# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
把 VoiceVault 的转录引擎从 Whisper 迁移到 FunASR(sherpa-onnx),中文识别速度提升 3x,不再需要 500MB 的模型文件。但"切个后端"这件听起来很简单的事,让我在 GitHub Release 的 404、Tauri 白屏、trait object 生命周期和 CSP 策略里翻滚了一整天。这篇文章把每个坑都扒干净。
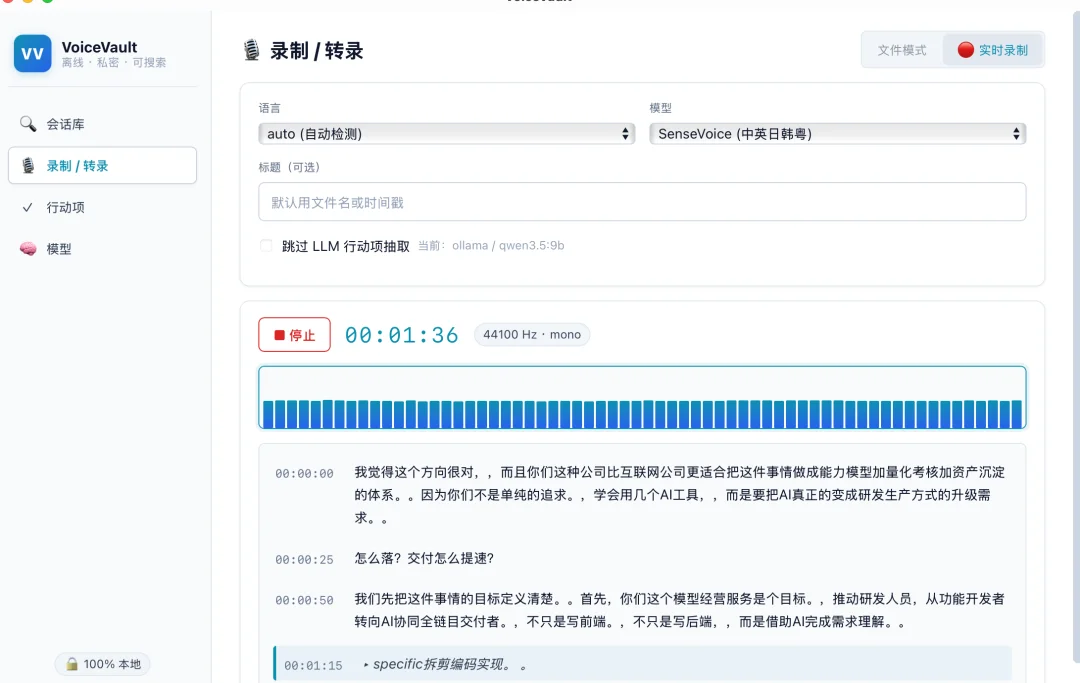
asr真流式真的好

干掉 wishper,用上 funAsr
Whisper 是个好模型,但它有三个让我越来越难受的问题:
1. 中文不是一等公民
Whisper 的训练数据以英文为主。base 模型跑中文会议,标点全丢、语气词乱飞、"的"和"得"五五开。想要像样的中文,至少得上 medium(1.5GB),M1 Pro 推理一分钟音频要 40 秒。
2. 模型太大,用户流失在下载
告诉用户"先下载一个 1.5GB 的模型",90% 的人关掉页面。base 模型 141MB 勉强可以接受,但效果又不行。
3. 流式是假流式
上一篇文章说过,Whisper 不是流式架构。每次 partial 都要对整段 buffer 重推理。30 秒的音频,每 2.5 秒做一次 partial,每次推理完整 30 秒 —— CPU 在烧,但用户看到的文字并没有变多少。
然后我遇到了 FunASR(via sherpa-onnx)。
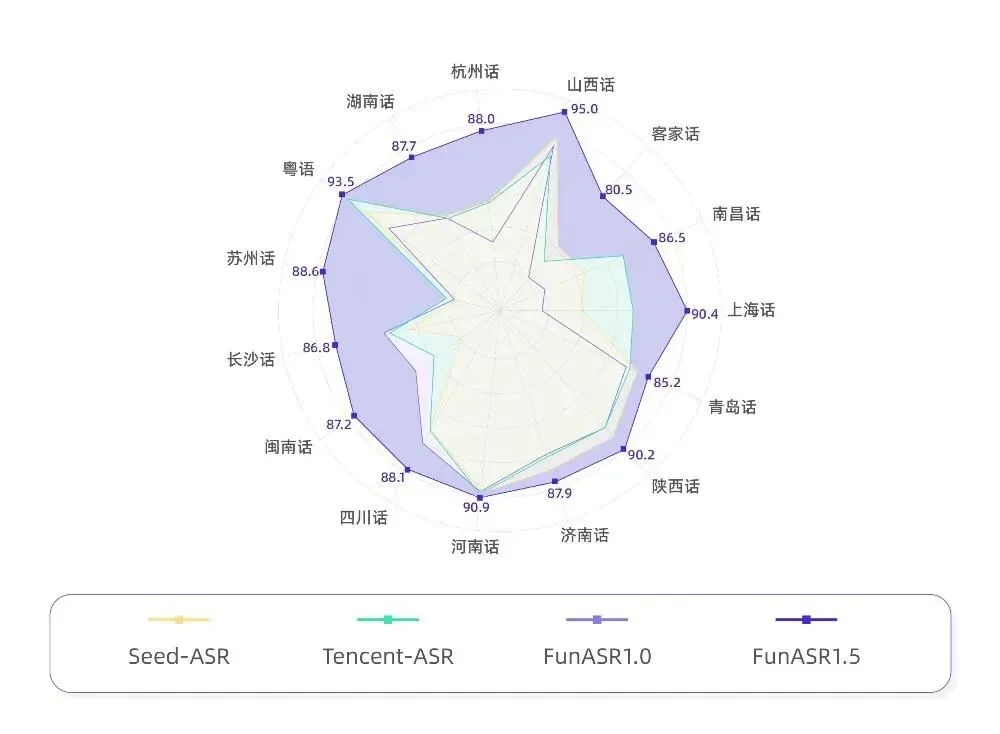
各项指标 SOTA
sherpa-onnx 是新一代一男哥(Daniel Povey,Kaldi 之父)团队的推理框架。它把阿里达摩院的 FunASR 系列模型(SenseVoice、Paraformer)打包成纯 ONNX,提供 C API + 多语言绑定。
三个硬数字说服了我:
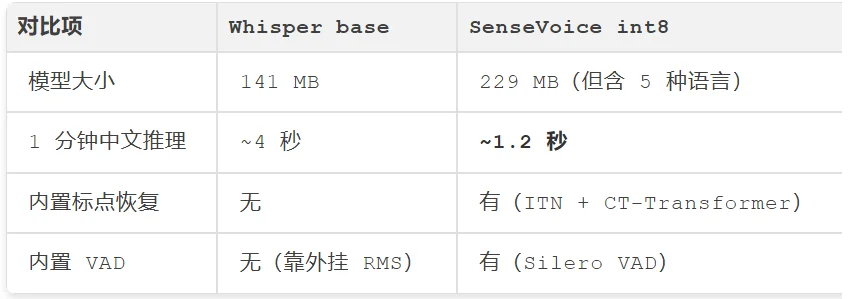
而且 SenseVoice 原生支持中英日韩粤五种语言,不需要指定语言参数就能自动检测。这对多语言会议场景是杀手级功能。
更关键的是:sherpa-onnx 提供了 Rust crate sherpa-onnx,直接 cargo add sherpa-onnx --features static,静态链接进二进制,零运行时依赖。
VoiceVault 在 Phase 1 就抽了一个 LlmBackend trait,让 Ollama 和 OpenAI 共存。这次对转录引擎做同样的事。
核心 trait 只有 3 个方法:
pub trait TranscriptionBackend: Send + Sync {
fn transcribe(&self, pcm_16k: &[f32]) -> Result<Vec<Segment>>;
fn backend_name(&self) -> &str;
fn language(&self) -> &str;}
输入统一为 16kHz mono f32 PCM(这是 Whisper 和 FunASR 共同的要求),输出统一为 Vec<Segment>。调用方不需要知道底层跑的是什么。
FunASR 后端的实现核心大概长这样:
impl TranscriptionBackend for FunasrBackend {
