# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

会读心的Siri想不想要?
今天,苹果发布了自家的最新模型ReALM,仅需80M参数,就能在上下文理解能力上打平甚至超越GPT-4!

论文地址:https://arxiv.org/pdf/2403.20329.pdf
ReALM可以将任何形式的上下文转换为文本来进行理解,比如解析屏幕、多轮对话、以及上下文中的引用。
在此基础上,用户正在关注什么,甚至是想些什么,都逃不过AI的法眼。
有了这个技术,你的Siri会反应更快,而且更加智能。

比如你让Siri推荐一些披萨店,在看到列表后,你可能希望选择其中一个,打电话叫个外卖。
以前憨憨的Siri并不能执行后面这个操作,但有了ReALM之后,就可以通过分析设备数据等操作,理解你的指示。
在几项相关基准测试中,ReALM的性能表现非常亮眼,连最小的80M参数模型也能媲美GPT-4,而更大的模型分数则更高。
让AI模型根据模糊的语言指令(比如「这个」、「那个」),来执行任务是一个相当复杂的问题。
不过,看起来苹果已经找到了方法,让AI模型能够综合各种模态、各种维度的信息,像人类一样思考和工作。
人类在交谈时,会联系到相当多的信息,——玩手机时也一样(比如后台任务、其他界面的显示、非对话实体)。
传统的模型很难理解这么复杂的参考信息,而苹果通过将所有内容转换为文本来简化了这个问题。
下面是一个对话场景转换为文本的例子:
在这方面,即使是ReALM最小的模型都表现得足够好(GPT-4级别),而且仅仅80M的参数非常适合在终端设备上使用。
——做更适合iPhone等设备的智能,这显然是苹果想要开辟的道路。
以解析屏幕为例,GPT-4等模型依赖图像识别,背后是基于大量图像训练数据而产生的大量参数。
而ReALM选择将图像转换为文本,节省了高级图像识别所需的参数,从而变得更小、更高效。
此外,苹果还通过限制解码、使用简单的后处理等方法来避免幻觉问题。

