# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天起,最新版的GPT-4 Turbo,正式向ChatGPT Plus用户开放了!

有了GPT-4 Turbo加持后,ChatGPT写作、数学、逻辑推理和编码的能力得到提升。
小编小试,果然ChatGPT最新数据已经更新到了4月。
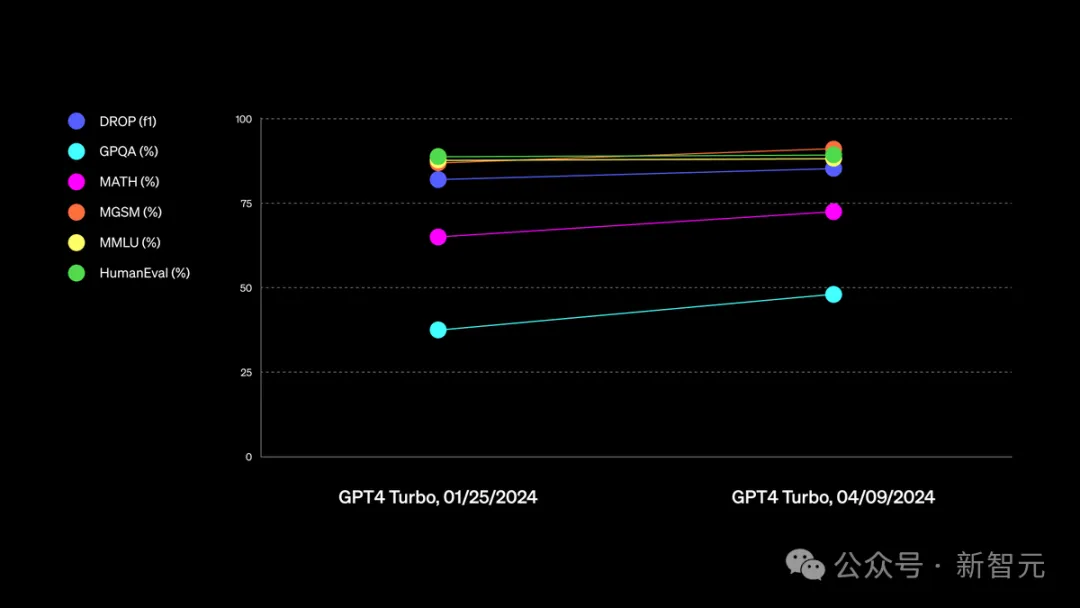
根据基准测试结果,GPT-4 Turbo在数学能力比上一代有了明显改进。
这也就不难理解,新版的GPT-4 Turbo今天再次登顶大模型排行榜。

