# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
零一万物API开放平台,正式向开发者开放了!
零一万物Yi大模型API开放平台推出后,更多开发者可以直接调用,围绕着Yi大模型,会发展出更加繁荣的生态,促成模型在更多应用场景的落地。
平台地址:https://platform.lingyiwanwu.com/playground
而在此前,Yi系列模型凭借着国际SOTA的性能、训练成本友好和更懂中文等优势在全世界AI社区中名声大震,开源的Yi系列模型,已经是开源社区一股不可小觑的中国力量。
开源模型、开放API、打造To C超级应用,零一万物正在一步步践行着CEO李开复博士的大模型商业化方法论。
此次API开放平台,提供了以下三个模型——
目前,Yi大模型API名额已经开放,新用户申请成功即送60元体验。折算下来也有百万甚至千万token了。

去年底,零一万物就正式开源了Yi-34B大模型,具备了处理200K上下窗口的能力。
这一次,性能更强的多模态模型,更专业的推理模型,和OpenAI API随意切换的兼容性,以及超低的价格,都让用户们惊喜无限。
多模态单挑OpenAI:中文图表体验出众,GPT-4V幻觉严重
这一次,针对实际应用场景,多模态模型Yi-VL-Plus能力得到了显著增强。
比如Charts, Table, Inforgraphics, Screenshot识别能力,还可以支持复杂图表理解、信息提取、问答以及推理。
举个栗子,找一张有些重影的图片,让模型去识别「这是什么店」。

Yi-VL-Plus准确给出了店名,并解释了这个店铺是做什么的。
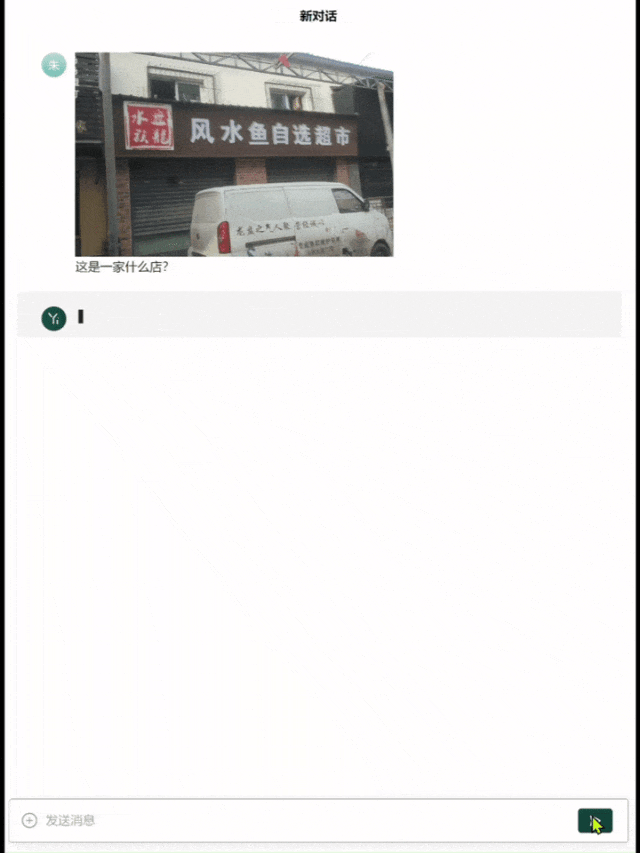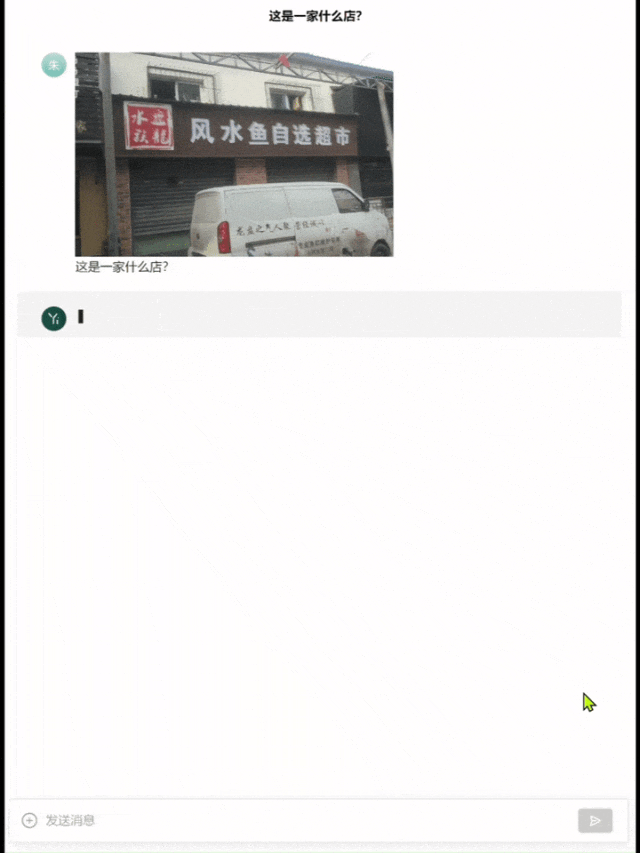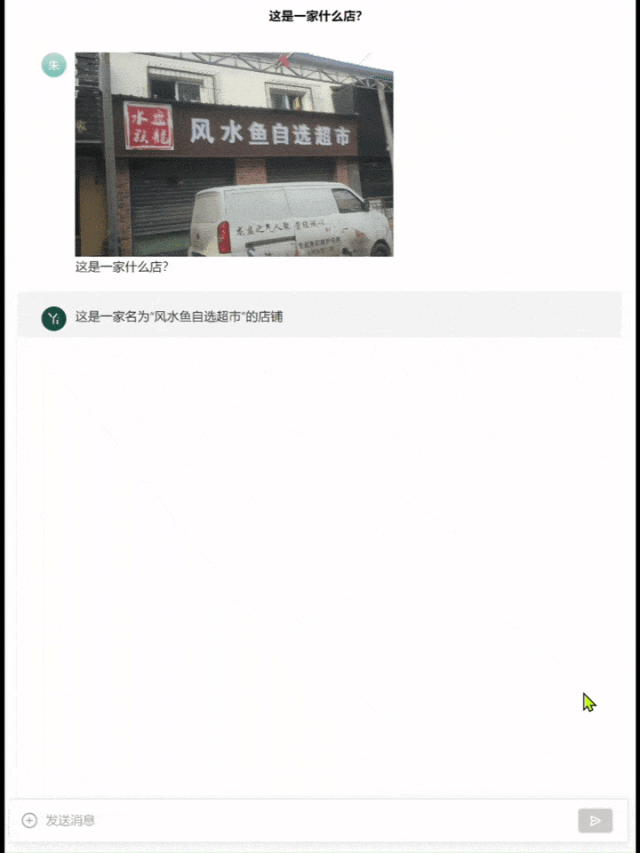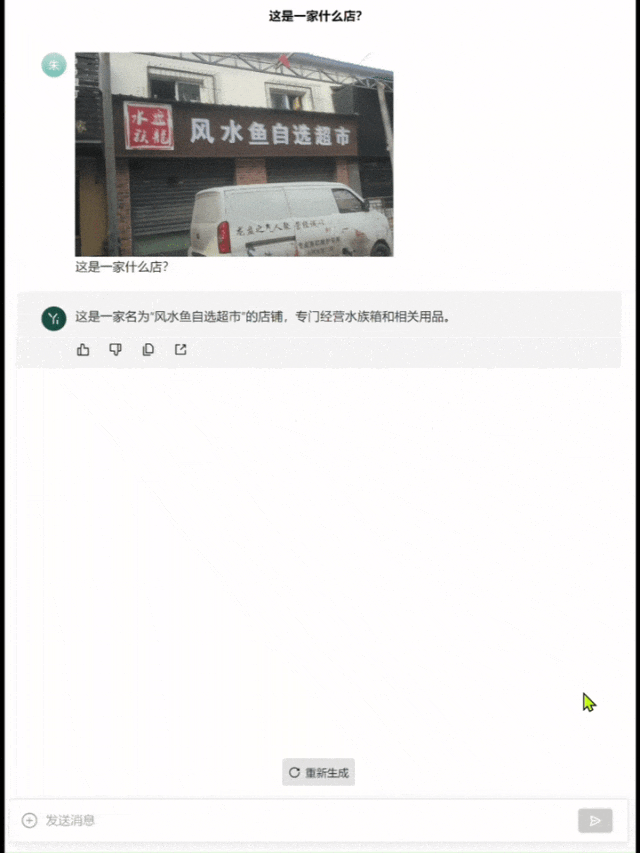
