# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

2026年的AI视频生成赛道,已经拥挤到连空气都变得稀薄。
从OpenAI的Sora到谷歌的Veo3,从字节的Seedance到快手的可灵,以及各路创业公司的模型,"百模大战"进入最惨烈的阶段。行业共识是:做视频生成模型,需要百人团队、千万卡时、亿级美元,以及至少一年的研发周期。
但就在这个被认为"只有巨头才能玩得起"的牌桌上,一群从未露面的年轻人,用一组近乎夸张的数据,把行业共识撕开了一个口子。
10个人。2个月。64张H100。
3月中到5月底,这支团队交付了业界首个22B参数的流式音视频模型—— MaineCoon v1.0。单卡H100实现47.5 FPS实时推理,生成成本压到Veo3的两千分之一,首次实现30min以上生成。
这家公司叫catnip.ai。这是他们的第一次公开发布。
支撑这一切的,是一个小到令人难以置信的团队。catnip.ai全公司10个人,一张合影就能装下,还没有一家中型奶茶店的排班表长。
创始人杨姝瑞是连续创业者,前TikTok、PixVerse产品负责人,推动过多款爆红特效模板的0-1落地。负责核心算法的谢泽柯,是香港科技大学(广州)助理教授——中科大本科、东京大学博士、前百度研究院,长期担任NeurIPS、ICLR、ICML等顶级会议的领域主席,现以首席科学家身份全职加入。其余产研成员来自字节Flow部门和豆包团队,一支标准的"字节系"精锐小队。
公司叫catnip(猫薄荷),模型叫MaineCoon(缅因猫),团宠却是一只叫77的小狗。代码跑到卡壳,有人会突然喊一声"77呢",那只小狗就从某个工位底下钻出来,摇着尾巴接受一轮集体撸毛。明明在做一件很硬核的事,却保留着一种近乎幼稚的松弛感,这是这支团队最显眼的气质。


这种松弛感,恰恰来自他们过去的艰难思考。
catnip并不是一开始就想做模型。杨姝瑞最初的目标很直接:做一款面向C端的互动视频应用。但做到一半,团队发现了一个冰冷的数字现实——一旦让视频真正人人"可交互",成本会指数级增长。如果直接接入现有模型的API,产品的商业模型根本跑不通。
调研了一圈市面上的互动类产品,他们发现互动视频之所以至今只停留在PGC层面——互动剧情游戏、互动短剧——而没能诞生真正的大众化产品,根源就在于供给成本太高。更深一层的问题是,现有模型从第一天起就是为PGC内容设计的,天然缺乏UGC内容该有的"活人感"和"网感"。抖音本质上是一个PGC平台,而PGC之所以能成立,恰恰是因为有海量UGC作为底座。任何UGC模式的产品爆发,前提都是供给成本降到足够低。
"什么时候模型能够像水一样,极速又便宜?"杨姝瑞意识到,答案只有一个:自己动手,把模型做得够轻、够小、够快。团队决定以愚公移山的方式,自研模型来突破这个通往梦想中途的难点。
这个转向是冒险的,但执行速度却快得惊人。3月中启动,5月底交付,2个月内不仅产出了SOTA模型,还同步完成了训练架构、数据Infra、推理系统的全部基建。64张H100,在动辄千卡集群的AI军备竞赛中几乎可以忽略不计,却产出了业界最快的流式音视频模型。
秘密不只在于技术,更在于一种反传统的组织设计。
据团队透露,他们的组织有两大特征。第一,目标愿景高度一致。团队里的每个人都相信:大量AI模型正在解决"智能"的瓶颈,这会解放人类,去除人身上的工具属性;而catnip的目标,是让被解放的人类在互动世界中感到幸福和快乐。这个愿景提前划定了公司的边界,让每个人的行动动机高度一致——这里没有浑水摸鱼的打工人,只有通往同一个方向的同行者。
第二,激进地使用"主题式分工",而非传统的"上下游分工"。按工作主题和领域切分,而非按职能流水线切分。比如这次模型的官网,由一位产品经理+设计师+开发闭环完成,基础架构同学只提供底层支持。这种分工避免了传统互联网式协作中大量的信息摩擦和等待成本,代价是对每个人的综合素质要求极高。catnip相信,AI时代的公司,人才是灵魂,产品只是灵魂长出来的手和脚。
这些设计的结果是近乎偏执的凝聚力。大家彼此背靠背,深夜群里喊一声,还都在线。有时搞到凌晨两三点,但没有人抱怨。他们有一个共同的使命,写在博客的最后一段:AI应该去除人身上的工具属性,让人类感受到更幸福。MaineCoon是他们通往这个愿景的第一个入口——一个可实时交互的世界。
理解了catnip是谁、为什么出发,才能理解他们为什么选择了一条与行业主流截然不同的技术路线。
AI视频生成领域有一个长期被忽视的悖论。现有的T2AV(Text-to-Audio-Video)模型,无论画质多么精美、动作多么流畅,都有一个致命的结构性缺陷:它们必须"整段生成完成后才能播放"。这意味着,用户输入一段提示词,可能需要等待数分钟甚至数十分钟,才能看到结果。在这个即时反馈成为本能的时代,这种延迟是致命的。
更重要的是,这种"离线生成"模式从根本上排除了互动的可能性。你无法与一个需要几分钟才能回应的AI进行实时对话,也无法在直播、社交、游戏等场景中部署一个"先思考再说话"的智能体。
行业并非没有意识到这个问题。加速方案层出不穷,但大多数都陷入了一个三角困境:要速度,就得牺牲画质;要画质,就得接受延迟;要降低成本,就得压缩模型规模。三者不可兼得,似乎成了铁
MaineCoon的解法,是从架构层面重新定义"生成"本身。
它不是先做完再播放,而是"边生成边播放"。0.64秒为一个生成单元,首帧在1秒内响应,随后像水流一样持续向前。这种Streaming-Native的设计,不是把现有模型改得更快,而是从一开始就为实时流式场景而生——从数据基础设施、训练框架、注意力模式、上下文分布、KV-Cache使用,到最终的推理部署,全链路围绕"实时"重新设计。