近期,苹果的人工智能研究不断发表,而6月将要召开的WWDC,会让我们看到苹果更多面向未来的布局。
首先给出一图流总结:
论文使用的数据集由合成数据,以及在注释者帮助下创建的数据组成。
每个数据点都包含用户查询和实体列表,以及与相应用户查询相关的真值实体(或实体集)。
反过来,每个实体又包含有关其类型和其他属性的信息,如名称和与实体相关的其他文本细节(如警报的标签和时间)。
对于存在相关屏幕上下文的数据点,上下文的形式包括实体的边界框、实体周围的对象列表以及这些周围对象的属性(如类型、文本内容和位置)。
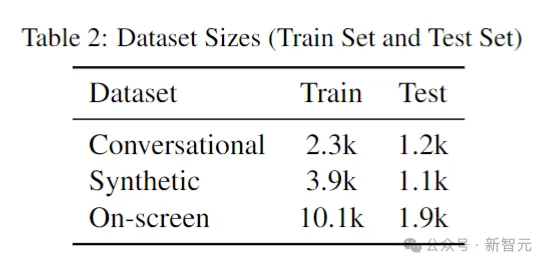
下表给出了训练集和测试集的情况:
在这种情况下,将收集用户与代理交互相关的实体的数据。
为此,会向测评员展示带有综合实体列表的屏幕截图,并要求测评员提供能明确引用综合列表中任意挑选的实体的查询。
例如,可能会向测评员提供企业或警报的综合列表,并要求他们引用该列表中的特定实体。
例如,可能会向测评员显示一个综合构建的企业列表,然后让他们引用所提供的列表中的特定企业。
例如,他们可能会说「带我去倒数第二的那个」或「打电话给主街上的那个」。
另一种获取数据的方法是依靠模板合成数据。
这种方法对基于类型的引用特别有用,因为用户查询和实体类型足以解析引用,而不需要依赖描述。
需要注意的是,此数据集的合成性质并不排除它包含可以将多个实体解析为给定引用的数据点:例如,对于查询「play it」,「it」可以解析为「音乐」和「视频」类型的所有实体。
有两个模板可以生成合成数据。第一个「基础」模板包括引用、实体和必要时可能的槽值(slot values)。
第二个「语言」模板导入了基础模板,并添加了不同的查询变量,这些查询可用于基础模板中定义的引用的目标案例。
数据生成脚本采用基础模板和语言模板,并通过用基础模板中定义的提及和槽值替换引用,生成语言模板中给出的可能查询。
它遍历所有受支持的实体。对于与模板中的实体匹配的实体类型,它会连接引用和实体,否则它只会添加没有引用的实体类型。
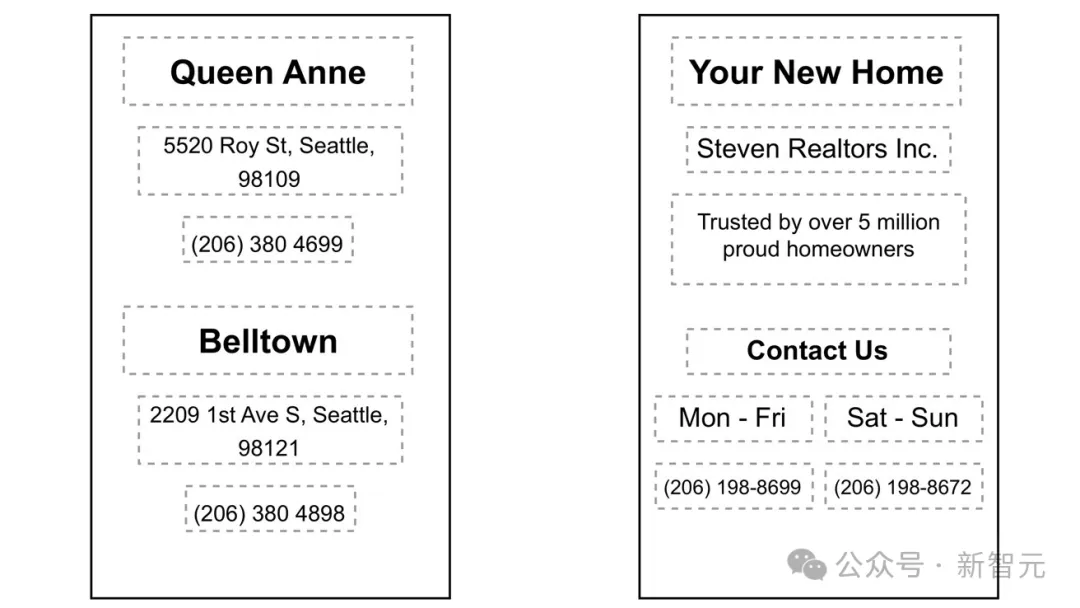
屏幕数据是从存在电话号码、电子邮件或者实际地址信息的各种网页中收集的。
论文对屏幕数据进行了两个阶段的注释处理。
第一阶段是根据屏幕提取查询,第二阶段是识别给定查询的实体和提及。
在第一个分级项目中,测评员会得到一张带有绿色和红色方框的屏幕截图(图 1a),以及绿色框中包含的信息,并要求他们将绿色方框中的数据归类为其中一个实体,如电话号码、电子邮件地址等。
然后,要求测评员对绿框中的数据提供三个唯一的查询结果。
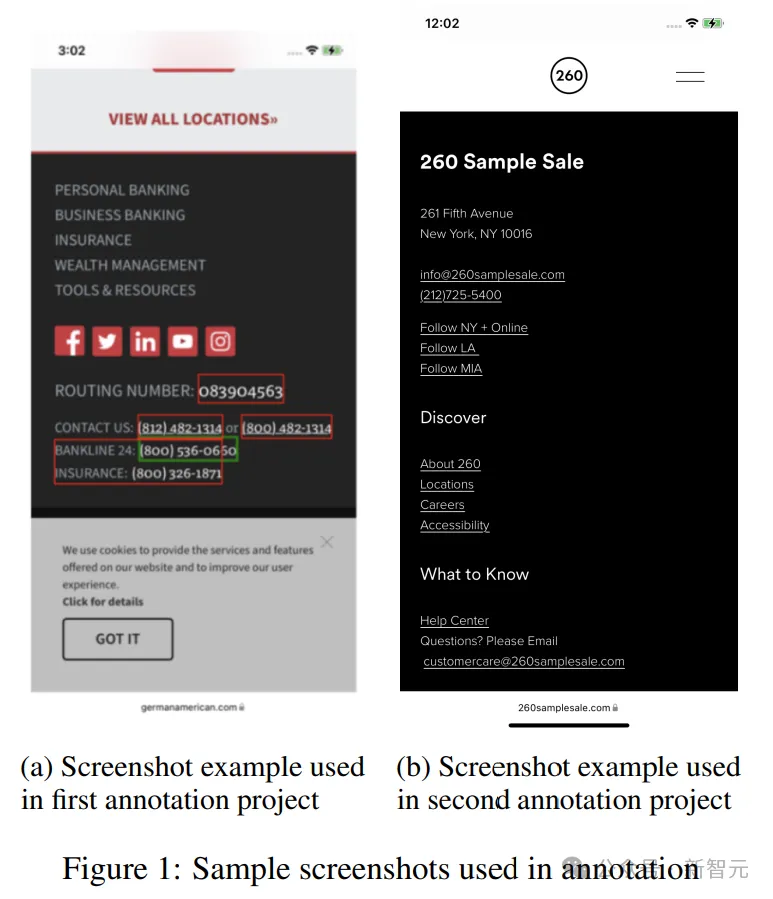
在第二个注释项目(图1b)中,将第一步收集到的查询以列表形式逐一展示给评分员,并附带相应的屏幕截图(无边界框)和所有屏幕实体。
测评员被问及该查询是否提到了给定的视觉实体之一,查询是否听起来自然。此外,他们还被要求提供所给查询中提及的列表实体,并标记查询中提及该实体的部分。
论文将其提出的模型ReALM与两种基线方法进行了比较:一种是基于MARRS中提出的参考解析器的重新实现(这种方法不使用LLM);另一种是基于ChatGPT。
在论文的具体实施中使用以下流程对LLM(FLAN-T5模型)进行微调。
将解析后的输入提供给模型,并对其进行微调。

