# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
是时候让CPU在AI应用上 “支棱”起来了。
这是去年大语言模型大火之时,权威期刊IEEE Spectrum在一篇文章中,开门见山给出的一个观点;并且是由一群AI研究人员得出、声量越来越大的那种。

文章还坦言道:
诚然GPU可能占据了主导地位,但在AI领域中的很多情况下,CPU却是更合适的那一个。
例如文章引援了Hugging Face首席布道官Julien Simon体验的真实案例——
拿一个英特尔® 至强® 系列CPU,就能轻松驾驭Q8-Chat这个大语言模型,而且响应速度很快。
Simon对此开诚布公地表示:
GPU虽然很好,但垄断从来不是一件好事,可能会加剧供应链问题并导致成本上升。
英特尔CPU在许多推理场景中都能很好地运行。
而这也正与当下大模型的发展趋势变化相契合,即逐渐从训练向推理倾斜,大模型不再仅仅较真于参数规模、跑分和测评,更注重在应用侧发力。
一言蔽之,比的就是看谁能“快好省”地用起来。
不过话虽如此,但在真实的AI场景中,CPU真的已经“支棱”起来了吗?
如果说当时在这个话题上,IEEE扮演了 “嘴替”,是在帮那些AI应用实践的先行者们发声,那么这种发声,确实又吸引或带动了更多实干者来验证这种可行性。他们如今已经可以给出一个确定答案,即在很多AI推理的场景中,CPU已经能很好地上岗了。
例如中国公有云服务器市场的翘楚京东云,它pick的便是最新的第五代英特尔® 至强® 可扩展处理器。
具体而言,是在其新一代京东云服务器上搭载了这款高端CPU。
话不多说,我们直接先来看下效果。
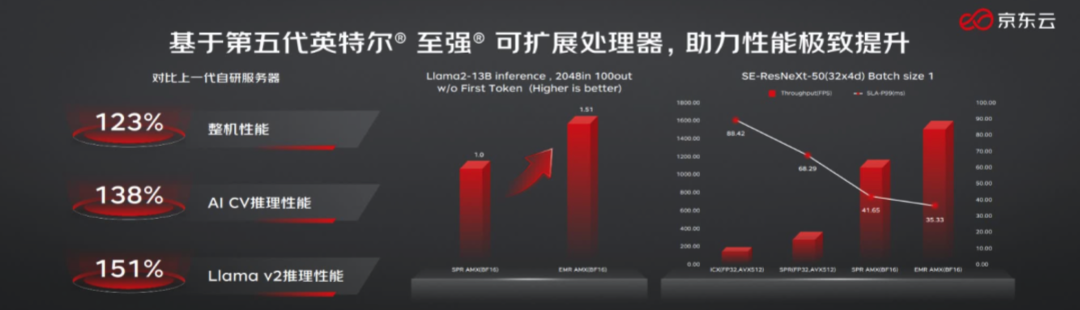
首先,从整体来看,新一代京东云服务器的整机性能最高提升了23%!