速度数据是惊人的:单卡H100达到47.5 FPS,单卡RTX Pro 6000达到30 FPS。作为对比,市面上其他流式音视频模型,在同等配置下的速度往往只有它的七分之一。
但真正的颠覆在于成本。饱和状态下,MaineCoon的生成成本在GPU吃满时,是每秒0.00025美元——Seedance 2.0的五百分之一,Veo3的两千分之一。当生成成本趋近于零,商业模式的想象空间被彻底打开。
流式生成带来了一个更深层的技术挑战:时间。
生成单元越小,跨时间段保持画面一致性、视觉稳定性以及音视频同步性的难度就越高。就像用极小的砖块砌一座无限长的墙,每一块砖都要与前后完美咬合,稍有偏差,整座墙就会歪斜、崩塌——业内称之为"Drift"(画面畸变)。
这是流式生成的阿喀琉斯之踵。大多数模型在生成几分钟后,画面质量就会明显下滑,角色变形、场景跳跃、音画不同步。超过10分钟的连续生成,几乎是一个无人区。
catnip.ai的团队为此首创了Agentic Streaming Inference(智能体流式推理)框架。简单来说,他们给模型装了一个"记忆系统"和"规划系统":通过智能体缓存管理、Chunk Commitment、长上下文Rollout和Prompt Planning,模型能够主动管理自己的生成历史,预测未来的内容走向,并在长达30分钟以上的连续生成中,保持时间一致性和音视频同步。

