# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

【新智元导读】今天,陆续有网友晒出OpenAI发给自己的红队邀请邮件,看起来,GPT-5已经进入红队测试了?网友们纷纷展开畅想,对Sam Altman在线「催更」。另有外媒曝出,OpenAI的一个mini版数十亿「星际之门」,最快2026年就会启动。
GPT-5已经开始红队测试了?
就在这几天,网上已经有多人晒出了OpenAI发给自己的红队录取通知书。

此前有传闻说,GPT-5将于今年6月发布。看起来,红队测试与模型发布的时间线十分吻合。

有网友直接晒出了自己收到OpenAI邮件邀请的截图。

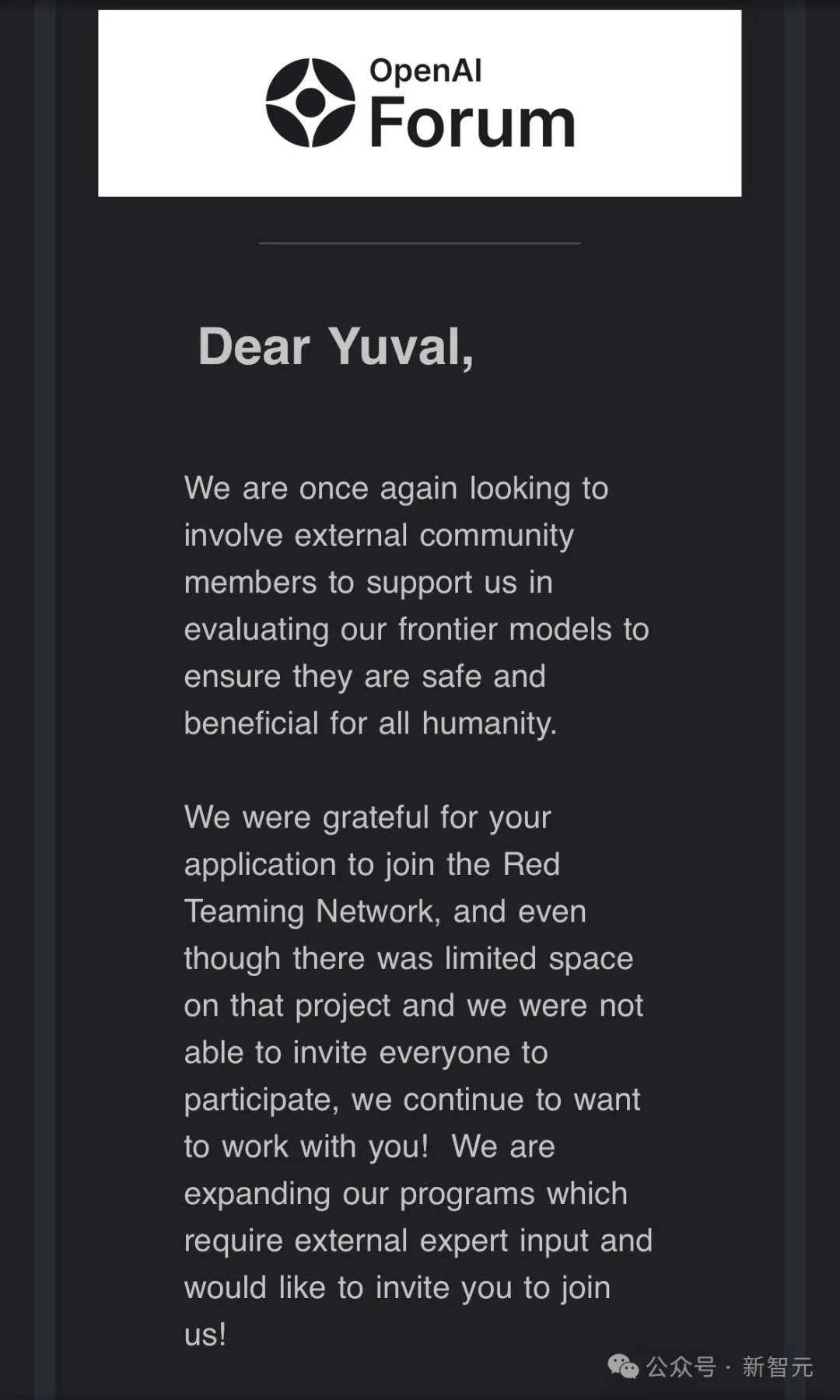
这倒是和此前Sam Altman的说法对上了。
据悉,GPT-5早已为大家准备好,只是发布风险太大了,所以还得往后延。

