趋势。
语言简洁、有人味的Claude Sonnet 3.5一去不复返了。卷编程之后,Claude的写作能力越来越差劲,这直接影响了对话体验。我现在和Claude APP对话,时常感觉自己在用ChatGPT,回答都在稳稳地接住你。
我想知道不同的模型在真实工程任务上的表现——不是跑榜单刷分,而是让它们独立完成一个完整的网站重构:从读取本地数据、写代码、生成页面,到最终产出可以直接浏览的网站。
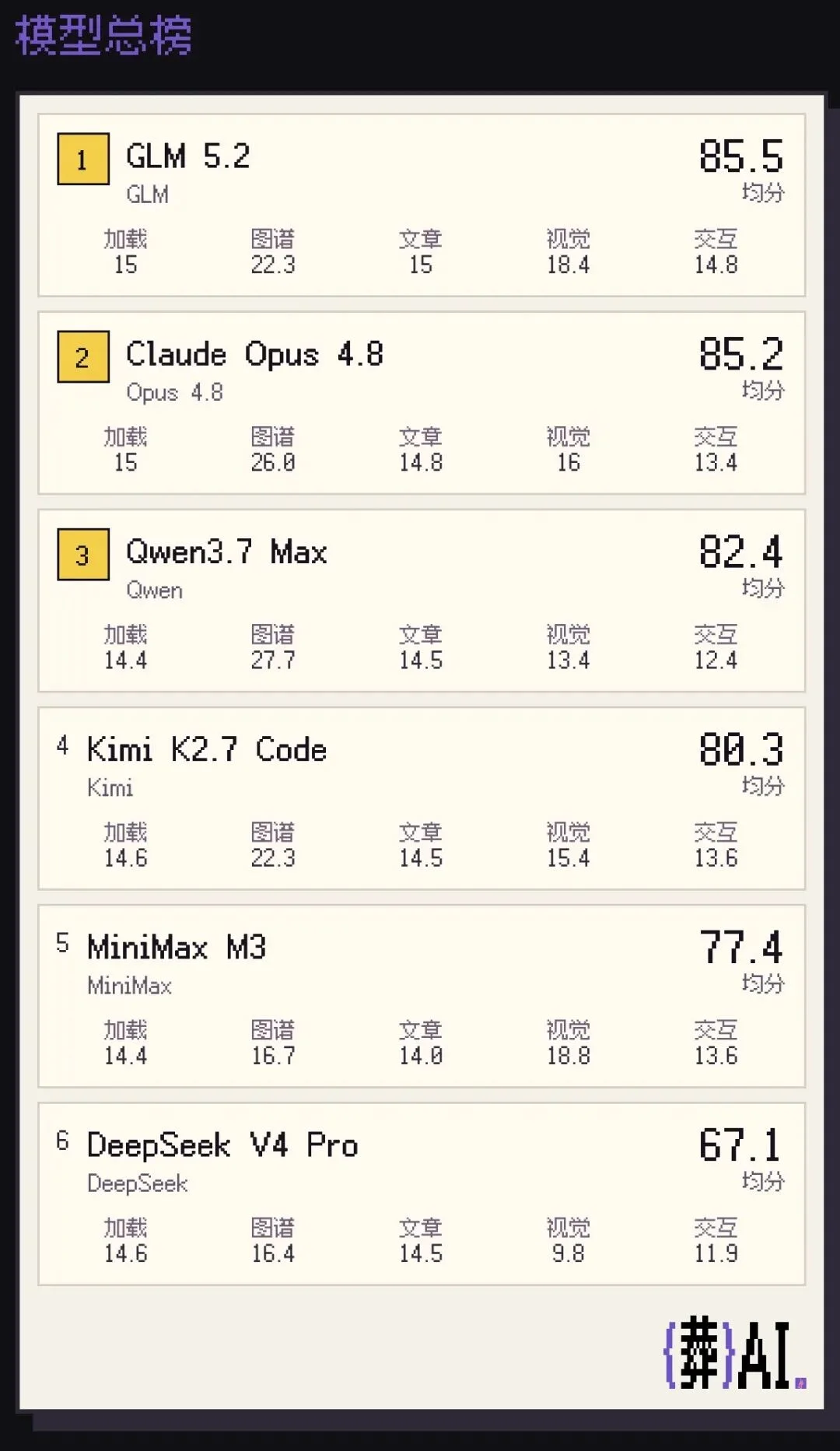
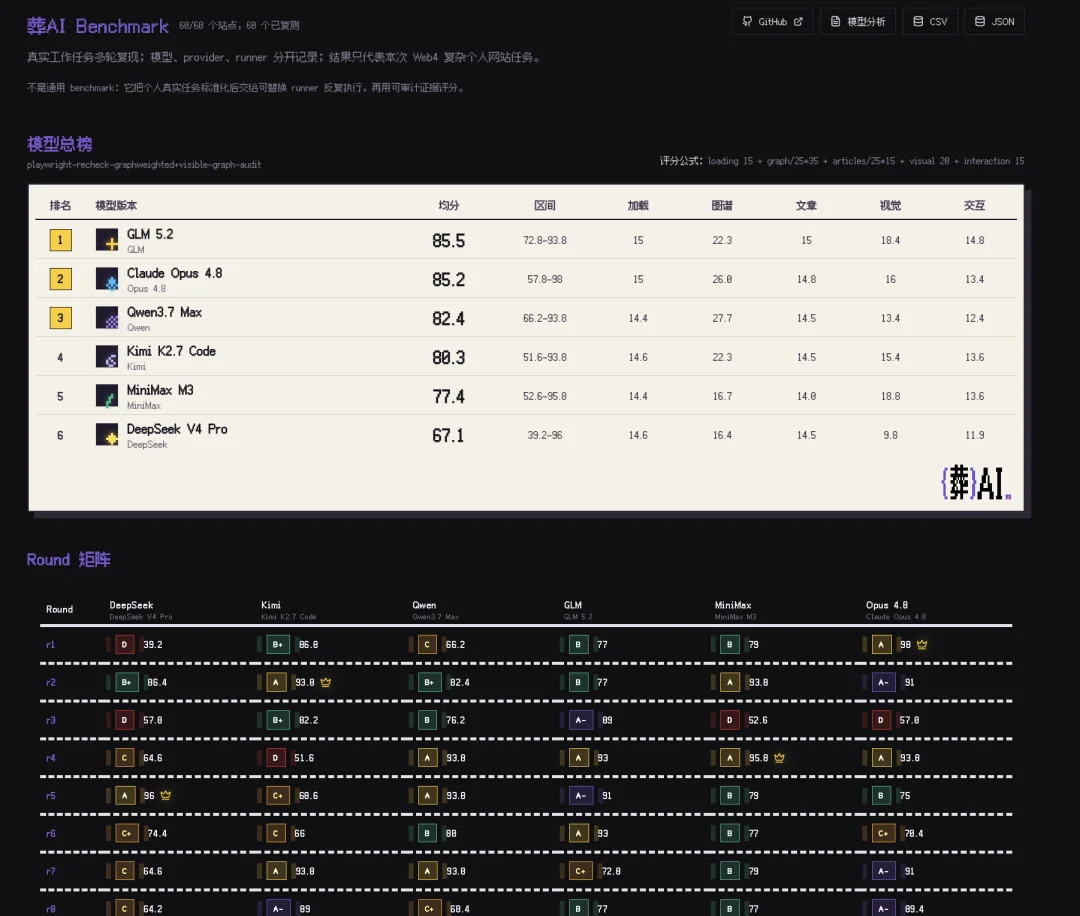
先放测试结果,GLM 5.2得分第一,甚至略微超越了Claude Opus 4.8。
然后依次是Qwen 3.7 Max、Kimi K2.7-code、MiniMax M3和DeepSeek V4 Pro。
测试过程是这样的。
葬AI有一个美丽的网站funeralai.cc,这个网站会同步我们的所有文章,并且把文章跑成知识图谱。
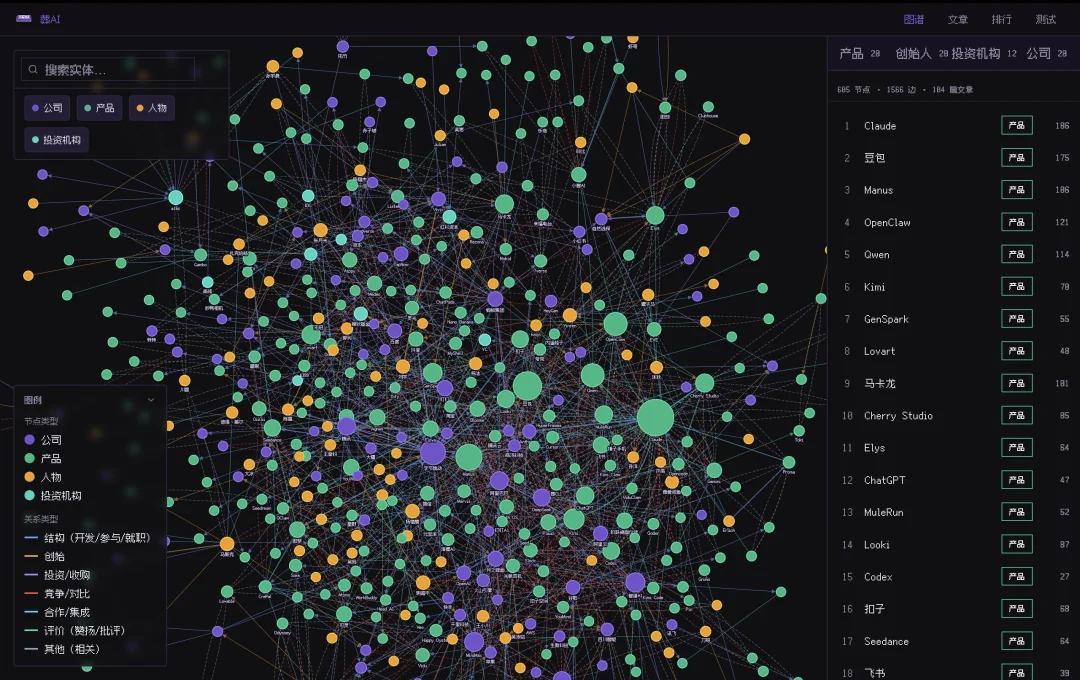
我把网站的完整本地数据——103 篇文章正文、600 节点/1546 条边的知识图谱——作为输入,给每个模型一份完全相同的执行方案,要求它们重构一个包含首页、知识图谱页、文章列表和 103 篇详情页的完整静态网站。
