# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2022 年底,随着 ChatGPT 的爆火,人类正式进入了大模型时代。然而,训练大模型需要的时空消耗依然居高不下,给大模型的普及和发展带来了巨大困难。面对这一挑战,原先在计算机视觉领域流行的 LoRA 技术成功转型大模型 [1][2],带来了接近 2 倍的时间加速和理论最高 8 倍的空间压缩,将微调技术带进千家万户。
但 LoRA 技术仍存在一定的挑战。一是 LoRA 技术在很多任务上还没有超过正常的全参数微调 [2][3][4],二是 LoRA 的理论性质分析比较困难,给其进一步的研究带来了阻碍。
UIUC 联合 LMFlow 团队成员对 LoRA 的实验性质进行了分析,意外发现 LoRA 非常侧重 LLM 的底层和顶层的权重。利用这一特性,LMFlow 团队提出一个极其简洁的算法:Layerwise Importance Sampled AdamW(LISA)。

LISA 介绍
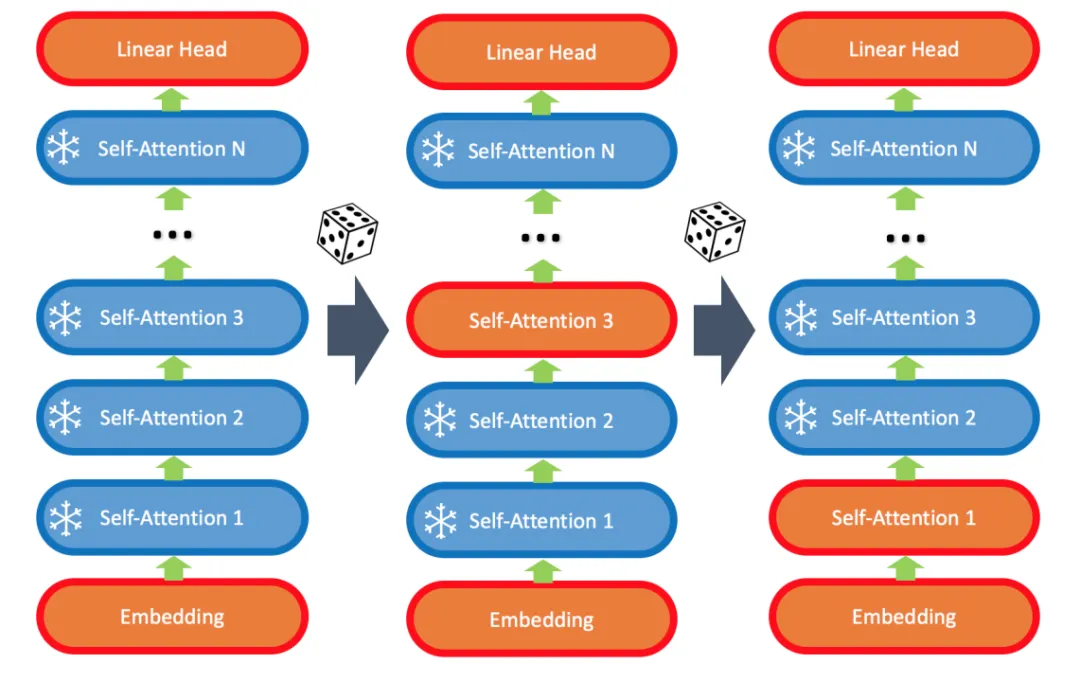
LISA 算法的核心在于:
- 始终更新底层 embedding 和顶层 linear head;
- 随机更新少数中间的 self-attention 层,比如 2-4 层。

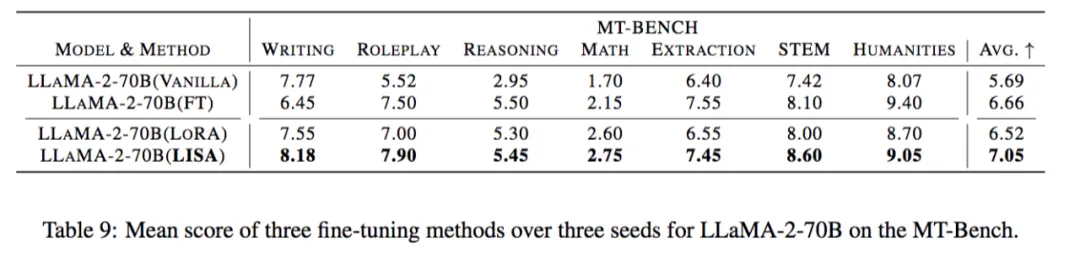
出乎意料的是,实验发现该算法在指令微调任务上超过 LoRA 甚至全参数微调。
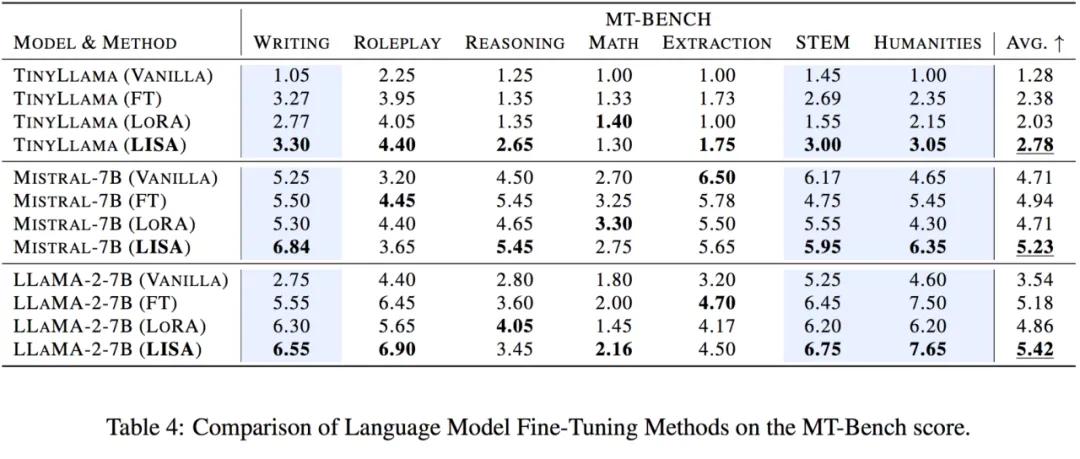
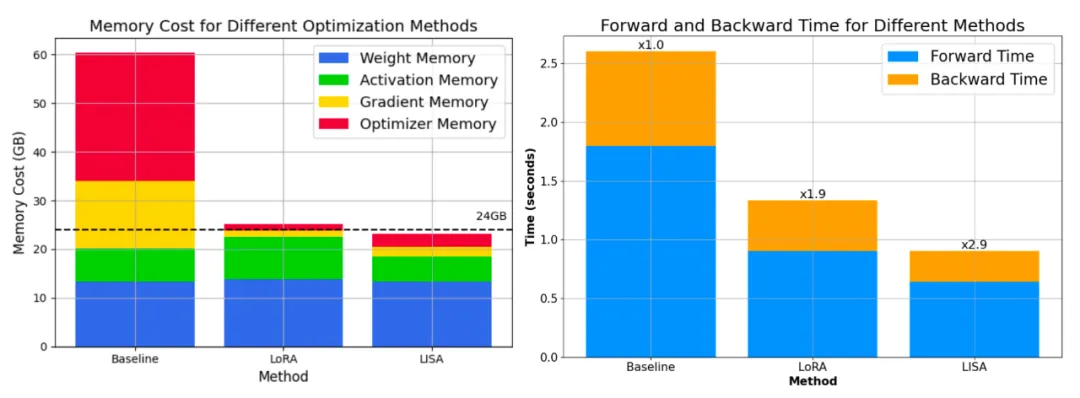
更重要的是,其空间消耗和 LoRA 相当甚至更低。70B 的总空间消耗降低到了 80G*4,而 7B 则直接降到了单卡 24G 以下!