这不是简单的技术优化,而是推理范式的跃迁。从"一次性生成一段视频"到"持续维护一个连贯的音视频世界",MaineCoon证明了:流式生成不仅可以很快,还可以很长。
如果MaineCoon只是一个更快的视频生成工具,那它至多是一家优秀的工程团队。但catnip.ai的野心,藏在他们对产品定位的重新定义里。
"社交世界模型"(Social World Model)——这是他们自己创造的概念。
现有的世界模型,无论是模拟物理环境的机器人训练系统,还是探索游戏世界的AI Agent,大多聚焦于"物"与"空间",而非"人"与"关系"。它们缺乏对人类社交动态的理解:情绪的微妙波动、对话的回合节奏、关系的亲疏远近。
catnip.ai认为,下一代AI-native社交平台的基础设施,不是一个内容生成器,而是一个能够主动观察、内部模拟、实时反应的"社交生命体"。
他们为此设计了三层架构:
感知层(Observation),处理面部表情、语气语速、表述方式等多模态信号,提炼为潜空间中的用户社交状态。这不是简单的"识别你在笑",而是理解"你为什么笑"。
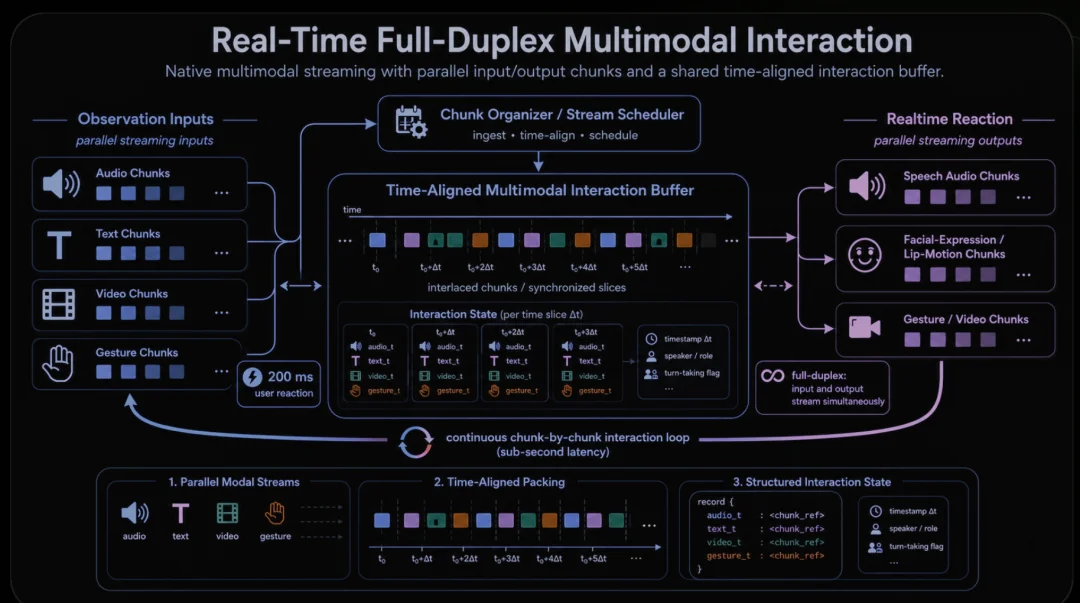
图片说明:全双工观察路径:音频、文本、视频、手势、表情和语调块并行流式传输,在时间对齐的交互缓冲区中进行组织,并在连续的低延迟循环中连接到实时输出
模拟层(Simulator),通过Latent Dynamics Model结合感知层的状态信息,产出一系列候选行动集——安抚、询问、开玩笑、沉默——并通过社交互动预测,确定最优行为。这是模型的"大脑",负责决策。
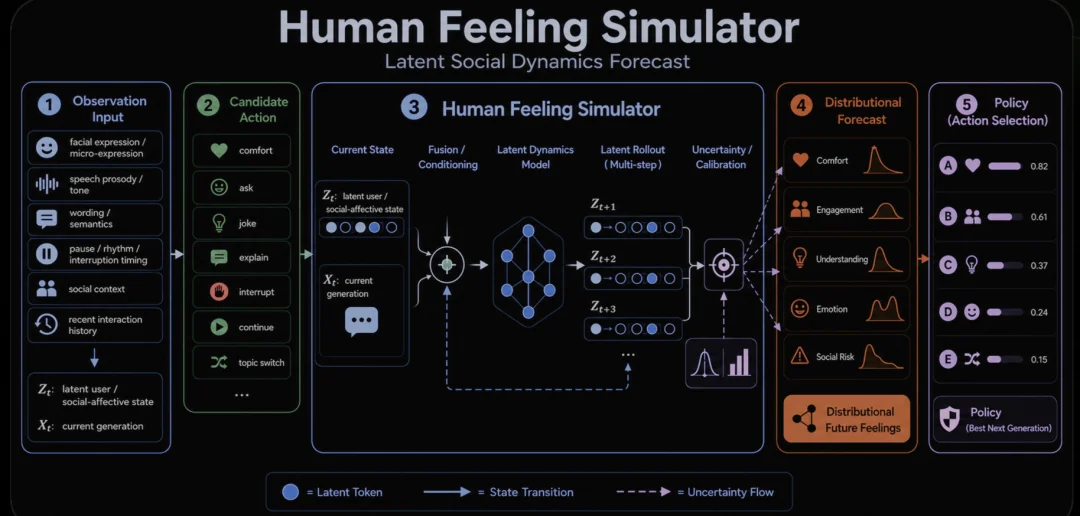
图片说明:人类感知模拟路径:候选行动通过模拟器进行测试,该模拟器可以预测情绪、参与度、信任度和下一步反应,然后将结果反馈到政策选择中。
渲染层(React),围绕社交互动预测,极速、实时、稳定地生成音视频画面。这是MaineCoon v1.0当前的核心能力,也是最终面向用户的出口。

为什么要从渲染层切入?创始人杨姝瑞的解释很直接:渲染层是最终出口,也是技术最难的部分。更重要的是,业界长期缺乏一个"极速推理+低成本+画质优异"的流式音视频模型,这是当前市场最大的缺口。先把最难的骨头啃下来,上面的两层才有落地的可能。
这个逻辑,与当年字节跳动先做推荐引擎、再做内容生态的路径,有异曲同工之处。
1950年,图灵在《计算机器与智能》中发问:机器能思考吗?76年后,这个问题有了一个新的变体:机器能社交吗?
MaineCoon是catnip.ai给出的第一份答卷。它不是终点,而是起点——一个面向实时、长时程交互而设计的Streaming-Native T2AV模型,一个社交世界模型的生成核心。
当生成成本压到近乎为零,当延迟压到1秒内,当时长突破无限——AI-native平台的底层基础设施才真正就绪。届时,我们面对的将不再是一个"生成视频的AI",而是一个能够主动理解、响应、记忆我们情绪及社交关系的"数字生命"。
10个00后,用2个月、64张卡证明了一件事:在这个时代,世界模型不需要百人团队、千万卡时。需要的是对场景的极致理解,对AI-Native研发范式的信仰,以及一群愿意把凌晨两三点当作常态的疯子。
AI视频生成的"百模大战"还在进行。但catnip.ai的出现,让这场战争的规则开始松动。当成本不再是门槛,当速度不再是瓶颈,当团队规模不再是护城河——真正决定胜负的,将是谁更理解"交互"这两个字的分量。
毕竟,人类发明视频,从来不是为了看机器表演。而是为了,被看见。
文章来自于"Z Potentials",作者 "Z Potentials"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