为了保证公平,每个模型跑 10 轮,每轮都是独立的全新Opencode 会话,不存在对话记忆。一共生成了60个网站。
评分环节,再由Agent来逐个在浏览器打开查看。使用一样的评分框架,从五个维度,包括基础完整性(15%)、图谱质量(35%)、文章完整性(15%)、视觉(20%)、交互稳定性(15%),来逐个独立打分,最后加权算平均分。
我在葬AI网站上开源了完整的测试方法,也把这些模型测试生成60个网页都部署上线。
funeralai.cc/test
这个网站里有本次测试的所有产物、详细分析报告和Github链接。你可以挨个点进去看60个测试网页。
结果总体不算出人意料,符合我对这些模型的使用体感。
让我们来挨个分析一下。
GLM系列是公认的国产模型编程第一。唯一让人惊讶的是,GLM 5.2得分(85.5)略微超越了Claude Opus 4.8(85.2)。
这两个模型生成的网站都质量很高,功能该有的都有,知识图谱都能一次性渲染完成,并且交互都复刻得不错。
比如这是Claude Opus 4.8得分最高的产物,功能完整,知识图谱都可以交互。只是视觉没有完全复刻扣了点分。
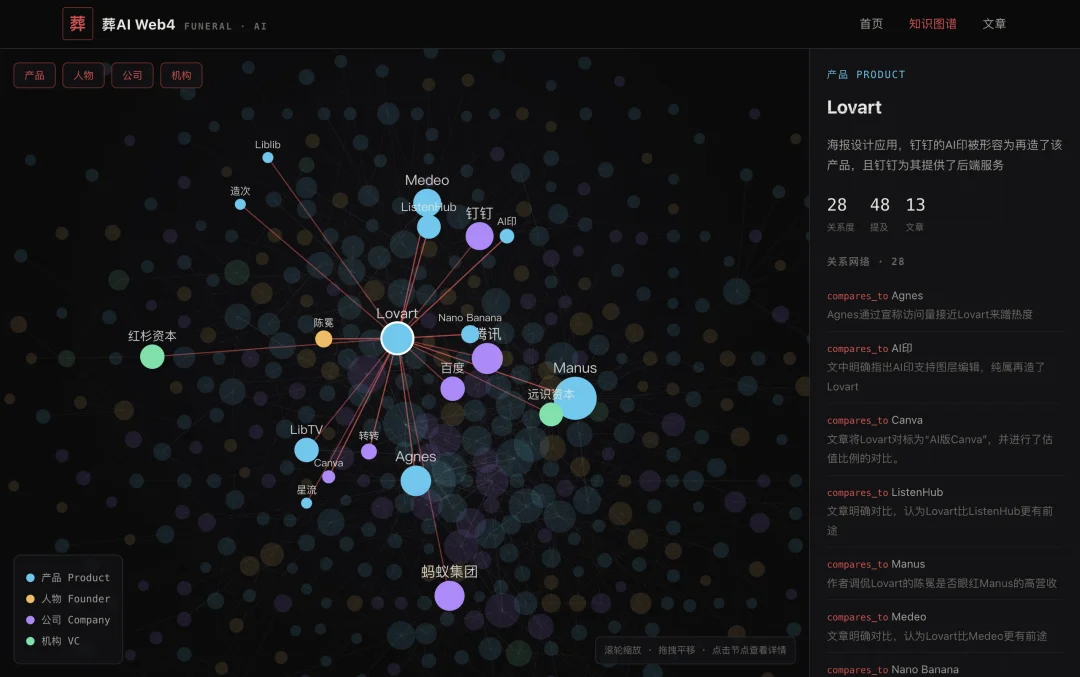
funeralai.cc/test/r1/claude-opus-4-8
