# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
SOTA 语音合成效果。
文本到语音合成(Text to Speech,TTS)作为生成式人工智能(Generative AI 或 AIGC)的重要课题,在近年来取得了飞速发展。在大模型(LLM)时代下,语音合成技术能够扩展大模型的语音交互能力,更是受到了广泛的关注。
多年来,微软持续关注语音领域的技术研究与产品研发,为了合成高质量自然的人类语音,NaturalSpeech 研究项目(https://aka.ms/speechresearch)应运而生。
为了实现这个宏伟远景,NaturalSpeech 项目将目标拆分成几个阶段:
1)第一阶段,在单个说话人上取得媲美人类的语音质量。为此,研究团队在 2022 年推出了 NaturalSpeech 1,在 LJSpeech 语音合成数据集上达到了人类录音水平的音质。
2)第二阶段,高效地实现像人类一样多样化的语音合成,包含不同的说话人、韵律、情感、风格等。为此,研究团队在 2023 年推出了 NaturalSpeech 2,利用扩散模型(Diffusion Model)实现了零样本(Zero-Shot)的语音合成。
在 2024 年,该研究团队联合中科大、港中大(深圳)、浙大等机构联合发布了全新的系统:NaturalSpeech 3,它从语音数据的 “表示” 和 “建模” 两个角度出发,利用创新的属性分解扩散模型和属性分解语音神经编解码器 FACodec,通过 Data/Model Scaling,实现了零样本语音合成的重要突破,极大地向第二阶段目标迈进。
3)当前,该联合研究团队正在研究更自然的语音合成,最终实现像人类一样自然且随意的发声。
想加入该研究团队从事最前沿的语音 / 音频 / 视频研究吗?文末有招聘信息。

aturalSpeech 3 论文链接: https://arxiv.org/abs/2403.03100
