# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
让我们来具体感受一下,百度智能体的思考过程。
在文心大模型4.0工具版上,我们可以这样提问——
「我要到大湾区出差一周。想了解一下天气变化,好决定带什么衣服。请帮我查一下未来一周北京和深圳的温度,告诉我出差应该带什么衣服,并整理成表格。」
接下来,它就会展示真正的技术了。
首先,它会调用一个「高级联网」工具,来查询当地的天气信息。
此外,王海峰在现场还分享了「多模型」技术。
如今,我们为什么需要多模型?
在推进大模型应用落地的过程中,开发者、企业不仅需要关注成本,还需要顾及效果和效率。
因此,在实际应用中,就需要从落地场景出发,去选择最适合自己的模型。
一方面,高效低成本的模型生产亟待解决。
对此,百度研制了大小模型协同的训练机制,可以有效进行知识继承,高效生产高质量小模型。
小模型不仅推理成本低,响应速度快。而且在一些特定场景中,经过微调后的小模型,效果可以媲美大模型。
它也可以利用小模型实现对比增强,帮助大模型完成训练。
与此同时,百度还建设了种子模型矩阵,数据提质与增强机制,以及一系列配套工具链,从预训练、精调对齐、模型压缩到推理部署。
这样一来,高效低成本的模型生产机制,可以加速应用,降低部署成本,取得更优的效果。
我们最常见的MoE便是「多模型」技术的典型代表。
可以看到,不论是GPT-4(据猜测),还是开源Grok、Mistral都采用了MoE架构。
它们都在基准测试中,取得了优异的表现。
百度认为,未来大型的AI原生应用基本都是MoE架构。通过大小模型的混用,而非单一模型去解决问题。
因此,针对场景匹配,什么时候调用大模型,什么时候调用小模型,都需要技术考量。
另一方面,是多模型推理。
百度研制了基于反馈学习的端到端多模型推理技术,构建了智能路由模型,进行端到端反馈学习,充分发挥不同模型处理不同任务的能力,达到效果、效率和成本的最佳平衡。
正如Robin会上所言,通过强大的文心4.0裁剪出更小尺寸的模型,要比直接拿开源模型,微调出来的效果要好得多。
这段时间,一张开源模型与闭源模型之间的差距不断拉近的图,在全网疯转。
许多人乐观地认为,开源模型很快突破极限,取得逼近GPT-4,甚至替代闭源模型的能力。
实则不然,开源模型并非拿来即用,而需要更多定制化的微调。
这也是百度发布了ERNIE Speed、Lite、Tiny三个轻量模型的原因。
通过文心大模型4.0,压缩蒸馏出一个基础模型,然后再用专门数据训练。这要比基于开源模型,甚至重训一个模型效果好得多。
文心4.0性能提升52.5%
除了上述这些之外,文心4.0的创新还包括基于模型反馈闭环的数据体系、基于自反馈增强的大模型对齐技术,以及多模态技术等等。
整个过程中,它展现出了娴熟的思考和规划能力,有条不紊地把用户需求拆解成多个子任务,一整套过程行云流水。
不仅如此,从万亿级的训练数据中,文心大模型学到的,除了自然语言能力外,还有代码能力。
顾名思义,这个智能体,能够帮我们写代码。
程序员和普通人的之间的壁垒,从此彻底打破,以前程序员才能做的事,现在人人都能做。
代码智能体,是由思考模型和代码解释器两个部分组成。
首先,思考模型会先理解我们的需求,经过一番思考后,把完成任务的指令和相关信息整合成提示,输入给代码解释器。
发布后的半年时间,文心4.0的性能又提升了52.5%。
文心大模型之所以能如此快速持续地进化,离不开百度在芯片、框架、模型和应用上的全栈布局,尤其是飞桨深度学习平台和文心的联合优化。文心大模型的周均训练有效率达到98.8%。
相比而言,一年前文心一言发布时,训练效率直接提升到了当时的5.1倍,推理则达到了105倍。
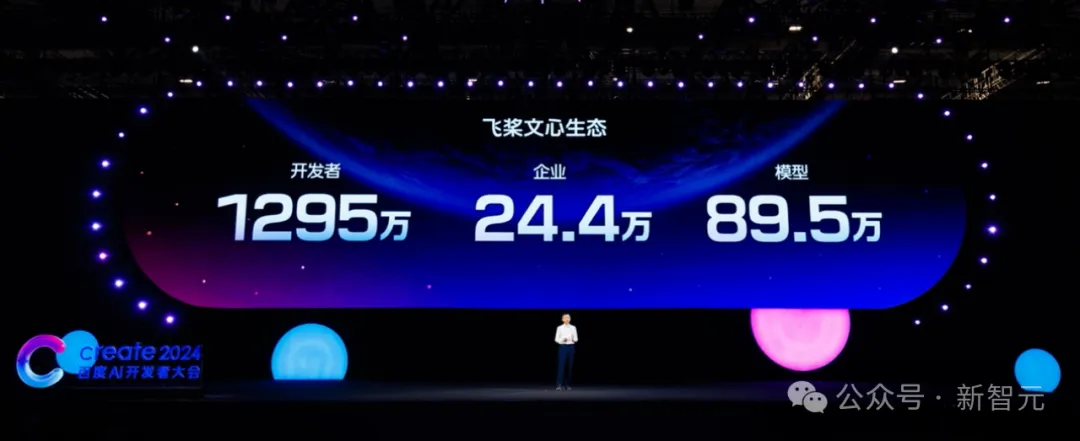
截至目前,飞桨文心生态已经凝聚了1295万开发者,服务了24.4万家企事业单位。基于飞桨和文心,已经有89.5万个模型被创建出来。
如今,文心一言累计的用户规模已达2亿,日均调用量也达到了2亿。
这2亿用户的工作、生活和学习,已经被文心一言改变。

文章来自微信公众号“新智元”,作者:新智元编辑部




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