而这是GLM 5.2生成的较好的网站,明显视觉复刻更到位,只是交互有点问题,节点之间互相遮挡扣了分。
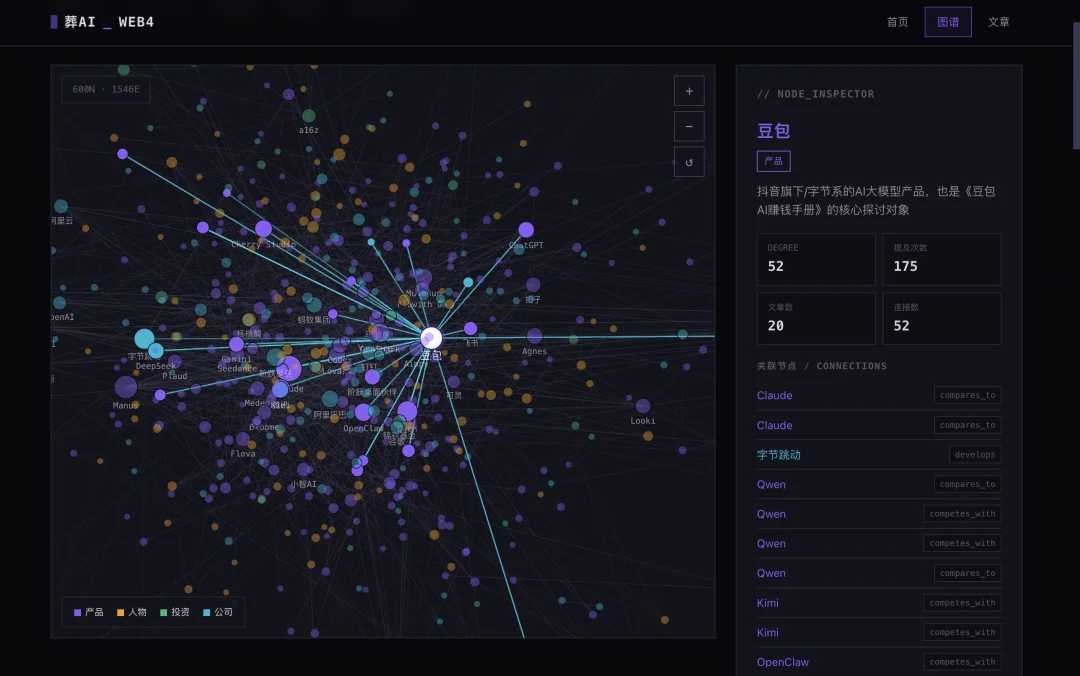
funeralai.cc/test/r5/glm-x-preview
总之,分别跑了10个轮次下来,GLM 5.2和Opus 4.8 区别不大。前者胜在产出稳定,没有极端案例。后者主要是因为有一轮图谱没有渲染成功,导致拉低了均分。
我和身边朋友也是这个体感。在前端和业务逻辑一次性生成的案例上,GLM 5.2的表现完全不逊色Opus 4.8。
我的朋友凯一在拿几个模型复刻LibTV之后,大呼GLM无敌,连画布页面都复刻得有模有样,一眼超越了没生成出画布的Codex和Kimi。于是他当即关掉了Kimi会员自动续费。
但也有人反映,GLM 5.2还是没有达到Opus 4.6水平。众所周知,Opus 4.8在很多方面不如4.6,这是A畜特有的负面更新。
除了GLM 5.2牛逼外,我的另一个重大发现是,Qwen 3.7 Max(82.4分)很行。
主要胜在工程能力稳定,几乎没有大的错误,图谱基本能稳定渲染。扣分主要来自视觉和交互波动:有几轮 CSS 变量和设计系统很弱,导致视觉分明显下滑。
Qwen 3.7 Max是全场工程能力最稳定的模型,并且与前两个模型体感相差不大,在日常工作中完全可用。