NaturalSpeech 3 Demo 演示: https://speechresearch.github.io/naturalspeech3
NaturalSpeech 3 论文一经推出就在国内外社交媒体上引发热议,推特网友盛赞:NaturalSpeech 3 是目前最好的零样本 TTS 模型,标题里的「Natural」可以说是当之无愧。
NaturalSpeech 3 可以仅仅通过 3s 的提示音频在没有见过的说话人上实现效果惊艳音色克隆,例如下面的例子:

NaturalSpeech 3 不仅能够实现逼真的音色模型,还能够非常好的还原韵律,情感等特征。我们来听听下面这个例子:

可以感觉到,NaturalSpeech 3 生成的结果在音质和音色方面和真实音频几乎没有差别,并且非常好的复刻了提示音频中包含的情绪等语音信息。
NaturalSpeech 3 还可以对不同的属性使用不同的提示实现更为可控的生成,例如可以使用一个语速较快的人的声音作为 duration 的提示,使得生成的结果同样具有较快的语速。例如下面这个例子:

可以发现,NaturalSpeech 3 的音色仍然和其他属性的 prompt 保持一致,但是跟随了 duration prompt 较快语速。
NaturalSpeech 3 的成功秘诀来自于基于属性分解的 Codec+Diffusion 建模范式以及 Data/Model Scaling。传统 TTS 系统因训练数据集有限,难以支持高质量的零样本语音合成。而最近的研究通过扩大语料库,虽有所进步,但在声音质量、相似性和韵律方面仍未达到理想水平。
NaturalSpeech 3 提出创新的属性分解扩散模型和属性分解神经语音编码器 FACodec,通过将语音分解成不同属性的子空间并根据不同的提示(prompt)分别生成,有效地降低了语音建模难度,从而大大提高了语音合成的质量和自然度。
与此同时,NaturalSpeech 3 通过将训练数据扩展到 20 万小时(这是迄今为止公开的研究工作中使用的最大规模数据)以及将模型大小扩展到 1B(2B 甚至更大的模型正在训练中),进一步提升语音合成的质量和自然度。