需要注意的是,与基线不同,论文没有在FLAN-T5模型上运行广泛的超参数搜索,而是坚持使用默认的微调参数。
对于由用户查询和相应实体组成的每个数据点,我们都会将其转换为句子格式,以便提供给LLM进行训练。
为了完成这项工作,论文假设会话引用有两种类型:基于类型的引用和描述性引用。
基于类型的引用在很大程度上依赖于将用户查询与实体类型结合使用,以确定哪个实体(一组实体中的哪一个)与相关的用户查询最相关:
例如,如果用户说「play this」,我们就知道他们指的是一首歌或一部电影这样的实体,而不是电话号码或地址;「call him」同样指的是一组电话号码或联系人中的第一个,而不是警报器。
相比之下,描述性引用倾向于使用实体的某个属性来唯一标识它:例如,「The one in Times Square」可能是指一组地址或企业中的一家。
需要注意的是,通常情况下,引用可能同时依赖于类型和描述来明确指代一个对象:考虑示例「play the one from Abbey Road」与「directions to the one on Abbey Road」,这两种情况都依赖于实体类型和描述,来识别第一种情况下的歌曲,以及第二种情况下的地址。
在论文提出的方法中,简单地对实体的类型和各种属性进行编码。
对于屏幕上的引用,先假设存在能够解析屏幕文本以提取实体的上游数据检测器。
然后,获得这些实体的类型、边界框和相关的非实体文本元素列表。
使用下面给出的算法,将这些实体(以及屏幕的相关部分)以仅涉及文本的方式编码到模型中:

研究人员假设所有实体及其周围对象的位置都可以通过各自边界框的中心来表示。
然后先从上到下(垂直,沿y轴)对这些中心(以及相关对象)进行排序,并在保持稳定的情况下,从左到右(水平,沿x轴)排序。
接下来,边距内的所有对象都被视为在同一行上,并用制表符彼此分隔,边距外更下方的对象被放置在下一行。
重复进行上面的操作,就可以有效地将屏幕信息从左到右、从上到下编码为纯文本。
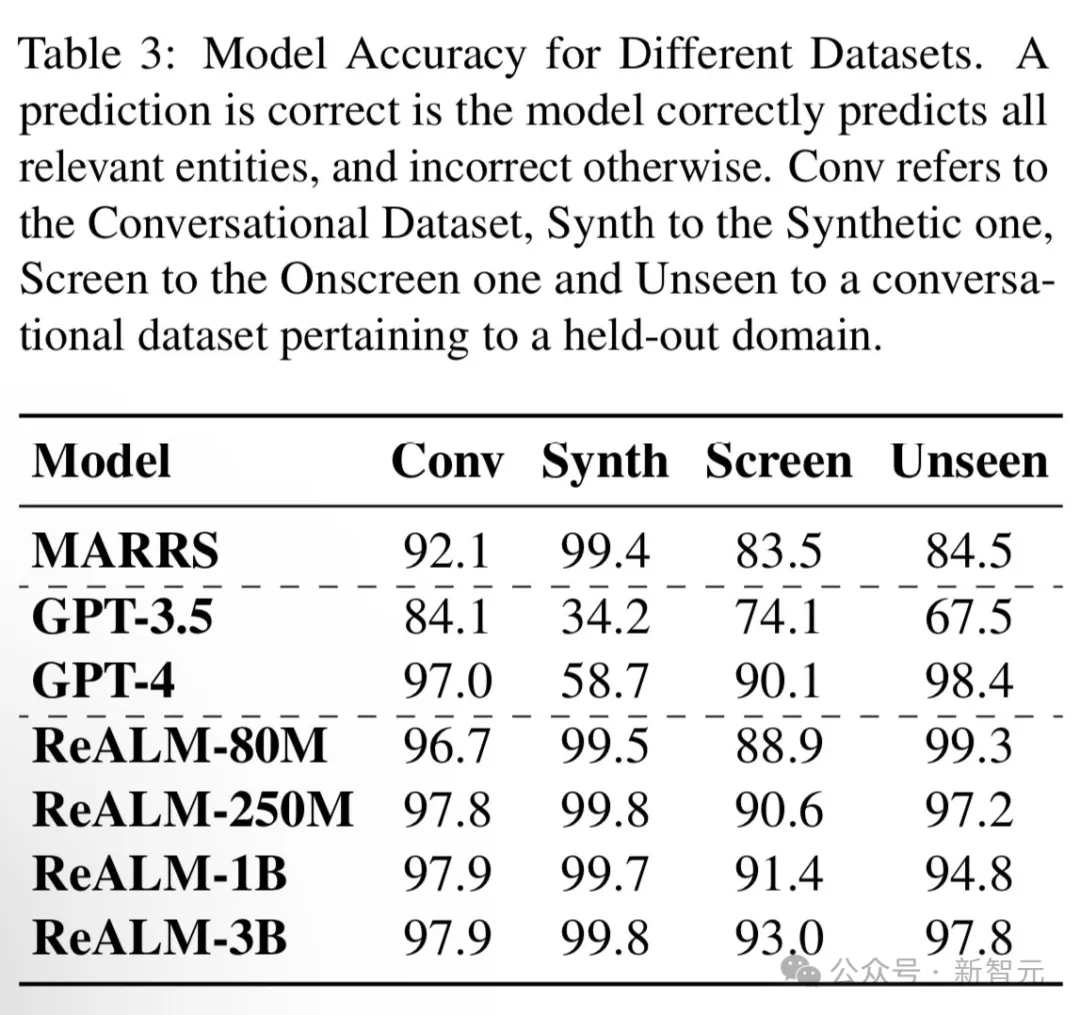
下表展示了ReALM和其他SOTA模型PK的结果:
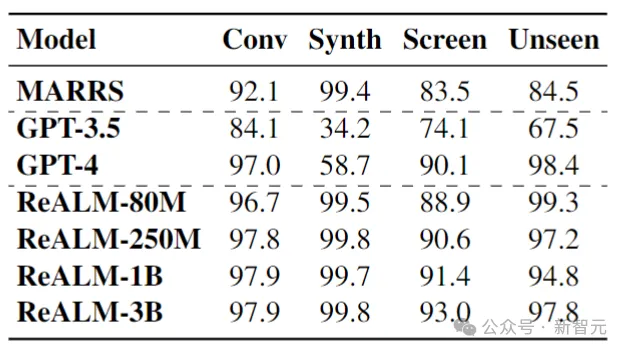
总体而言,ReALM在所有类型的数据集中都优于MARRS模型,并且干掉了参数量大几个数量级的GPT-3.5。
在屏幕相关的数据集上,ReALM采用的文本编码方法能够表现得几乎与GPT-4(采用屏幕截图)一样好。
最后,研究人员尝试了不同尺寸的模型。可以看到,随着模型大小的增加,所有数据集的性能都有所提高,而屏幕相关数据集的差异最为明显,因为这项任务在本质上更加复杂。
参考资料:
https://appleinsider.com/articles/24/04/01/apple-ai-research-realm-is-smaller-faster-than-gpt-4-when-parsing-contextual-data
文章来自微信公众号“新智元”,作者:新智元



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