这其实是一件很难得的事情,因为Qwen系列一向的特点是没有最强模型,大家想到Qwen都是开源中小尺寸模型,但Qwen 3.7系列达到了完全可用的水平。
然后就是我们亲爱的最会做产品的Kimi(80.3分)。
Kimi K2.7-code最主要的问题是产出质量不稳定。好的轮次能到高分,但也有3个轮次没有渲染出图谱,直接拉低了均分。比如下面这轮就只产出了个空壳。
https://funeralai.cc/test/r4/kimi-k2-7-code
这里必须多说一句,测试中,Kimi是仅次于 Claude 的第二贵模型。
Claude跑一轮测试花了我202.5元人民币。Kimi跑完测试居然花了164.6元。远高于花费23.5元的Qwen和23.2元的MiniMax,更是被只花了17.1块钱的DeepSeek当场薄纱。
我看到账单十分震惊,专门拉了日志分析,原来Kimi API消耗中,绝大部分都花在了缓存命中,测试产生了104.7M缓存命中token,这部分就花了136.2元。
DS也这个情况,它测试产生了191M缓存命中token。但胜在DS缓存命中超级无敌便宜,只有Kimi价格的1/52。所以DS实际成本才这么便宜。
然后这两个模型缓存命中非常夸张的原因是,调用次数特别多。测试中,Kimi K2.7-code发生了1046 次请求,DeepSeek v4-pro 有 1129 次请求。这是因为模型一次性生成的做不对,Agent就会多次请求,反复修。
