# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一个开源的省Token工具Headroom,火了!
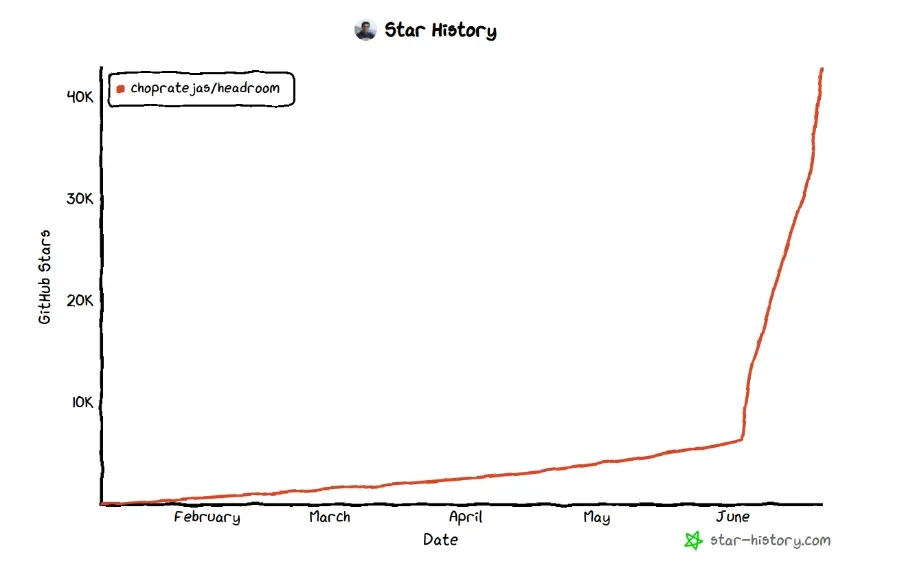
Headroom Star History,6月后项目热度快速上涨
Trendshift页面显示,Headroom在6月2日第一次冲到GitHub Trending第1名;Star History曲线也能看到,项目热度6月后明显上升。
根本原因是因为AI编码工具开始跑长任务后,token不够用了。
截至6月22日,公开页面显示Headroom已有4万多个star,最新版本是v0.26.0。一个“上下文压缩层”工具能到这个热度,已经说明很多问题。
如果你经常用Codex、Cursor、Claude Code写代码,大概率会遇到一个很微妙的问题。
刚开始确实爽。AI能写代码、修Bug,自己循环验证。可一旦任务稍微变长,token的消耗就开始起飞。模型还没正式开始写代码,光是“读材料”就先烧了一大截上下文。
插件Headroom,专门处理这种问题:在内容进入大模型之前,先把上下文压缩一遍。
它更像AI Agent和大模型之间的一层“上下文压缩器”。
官方介绍写得很简单:压缩工具输出、日志、文件和RAG chunks,减少60%到95%token,同时尽量保持答案不变。