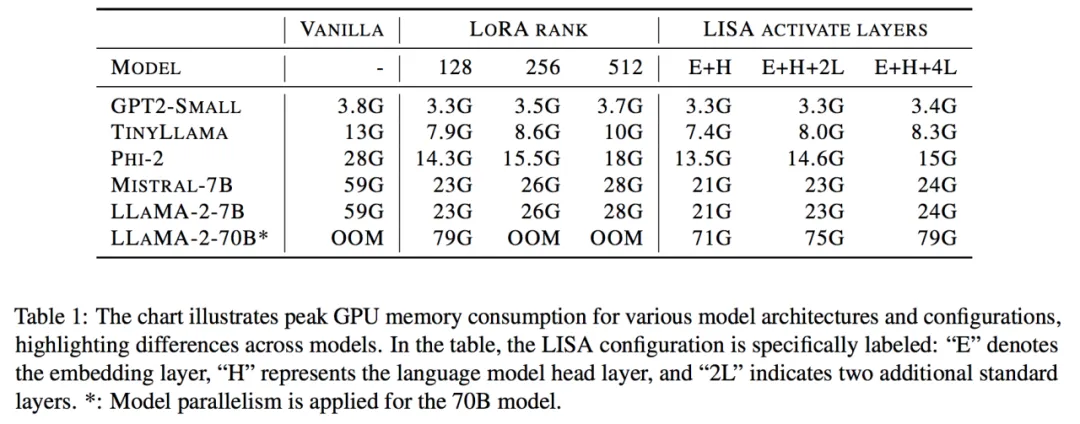
进一步的,因为 LISA 每次中间只会激活一小部分参数,算法对更深的网络,以及梯度检查点技术(Gradient Checkpointing)也很友好,能够带来更大的空间节省。
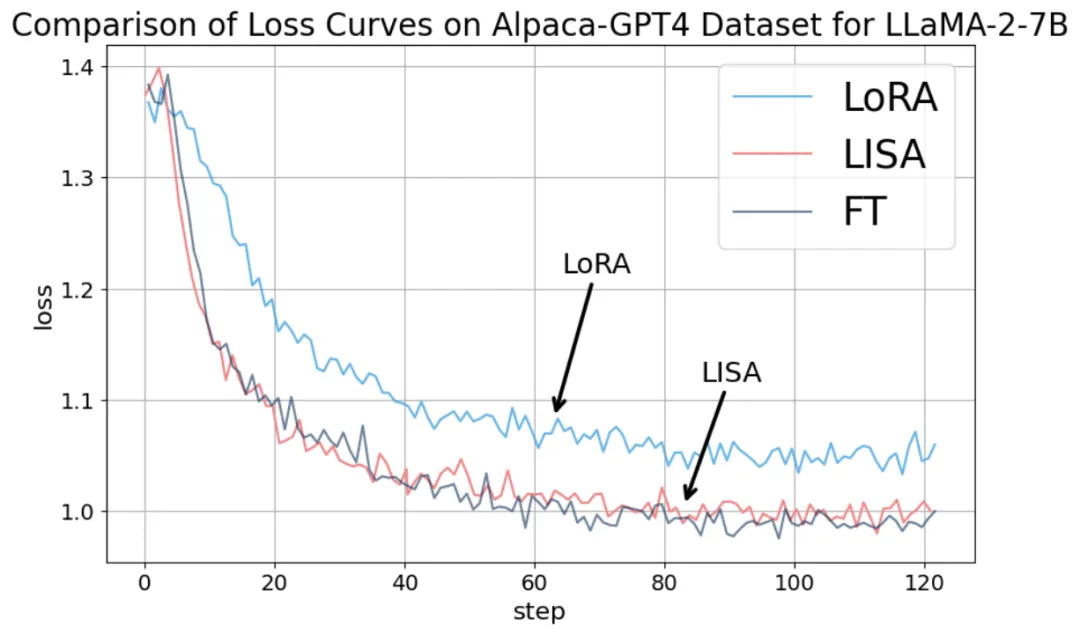
在指令微调任务上,LISA 的收敛性质比 LoRA 有很大提升,达到了全参数调节的水平。
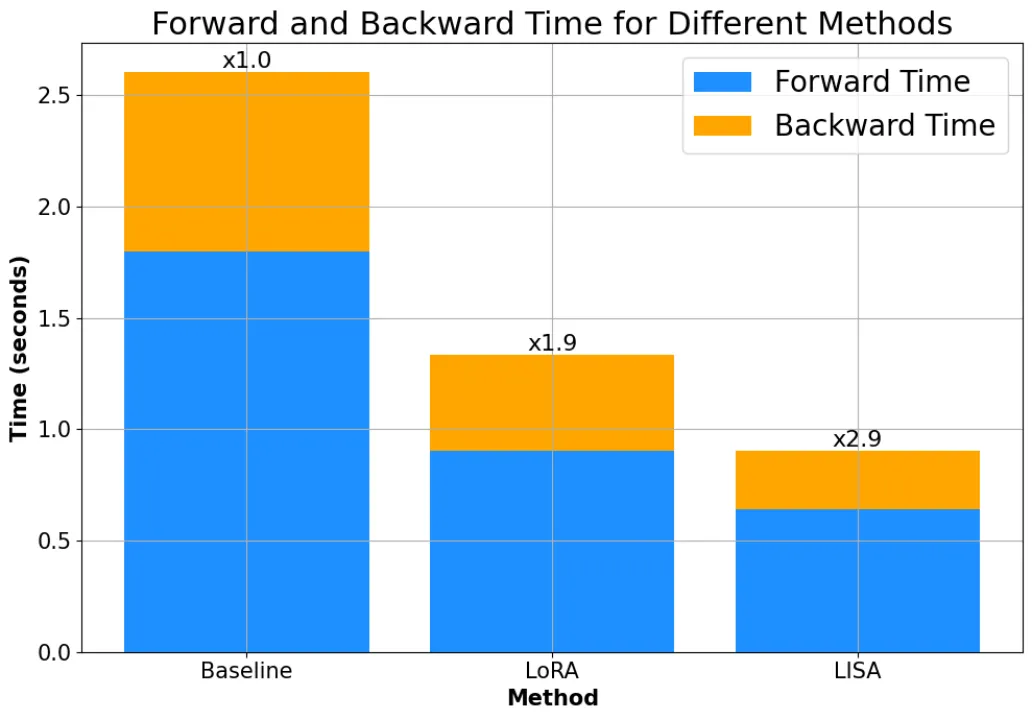
而且,由于不需要像 LoRA 一样引入额外的 adapter 结构,LISA 的计算量小于 LoRA,速度比 LoRA 快将近 50%。
理论性质上,LISA 也比 LoRA 更容易分析,Gradient Sparsification、Importance Sampling、Randomized Block-Coordinate Descent 等现有优化领域的数学工具都可以用于分析 LISA 及其变种的收敛性质。
一键使用 LISA
