
揭秘AI幻觉:GPT-4V存在视觉编码漏洞,清华联合NUS提出LLaVA-UHD
揭秘AI幻觉:GPT-4V存在视觉编码漏洞,清华联合NUS提出LLaVA-UHDGPT-4V 的推出引爆了多模态大模型的研究。GPT-4V 在包括多模态问答、推理、交互在内的多个领域都展现了出色的能力,成为如今最领先的多模态大模型。
来自主题: AI技术研报
6305 点击 2024-04-07 17:46
 搜索
搜索
GPT-4V 的推出引爆了多模态大模型的研究。GPT-4V 在包括多模态问答、推理、交互在内的多个领域都展现了出色的能力,成为如今最领先的多模态大模型。

对于大型视觉语言模型(LVLM)而言,扩展模型可以有效提高模型性能。然而,扩大参数规模会显著增加训练和推理成本,因为计算中每个 token 都会激活所有模型参数。
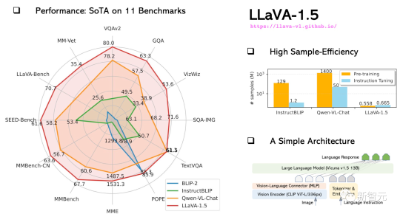
GPT-4V风头正盛,LLaVA-1.5就来踢馆了!它不仅在11个基准测试上都实现了SOTA,而且13B模型的训练,只用8个A100就可以在1天内完成。