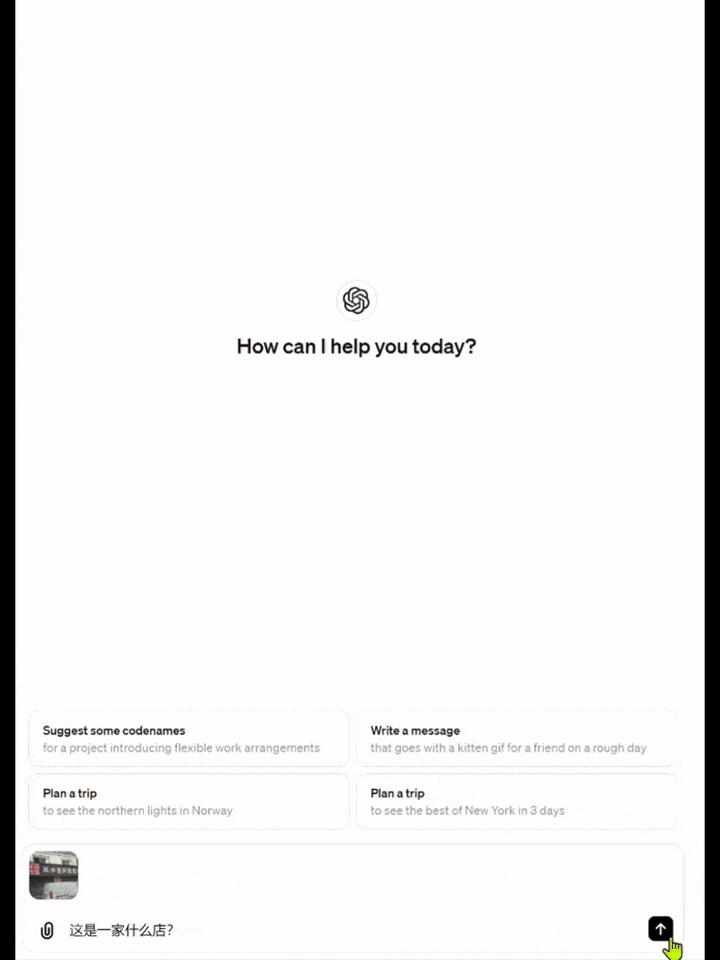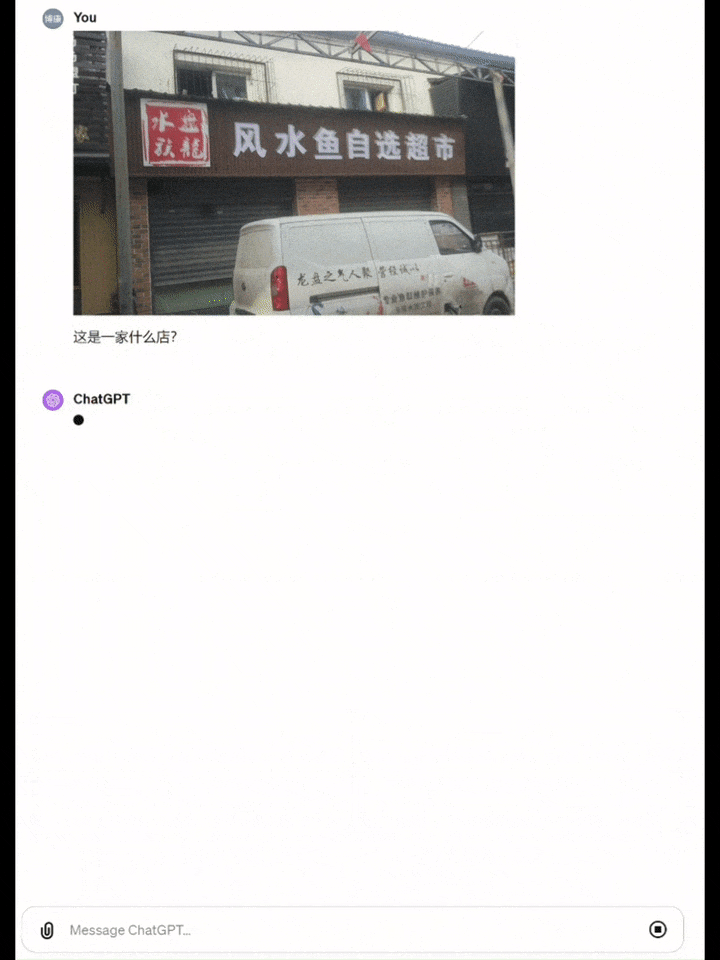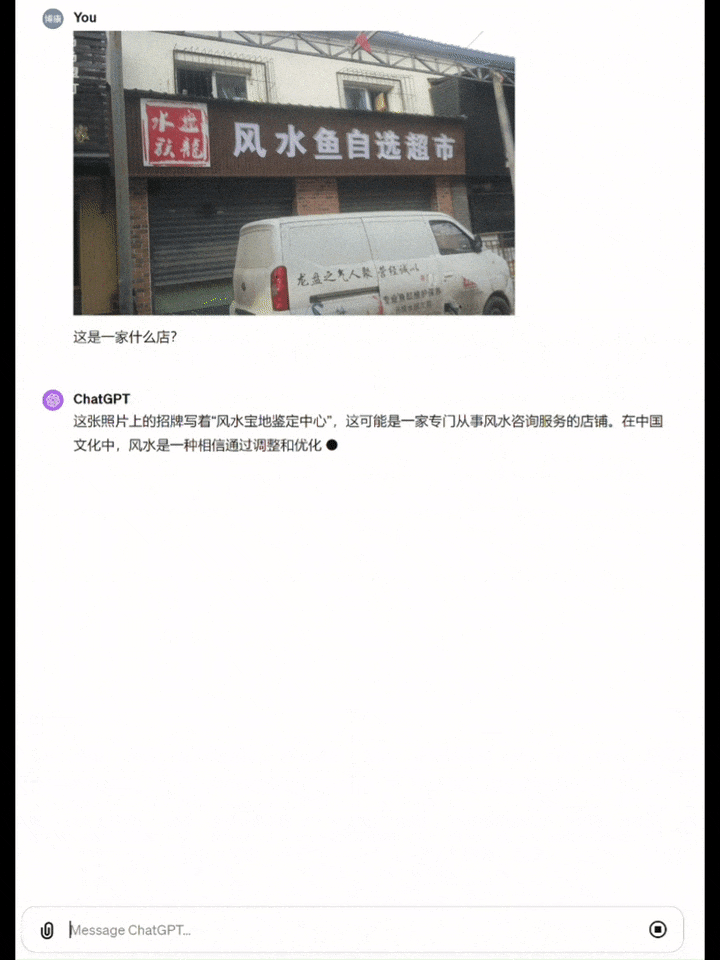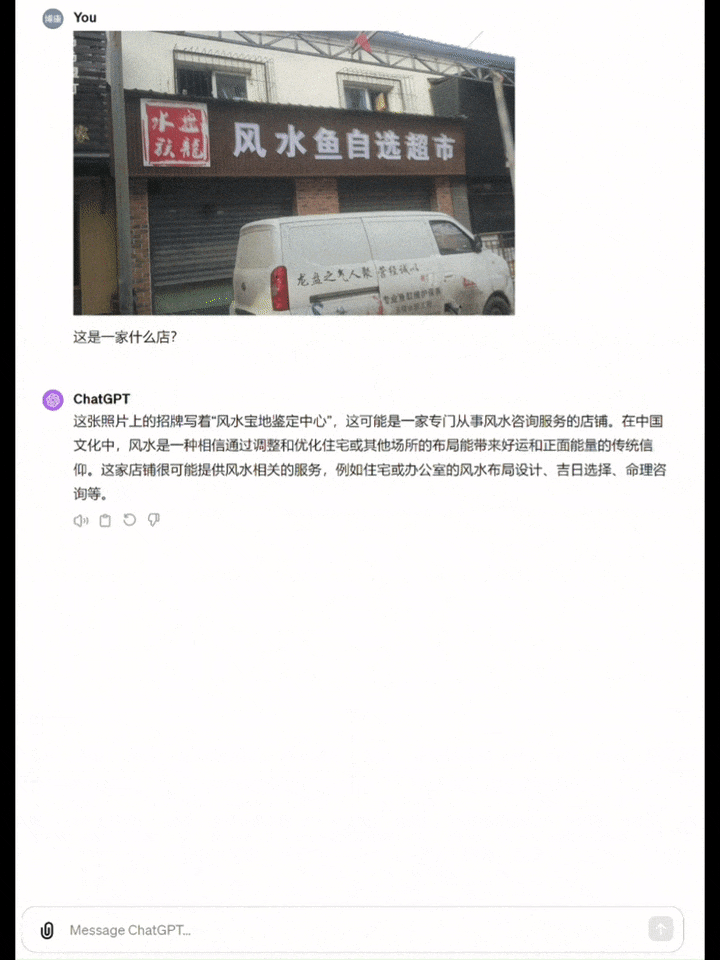
而GPT-4直接识别成了「风水宝地鉴定中心」……
值得一提是,中文图表的体验,Yi-VL-Plus通常也优于GPT-4V。
新升级模型在Yi-VL基础上进一步提升图片分辨率,支持1024*1024,明显提升了场景中文字、数字OCR识别准确性。
下面这张图表中,表格内容繁杂,而且分辨率很低。
若想准确识别图中信息,对于模型来说,确实是一个不小的挑战。
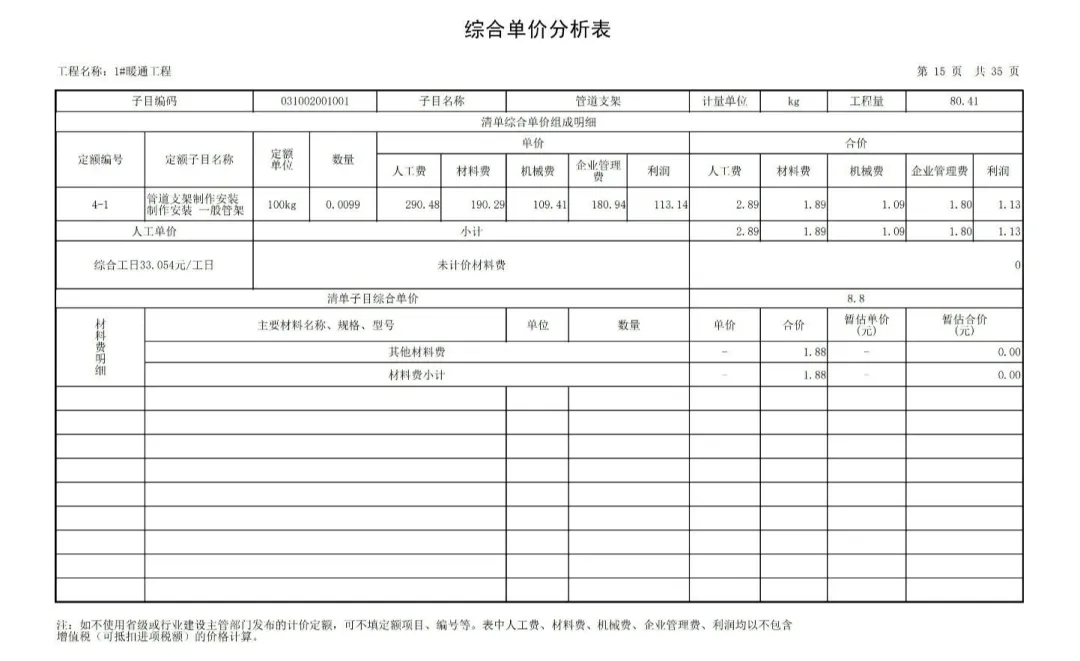
不过,当询问「暖通工程的人工单价是多少」,Yi-VL-Plus一眼就看出了33.054元/工日。

GPT-4V表示由于图像清晰度和视角问题,无法看出具体细节。