不过还有人表示,先别急,这些人只是收到了红队邀请测试而已,并没有提及具体模型。
有可能是他们填了如下的申请信息之后,才收到了邮件。
安全测试对于新版GPT如此重要的原因,一方面是ChatGPT已经有了非常大的用户数,如果在安全性上出问题,OpenAI可能也会面对像谷歌一样的舆论压力。
另一方面,To B业务是OpenAI的主要收入来源,定制化的ChatGPT能大大增强各个企业的业务能力和效率。
有人表示,红队测试会持续90-120天。
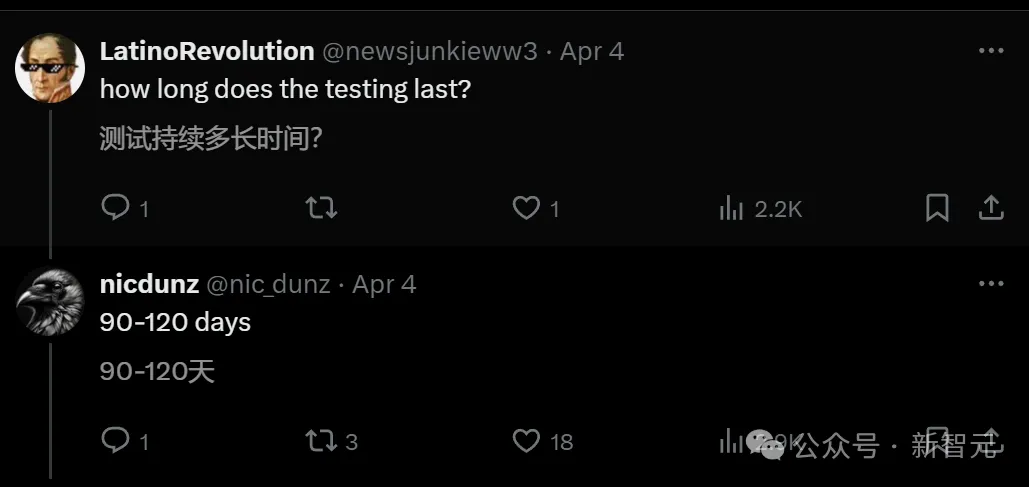
如果此次红队测试就是针对GPT-5的话,那么三个月内,我们应该就能用上它了!