除此之外,在AI推理方面的性能也是Up Up Up。
而之所以能有如此突破,核心就是第五代英特尔® 至强® 可扩展处理器内置的AMX(高级矩阵扩展)技术对AI的加速能力。
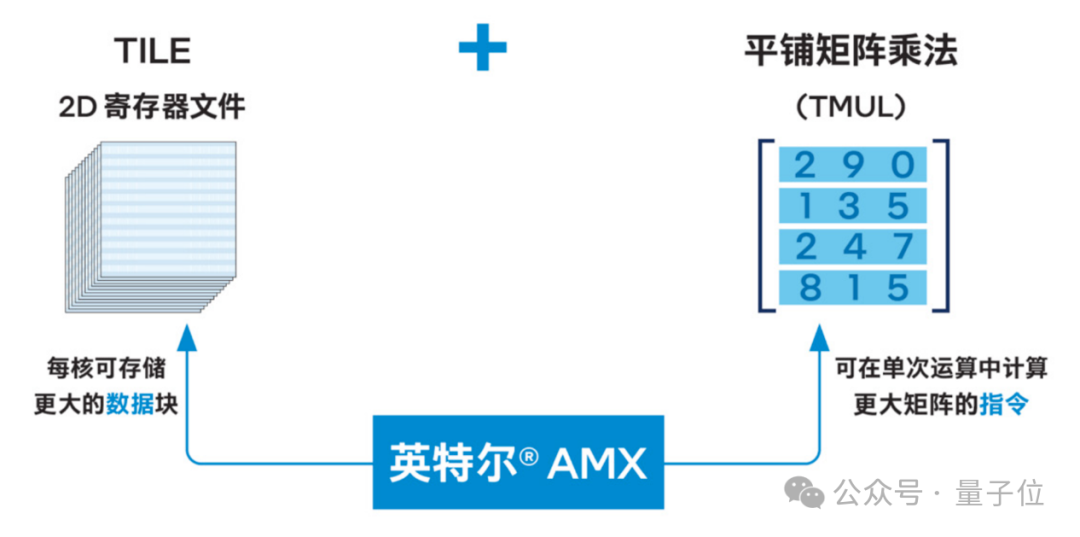
英特尔® AMX是针对矩阵运算推出的加速技术,支持在单个操作中计算更大的矩阵,让生成式 AI 更快地运行。
一言以蔽之,你可以把它当作内置在CPU中的Tensor Core。
展开来说, AMX引入了一种包含两个组件的新矩阵处理框架,包括二维的寄存器文件,它由被称为“tile”的寄存器组成;另一个是一系列能够在这些tile上执行操作的加速器。
在这些技术的加持之下,以向量检索为例,当处理n个批次的任务时,需要对n个输入向量x和n个数据库中的向量y进行相似度比较。
这一过程中的相似度计算涉及到大量的矩阵乘法运算,而英特尔® AMX能够针对这类需求提供显著的加速效果。
在提升模型性能的过程中,英特尔® oneDNN作为AMX的软件搭档,可为操作者提供一种高效的优化实现方式。
开发者仅需调用MatMul原语,并提供必要的参数,包括一些后处理步骤,oneDNN便会自动处理包括配置块寄存器、数据从内存的加载、执行矩阵乘法计算以及将结果回写到内存等一系列复杂操作,并在最后释放相关资源。
这种简化的编程模式显著减轻了工程师的编程负担,同时提升了开发效率。
通过上述软硬结合的优化措施,京东云新一代服务器就可以在大模型推理和传统深度学习模型推理等场景里提供能满足客户性能和服务质量 (QoS) 需求的解决方案,同时还可以强化各种CPU本就擅长的通用计算任务的处理效率。仅就大家关心的大模型推理而言,已经能用于问答、客服和文档总结等多种场景。
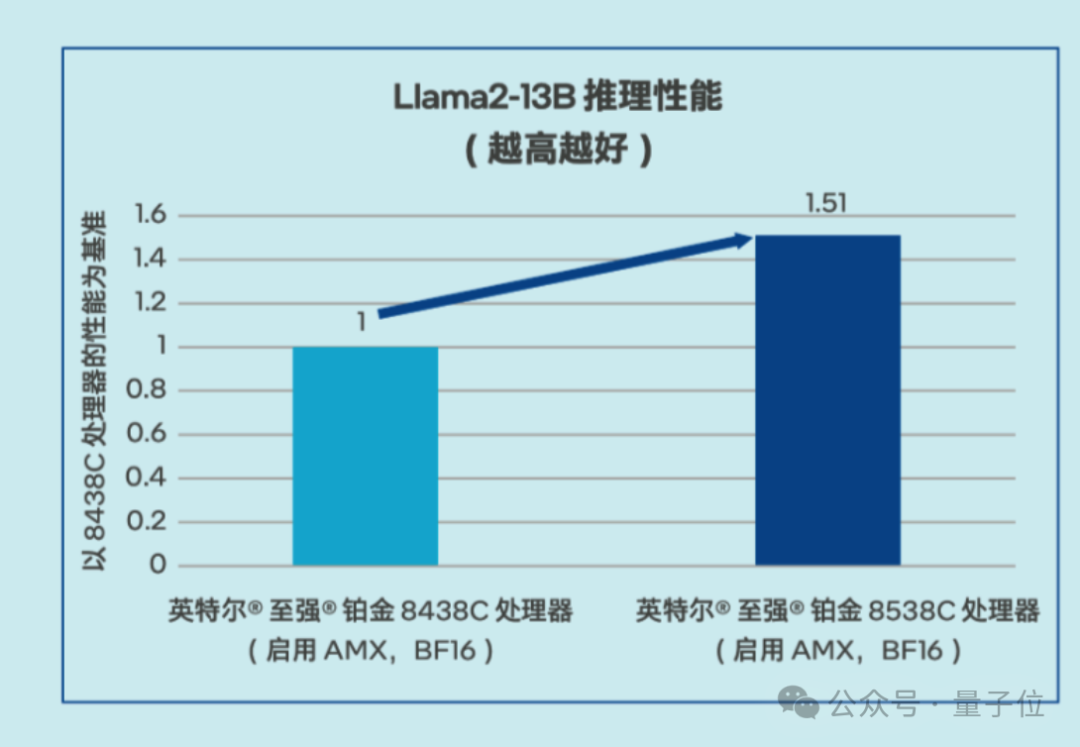
△Llama2-13B推理性能测试数据
而且除了性能上的优化之外,由于搭载了英特尔® AMX等模块,新一代京东云服务器也可以更快地响应中小规模参数模型,把成本也狠狠地打了下去。
