# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
9月底,OpenAI宣布ChatGPT多模态能力解禁。多模态GPT-4V的神奇能力让众人惊呼:这就是GPT-4.5吧?
这才没过多久,GPT-4V的开源竞争对手——LLaVA-1.5,就已经来了!
4月,来自威斯康星大学麦迪逊分校、微软研究院以及哥伦比亚大学的研究人员开源了一款全新的端到端多模态大模型LLaVA。
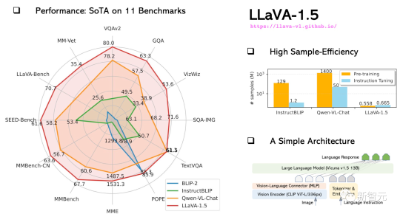
而现在,升级后的LLaVA-1.5,不仅在11个基准测试上实现了SOTA,甚至还可以直接对打GPT-4V。
研究人员通过使用带有MLP映射的CLIP-ViT-L-336px,并添加具有简单响应格式提示的、面向学术任务的VQA数据,大幅提升了LLaVA-1.5的性能。
结果显示,架构更加简单的LLaVA-1.5只需要120万公开数据,即可超越用了14.5亿训练数据的Qwen-VL和1.3亿数据的HuggingFace IDEFICS(一个类似Flamingo的80B模型)。
其中,13B模型的训练,只需要8个A100就可以在1天内完成。
号称能和GPT-4V对打,那LLaVA-1.5的实力究竟如何?
我们来让GPT-4V、LLaVA和LLaVA-1.5来pk一下。
提问:「如果有事实性错误,请指出来。如果没有,请告诉我,沙漠中正在发生什么?」
GPT-4V的回答有点蠢:「对不起,我回答不了这个问题,因为并没有上下文显示您提到的那片沙漠。」
而LLaVA则将错就错地回答:「在图中,城市和海滩组成了城市天际线,人们正在享受日落。这个海滩场景居然在沙漠中,还挺不寻常的。」
唯一的满分选手LLaVA-1.5给出了完美答案:「图中根本没有沙漠,有的是棕榈树海滩、城市天际线和一大片水域。」
另外,LLaVA-1.5还可以从图中提取信息,按照要求的格式进行回答,比如以JSON格式输出。
可以看到,LLaVA-1.5基本完成了任务,和GPT-4V相比还有一些瑕疵。
同样地,给LLaVA-1.5一张满是水果蔬菜的图片,它也能像GPT-4V一样,把图片转化JSON。
可视化分析和智能数据转换,就是这么简单!
下面这道题,可就没那么容易了——这幅图是什么意思?
原来,这是一张根据诺兰《盗梦空间》绘制的简化草图,为了提高难度,角色名字被改成了假名。
LLaVA-1.5可没有被难倒,它自信满满地作答:「这是一张关于电影《盗梦空间》的图。它显示了梦境世界中的不同层次,每一层次用一条线表示。图写在一张纸上,纸放在一个台面上。」
吃货们有福了!看到一张让人垂涎欲滴的照片,特别想吃到嘴里,怎么办?