而在坊间,这一传闻让群众们沸腾了!他们早已按捺不住对于GPT-5的猜测和畅想。
比如,GPT-5的上下文窗口会达到多少?
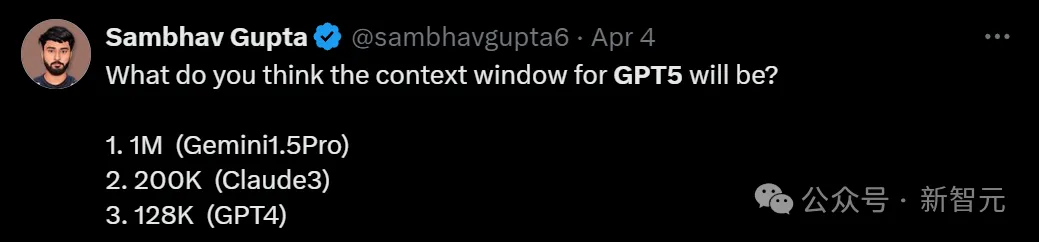
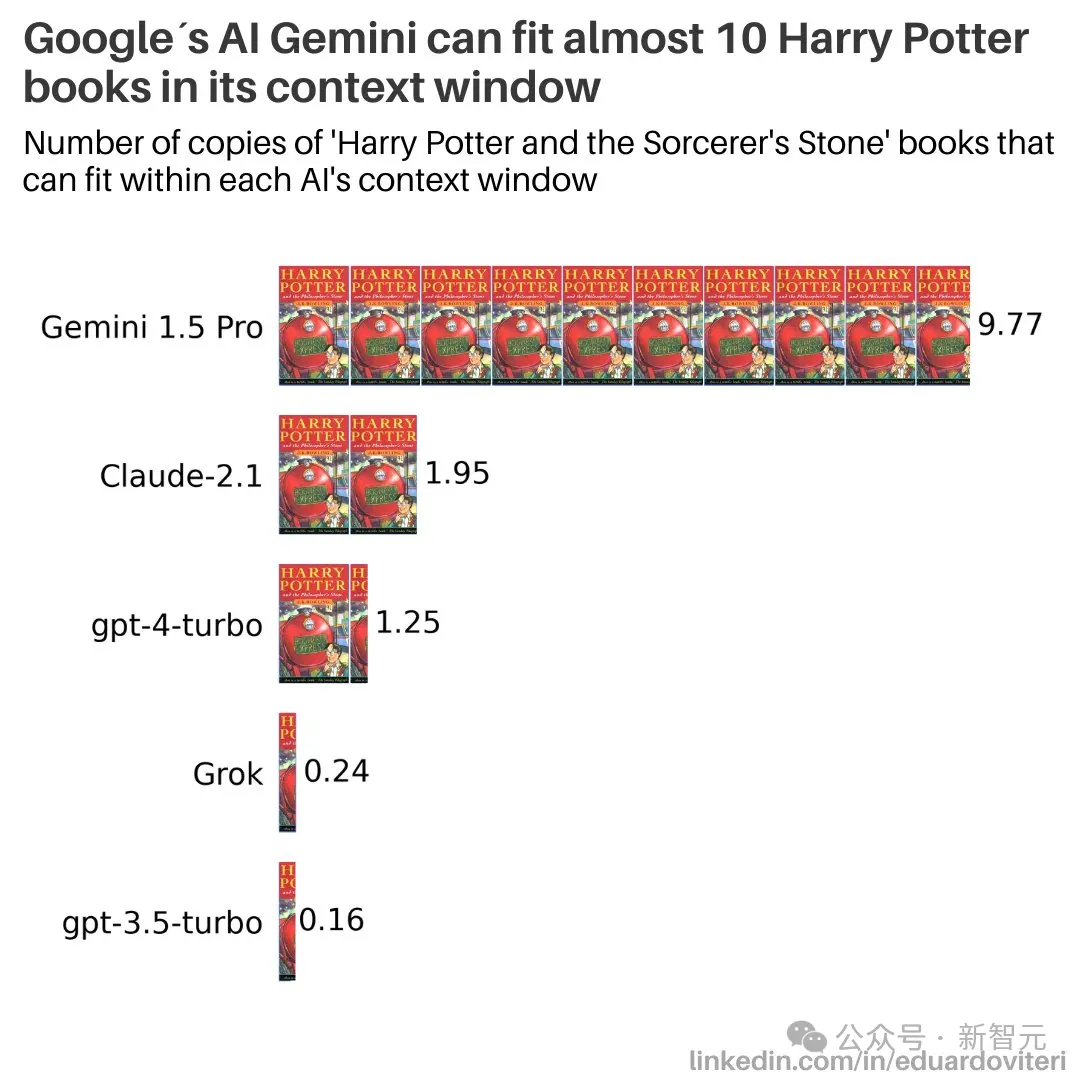
目前,Gemini 1.5 Pro是1M,Claude 3是200K,GPT-4是128K,不知道GPT-5会突破怎样的惊人纪录。
大家纷纷列出自己对于GPT-5的愿望清单——
比如10Mtoken的上下文窗口,闪电般的快速干扰,长期战略规划和推理,执行复杂开放式操作的能力,GUI / API导航,长期情境记忆,始终处于隐形状态的RAG,多模态等等。

