# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大连理工大学信息检索研究室在始智AI wisemodel.cn开源社区发布了司法大模型--太令(TaiLing)1.0版,“太令”是专门为司法领域定制的大语言模型,其训练基础是庞大的通用中文语料库,并结合了裁判文书、合同、司法考试材料以及司法问答等专业司法数据进行深度训练。“太令”大模型旨在封闭环境中为司法业务提供全面的支持,能够自动检测并纠正司法文件中的语法、拼写和事实错误,精确提取关键信息,并提供基于历史案例的罪名预测及量刑建议。
https://wisemodel.cn/models/DUTIR/TaiLing(模型地址)
在智慧司法的新时代,自然语言处理技术在司法行业中的应用日益成为关注的热点。应对这一需求,大连理工大学信息检索研究室发布司法大模型--太令(TaiLing)1.0版。
01
“太令”大模型
需求与挑战
司法精确性的要求:司法文档,包括判决书、诉状和合同等,对准确性的要求极为严格。在这些文件中,任何语法、拼写或事实上的错误都可能引发审判结果的重大偏差,从而影响整个案件的研判。因此,确保这些文档的准确性是至关重要的。
处理大规模数据的需求:在司法领域,处理大量的文档和数据是一项复杂任务,这些文档包括案件记录、法律文件和证据材料等。手工准确地提取与案件相关的信息不仅成本高昂,而且需要众多一线司法办案人员的投入。因此,如何在可控成本内有效提升案件处理效率,成为行业从业者面临的一个迫切问题。
司法判决的一致性要求:在司法实践中,维护判决的一致性至关重要。这意味着,对于具有相似案情的不同案件,需要确保它们接受一致的裁决和公正的处理。这种做法不仅维护了法律的严肃性和权威性,也保证了法律的公正性。
司法业务和技术融合的趋势:随着司法领域与信息技术的不断融合,利用大语言模型等智能技术来协助处理司法业务成为一种趋势。
文本校核
文本校核任务致力于自动检测并纠正司法文书中的语法、拼写和事实错误。它的关键在于提升文档质量,减少人为错误,从而保障法律文件的可靠性。对司法专业人员而言,这意味着可以节省大量校对和修正时间,确保文件的专业标准。