fn transcribe(&self, pcm_16k: &[f32]) -> Result<Vec<Segment>> {
let duration_secs = pcm_16k.len() as f64 / 16000.0; if self.use_vad && self.vad.is_some() && duration_secs > 30.0 {
// 长音频:Silero VAD 切段 → 逐段推理
self.transcribe_with_vad(pcm_16k) } else {
// 短音频:一次性推理
self.transcribe_whole(pcm_16k) } }}
配置切换也是一行 TOML:
# config.toml
backend = "funasr" # 或 "whisper"
[funasr]
model_kind = "sensevoice"
use_punctuation = trueuse_vad = true
不改代码,不改命令行参数。整个 CLI 和桌面端的转录管线自动走 FunASR。
FunASR 模型从 sherpa-onnx 的 GitHub Releases 下载。我按照 README 里的 tag v1.12.39 拼了 URL:
https://github.com/k2-fsa/sherpa-onnx/releases/download/v1.12.39/ sherpa-onnx-offline-punctuation-ct-transformer-zh-int8.tar.bz2
结果:HTTP 404 Not Found。
我确认了三遍文件名没拼错,然后去 GitHub 看那个 release —— 281 个 assets,没有一个叫 punctuation 的。
折腾了 20 分钟后我意识到:sherpa-onnx 的模型不是按版本号发 release 的,是按类型标签发的。
用 GitHub API 扫了所有 releases:
curl -s "https://api.github.com/repos/k2-fsa/sherpa-onnx/releases?per_page=100&page=2" \ | python3 -c "
import json, sys
for r in json.load(sys.stdin):
for a in r.get('assets', []):
if 'punct' in a['name'].lower():
print(f\"{r['tag_name']}: {a['name']}\")
"
输出:
punctuation-models: sherpa-onnx-punct-ct-transformer-zh-en-vocab272727-2024-04-12-int8.tar.bz2
tag 不是 v1.12.39,而是 punctuation-models。而且文件名也完全不同 —— 多了 zh-en-vocab272727 这一段。
逐个验证后发现,四个模型全错:

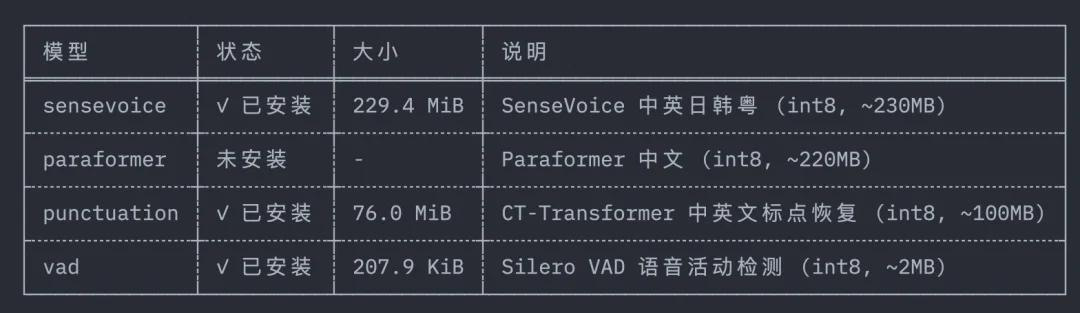
VAD 最骚:别的模型都是 tar.bz2 压缩包,就它一个裸的 silero_vad.int8.onnx 文件,200KB,直接下载。
下载代码得加分支:
async fn download_funasr_model(ctx: &AppContext, info: &FunasrModelInfo) -> Result<()> {
let is_single_file = !info.archive.ends_with(".tar.bz2");
if is_single_file {
// 单文件下载(如 silero_vad.int8.onnx) std::fs::create_dir_all(&local_dir)?;
let target = local_dir.join(&info.archive);
download_file(&url, &target, info.archive).await?; } else {
// tar.bz2 归档:下载 → 解压 → 重命名
download_file(&url, &archive_path, info.archive).await?; Command::new("tar").args(["xjf", ...]).output()?; std::fs::rename(&extracted_dir, &local_dir)?; }}
经验:不要相信 README 里的下载 URL。用 curl -sI <url> 验证每一个。302 重定向 = 存在,404 = 不存在
VoiceVault 的流式转录(实时录音 + 实时出字幕)是整个产品最复杂的组件。上一篇文章用了 2000 字讲它的架构。
问题是:它被 Whisper 硬编码了。
// 改之前:直接依赖 Whisper 的 Transcriberpub struct StreamingTranscriber {
// ...}
impl StreamingTranscriber { pub fn start(cfg: StreamingConfig) -> Result<Self> {
let transcriber = Arc::new(Transcriber::new(&cfg.model_path, &cfg.language)?);
// ... }}
Transcriber 就是 whisper-rs 的封装。想用 FunASR 做流式?整个 StreamingTranscriber 要重写。
但仔细看代码,流式的核心逻辑跟具体后端完全无关:
真正跟后端相关的只有一行:transcriber.transcribe(&pcm)。
于是重构方案很清晰 —— 把 Arc<Transcriber> 换成 Arc<dyn TranscriptionBackend>:
// 改之后:接受任意后端
impl StreamingTranscriber { pub fn start( cfg: StreamingConfig, backend: Arc<dyn TranscriptionBackend + Send + Sync>, ) -> Result<Self> {
let task = tokio::spawn(async move {
run_loop(cfg, backend, input_rx, event_tx, stop_rx).await; });
// ... }}
StreamingConfig 也瘦了 —— 去掉了 model_path 和 language(这些是具体后端的事,不是流式框架的事):
// 改之前pub fn new(model_path: PathBuf, language: String, input_sr: u32) -> Self