当然,Yi-VL-Plus的多模态能力,不仅仅局限于识别,还可以将图片中的内容,转换成你想要的格式。
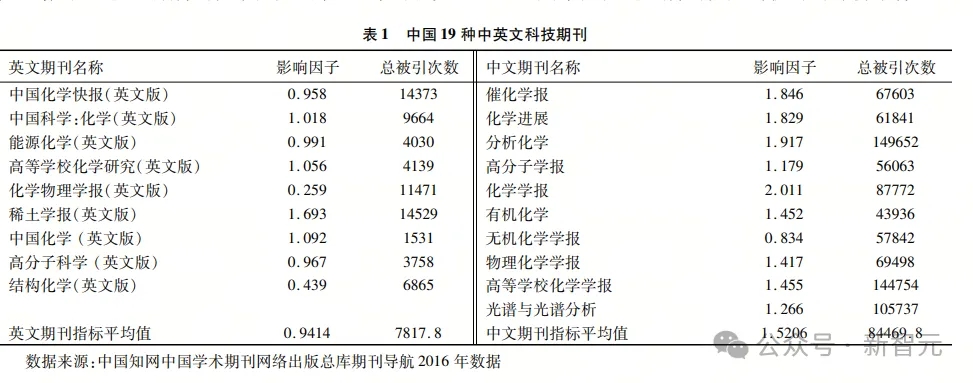
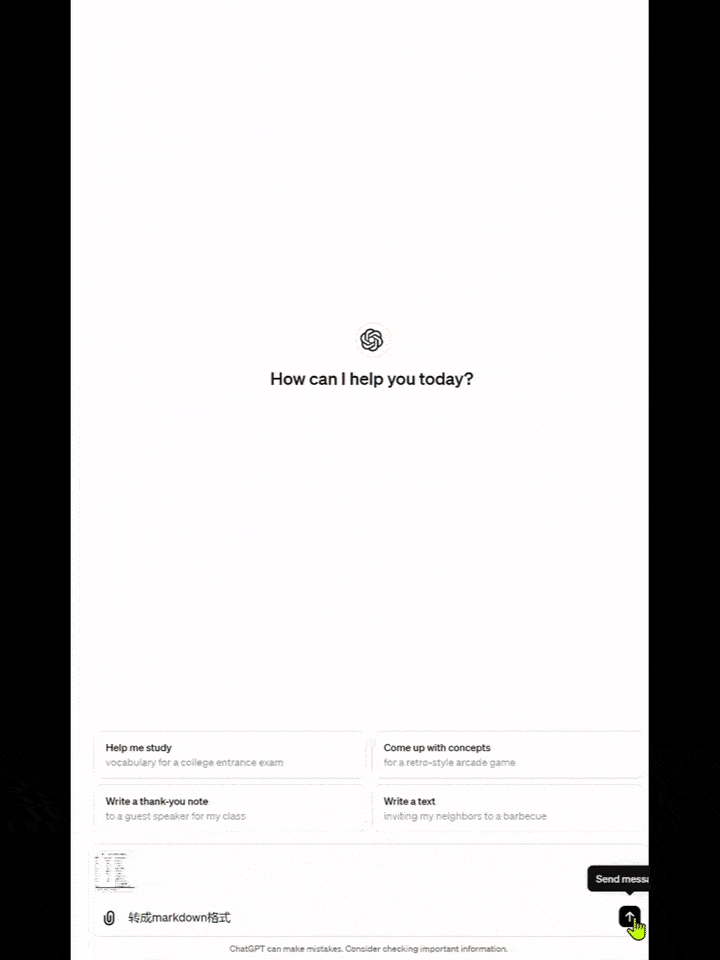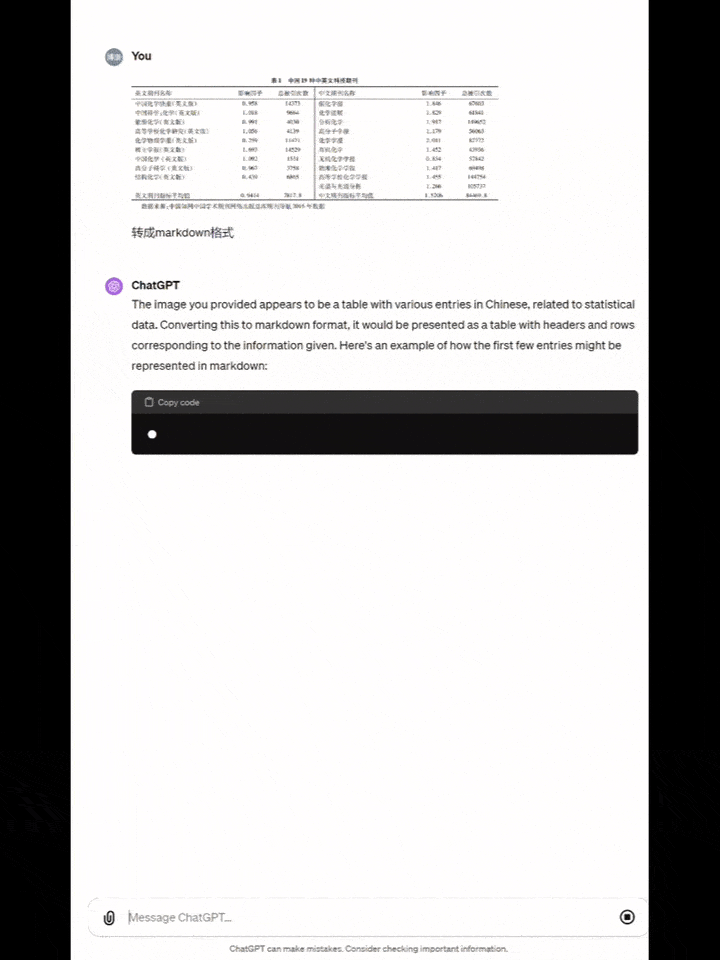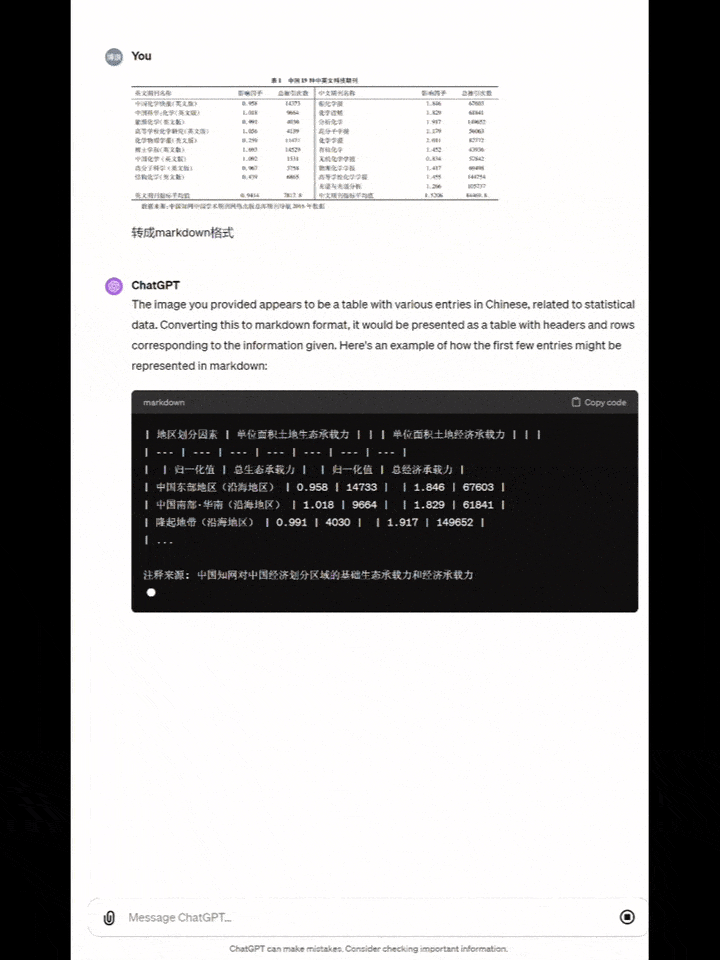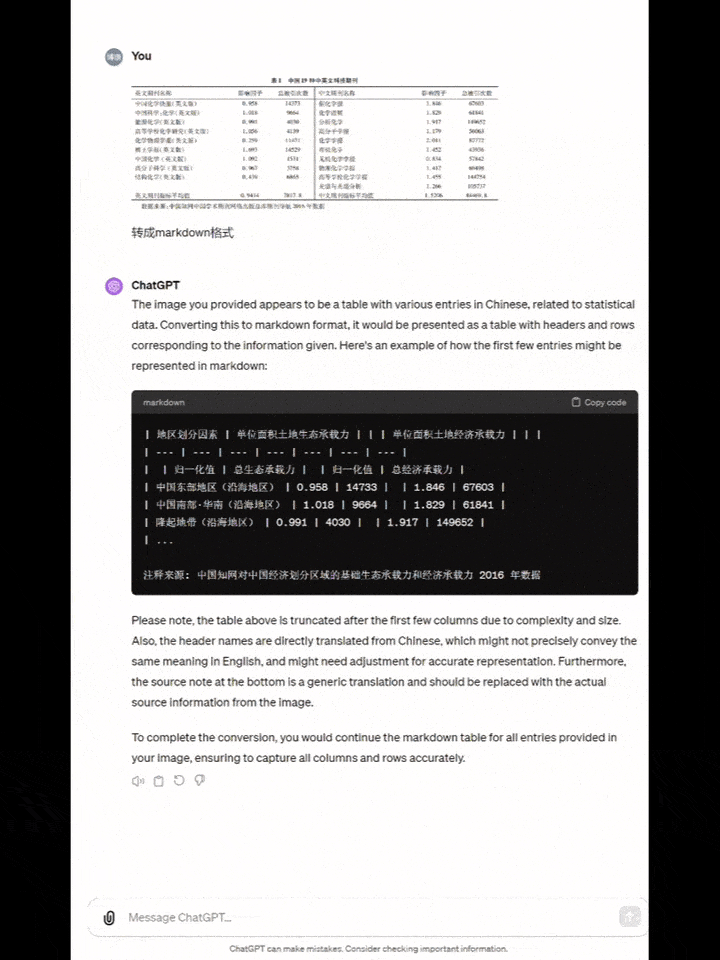
要求模型将中文图表转成markdown格式。
Yi-VL-Plus从表头到每列每行的文字,标点符号,甚至是英文期刊中一个空行,全部准确准换。

而GPT-4V又开始了自己的胡言乱语......
除了表格,Yi-VL-Plus还可以用中文来详细分析不同类型电池市场份额的饼状图。
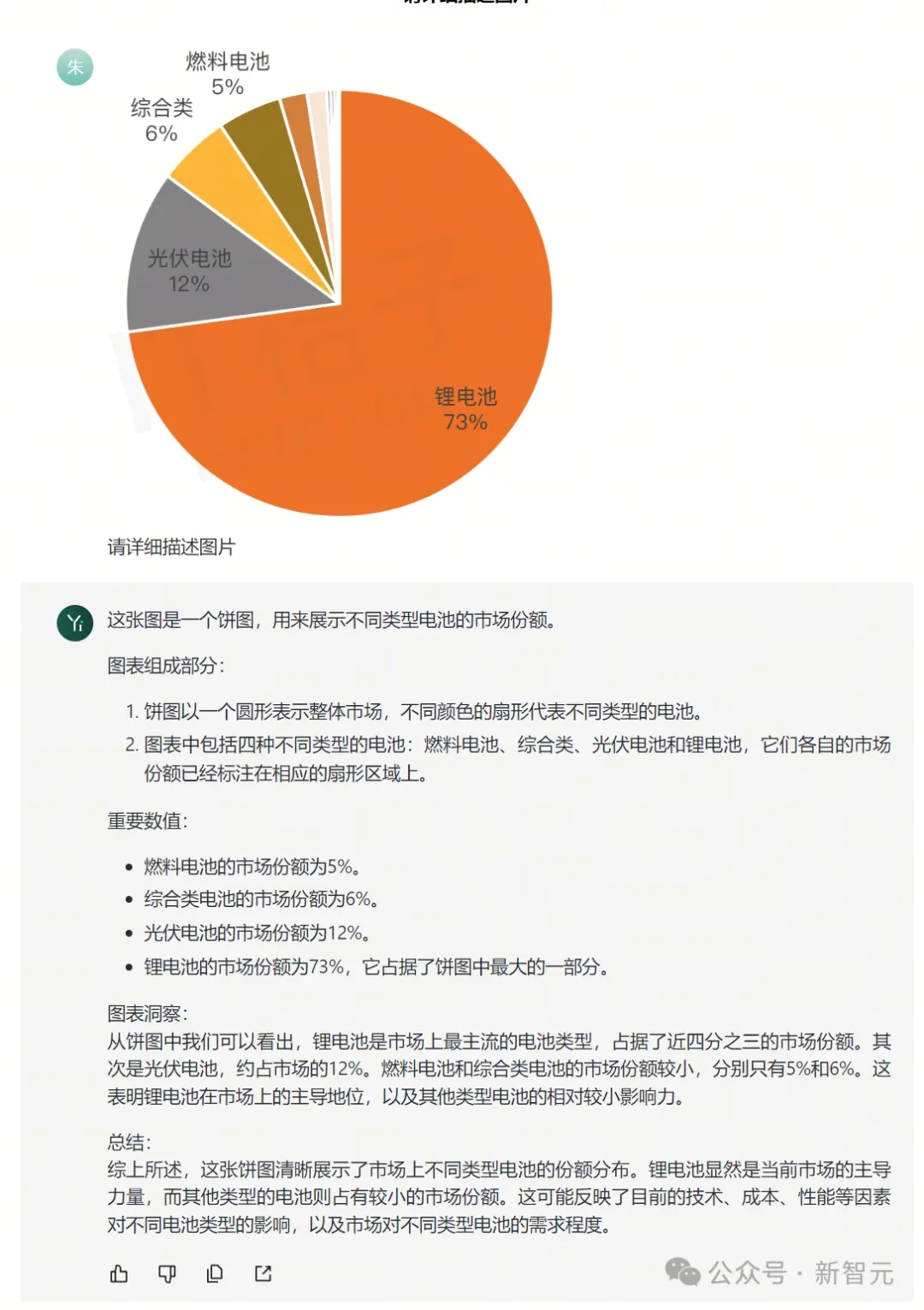
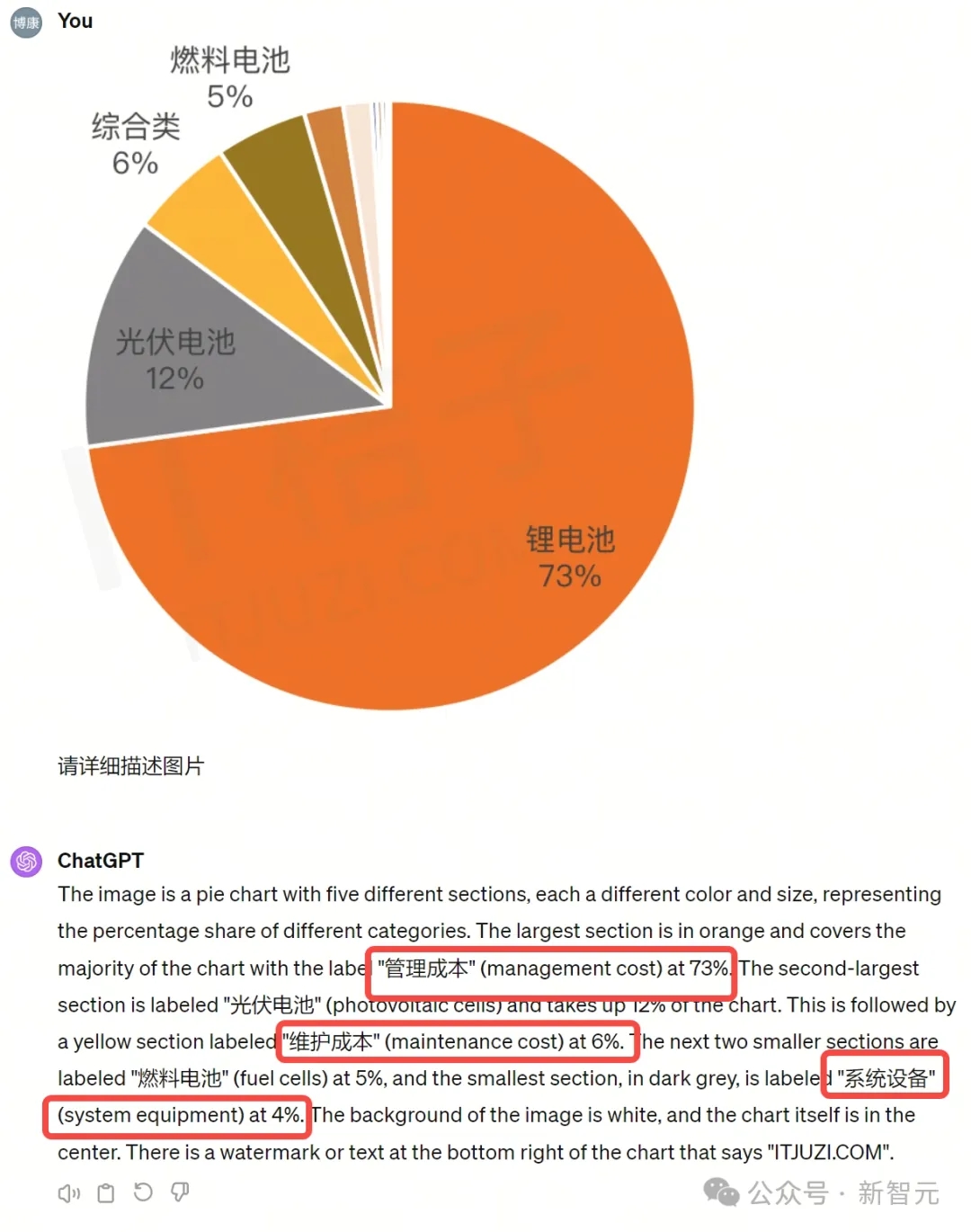