Headroom官方Demo,展示压缩前后的token变化
Headroom的定位不难理解。
你让AI Agent干活时,它会不断把信息喂给模型:工具返回、终端日志、测试结果、文件内容、RAG检索结果、对话历史。
Headroom在这些内容和模型之间,先判断内容类型,再选择压缩方式。
官方列出的用法也比较直接。
·库模式:用`compress(messages)`接到Python或TypeScript应用里。
·代理模式,用`headroom proxy --port 8787`放在模型API前面,尽量不改业务代码。
·代理包装,用`headroom wrap claude|codex|cursor|aider|copilot`包住常见AI编码工具。
·MCP服务,用`headroom_compress`、`headroom_retrieve`、`headroom_stats`给支持MCP的客户端调用。
它还做了跨代理内存、`headroom learn`、输出token缩减等能力。更棒的是,它没有逼开发者换工作流,而是尽量塞进已有工具链。
Headroom支持库、代理、agent wrap、MCP server等多种形态
Headroom官方说,在真实Agent工作环境里,token可以减少60%到95%。
当然,不能所有的任务都能稳定的省95%token。但是它确实解决了AI编程中最浪费的一类任务。
终端日志很典型。
很多日志会重复路径、warning和堆栈。模型并不需要逐字读完,只需要知道哪里失败、错误类型是什么、和哪个文件有关。
JSON输出也一样。接口返回可能有几十个字段,但模型经常只需要状态、错误码、关键字段和少量上下文。
测试结果也是重灾区。跑测试时,模型真正需要的是失败用例、断言位置、异常信息和相关文件,不一定需要完整输出。
代码搜索、RAG文档片段、历史对话也是同一类问题。它们都可能很长,但不是每个字都对当前任务有价值。
这就是Headroom的价值。它不是让模型更聪明,只负责让模型少读无关材料。
普通摘要有个麻烦:压掉的信息,如果后面要用,可能就没了。
这在AI编程里很危险。比如日志里某一行错误、JSON里某个字段、测试输出里的某个断言,摘要阶段一旦漏掉,后面模型就可能判断错。
Headroom的思路是可逆压缩。它会把原始内容缓存在本地,先让模型浏览压缩后的版本。如果模型后续需要细节,可以通过`headroom_retrieve`把原文取回来。
这个设计很适合Agent。Agent做任务不是读完就结束,它会不断试错、验证、回查。先看短版,需要时再翻原文,比一次性把所有内容塞进上下文更像工程系统。
Headroom的工作原理图里,有几个点值得开发者看。
它运行在本地,官方写的是“your data stays here”。这对企业内部代码、日志和文档很重要,因为很多上下文不适合直接交给外部服务处理。
它有ContentRouter,会检测内容类型,然后选择不同压缩器。
SmartCrusher主要处理JSON,CodeCompressor主要处理代码AST,Kompress-base处理文本。CacheAligner用来稳定前缀,让模型供应商的缓存更容易命中。CCR负责把原始内容留在本地,方便后续回查。
换句话说,它会按内容类型做压缩、缓存和回取,路线比普通摘要更工程化。

Headroom官方工作原理图,内容会先经过本地压缩和路由
Headroom最适合的场景,正好是很多开发者每天都在用的AI编码工作流。
你经常让Codex或Claude Code跑测试、读日志、修bug,它就有用。
你用Cursor改大型仓库,经常让模型读文件、扫引用、看输出,它也有用。
你在做RAG Agent或企业内部Agent,每次检索都会返回一堆文档片段,它更有用。
你们团队已经开始关心AI编码成本,或者发现Agent一跑长任务就很贵,这类工具就值得使用。
它不太适合轻度用户。如果你只是偶尔问几句代码,或者改一个很短的单文件脚本,Headroom可能帮不上太多。它真正发挥作用的地方,是长任务、大输出、多工具调用的Agent场景。
这个工具很香,但不能神化。
日志、JSON、重复工具输出、RAG文档片段,这些内容确实适合压缩。复杂代码语义、安全审计、线上事故排查、金融和医疗类系统,就要谨慎很多。
因为有些任务依赖细节。异常堆栈里一行看似无关的内容,可能正好指向根因。JSON里某个字段看着不起眼,可能影响权限判断。代码审查里一段上下文被压掉,模型可能就看不出设计风险。
所以真正要注意的,不只是token省了多少,还要注意任务成功率、回查次数、误判成本和修复质量。
如果只是把上下文压短,但AI修错了方向,省下来的token很快会在返工里烧回来。
Headroom这个插件的出现,不只是能省token,还在提醒开发者:AI编码工具越来越像一个工程系统。以前我们优化数据库查询、缓存和接口响应,现在用AI写代码,也要优化模型看到的上下文。
Codex、Cursor、Claude Code越能干,喂给它们的东西也越多。日志、工具输出、历史对话、RAG文档、文件内容,都在变成AI编程成本的一部分。
Headroom这种工具走红,说明开发者开始意识到:AI Agent不只要会干活,还要减少浪费。
如果你已经开始觉得AI编码账单肉疼,或者Agent经常被一大堆输出淹没,Headroom可以试一试。
参考链接
https://github.com/chopratejas/headroom
文章来自微信公众号 “ 51CTO技术栈 ”,作者 “ 大石 ”



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