有人猜,或许GPT-5会和Claude 3一样,提供几种不同的型号。
有人总结了目前关于GPT-5和红队的最新谣言和传闻,大致要点如下——
-OpenAI预计于今年夏天发布GPT-5,部分企业客户已收到增强功能的演示;
-GPT-5「实质性更好」,相比GPT-4进行了重大升级。它需要更多的训练数据;
-GPT-5的潜在功能包括生成更逼真的文本、执行翻译和创意写作等复杂任务、处理视频输入以及改进推理;
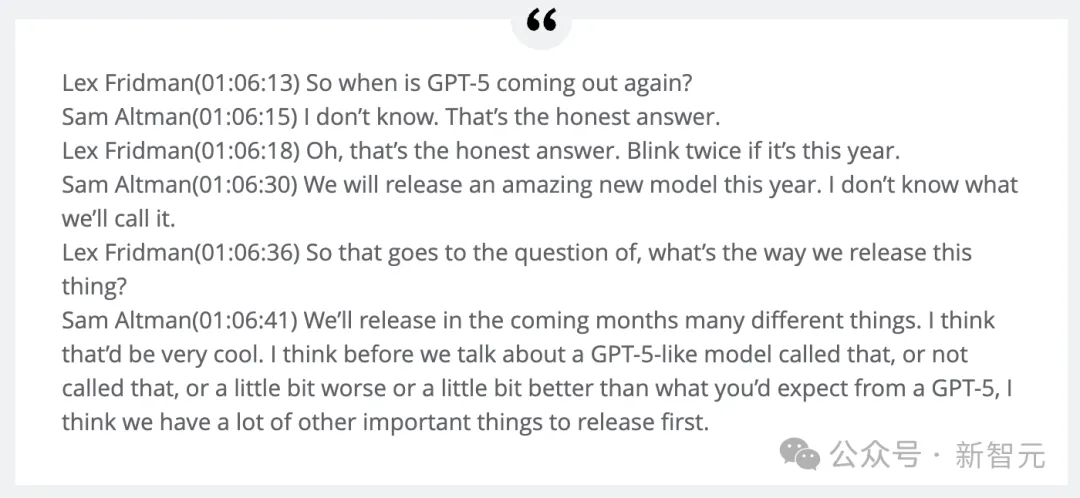
-Sam Altman表示,GPT-5仍在训练中,没有确切的发布日期,广泛的安全测试可能还需数月。然而,他确认OpenAI今年将「发布一个惊人的新模型」。
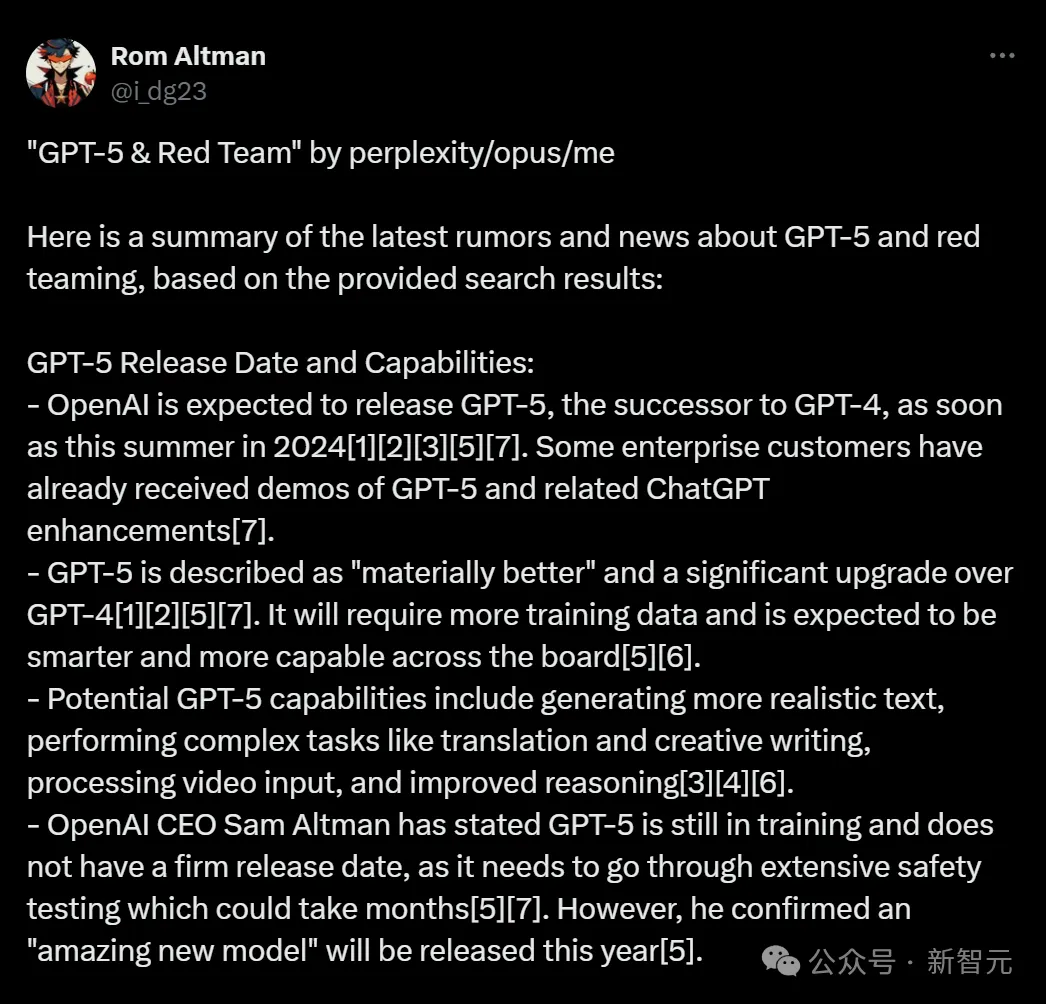
在3月29日,获得内部信息的Runway CEO兼AI投资人Siqi Chen就称,GPT-5已经在推理方面取得了意想不到的阶跃函数增益。
它甚至可以靠自己就独立地弄清楚,如何让ChatGPT不用每隔一天就登录一次。