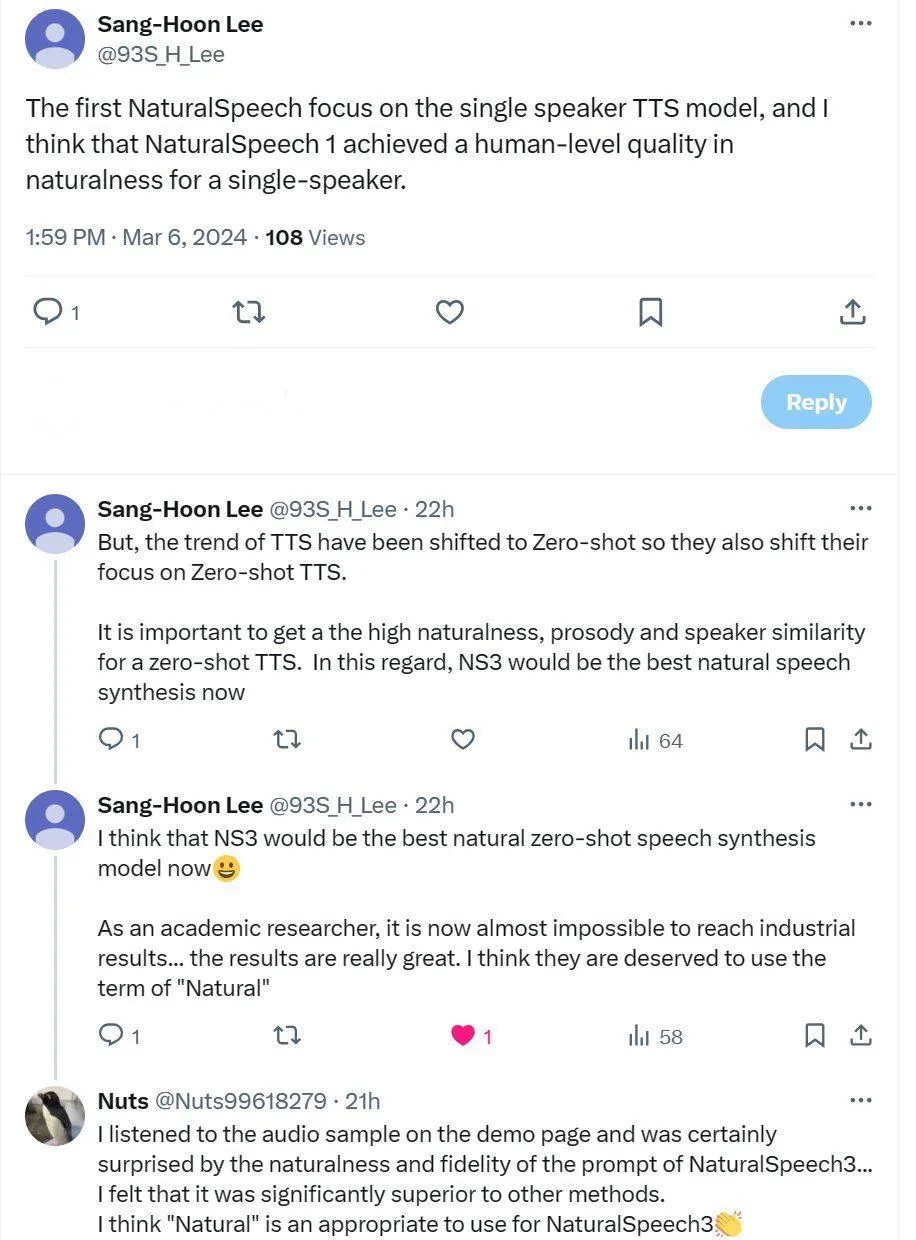
属性分解神经语音编解码器(FACodec): NaturalSpeech 3 提出一种创新的属性分解神经语音编解码器(Codec)负责将复杂的语音波形转换成代表不同语音属性(内容、韵律、音色和声学细节)的解耦子空间,并从这些属性重构高质量的语音波形。
FACodec 通过使用语音编码器、音色提取器、三个分解向量量化器(分别针对内容、韵律和声学细节)、一个语音解码器以及多种训练技术的组合,实现了这一过程。这种设计促进了语音属性间的解耦,简化了 TTS 对语音表示的建模过程。
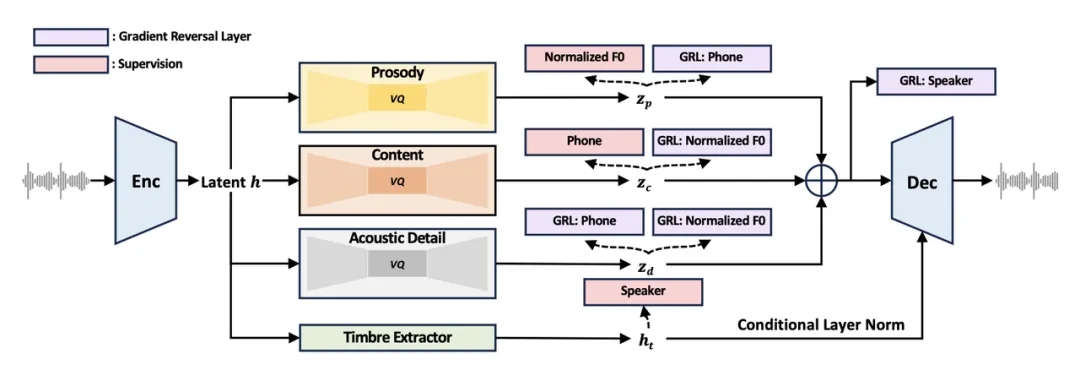
NaturalSpeech 3的属性分解神经语音编解码器FACodec
目前语音开源项目 Amphion 已经支持 NaturalSpeech 3 的核心组件 FACodec,并且已发布预训练模型。FACodec 作为 NaturalSpeech 3 的核心,能够将复杂的语音波形转换成表示内容、韵律、音色和声学细节等属性的解耦表示,并从这些属性重构高质量的语音波形。
这一技术能够显著降低语音的建模难度,研究人员可以利用 FACodec 复现 NaturalSpeech 3 或应用到语音合成、语音转换等各式各样的下游生成任务。
FACodec 预训练模型: https://huggingface.co/spaces/amphion/naturalspeech3_facodec
FACodec 代码: https://github.com/open-mmlab/Amphion/tree/main/models/codec/ns3_codec
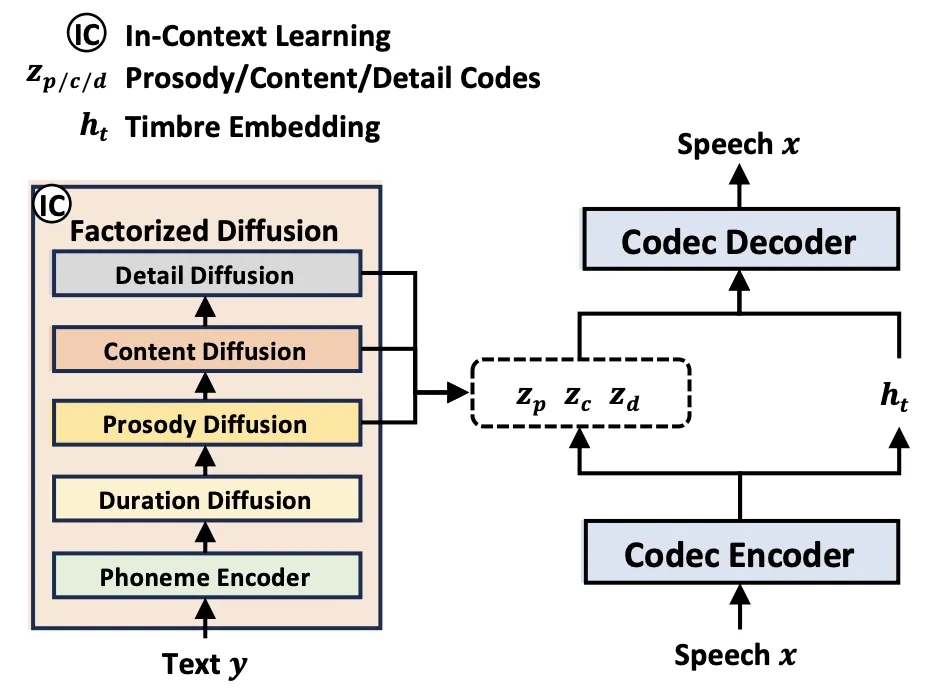