而GPT-4V再次暴露了自己最大的缺点:无法正确认出饼状图中的中文字。
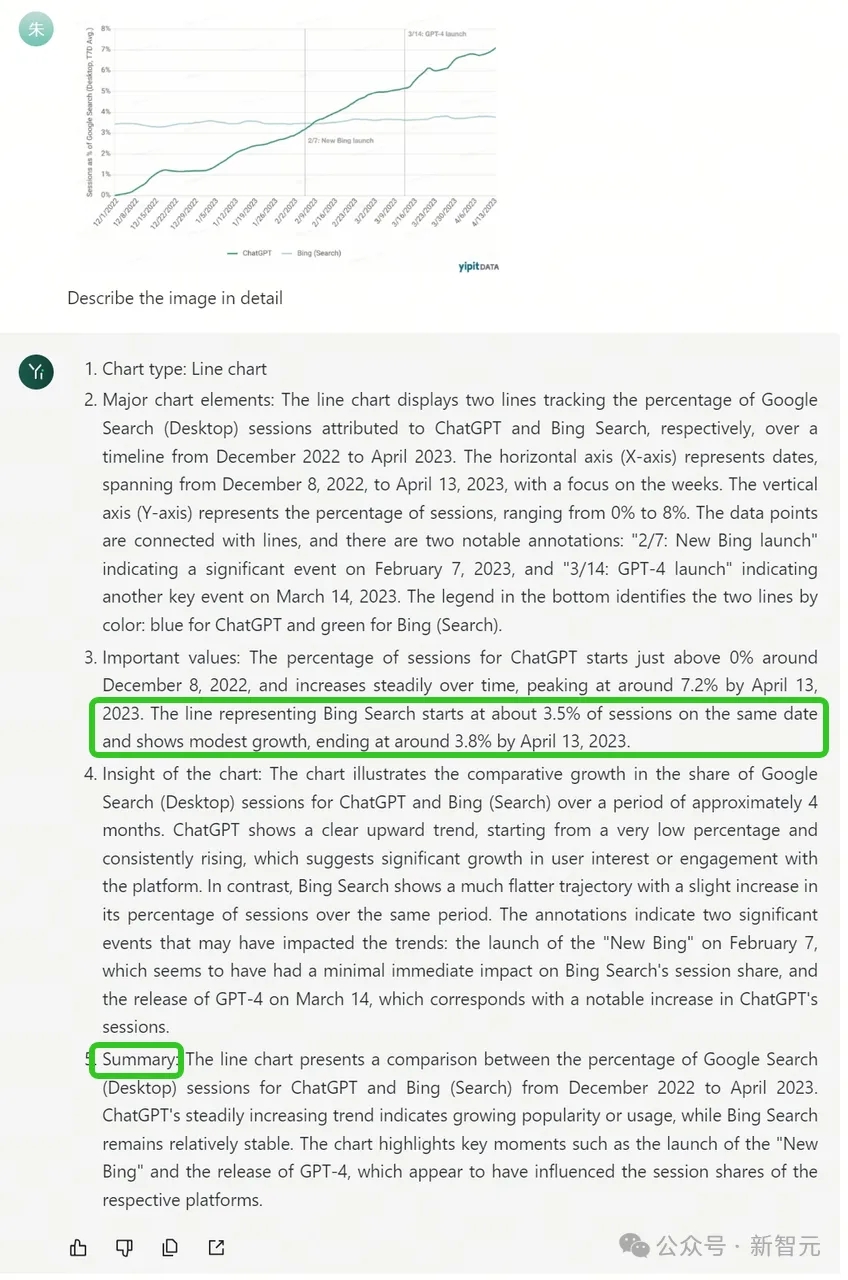
比起GPT-4V,Yi-VL-Plus对于折线图的分析更全面,数值也更精准。
下面这张图,比较了GPT-4和New Bing在谷歌搜索量上的变化。
Yi-VL-Plus十分精准地识别出:从2022年12月8日起,ChatGPT的百分比就开始随着时间推稳步增长,到2023年4月13日达到了7.2%的峰值。
而代表Bing搜索的线,在同一天是百分比为3.5%,随后一直保持温和缓慢的增长,在2023年4月13日结束时,大约停在3.8%。
而GPT-4V读图的过程中就出现了重大错误,比如把ChatGPT 2022年11月所占的百分比识别为了1%。但实际上图表中的时间是从2022年12月开始的。
而把Bing这段时间的百分比识别为了3%到5%,数字也不够精确。

此次Yi-34B-Chat-200K的开放,让大模型应用彻底进入了长文本时代!