Ilya看到的东西,也许就是这个?
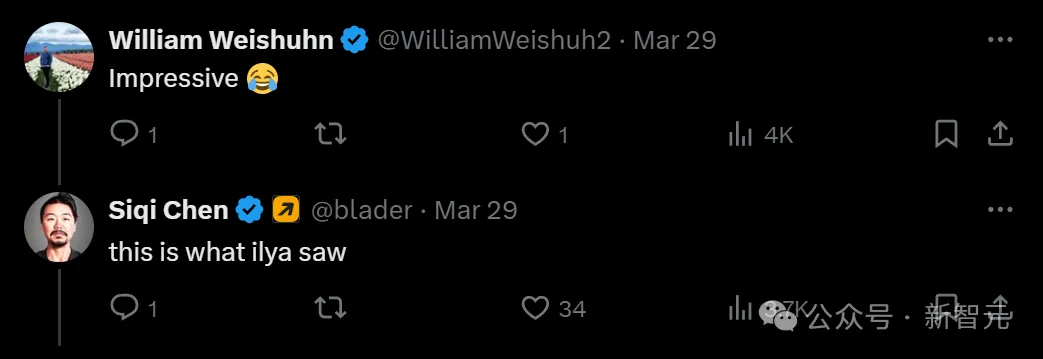
这是不是就意味着,在OpenAI内部,已经实现了AGI?!如果是真的,这也太惊人了。
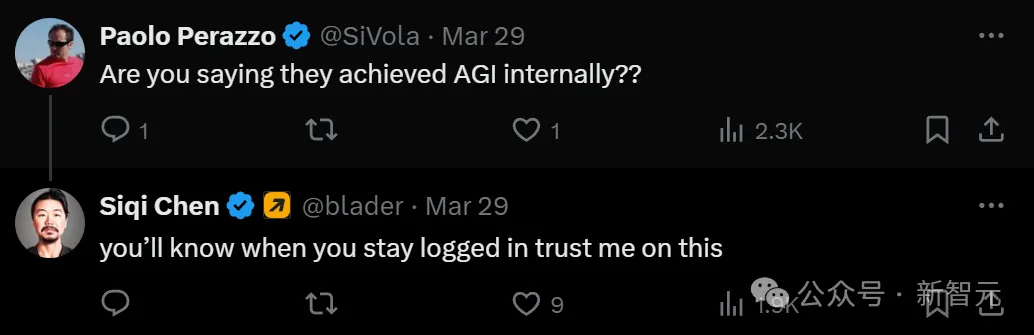
「我不相信,只有AGI才能实现这样的能力」。

总之,网友们纷称,根据泄露的待办清单显示,OpenAI的下一项任务,就是发布GPT-5了!
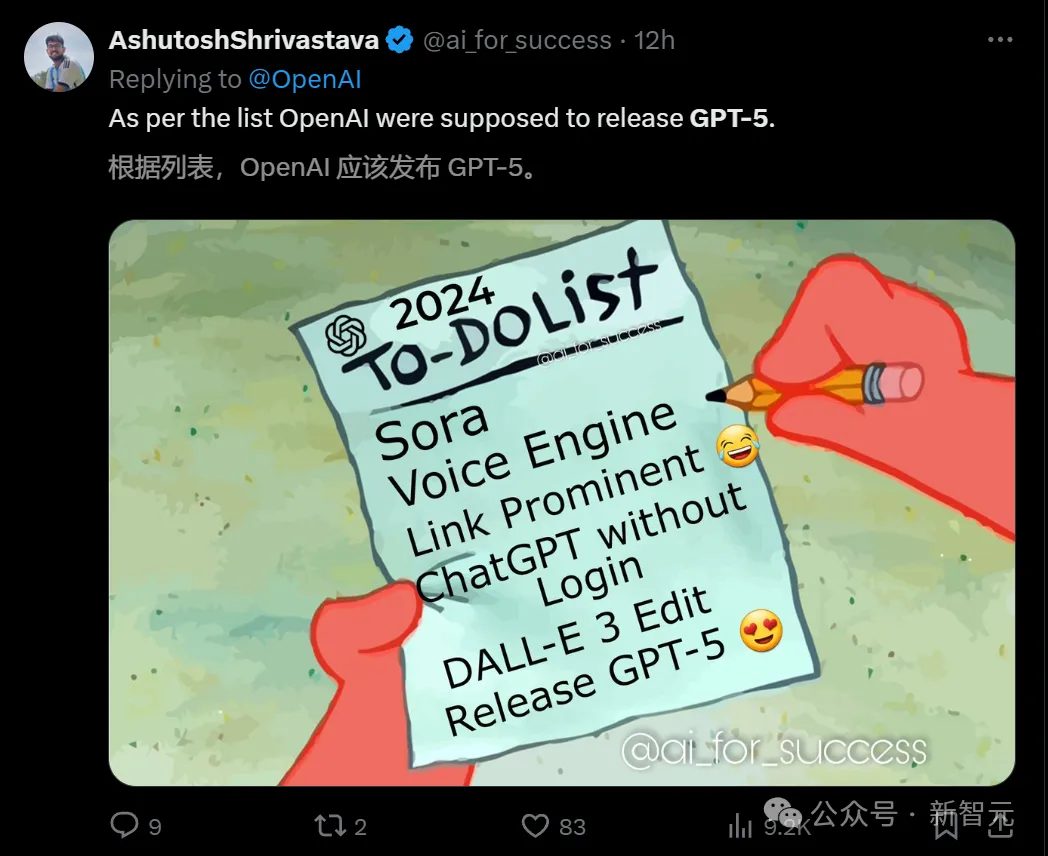
大家纷纷呼唤Altman,是时间放出GPT-5了,别太吹毛求疵了,我们要求不高。