信息抽取
信息抽取任务专注于从复杂的司法文档中精确地提取关键信息,如人物、地点、事件及其相互关系,快速识别和分类重要的数据点,从而支持案件分析和法律决策制定。这种高效的信息提取能力使司法专业人员能够快速获得案件的全貌,促进更准确的证据分析和案件理解。
量刑辅助
量刑辅助任务旨在为司法专业人员提供基于数据和历史案例的量刑建议,以增强判决的客观性和一致性。此任务集中于分析类似案件的量刑标准,考虑案件特定因素如罪行性质、被告人背景等,通过构建预测模型,生成合理的量刑参考。
02
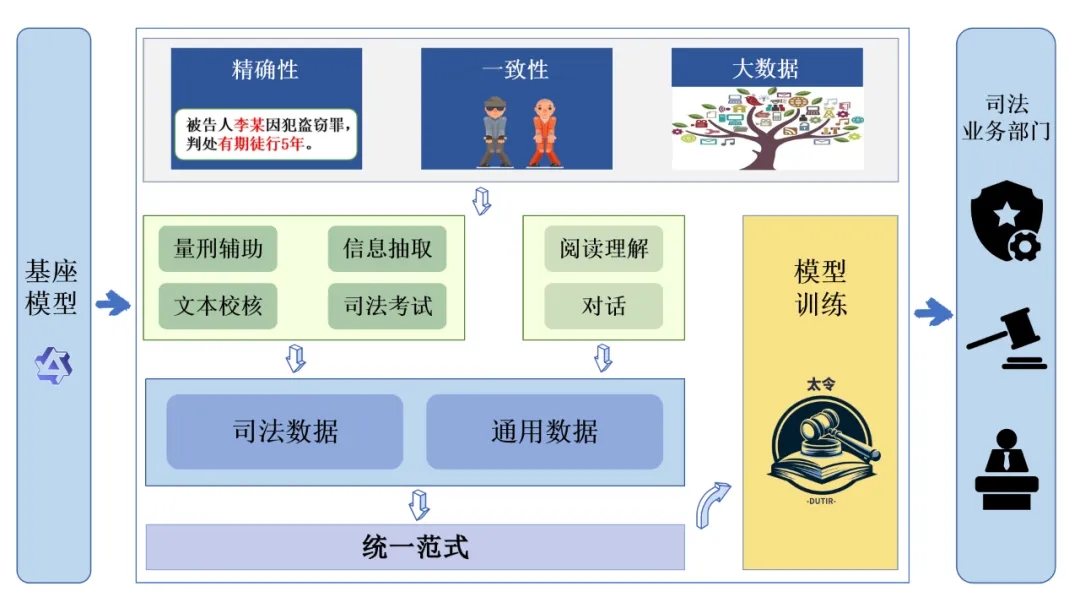
模型训练和优化
基座介绍
“太令”基座模型采用Qwen-7B系列,该模型拥有70亿参数,经过在超过2万亿tokens的大型数据集上的预训练,在文本理解和生成、模式识别、支持决策等方面具有良好的表现。在模型训练过程中,我们使用了8张Nvidia A40 48 GB显卡,并结合QLoRA技术,将基座模型针对司法领域进行定制和微调。我们的训练代码基于Firefly(流萤)项目进行了优化,以确保模型的性能更高效稳定。
任务范式和指令
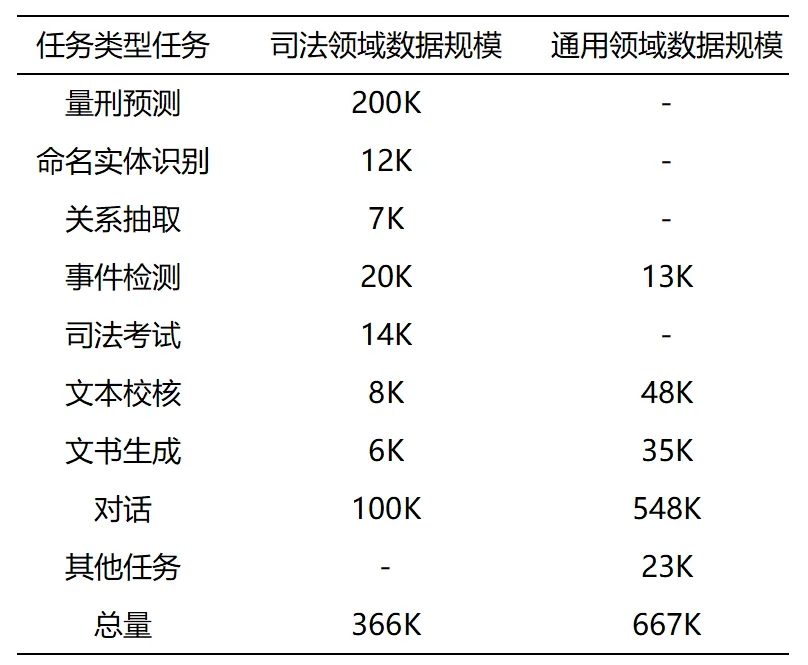
我们充分发掘和利用现有的司法领域自然语言处理数据集,将现有开源的九种法律任务类型归纳为了判别与生成两类任务,结合司法业务的核心三大类(文本校核、信息抽取、量刑辅助)任务特点,建立了针对判别与生成两类任务统一的任务范式,并从近千万条开源数据中筛选构建了37万条高质量指令数据。该指令数据集涵盖了核心三大业务在内的九种不同任务类型。
我们的目标是通过一个大模型实现在封闭场景下对实际司法业务的全面支持。因此我们针对多种实际司法业务建立了统一的任务范式,并针对不同的具体任务构建了丰富的指令模板。
文本校核:在统一任务范式的基础上,我们将原本“语病识别→错误修改”的Pipeline任务转换为更贴合语言生成模型的正确表述生成任务。具体而言,例如给定样例“交通狮子路口发生交通事故”。现有任务范式标注为“原句位置[2,3],狮子改为十字”,而我们的范式标注为“交通十字路口发生交通事故”。为了进一步提高模型性能,我们引入了链式结构的多层级任务,将标注进一步补充为正例“原文可修改为:交通……”或负例“原文不存在错误,原文为:交通……”。