就连奥特曼本人表示,「GPT-4现在更加智能,使用起来也更舒适」。

另外,据OpenAI介绍,GPT-4 Turbo在回复时,变得更直接、减少啰嗦内容,更加口语化。
一起看看,GPT-4 Turbo在基准测试中能力如何?
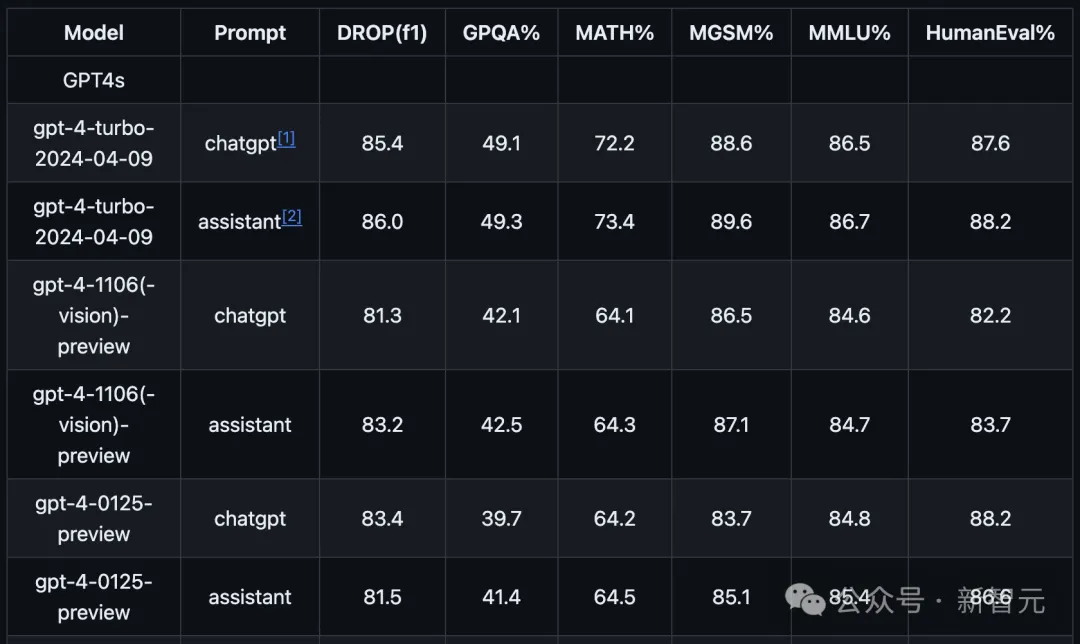
在官方公开GitHub上,OpenAI放出了gpt-4-turbo-2024-04-09最新的评估结果。
主要在以下七大基准上,对模型完成了评估:
在这个GitHub库中,OpenAI主要使用零样本、CoT设置,并采用简单的指令,如「解决以下多项选择题」。