你以为这就结束了?英特尔CPU给新一代京东云服务器带来的好处,可不只涉及推理加速和成本,更可靠的安全防护也是其独到优势之一。
基于新款处理器内置的英特尔® Trust Domain Extension(英特尔® TDX)技术,京东云在不改变现有应用程序的情况下,就能构建基于硬件设备的可信执行环境(Trusted Execution Environment,TEE)。
英特尔® TDX通过引入信任域(Trust Domain,TD)虚拟环境,利用多密钥全内存加密技术,实现了不同TD、实例以及系统管理软件之间的相互隔离,让客户的应用和数据与外部环境隔离,防止未授权访问,且性能损耗较低。
总的来说,英特尔CPU上的这项技术,是从硬件、虚拟化、内存到大模型应用等多个层面,为新一代京东云服务器的数据和应用保密提供了可靠支撑。
AI进入2.0时代,所有应用都值得重写一遍已逐渐成为共识。
如果站在算力基础设施的视角重新审视这场变革,还能发现这样一个新趋势:推理算力越来越被重视起来。
也就是随着大模型应用场景的日益丰富,对推理阶段的性能要求也变得更高和多样化。
一方面,实时性强、时延敏感的终端侧场景需要尽可能短的响应时间;
另一方面,并发量大、吞吐量高的云端服务则需要强大的批处理能力。
与此同时,面向不同硬件平台、网络条件的推理适配也提出了更复杂甚至带有不同前置条件的要求。
如此一来,此前在硬件上的单一“审美观”就被改写,本来就主攻通用计算、能在整个AI的协同编排中扮演重要角色,又能撸袖子自己上、兼顾AI加速,同时还有更多“才艺”、应用适配也更为灵活,相比GPU或专用加速芯片获取更容易,且已部署到无处不在的CPU,其价值也被重新发现,这一切都顺理成章。
相信随着软硬件适配的不断深入,以及云边端协同的加速落地,CPU还有望在AI,特别是AI推理实践中找到更多的用武之地,发挥更大的应用潜力。
可以预见,高性能、高效率、高适应性的CPU,在大模型越来越卷的时代,依旧是个可靠的选择。这一点,会有更多人因为实践,从而见证。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