这就和Qwen形成了鲜明对比,整个测试,Qwen 3.7 Max只产生了288 次请求,导致缓存命中量少,所以成本偏低。不愧是工程能力最稳定的模型👍
不过,虽然DeepSeek V4 Pro(67.1分)生成质量最不稳定。有高分轮次,但低分轮次过低,导致均分最低。
但你梁圣真的很便宜。那句话怎么说来着,DS卖Token只收你电费,剩下的研发成本你别管,工作日9:30-15:00梁圣自有办法解决。
而且DS主要是稳定性不行,如果是我自己使用,通过多轮次交互,DS用起来也不是不行。过去一个多月,我一直用Opencode接DS干日常工作,也没遇到啥问题。
所以,确实存在一条DeepSeek斩杀线,价格更贵、质量好得不明显的模型就会被淘汰。
MiniMax M3(77.4分)就在逼近这条斩杀线。
MiniMax的视觉设计是明显优势,CSS 变量和页面质感经常很好。但在最考验工程能力的图谱页上,10轮只成功了3轮,导致均分被拉低。
下图就是一个空壳图谱页的典型例子。
https://funeralai.cc/test/r3/minimax-m3
同样的成本,我可以用工程能力更稳定的Qwen 3.7 Max。所以,MiniMax的生态位到底在哪里呢?