这种提示方式更能真实反映模型在实际使用中的表现。
具体结果如下所示:
最新的gpt-4-turbo比以往的GPT-4系列,在性能上有着明显的提升。
尤其数学方面,能力实现了近10%的跃阶。
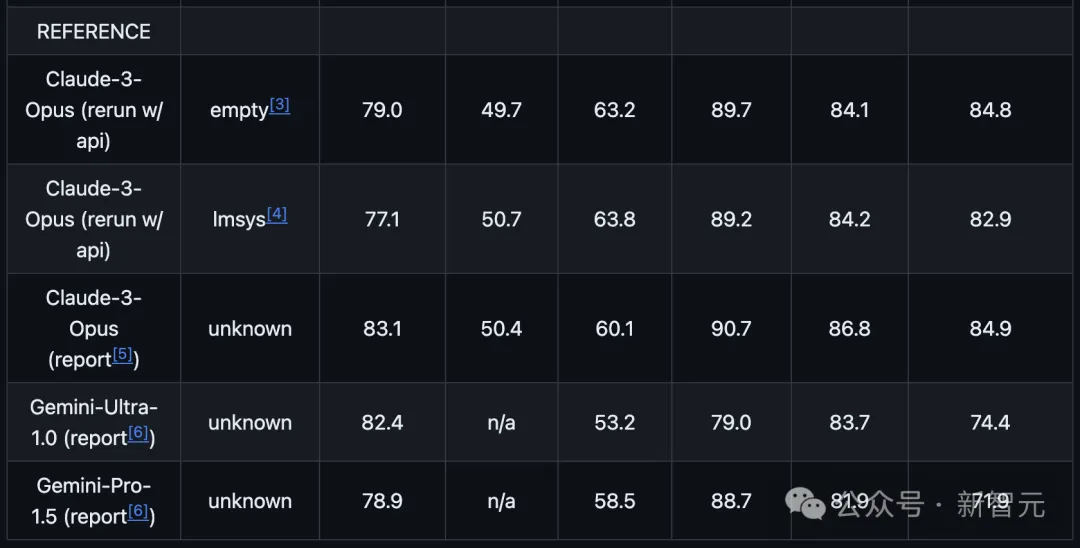
而在整体的比较中,新模型也基本上实现了对Claude 3 Opus和Gemini Pro 1.5的全面超越。
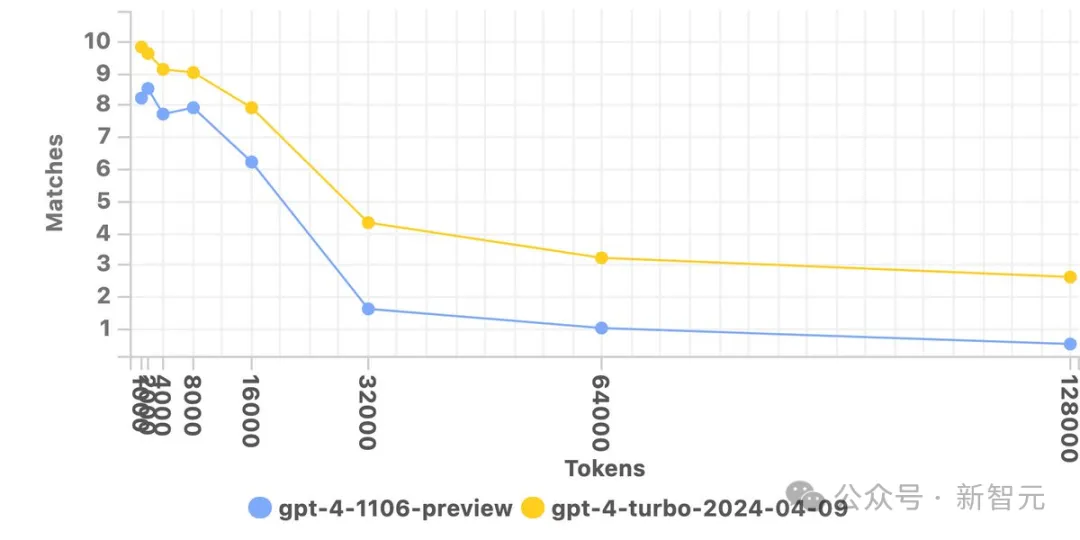
同样的,在大海捞针测试中,最新的gpt-4-turbo也是全方位地超越了此前的1106-preview。