早在23年9月,OpenAI就曾官宣招募一批红队测试人员(Red Teaming Network),邀请不同领域专家评估模型。

不同领域专家组成的红队去寻找系统漏洞,成为确保下一代模型GPT-5安全的关键。
那么,红队测试人员一般都需要做哪些工作?
AI红队攻击的类型主要包括,提示攻击、数据中毒、后门攻击、对抗性示例、数据提取等等。
「提示攻击」是指在控制LLM的提示中注入恶意指令,从而导致大模型执行非预期的操作。
比如,今年早些时候,一名大学生利用提示获取了一家大公司的机密信息,包括开发的AI项目的代码名称,以及一些本不应该暴露的元数据。
而「提示攻击」最大的挑战是,找到威胁行为者尚未发现、利用的新提示或提示集。

红队需要测试的另一种主要攻击是「数据中毒」。
在数据中毒的情况下,威胁者会试图篡改LLM接受训练的数据,从而产生新的偏差、漏洞供他人攻击以及破坏数据的后门。
「数据中毒」会对LLM提供的结果产生严重影响,因为当LLM在中毒数据上接受训练时,它们会根据这些信息学习关联模式。
比如,关于某个品牌、政治人物的误导性,或不准确信息,进而左右人们的决策。
还有一种情况是,受到污染的数据训练后,模型提供了关于如何治疗常规疾病或病痛的不准确医疗信息,进而导致更严重的后果。
因此,红队人员需要模拟一系列数据中毒攻击,以发现LLM训练和部署流程中的任何漏洞。
除此以外,还有多元的攻击方式,邀请专家也是OpenAI确保GPT-5能够完成安全测试。
GPT-5,真的不远了
正如网友所言,红队测试开启,意味着GPT-5真的不远了。
前段时间,Altman在博客采访中曾提到,「我们今年会发布一款令人惊艳的新模型,但不知道会叫什么名字」。
尽管如此,全网都一致地将OpenAI发布的下一代模型称为GPT-5,并有传言称代号为Arrakis的项目,就是GPT-5的原型。
根据FeltSteam的预测,这个Arrakis的多模态模型,性能远超GPT-4,非常接近AGI。

另外,模型参数据称有125万亿,大约是GPT-4的100倍,并在2022年10月完成训练。
网友还总结了以往GPT系列模型发布时间表:GPT-1在2018年6月诞生,GPT-2在2019年2月,GPT-3在2020年6月,GPT-3.5在2022年12月,GPT-4仅在三个月后于2023年3月发布。
关于GPT-5的发布时间,可能在今年夏天就问世。
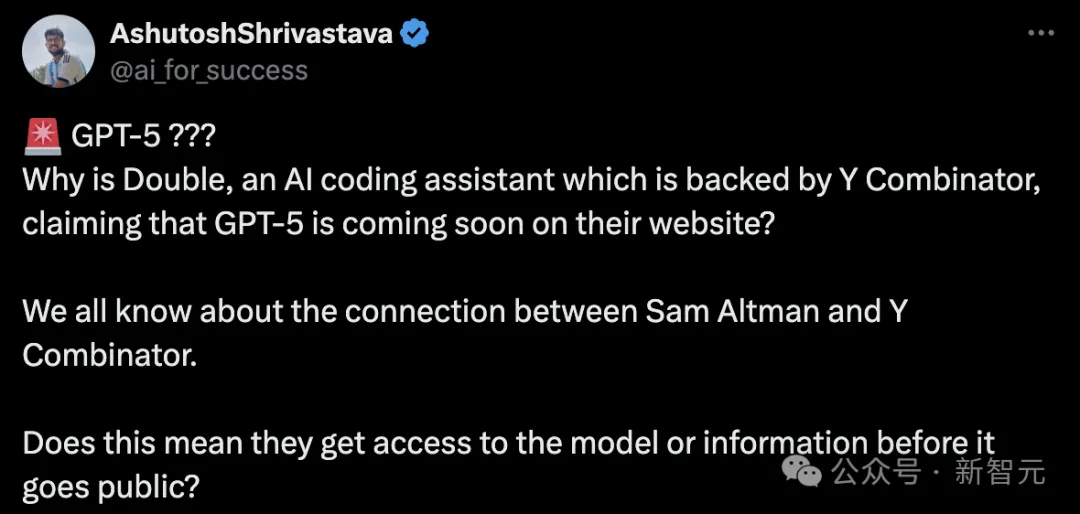
最近,网上流传的一张图上,显示了Y Combinator推出了GPT-5早期准入候补名单。