属性分解扩展模型:NaturalSpeech 3 设计了多个扩散模型模块来分别建模音素持续时间、韵律、内容、声学细节(其中韵律,内容,声学细节共享一个Diffusion模型),而不需要单独对音色进行建模,因为音色特征可以直接从 prompt 中提取。此外,每一个扩散模型的 prompt 仅与该模块的语音因素相关,实现了对各个模块的可控性生成。
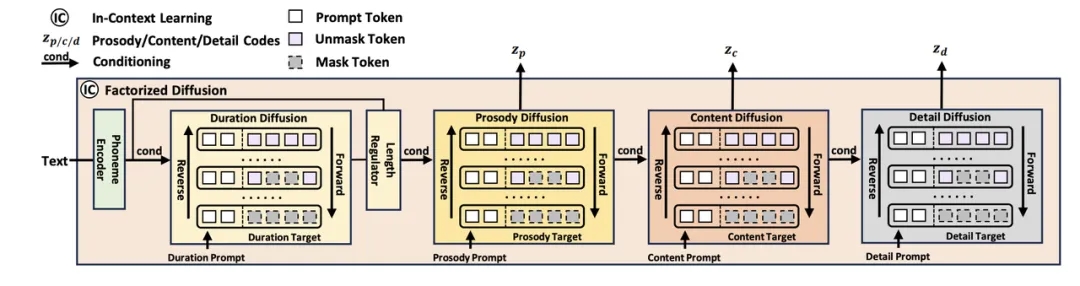
NaturalSpeech 3的属性分解扩散模型
SOTA 的语音合成效果:经过大量的实验验证,NaturalSpeech 3 在语音质量、相似性、韵律和可懂度方面均超越了现有最先进的 TTS 系统。特别是,在 LibriSpeech 测试集上,与真实语音相比,NaturalSpeech 3 在 CMOS 评分上达到了相当甚至更好的语音质量;在语音相似度方面,实现了新的最佳水平;在韵律建模上也展现了显著的改进。
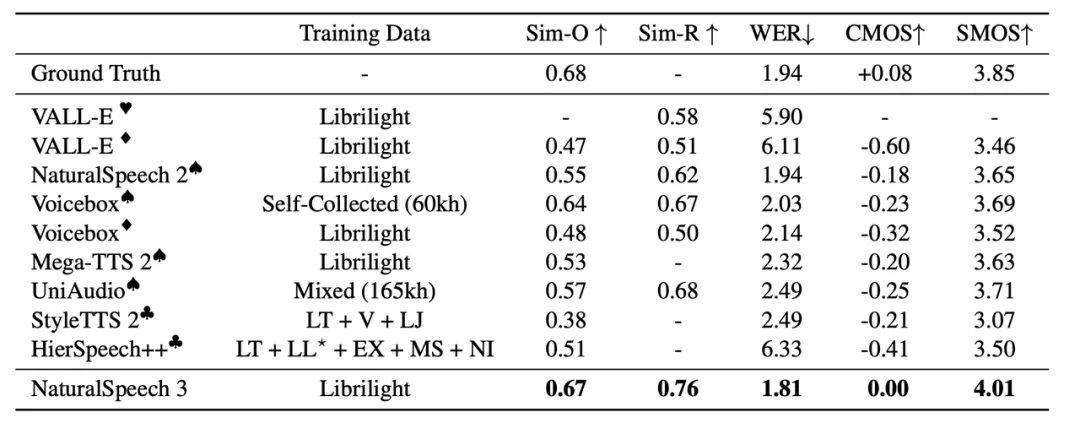
NaturalSpeech 3和其它TTS系统比较
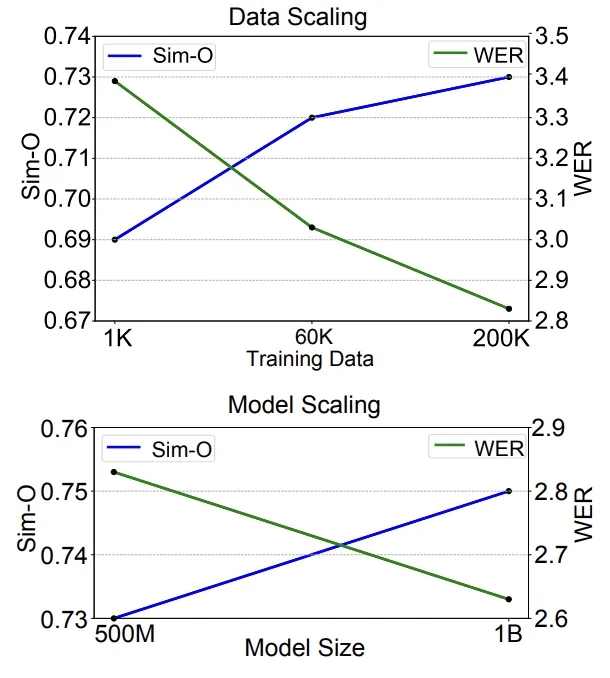
NaturalSpeech3在不同模型大小和数据量下的比较
FACodec的扩展用途: NaturalSpeech 3 中提出的FACodec不仅仅在非自回归语音合成中取得了很好的结果,而且进一步证明了其在自回归语音合成范式中的显著效果。作者们使用经典的自回归架构VALL-E,相比原本的基于RVQ的Codec,在音质、相似度、稳定性上都有非常显著的提升!这进一步说明了基于属性分解的语音表征的巨大空间。
Data/Model Scaling:值得一提的是,NaturalSpeech 3 还将模型拓展到 1B 大小、数据量拓展到 20 万小时左右,在提升合成语音质量,相似度,可理解性方等面的令人期待的结果,展示了较强的 Scaling 能力。
本文来源于公众号机器之心,作者机器之心编辑部



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