众所周知,上下文越长,对模型的挑战就越大。
而gpt-4-turbo可以在处理长达64k Token的内容时,性能直接媲美预览版在26k Token时的表现。
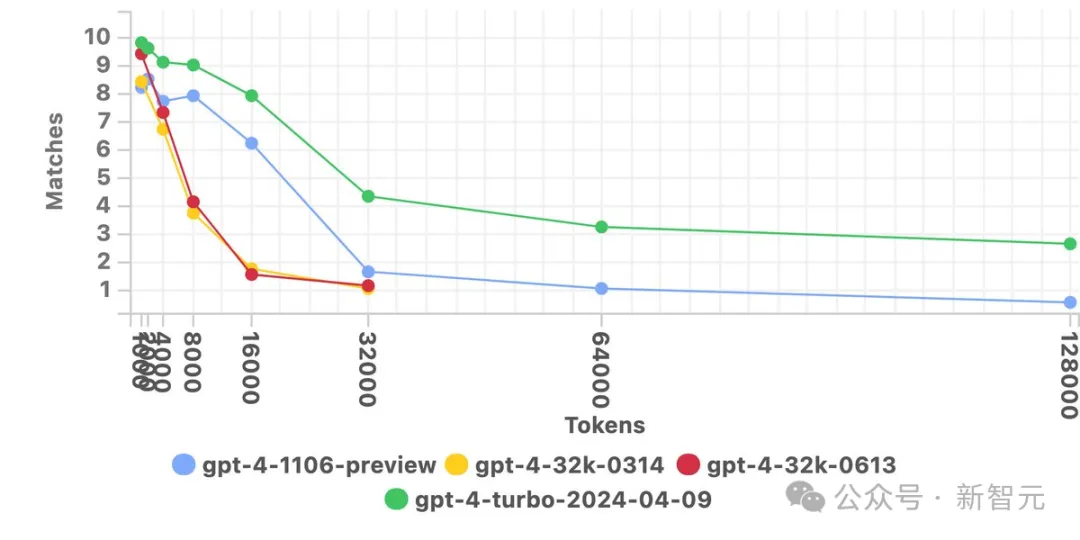
如果我们回顾一下GPT-4刚发布时的情况,也就是大约一年之前。
最新的gpt-4-turbo在32k的配置下,性能比初代GPT-4提高了约4.3倍。
顺便一提,那个时候,模型能处理的上下文最高只到32k。
前段时间,Anthropic手里的最强大模型Claude 3 Opus,可以说是霸榜各大榜单。