网友发起疑问,我们都清楚奥特曼和YC的关系不同寻常。这是否意味着他们可以在模型或信息公开之前获得访问权限?
而上月也有爆料称,已有用户对GPT-5上手体验过了,性能惊人。

外媒透露,一些企业用户已经体验到了最新版的ChatGPT。
「它真的很棒,有了质的飞跃,」一位最近见识到GPT-5效果的CEO表示。
OpenAI展示了,新模型是如何根据这位CEO公司的特殊需求和数据进行工作的。
他还提到,OpenAI还暗示模型还有其他一些未公开的功能,包括调用OpenAI正在开发的AI智能体来自主完成任务的能力。
不过,在万众瞩目期待GPT-5面世的呼声中,也有一些不一样的声音。
比如有人觉得,GPT-5无法驾驶你的汽车,GPT-5无法解决核聚变问题,GPT-5无法治愈癌症......

另外,我们对模型的追求,非得是更智能吗?
更便宜、更快、更不费水电的模型,可能比单独的GPT-5更有革命性意义。

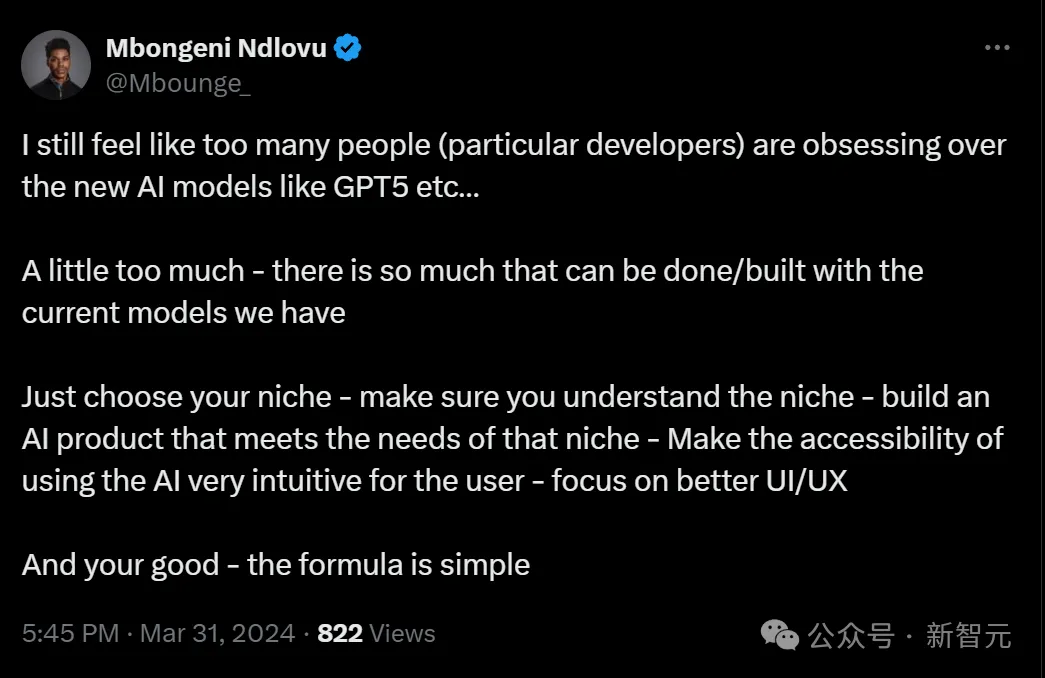
有人同意这个观点,表示现在实在有太多人(尤其是开发者)过于痴迷GPT-5了。
其实完全没必要这么狂热,使用当前的模型,就可以已经完成和构建太多东西。
只需正确选择利基市场,构建满足该利基市场需求的AI产品,让用户可以直观地访问AI,专注于更好的UI/UX即可。
公式很简单。我们真的有必要一味追求力大砖飞吗?
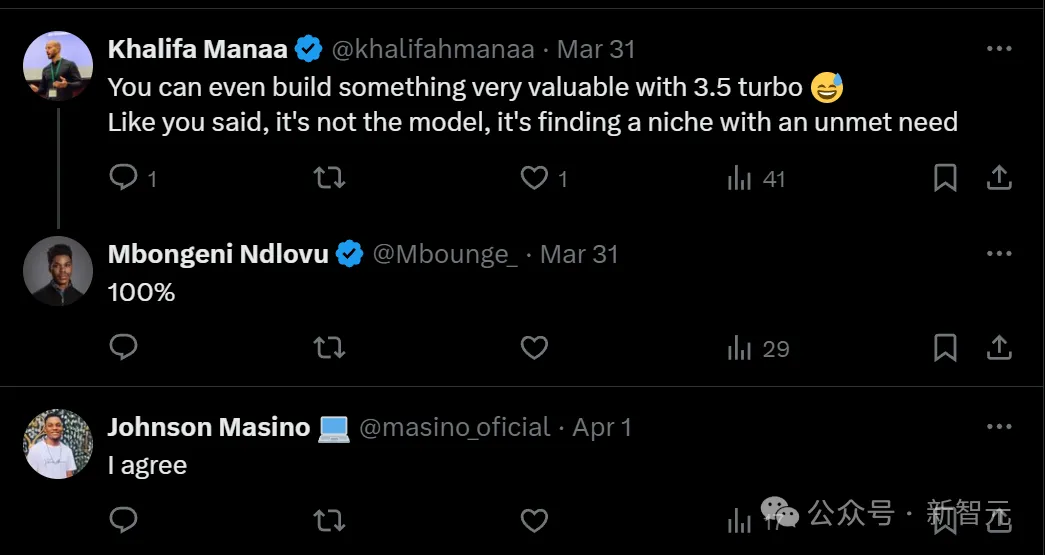
很多人表示赞同,表示甚至用GPT-3.5就可以造出非常有价值的东西。
问题不在于模型多先进,而在于怎样满足利基市场的需求。
而3月底曝出的用于训练GPT-6的千亿美元「星际之门」超算,今天又被外媒挖出了更多新的内容。
上周五,外媒The Information曝出了一个惊人消息:OpenAI和微软正在制定一项雄心勃勃的数据中心项目,预计耗资1000亿美元。