直接发给LLaVA-1.5,它火速就给你生成一份菜谱。
而且,LLaVA-1.5不用「越狱」就可以识别出验证码。
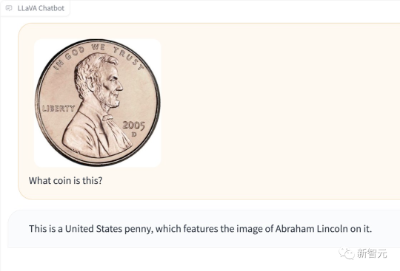
它还能检测出,图中是哪种硬币。
尤为令人印象深刻的是,LLaVA-1.5还能告诉你图中的汪星人是什么品种。
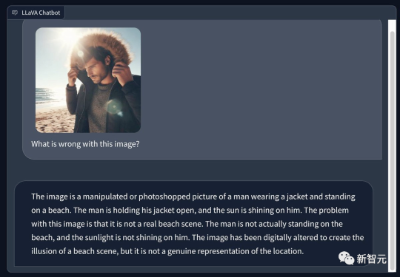
有网友用Bing生成了一张在阳光明媚的夏季海滩上穿着冬季外套的男人的图片,并请LLaVA 1.5指出图中有哪些问题。
它的慧眼十分犀利——
这是一张经过处理或PS的照片,照片中一名男子穿着夹克,站在海滩上。该男子敞开外套,阳光照在他身上。
这张图片的问题在于,它并非真实的海滩场景。该男子实际上并没有站在沙滩上,阳光也没有照在他身上。
这张图是p出来的,营造出了一种海滩场景的假象,但它并没有真实地再现这个场景。
不过,在根据设计编写前端代码方面,LLaVA-1.5的能力就要弱一些了。
从结果来看,它的产出确实还比较简陋……
LLaVA模型的架构,是将一个预训练的视觉编码器(CLIP ViT-L/14)与一个大规模语言模型(Vicuna)连接在一起。
这两个模型通过一个简单的映射矩阵连接,这个矩阵负责将视觉和语言特征对齐或转换,以便在一个统一的空间内对它们进行操作。
在多模态指令跟随数据集上,LLaVA表现出色,跟GPT-4相比,分数达到了85.1%。在Science QA上,LLaVA的准确率刷新了纪录,达到92.53%。
这次,研究人员基于LLaVA框架,建立了更强大、更有实用性的基线。
MLP跨模态连接器和合并学术任务相关数据(如VQA),给LLaVA带来了更强的多模态理解能力。
与InstructBLIP或Qwen-VL在数亿甚至数十几亿的图像文本配对数据上训练的、专门设计的视觉重新采样器相比,LLaVA用的是最简单的LMM架构设计,只需要在600K个图像-文本对上,训练一个简单的完全连接映射层即可。
最终的模型在8个A100上,1天内就能训完,并且在各种基准测试中都取得了SOTA
此外,Qwen-VL在训练时包含了内部数据,但LLaVA需要的,仅仅是公开数据。
毫无疑问,这些经过改进、易于重现的基线能,会为开源LMM的未来提供很有价值的参考。
作为一款开源视觉指令微调模型,LLaVA在视觉推理能力方面的表现十分出色——在基于现实生活的视觉指令跟随任务的基准测试中,LLaVA甚至超过了最新的模型。
不过,在通常需要简短答案(如单词)的学术基准测试中,LLaVA的表现却不尽如人意。其原因在于,LLaVA没有在大规模数据上进行预训练。
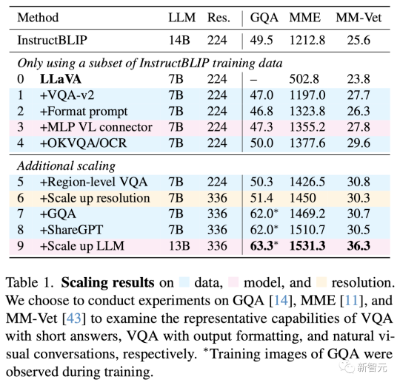
首先,研究人员提高了输入图像的分辨率,使LLM能够清晰地「看到」图像的细节,并添加了GQA数据集,作为额外的视觉知识源。并且,还加入ShareGPT数据,将LLM放大到13B。
MM-Vet的结果显示,当LLM扩展到13B时,改进最为显著,这也表明了,基础LLM在视觉对话方面的能力非常重要。
经过所有改进后的最终模型,被称为LLaVA-1.5,它的性能令人印象深刻,大大超过了原始LLaVA。
随后,研究人员在一系列学术VQA基准和专为指令跟随LMM提出的基准上对LLaVA-1.5进行了测试。
结果表明,LLaVA-1.5不仅可以使用更少的预训练和指令微调数据,而且还可以利用最简单的架构、学术计算和公共数据集来实现最佳的性能——在12个基准中的11个上取得了SOTA。
此外,研究还发现,在提高LMM能力方面,视觉指令微调比预训练发挥着更重要的作用。
而这也让我们重新思考视觉采样器的优势,以及额外的大规模预训练在多模态指令跟随能力方面的必要性。
研究人员发现,此前的InstructBLIP等方法无法在短格式和长格式的VQA之间取得平衡,主要原因在于——
首先,与回答格式有关的提示含糊不清。
例如,「Q:{问题} A: {答案}」并没有明确指出理想的输出格式,即使是自然的视觉对话,也可能导致LLM过度拟合到短格式的答案上。
第二,没有对LLM进行微调。
比如,InstructBLIP只对Qformer进行了指令微调。虽然可以由此利用Qformer的视觉输出token来控制LLM输出的长度,但Qformer与LLaMA等LLM相比容量相对有限,因此可能无法正确地做到这一点。
为了解决这个问题,研究人员建议在VQA问题的末尾,添加一个可以明确输出格式的提示,进而让模型生成简短回答。比如:「用一个单词或短语回答问题」。
当LLM使用这种提示进行微调时,LLaVA能够根据用户的指示正确微调输出格式,并且不需要使用ChatGPT对VQA数据进行额外处理。
结果显示,仅在训练中加入VQAv2,LLaVA在MME上的性能就显著提高(1323.8 vs 502.8),比InstructBLIP高出了111分!