信息抽取:包含命名实体识别与关系识别两类任务。在统一的任务范式基础上,我们将原本的三元组表示转换为了自然语言表示。例如将原本的“[嫌疑人(实体),贩卖(关系),涉案物品(实体)]”转换为“嫌疑人与涉案物品具有贩卖关系”。
量刑辅助:量刑辅助包含罪名预测与刑期预测两类任务。在统一范式的基础上,我们将原本的判别或连续的回归标注转换为了离散的自然语言标注。为满足办案人员对刑期预测任务的实际需求,我们将原有数据中的具体刑期归化至一定区间。具体而言,例如文本中的实际标注为“罪名:盗窃、故意伤害,刑期:三年零六个月”归化为“罪名:盗窃、故意伤害,刑期:三年以上四年以下”。归化标准为判罚有期徒刑或拘役一年以下者以半年为区间,一年以上以年为区间。
此外,为了保证模型对域外指令的泛化能力,我们进一步在训练数据中添加了额外的任务数据,包含通用领域的对话、思维链数据与非核心任务的司法领域数据。特别的,我们在实验中发现,引入通用类数据会对司法领域判别任务带来负面效果。因此,我们仅对特定的非判别、非核心任务添加了额外数据。
最终用于“太令”大模型训练的指令数据统计如下表:
03
评测结果与样例展示
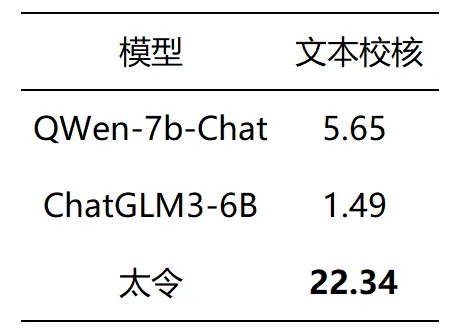
为了评测“太令”模型的性能,我们用QWen-7b-Chat模型和最新发布的新一代对话预训练模型ChatGLM3-6B在三大类任务上进行对比测评,同时选取“太令”的主要功能进行样例展示。
文本校核
文本校核的测试指标是Rouge-L,测试集来自我们自行标注的司法文本校核数据集。由于我们将原本的Pipeline任务转换为生成任务,因此参考自动翻译与摘要生成任务,将Rouge-L作为文本校核的评测标准。
下面是“太令”文本校核的正样例展示:

信息抽取
信息抽取的测试指标是Micro-F1,测试集来自CAIL2021与CAIL2022,测试集输出为固定格式的文本序列。因为基座模型在未进行训练的情况下难以识别未知的司法实体或关系类型,因此我们对基座模型的测试采用了Few-shot策略。
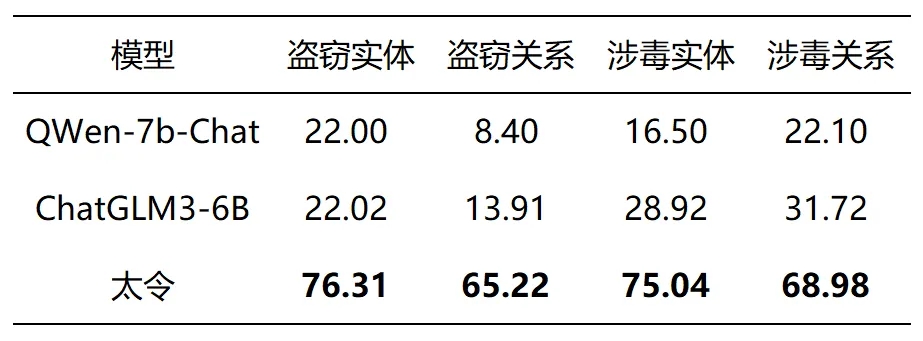
下面是“太令”信息抽取的样例展示:

量刑辅助
量刑辅助中两类任务的测试指标均是Micro-F1,测试集来自CAIL2018。由于在量刑预测任务中我们将原本的回归任务转换为了分类任务,因此参考标准的分类任务指标,我们将Micro-F1值作为评测指标。特别的,因为现有大模型并没有针对刑期做特别的预处理,我们采用了在对基座模型的测试中采用了Few-shot策略。
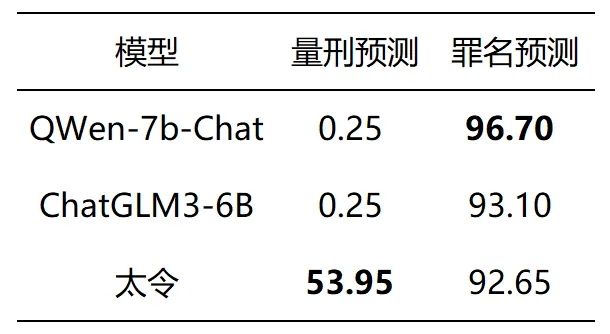
下面是“太令”量刑辅助的样例展示:
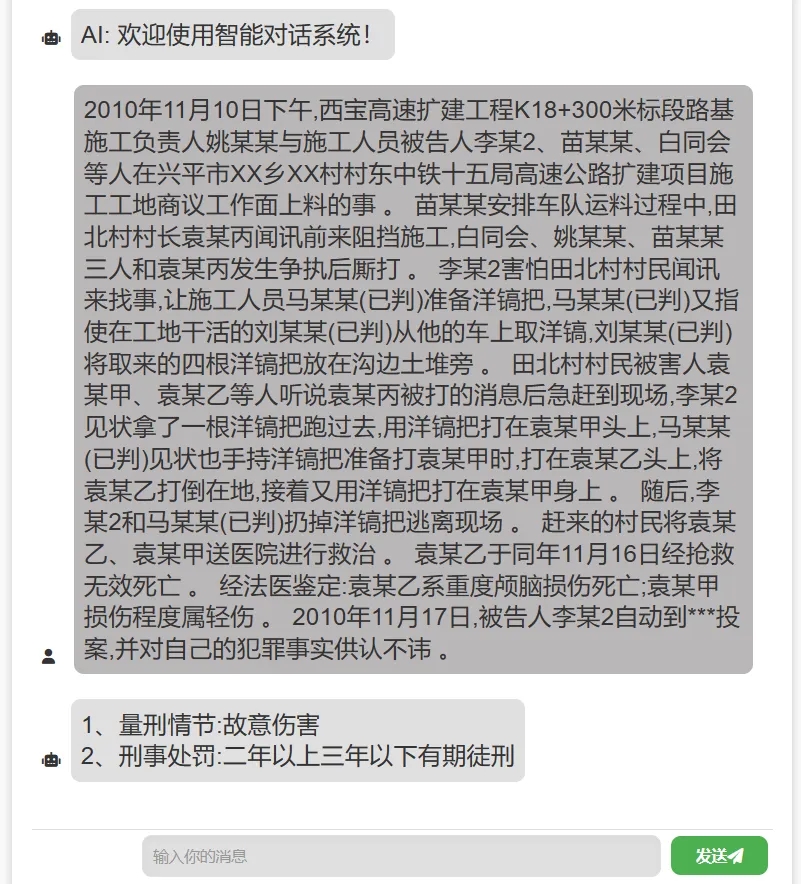
对话能力
“太令”大模型维持了在通用领域和司法领域的对话能力且增强的推理能力。下面是“太令”在通用领域和司法领域对话能力的样例展示:

资源网址
为了便于体验,我们提供了一个推理脚本进行测试。感兴趣的读者可以通过脚本加载模型来体验“太令”的功能。
GitHub:
https://github.com/DUTIR-LegalIntelligence/Tailing
wisemodel:
https://wisemodel.cn/models/DUTIR/TaiLing
04
“太令”项目专注于在司法领域内推进大型语言模型在实际业务场景下的落地,“太令”旨在为多种司法业务场景提供智能服务。其在信息提取等自然语言处理基础任务上的表现出众,并且在文本校核、量刑辅助等特定任务上更是展现了良好性能和巨大潜力,为未来在智慧司法的应用进行了有益探索。
“太令”由大连理工大学信息检索研究室(DUTIR)开发完成。
指导教师:孙媛媛、罗凌、杨志豪、林鸿飞
学生成员:张元俣、帕尔哈提·吐拉江、逯志兴、孙皓宸、宁金忠、丁泽源、潘丁豪、张家诚、张海光、张天宇、杜金明、李汶蔚、李明达、占嫦妍、周钦、蔡艾宸、乐滢滢。
本文来源:大连理工大学信息检索研究院

编辑:安冉
审核:赵雅鑫


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