不过,就在今天,OpenAI凭借着全新的gpt-4-turbo,又把它从「榜一」的位置上拉了下来。
根据「LLM排位赛」最新的结果,GPT-4-Turbo再次超越Claude 3,夺得第一。
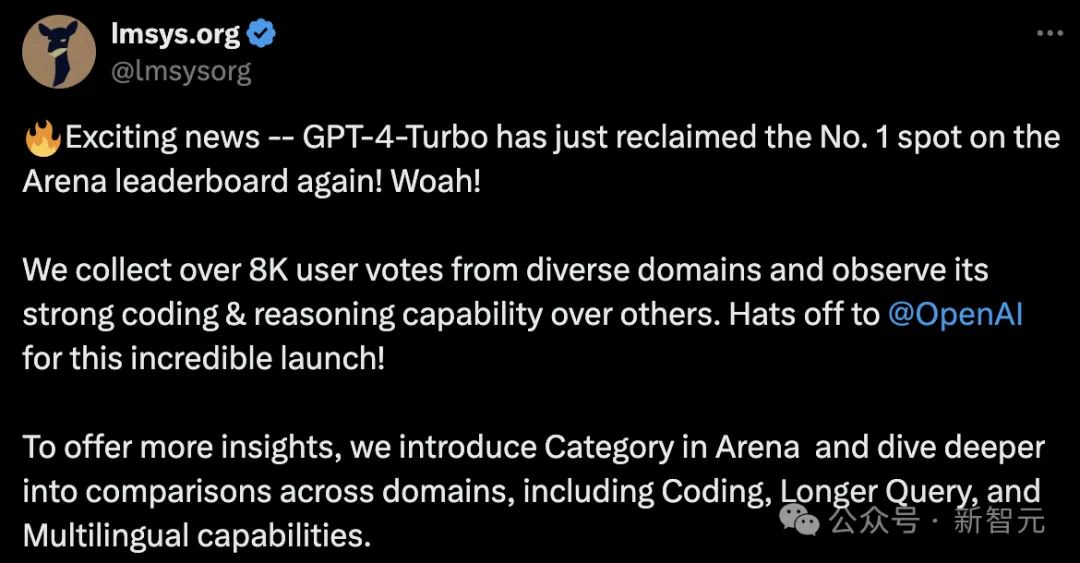
LMSYS Org从多个领域收集了超过8000张人类投票,发现GPT-4-Turbo在编程与推理方面的表现,超越了其他模型。
为了深入了解,研究人员在Arena引入了「类别」功能。
通过这一新功能,可以对编程、长查询处理和多语言能力等不同领域进行了更详尽的比较。
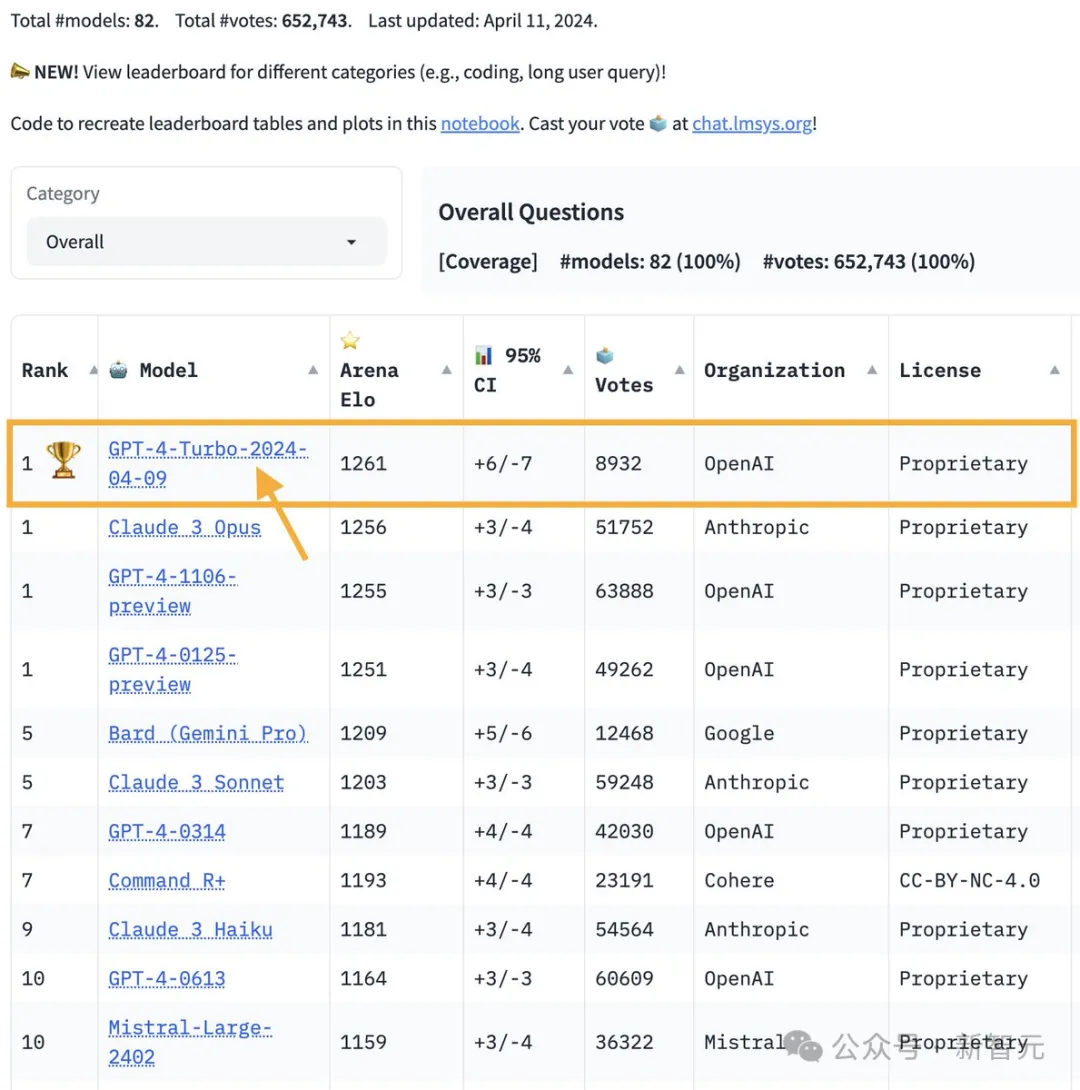
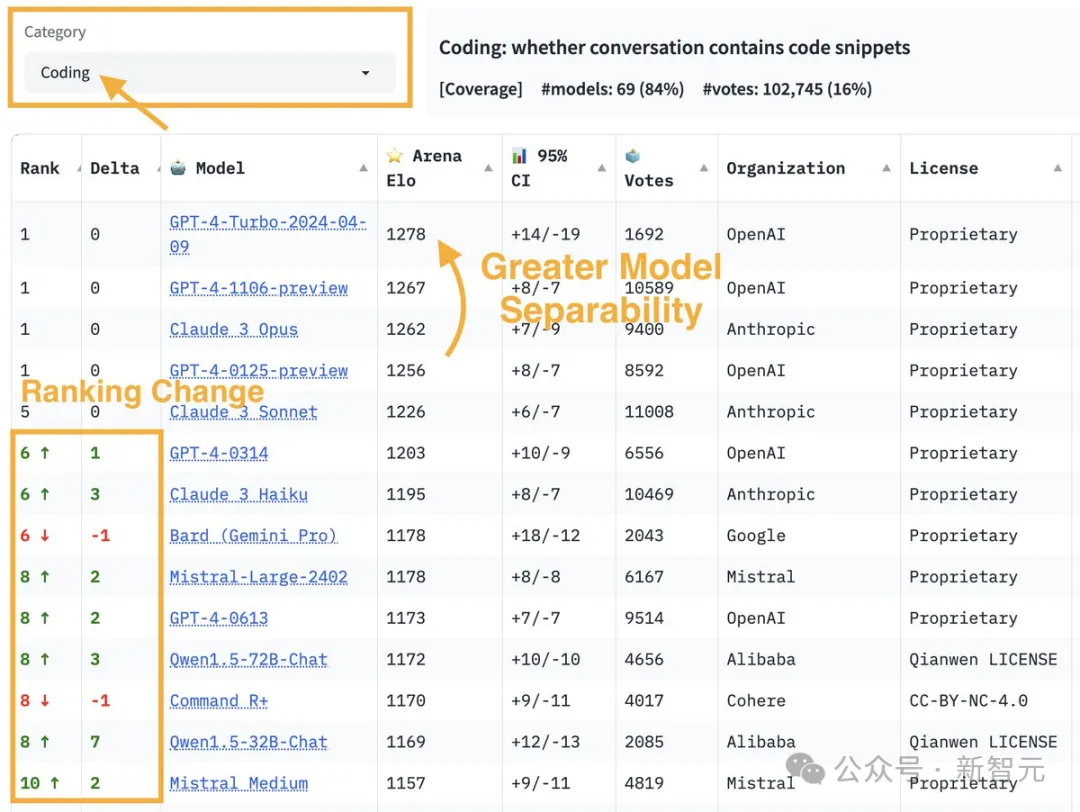
研究人员还对编程领域中包含代码片段的所有对话进行了标记。在这一方面,GPT-4-Turbo展现出更强的性能。
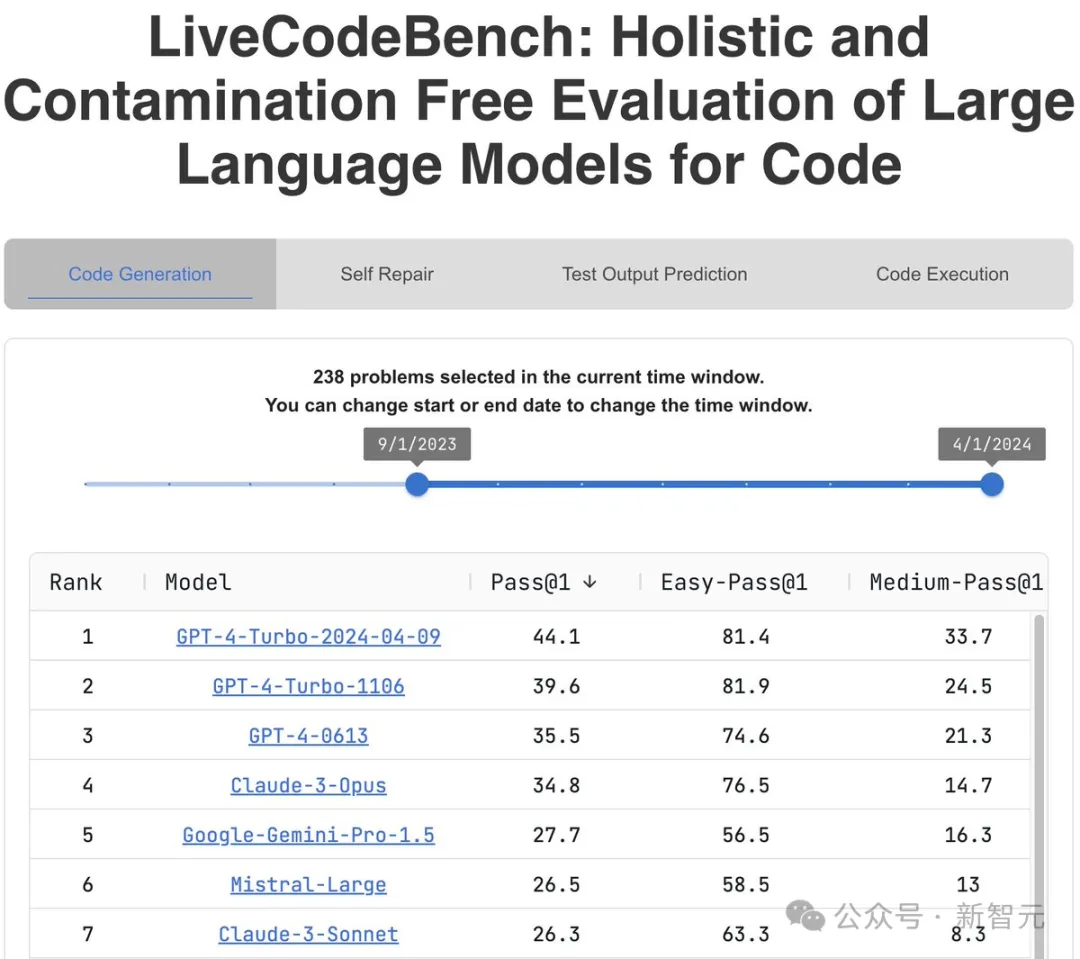
类似的,Naman Jain也发现,新版GPT-4-Turbo在LiveCodeBench(包含编程竞赛题)上的表现,提高了惊人的4.5分。
这类问题对目前的LLM来说挑战很大,而OpenAI此次的更新,明显是大幅提升了模型推理能力。