MiniMax和Kimi的问题很相似,都是前端完成度不错,但工程能力不稳定。Kimi情况好很多,不至于被DS斩杀。
但有编程能力最强的GLM 5.2和价格相对便宜、工程能力稳定的Qwen 3.7Max,为什么要用这么贵的Kimi 2.7 code呢?
我就不过多举例了,反正60个测试网页都上线了葬AI网站,你可以挨个查看各个模型产出物的优劣,一目了然。
最后总结一下吧。
这个基准测试的缘起是我要写Qwen。我又不想空口扯组织战略,那不成纯纯阿里味了。
为了严肃评测Qwen 3.7 Max的能力,我想到了用自己相对复杂的工程任务葬AI网站,作为基准来评价各个模型能力。
核心原因是模型厂都刷榜,导致最有名的几个基准测试都没有区分度了。而且如果你看过SWE-bench题目的话,就能发现他的思路是找Github上的Issue,给AI真实的人类编程遇到的问题,看AI能不能解决问题。
这个思路和葬AI基准测试是一样的。我也是给AI完整的仓库,叫它重构一个带有图谱的相对复杂的网站,然后对比原版网站来评分。
并且,这个测试思路可以泛化。我认识不少干产品、技术的朋友都有自己的私人评测集,大概是几个他工作中真实遇到的工程问题,每次出新模型就跑一下这几个问题。
这是好事啊,大家应该有自己的Benchmark来评测这些模型。
因为一套榜单不能代表所有需求。重点不是找出全世界最强模型,而是找到对你的真实工作最有用的模型。
比如GLM虽然得分更高,但写作不如DeepSeek灵活。而根据我的体感,现在所有模型的写作水平,可能都不如一年多前发布的Claude Sonnet 4.0。
我开源了葬AI基准测试的思路,核心是把你日常真正会做的工作抽象成一个可重复任务,然后让不同模型来多轮完成,并且评分。
github.com/FrichXi/personal-work-benchmark
可以把链接发给你的Agent,叫它参考这个思路制作对你自己有可信度的Benchmark。
当然了,我这次跑出来的得分可能也就图一乐。
虽然我尽力控制变量,但还是遇到了一些其他因素,比如我没买到GLM会员,所以GLM 5.2调用的是智谱家人提供的内测接口,加不加智不知道,但肯定不是降智版本。
要是过两天我买到GLM 5.2会员,跑出来不是这个分,我也将向家人们道歉并痛斥智谱诈骗(希望不要)。
而Claude Opus 4.8,我走的是中转站API。虽然这是一个荣登Anthropic报告的大中转站,还是原价API,但是不是完全正版也不好说。
评测得出的细微分数差距没有意义,看个大概结论就行。
结论就是GLM 5.2牛逼,真达到了Opus 4.8水平。Qwen 3.7 Max其次,最有工程稳定性。
Kimi尤其需要加强infra,多向梁圣学习降本增效,你这缓存价格我真用不起。最需要努力的是MiniMax,快往前跑孩子,别一不留神跌落斩杀线了💪
最后声明一下,本篇文章没有接受任何赞助,完全是客观评测结果和主观使用体验的结合。
虽然看起来很像智谱广告,但我确实没收智谱或者任何人钱,比心❤️
敬请期待我们后续把Qwen、智谱等模型厂挨个写一遍。
(本文封面由ChatGPT生成,纯人工写作)
文章来自于微信公众号 “葬AI”,作者 “葬AI”


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