无论是多篇文档内容的理解,海量数据的分析和挖掘,还是跨领域的知识融合,它都可以游刃有余地掌握。
在业界知名的「大海捞针」测试中,Yi-34B-Chat-200K的准确率可以达到99.8%之多。

文学爱好者们有福了,几十万字的小说,通过Yi-34B-Chat-200K就能马上掌握作品精髓。
比如王尔德的经典名著《The Picture of Dorian Gray》(道林·格雷的画像),中文版长达20多万字。
我们把296页的英文原著PDF扔进去,Yi-34B-Chat-200K立刻就给出了中文内容总结。
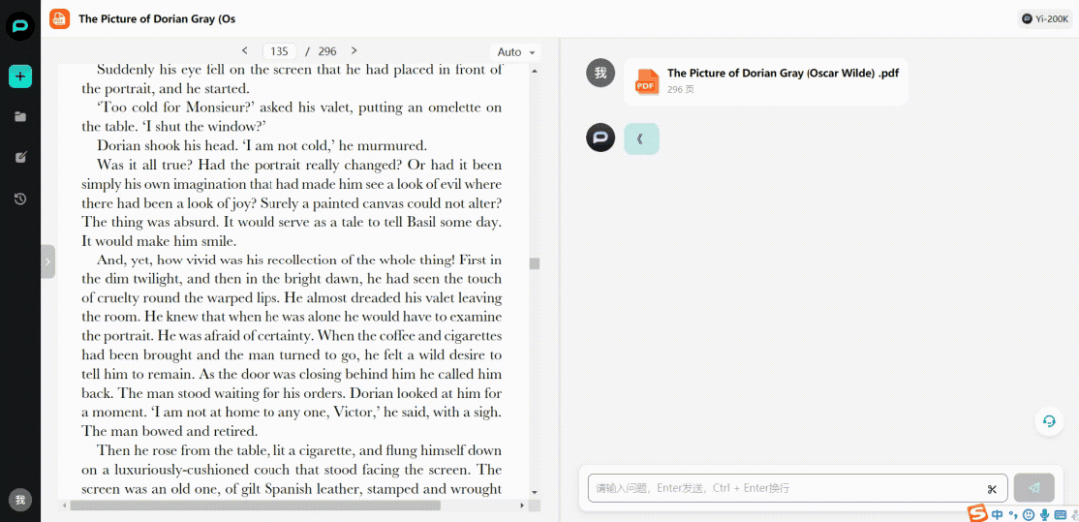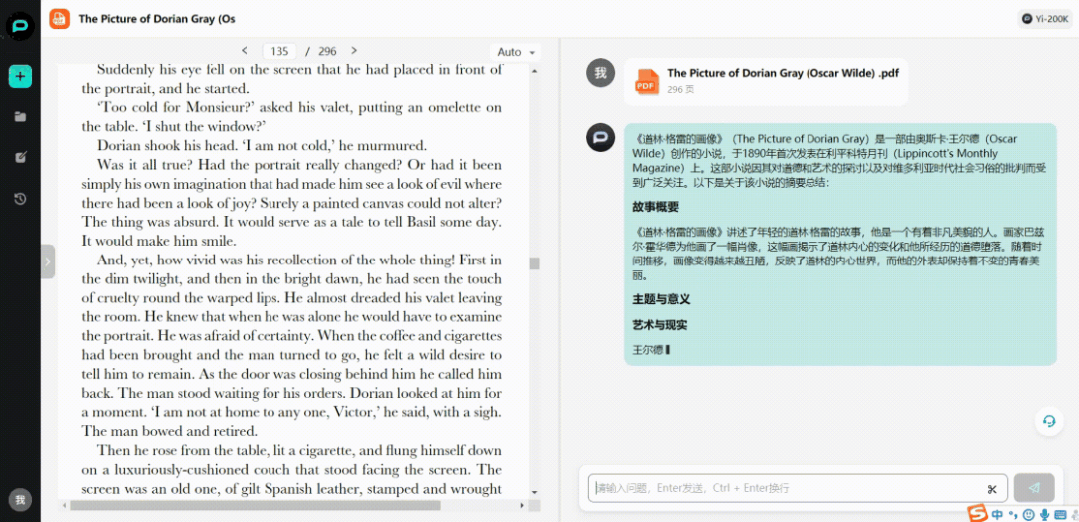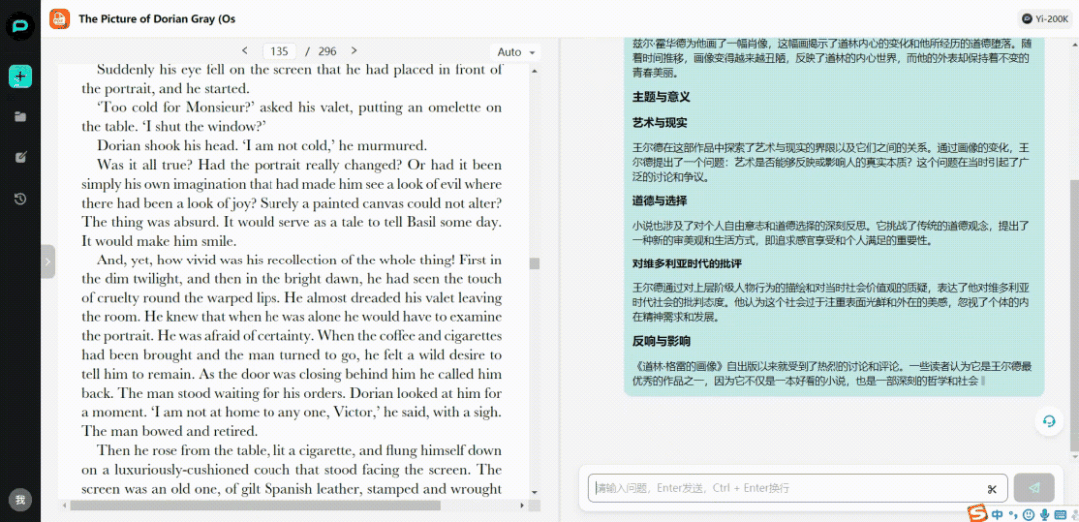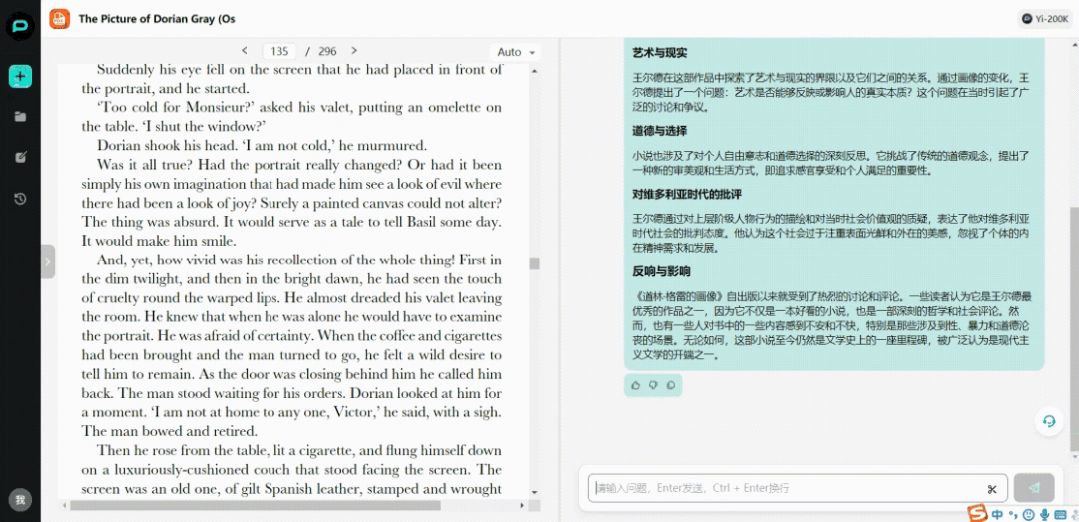
盘根错节的人物关系太过复杂?没关系,模型可以在通读几十万字后,帮你条分缕析地找出人物线索。


不懂就问,以后玩「剧本杀」,是不是就可以带着Yi-34B-Chat-200K来帮忙读剧本了?