为了贡献大模型开源社区,LMFlow 现已集成 LISA,安装完成后只需一条指令就可以使用 LISA 进行微调:

如果需要进一步减少大模型微调的空间消耗,LMFlow 也已经支持一系列最新技术:
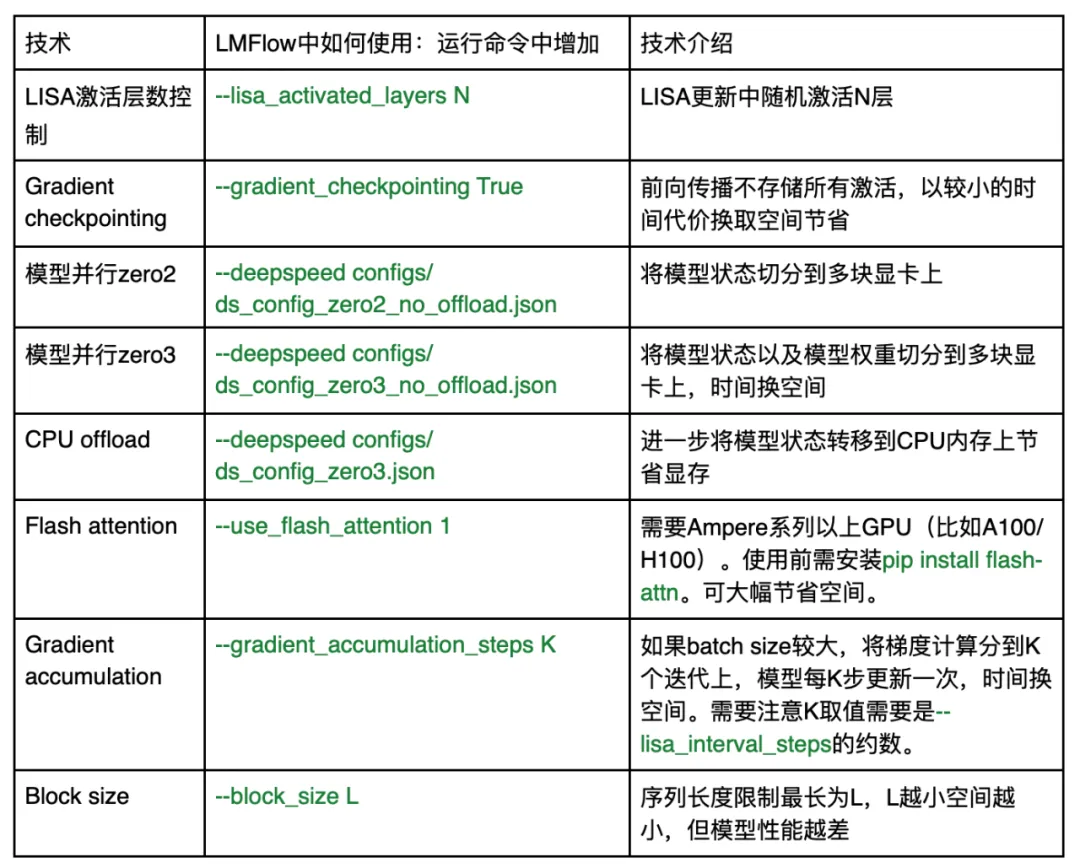
如果在使用过程中遇到任何问题,可通过 github issue 或 github 主页的微信群联系作者团队。LMFlow 将持续维护并集成最新技术。
总结
在大模型竞赛的趋势下,LMFlow 中的 LISA 为所有人提供了 LoRA 以外的第二个选项,让大多数普通玩家可以通过这些技术参与到这场使用和研究大模型的浪潮中来。正如团队口号所表达的:让每个人都能训得起大模型(Large Language Model for All)。
[1] Hu, Edward J., et al. "Lora: Low-rank adaptation of large language models." ICLR 2022.
[2] Dettmers, Tim, et al. "Qlora: Efficient finetuning of quantized llms." Advances in Neural Information Processing Systems 36 (2024).
[3] Ding, Ning, et al. "Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models." arXiv preprint arXiv:2203.06904 (2022).
[4] Lialin, Vladislav, et al. "Stack more layers differently: High-rank training through low-rank updates." arXiv preprint arXiv:2307.05695 (2023).
文章来自微信公众号“机器之心 ,作者:机器之心




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