// 改之后pub fn new(input_sr: u32) -> Self
调用方(桌面 start_streaming 命令)负责创建后端:
let backend: Arc<dyn TranscriptionBackend + Send + Sync> = match state.config.backend { TranscriptionBackendKind::Funasr => {
let funasr = FunasrBackend::new(&funasr_config)?; Arc::new(funasr) } TranscriptionBackendKind::Whisper => {
let whisper = Transcriber::new(&model_path, &lang)?; Arc::new(whisper) }};let mut transcriber = StreamingTranscriber::start(stream_cfg, backend)?;
重构量:改了 ~50 行核心代码,没增加复杂度,去掉了一个硬编码依赖。所有原有的单元测试继续通过。
这种重构如果在 Phase 1 做就是"过度设计"。但在第五次迭代做,就是"刚好"。好的架构是演进出来的,不是预测出来的。
拉个对比:
Whisper (base) FunASR (SenseVoice int8)
──────────────────────────────────────────────────────────────────────
模型下载 141 MB 229 MB(含 5 语种)
+ 标点恢复 无 + 76 MB
+ VAD 无 + 0.2 MB
──────────────────────────────────────────────────────────────────────
总下载量 141 MB 305 MB
──────────────────────────────────────────────────────────────────────
1 分钟中文推理 ~4 秒 ~1.2 秒
标点 无 自动恢复
语种切换 需手动指定 自动检测
长音频处理 整段推理(30s 限制) VAD 分段推理(无限制)
最明显的改善:
如果你在做本地 ASR/TTS/VAD,sherpa-onnx 的 Rust 绑定值得认真看。它的优势:
缺点:模型散落在不同 GitHub Release tag 里,发现正确的下载 URL 需要侦探技能。
这次迁移的技术收获不在于"用 FunASR 替代 Whisper" —— 那只是换了一行依赖。真正的收获是:
VoiceVault 现在有了真正的实时流式字幕、全文搜索、LLM 行动项提取。全部离线,全部开源,13MB 二进制。
下一步:Silero VAD 替换 RMS VAD 做流式分段,partial 增量复用减少重复推理。做完这两件事,流式转录就真正到"生产级"了。
开源地址:http://github.com/coder-brzhang/voicevault
注意,本项目仅在小张的400 多个人的小群(公众号菜单-联系我-加群)中分享。
文章来自于"老码小张",作者 "小张"。



【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