如此高端的上下文能力,当然还可以用在一些更正经的地方。
比如,科研人员可以用它高效提取论文要点。
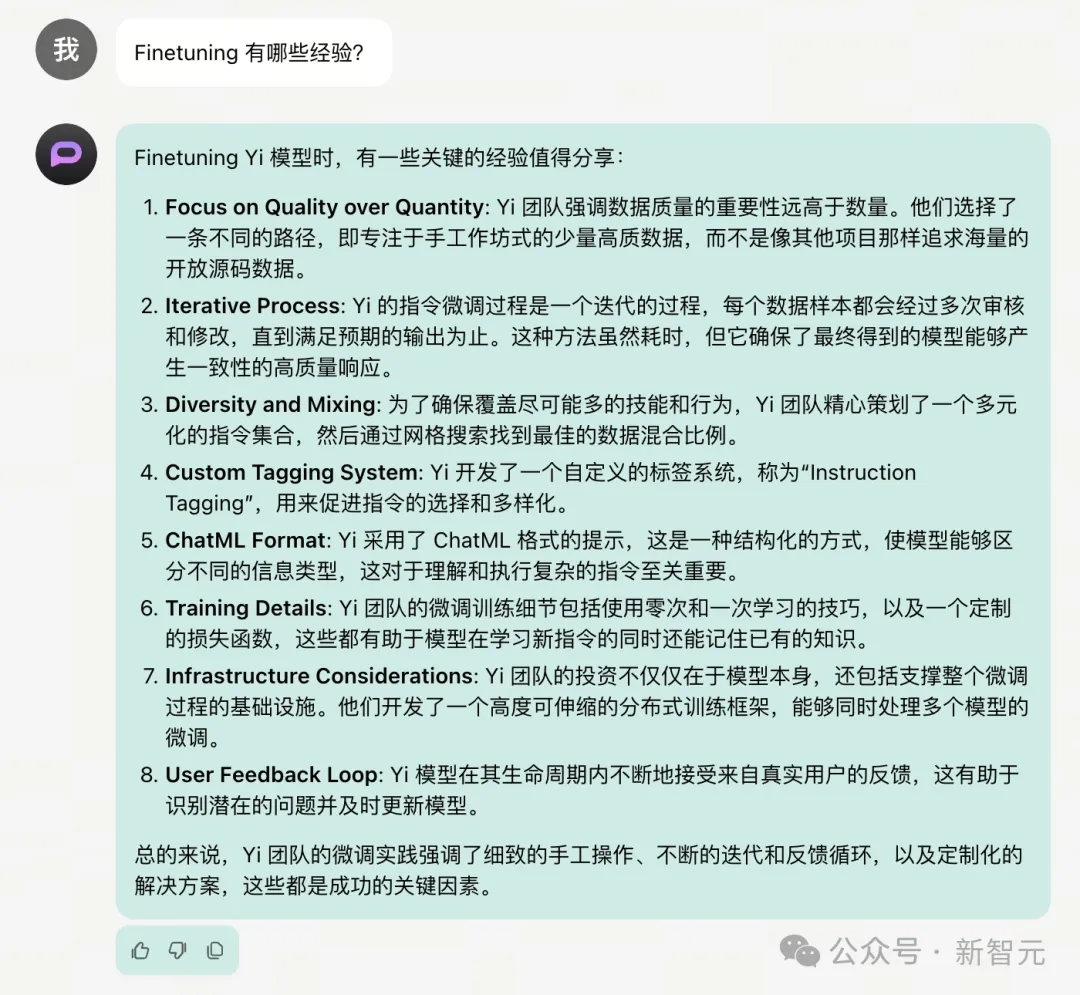
举个例子,把Yi模型的26页报告输入进去,Yi-34B-Chat-200K就能立刻总结出模型有哪些亮点和优势。
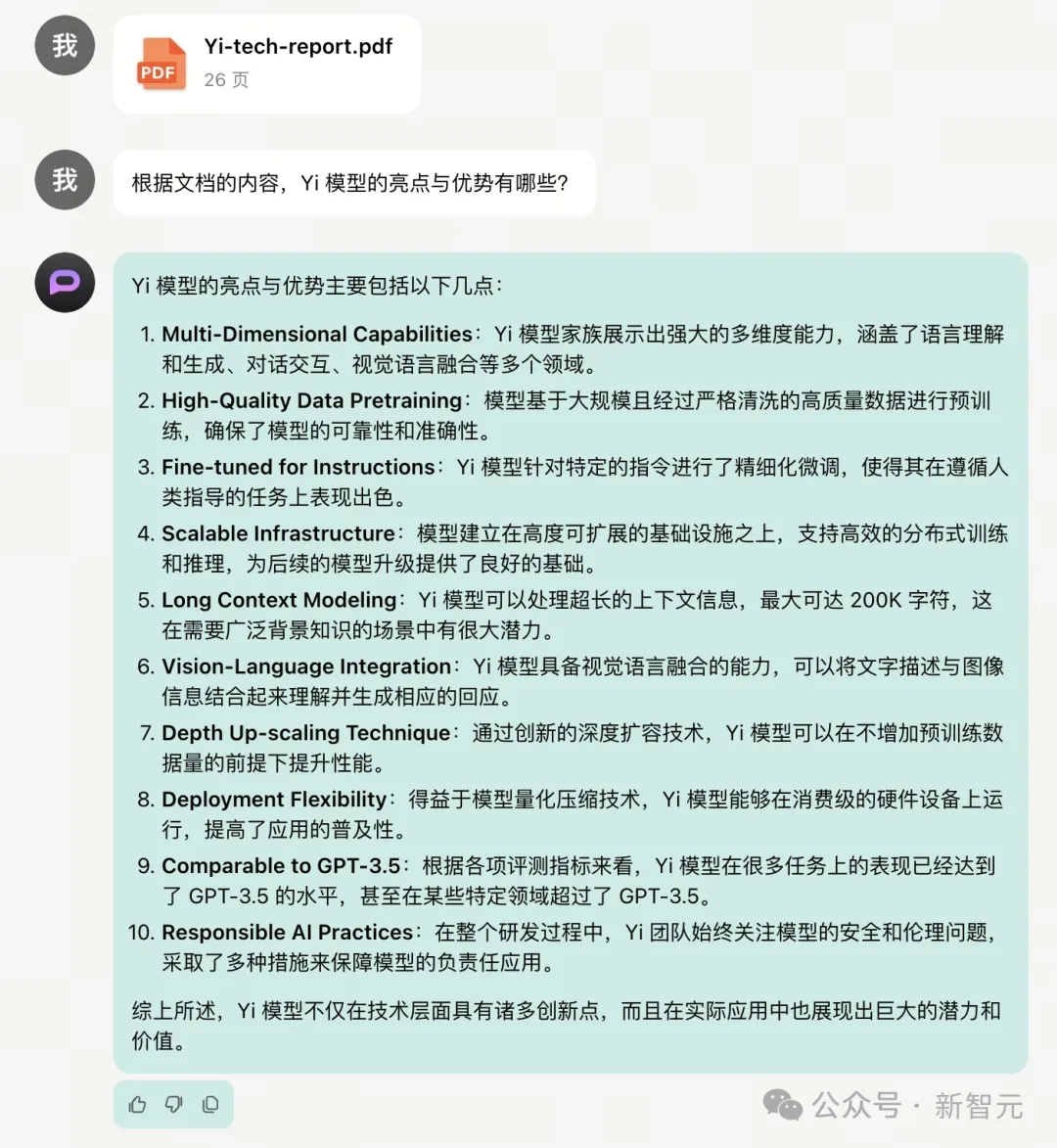
并且,还能从如此长篇的报告中,总结概括出模型微调的8条关键经验:
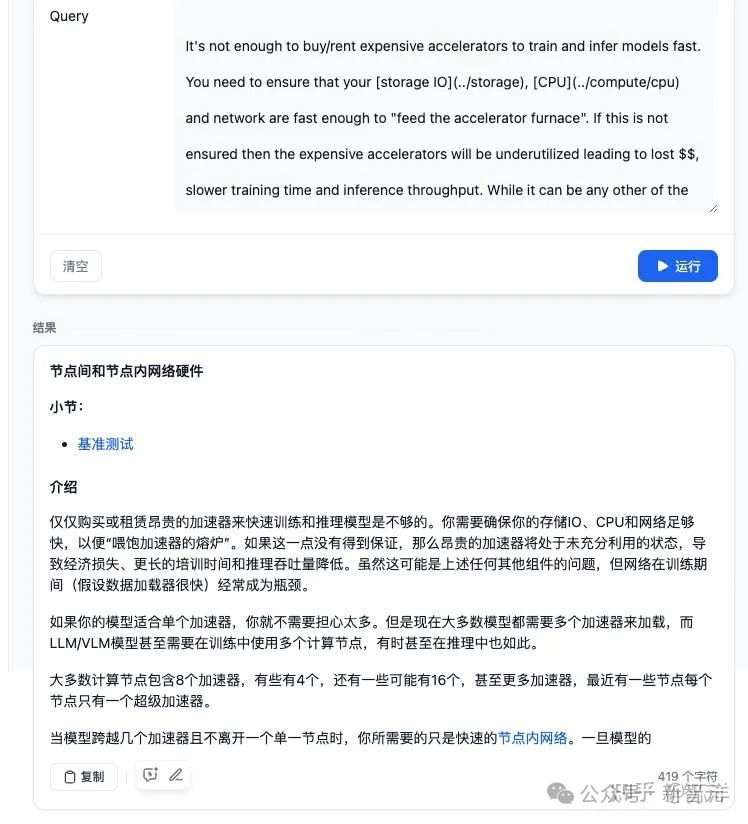
知乎知名答主「苏洋」,直接用Yi-34B-Chat-200K和LLM应用开发平台Dify快速搭建了一个模型应用。
前HuggingFace员工、前transformers核心贡献者Stas Bekman曾写了一本机器学习的书。
而苏洋直接使用Yi-34B-Chat-200K,就让模型迅速地吐出结果了。
每篇内容大概只需要花费十几秒的时间,模型就能自动翻译出来了!