在长查询领域(Token数量超过500),Claude-3 Opus表现最佳。
令人有些意想不到的是,Command R/R+在这一领域中也有着非常高的得分。
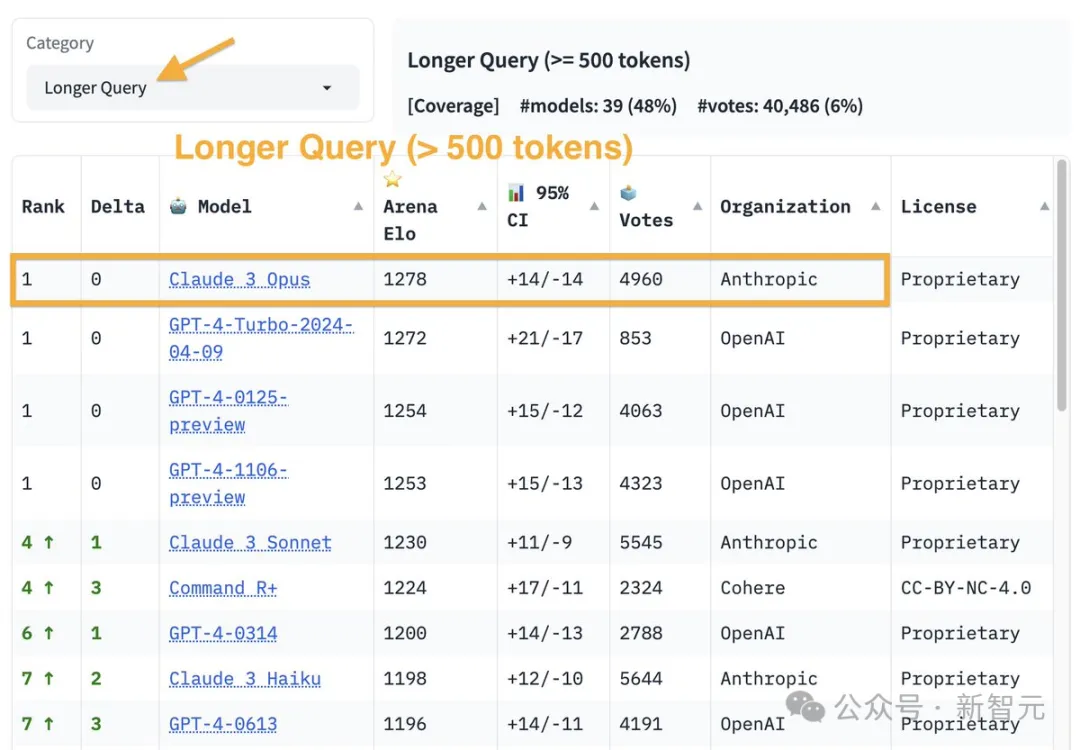

有趣的是,如果只涉及英语提示,排名会与整体略有不同。
在这一类别中,三种GPT-4-Turbo依然处于领先地位。
而这种变化的产生,是因为随着用户基数的扩大,语言使用从英语转向包括中文在内的多种语言。
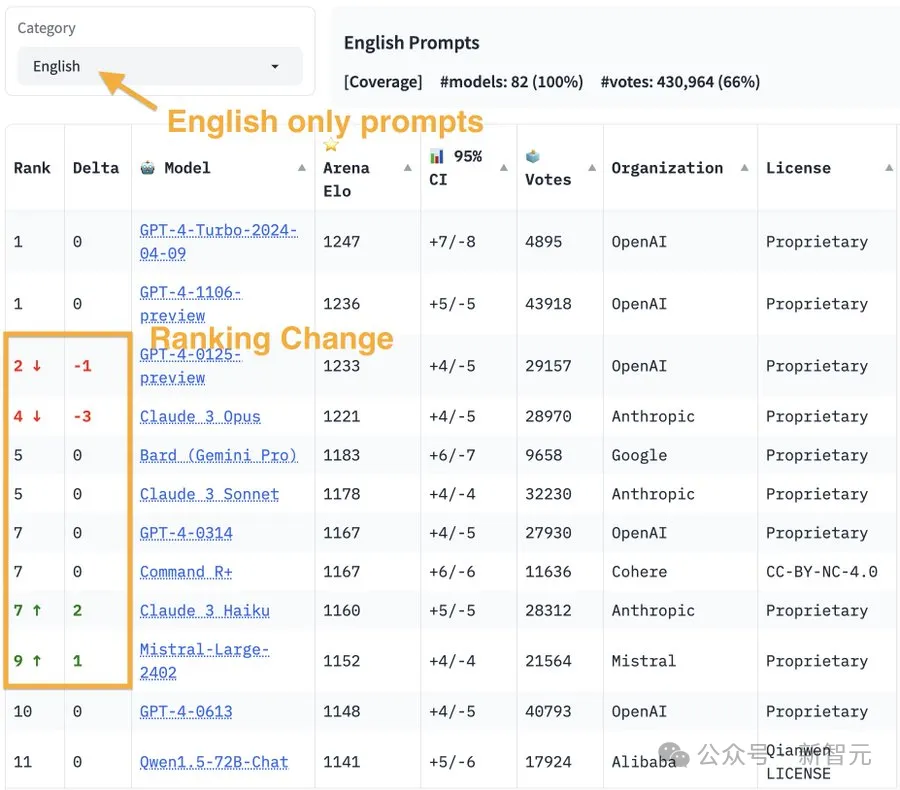
而在应对不同的语言时,模型的表现也有所差异。
例如,在中文环境中,Claude-3 Opus排名第一。
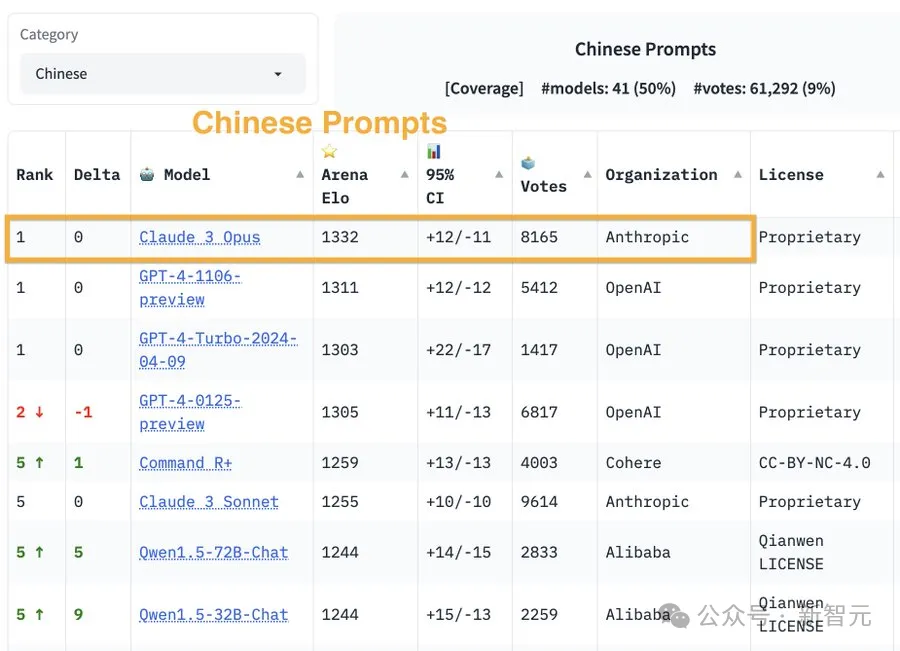
以下是模型评分的置信区间 (CIs) :

以及整体的胜率热图:

参考资料:
https://twitter.com/OpenAI/status/1778574613813006610
https://twitter.com/lmsysorg/status/1778555678174663100
文章来自微信公众号“新智元”,作者:桃子 好困