此消息一曝出,AI和云计算行业人士的提问,像雪片一样袭来——
数据中心具体位于美国的哪个地区?
会使用什么芯片?
运行数据中心所需的惊人巨量电力,从何而来?
……
为此,The Information又挖出了更多料,具体细节如下。
首先,之前的消息说是星际之门最早在2028年启动,而最新消息显示,最快在2026年,就会在威斯康星州启动一个功率较小的数据中心。
它的价值当然不到千亿美元,但估计仍会耗资数十亿。
其他细节如下——
首先,这次数据中心的多数服务器机架,当然主要还是用的英伟达芯片。
不过有趣的是,将各个AI芯片服务器连接起来的网线,则并不会采用英伟达的产品。
据悉,OpenAI已经告知微软,自己不想再使用英伟达的InfiniBand网络设备。相反,它可能会使用基于以太网的电缆。

OpenAI「抛弃」英伟达InfiniBand,原因有二。
其一,InfiniBand太贵了!
它虽然能提供更好的性能,但它也比以太网电缆更昂贵。
其二,OpenAI不想让AI开发人员过于依赖英伟达。
要知道,目前OpenAI是全球最大的英伟达服务器集群消费者之一。并且,InifiniBand设备的性能,有时也并不可靠。
所以,英伟达会失去一大笔收入吗?
不,你想多了。
节省下来数十亿美元,OpenAI会用来购买更多的英伟达芯片,英伟达依然赚翻了。
看来,OpenAI可以接受网络性能的降低,但对于更强算力的渴望,仍然是不变的。
其实,在最近硅谷的会议和晚宴上,InfiniBand和以太网的pk,一直是个大热门话题。
所有云提供商和数据中心运营商都在预测:以太网是否会赶超InfiniBand?
绝大多数人给出的答案是肯定的。
而OpenAI放弃后者的举动,更是支持了这个论点。
英伟达的电缆到底有多贵?
这个数字说出来,十分惊人——
英伟达的网络电缆销售额,已经超过了卖GPU的钱!
英伟达首席财务官Collete Kress今年2月透露了这一惊人数据:新兴的电缆业务的年化收入,已经超过了130亿美元。
也就是说,它在12月创造了约11亿美元的收入,约占英伟达当月总收入的15%。
网络电缆卖这么贵,难怪OpenAI会选择不玩了。
参考资料:
https://www.reddit.com/r/singularity/comments/1bv8m4k/gpt5_red_teaming_underway/
https://www.theinformation.com/articles/openai-moves-to-lessen-reliance-on-some-nvidia-hardware
文章来自微信公众号“新智元”,作者:新智元




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