图源:https://zhuanlan.zhihu.com/p/686774859?utm_psn=1751239717650427904&s_r=0
深圳超思维智能技术负责人近期也在测试大模型的知识库挂载操作,期望成为公司多模态开发中的一部分功能。
此次他利用Yi-34B-Chat-200K进行了知识库挂载的操作,对非常复杂的表格数据和专业性极强的学术文档进行了长文本总结和关键信息提取!
在这个过程中,模型的长文本输入、输出和总结以及关键信息提取的能力,都体现得淋漓尽致。
具体来说,它可以对中英文混合的表格形文档进行信息筛选、内容总结。
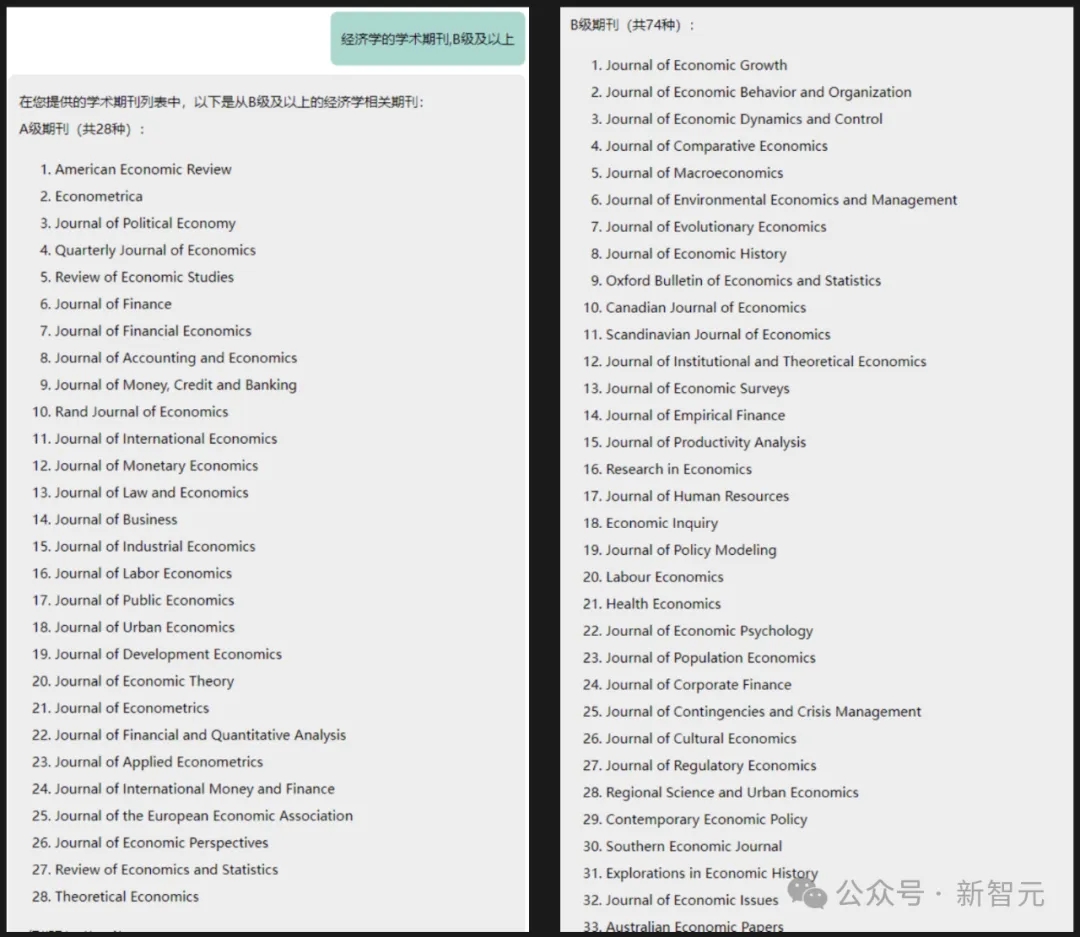
它能对中英文混合内容进行准确分辨,还能处理表格形式的数据。
比如总结出学术期刊列表中的A+级期刊和B级及以上期刊。
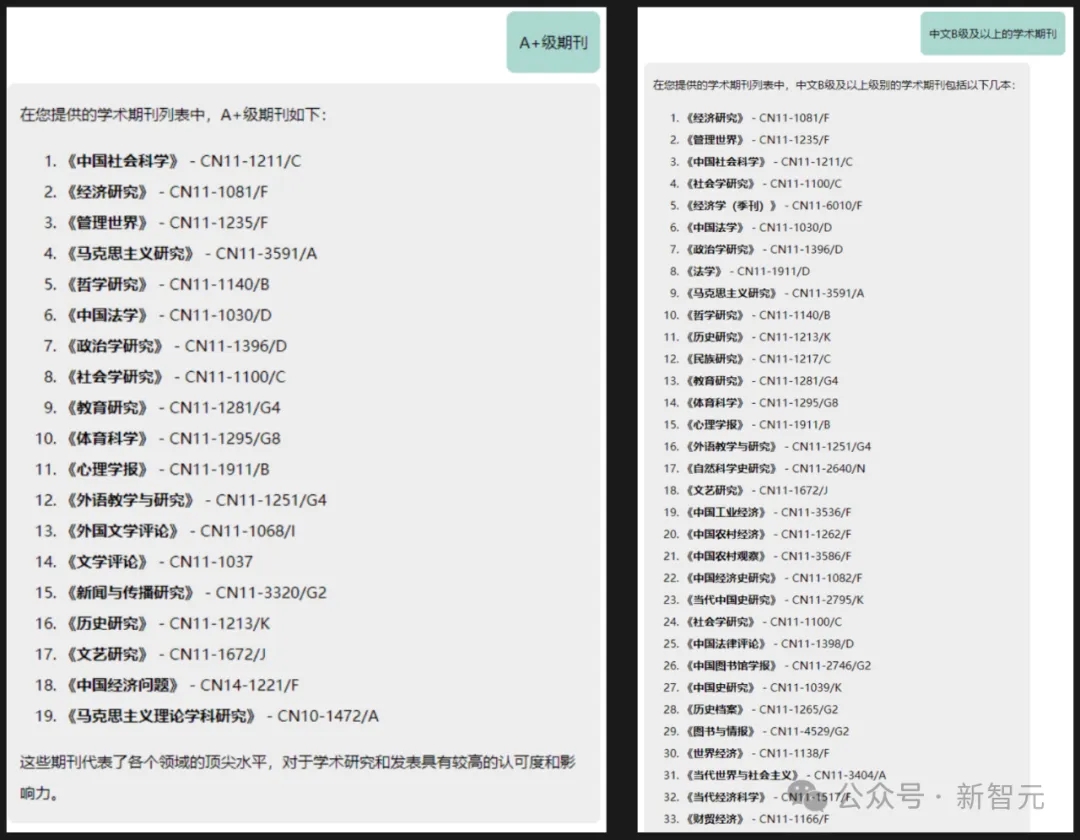
专业性非常强的学术文档,它也能提取出内容,比如Debian和Ubuntu系统使用说明下的主要内容。

而且,即使是文档内部小标题的详细内容,还是PDF图片中的文字内容,它都能有效地筛选和总结出来。

而Yi交流群中的AI大模型发烧友「闻」,尝试了200K API后,有了一些非常惊喜的发现。
「闻」一直在尝试能否用AI模型来翻译关于古典音乐的英文。
要知道,翻译古典音乐科普是一个巨大的挑战,尤其是当原文不只是英语的情况下。要翻译这种材料需要的不仅是英文好,也需要比较强的音乐专业背景。
他尝试过市面上所有的大模型和API,而Yi-34B-Chat 200K的长文本表现,让他直呼惊艳!


仔细看翻译,Yi-34B-Chat-200K这种程度的准确度,对古典音乐知识的掌握已经到达了很专业的水准。

经过一波demo对零一万物开放模型的了解,许多人早已等不及上手一试。
Yi大模型到底该如何使用?
正如开头所言,目前已经全面开放API名额。
现在,直戳零一万物API开放平台链接:https://platform.lingyiwanwu.com/

另外,Yi Model API与OpenAI API是完全兼容的。
也就是说,你只需修改少量代码,即可实现平滑迁移。
API开放之后,零一万物还将为开发者社区带来更多的惊喜,主要亮点包括:
1. 发布一系列模型API,包括更大参数量、更强多模态、更专业数学推理代码模型。
2. 突破更长上下文,从当前20万token扩展到100万token。支持更快的推理速度,显著降低推理成本。
3. 基于模型拥有的长上下文能力,构建向量数据库、RAG、Agent架构在内的全新开发者AI框架。
零一万物首批开放3款大模型API之后,开发AI 2.0的应用生态,就等你来创造。
本文来源于公众号新智元,作者编辑部




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