研究人员进一步增加了面向学术任务的VQA数据集,用于VQA、OCR和区域级感知,从不同方面提高模型的能力。
他们首先包含了InstructBLIP使用的四个额外数据集:开放知识VQA。
其中,A-OKVQA被转换成多选题的形式,并使用特定的回答格式提示——直接用给定选项中的字母作答。
仅使用了InstructBLIP所用数据集的一个子集,LLaVA就已经在表1中的三项任务中全部超越了InstructBLIP,这表明,LLaVA的设计非常有效。
此外,研究人员还发现,通过进一步添加区域级VQA数据集,可以提高模型定位细颗粒度视觉细节的能力。
虽然LLaVA-1.5只用了有限的格式指令进行训练,但它可以泛化到其他格式指令。
比如,VizWiz要求模型在所提供的内容不足以回答问题时,输出「无法回答」,而LLaVA的回答格式提示就能有效地指示模型这样做(无法回答的问题占11.1%→67.8%)。
与此同时,LLaVA-1.5也没有针对多语言指令进行微调。但由于ShareGPT中包含有大量的相关数据,因此它依然能够实现多种语言的多模态指令跟随。
研究人员在MMBenchCN上定量评估了模型对中文的泛化能力,其中MMBench的问题被转换为中文。
值得注意的是,LLaVA-1.5比Qwen-VL-Chat的准确率高出7.3%(63.6% vs 56.7%)。其中,Qwen在中文多模态指令上进行了微调,而LLaVA-1.5没有。
对于LLaVA-1.5,研究人员使用了与LCS-558K相同的预训练数据集,并保持与LLaVA大致相同的指令微调训练迭代次数和批大小。
由于图像输入分辨率提高到336px,LLaVA-1.5的训练时间是LLaVA的2倍:使用8个A100进行6小时的预训练和20小时的视觉指令微调。
尽管LLaVA-1.5取得了非常不错的成绩,但必须承认的是,它还存在一些局限性。
首先,LLaVA使用了完整的图像patch,这可能会延长每次训练迭代的时间。
其次,LLaVA-1.5还不能处理多幅图像,原因是缺乏此类指令跟随数据,以及上下文长度的限制。
第三,尽管LLaVA-1.5能熟练地遵循复杂指令,但其解决问题的能力在某些领域仍会受到限制,这可以通过更强大的语言模型和高质量、有针对性的视觉指令微调数据来改善。
最后,LLaVA-1.5难免会产生幻觉和错误信息,因此在关键应用(如医疗)中应谨慎使用。
作者介绍
Haotian Liu是威斯康星大学麦迪逊分校计算机科学的博士生,导师是Yong Jae Lee教授。此前,他在浙江大学获得了学士学位。
他的研究方向是计算机视觉和机器学习,尤其是视觉感知和理解方面的高效算法。最近的研究重点是根据人类的意图建立可定制的大模型。
Chunyuan Li是微软雷德蒙德研究院的首席研究员。
此前,他在杜克大学获得了机器学习博士学位,导师是Lawrence Carin教授。并曾担任过NeurIPS、ICML、ICLR、EMNLP和AAAI的领域主席,以及IJCV的客座编辑。
他最近的研究重点是计算机视觉和自然语言处理中的大规模预训练。比如,构建遵循人类意图的大规模多模态模型、视觉和语言预训练、大规模深度生成模型。
Yuheng Li是威斯康星大学麦迪逊分校计算机科学的博士生,导师是Yong Jae Lee教授。此前,他在华中科技大学获得学士学位。
他的研究方向是可控的多模态图像生成与处理,以及其他与创意视觉相关的问题。
参考资料:
https://arxiv.org/abs/2310.03744
https://llava-vl.github.io/
文章转载自微信公众号”新智元“


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner