# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Meta 于本周四正式发布 Llama 3,官方号称「有史以来最强大的开源大模型」。
本次发布了 8B 和 70B 参数的大模型,提供了新功能,改进了推理能力,在行业基准测试上展示了最先进的性能。8B 参数评测结果碾压 Gemma-7B、Mistral-7B 版本;而 Llama 3 70B 版本评测结果同样也在诸多成绩上超过了 Gemini 1.5 Pro 和 Claude 3 Sonnet。
在接下来的几个月里,Meta 计划推出新功能、更长的上下文窗口、额外的模型尺寸和增强的性能,并且将分享 Llama 3 的研究论文。
之前预告的 Meta AI 也正式发布,将在 Meta 多款应用程序中整合,这些应用程序包括 Instagram、WhatsApp、Messenger 和 Facebook。这项技术将在包括澳大利亚、加拿大、新加坡和美国在内的十几个国家推出。网页版 Meta.ai 同步上线。
Llama 3 很快将在 AWS、Databricks、Google Cloud、Hugging Face、Kaggle、IBM WatsonX、Microsoft Azure、NVIDIA NIM 和 Snowflake 上推出,并得到 AMD、AWS、Dell、Intel、NVIDIA 和 Qualcomm 提供的硬件平台的支持。
文章基于 Meta 官方 Blog 整理,Founder Park 有增删。
Llama 3 模型,拥有 8B(80 亿)和 70B(700 亿)参数,相较于 Llama 2 模型取得了显著进步,并在相应参数规模的大型语言模型领域刷新了性能纪录。得益于预训练和后续训练阶段的技术提升,Llama 3 无论是在预训练还是在指令微调后,都成为了目前业界在这些参数级别上表现最为出色的模型。后训练流程的优化显著降低了误拒率,增强了模型的一致性,并丰富了模型的响应多样性。此外,Llama 3 在推理、代码生成和遵循指令等方面的能力也有了显著提升,使其更加灵活易用。
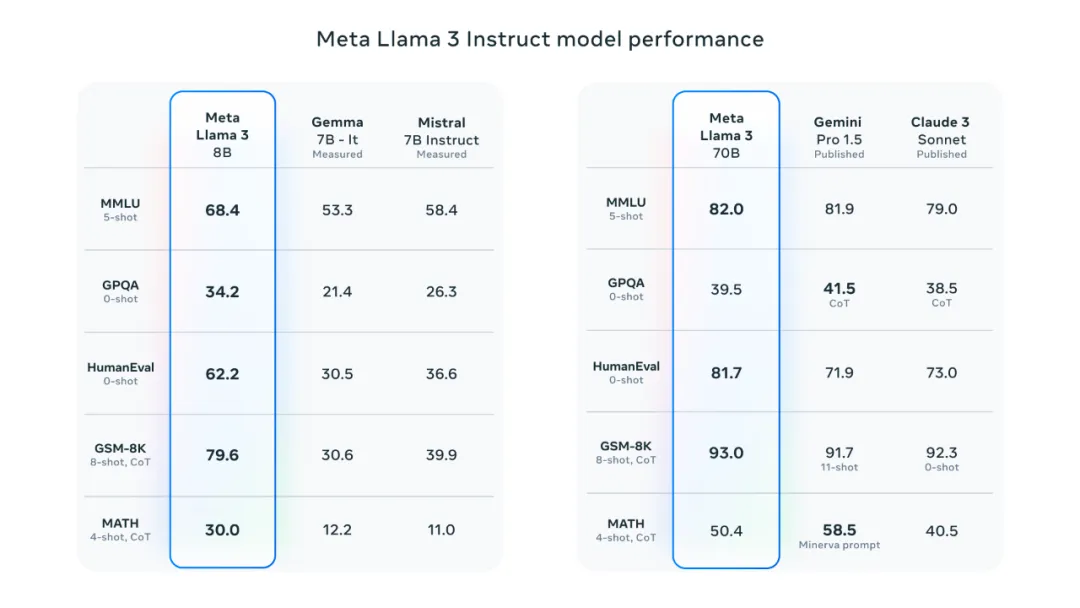
详细评测细节:https://github.com/meta-llama/llama3/blob/main/eval_details.md
在 Llama 3 的研发过程中,不仅关注了模型在标准化测试中的性能,还特别注重提升模型在现实应用场景下的表现。为此,Meta 精心设计了一套全新的、高质量的人类评估标准。这套评估标准包含了 1800 个测试项,覆盖了 12 个主要的应用场景,包括寻求建议、集思广益、分类、回答封闭式问题、编程、创意写作、信息抽取、角色扮演、回答开放式问题、逻辑推理、内容改写和文摘总结等。
为了避免模型在这一评估标准上出现意外的过拟合现象,甚至限制了包括建模团队在内的所有团队对该评估集的访问权限。下图展示了我们在这些不同类别和测试项上的人类评估结果的汇总,并列出了与 Claude Sonnet、Mistral Medium 以及 GPT-3.5 模型的对比情况。
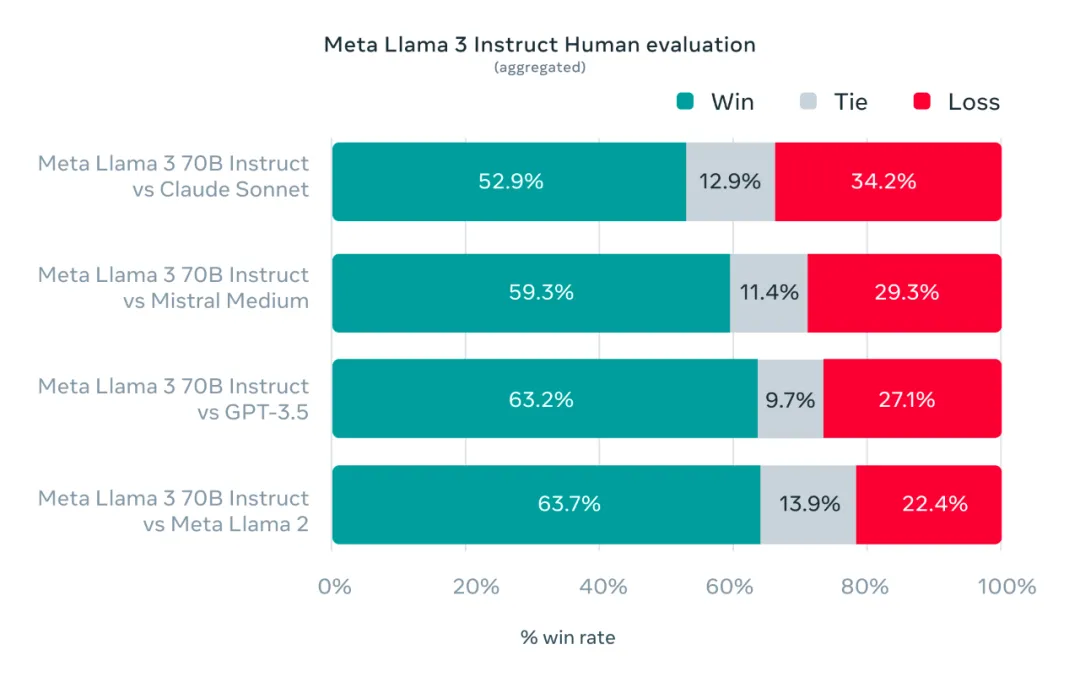
基于这套评估集,我们 70B 参数的指令遵循模型在现实世界的应用场景中,相较于其他相似规模的竞争对手模型,展现出了卓越的性能。
我们的预训练模型也在同等规模的 LLM 模型中树立了新的行业标准。
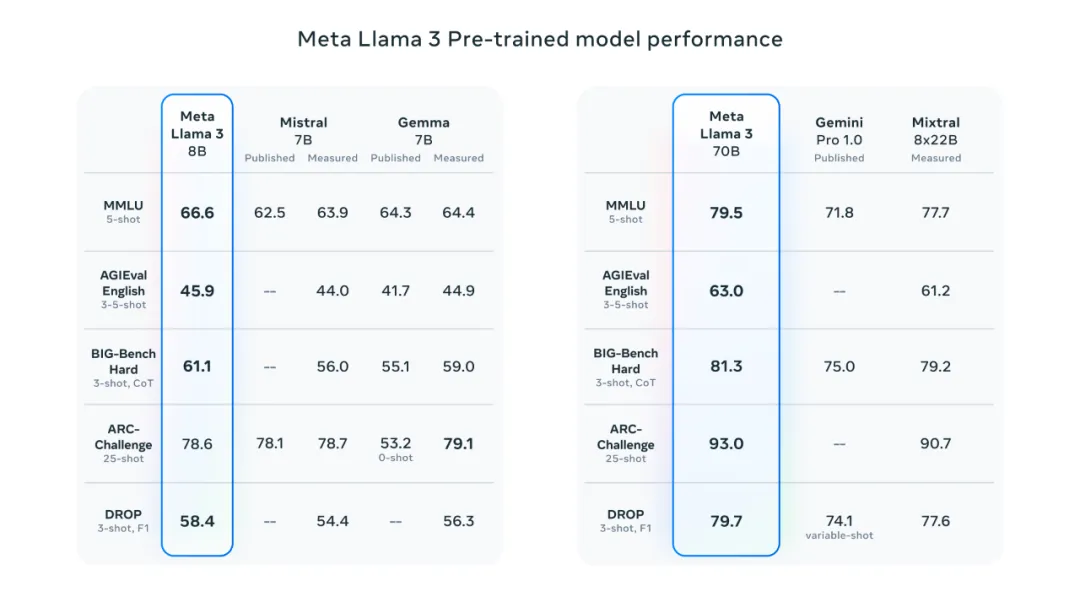
详细评测细节:https://github.com/meta-llama/llama3/blob/main/eval_details.md
要打造出一款优秀的语言模型,关键在于创新思维、扩大规模以及追求简洁的优化。在 Llama 3 的研发过程中,我们始终贯穿了这一设计理念,并集中精力在四个核心要素上:模型架构的创新、预训练数据的选择、预训练过程的扩展,以及对模型进行指令微调的精细打磨。
在 Llama 3 的模型设计中,我们遵循了简化而高效的设计理念,选择了一个标准的仅解码器的 Transformer 架构。与前一代 Llama 2 相比,我们在几个关键方面进行了改进。Llama 3 采用了一个拥有 128K token 的分词器,这种分词器在编码语言时更加高效,这使得模型的性能得到了显著提升。为了进一步提升 Llama 3 模型在推理过程中的效率,我们在 8B 和 70B 规模的模型中都实施了分组查询注意力(GQA)技术。在训练过程中,我们让模型处理最多 8,192 个 Token 的序列,并巧妙地使用掩码技术来确保模型的自注意力机制不会跨越不同文档的界限,从而保证了模型的准确性和效率。
为了训练最好的语言模型,构建一个庞大且高质量的训练数据集是关键所在。本着我们的设计理念,我们在预训练数据上投入了大量资源。Llama 3 的预训练基于超过 15T 的 Token,这些 Token 全部来源于公开可获取的数据。与 Llama 2 相比,我们的训练集规模扩大了七倍,代码数据量也增加了四倍。为了适应即将到来的多语言场景需求,Llama 3 的预训练数据中超过 5% 是非英语的高质量数据,覆盖了超过 30 种语言。尽管如此,我们预计这些语言的性能表现会弱于英语。
为了保障 Llama 3 能够在最优质的数据上进行训练,我们设计并实施了一系列先进的数据过滤流程。这些流程包括应用启发式过滤器、NSFW 内容过滤、语义去重技术和文本质量分类器等,用以预判数据的优劣。我们意外发现,Llama 系列的前代产品在筛选优质数据上表现出奇地高效,因此我们利用 Llama 2 来生成用于 Llama 3 的文本质量分类器的训练集。
此外,我们开展了大量的实验,旨在寻找将不同来源的数据以最佳方式混合的策略,以构建我们的最终预训练数据集。这些实验帮助我们确定了一种数据组合,使得 Llama 3 能够在包括智力问答、STEM、编程、历史知识等多个应用场景中均有出色的表现。
为了让 Llama 3 充分吸收和利用我们的预训练数据,我们在扩大预训练规模上做了大量工作。具体而言,我们为后续的性能基准测试制定了一套详尽的 Scaling Laws。这套法则帮助我们精选出最佳的数据处理方案,并指导我们如何最高效地使用我们的计算资源。更重要的是,这些 scaling laws 让我们能在模型训练之前,就预测出在关键任务(比如 HumanEval 基准测试中的代码生成任务)上的最大模型性能。这样的预测能力确保了我们的最终模型在多样化的应用场景和能力上都能有出色的表现。
在开发 Llama 3 的过程中,我们对模型规模的效应有了新的发现。例如,对于一个 8B 参数的模型,Chinchilla 模型建议的训练计算量大约是 200B 个 Token,但我们的研究发现,即使在模型处理了比这个量大两个数量级的数据之后,性能仍在提升。无论是 8B 还是 70B 参数的模型,当我们将训练数据量提升到 15T 个 Token 时,它们的性能都还在以对数线性的方式提升。虽然大型模型在较少的计算资源下就能达到小型模型的性能,但由于推理阶段的高效率,小型模型通常更受青睐。
为了训练我们最大规格的 Llama 3 模型,我们采用了三种并行化技术:数据并行、模型并行和流水线并行。在 16K 个 GPU 上同时训练时,我们的最高效实现方式能够达到每个 GPU 超过 400 TFLOPS 的计算利用率。我们还特别构建了两个 24K GPU 的集群来进行模型训练。
为了提高 GPU 的使用效率,我们开发了一套先进的训练栈,它能够自动进行错误检测、处理和维护。此外,我们还大大提升了硬件的可靠性,改进了静默数据损坏的检测机制,并研发了新的可扩展存储系统,以降低检查点和回滚操作的开销。这些创新使得我们的训练效率达到了 95% 以上。总的来说,与 Llama 2 相比,Llama 3 的训练效率提升了大约三倍。
为了使我们的预训练模型在聊天应用场景中发挥最大效能,我们对指令微调方法(instruction-tuning)进行了创新性的改进。我们的后训练策略融合了监督式微调(SFT)、拒绝抽样、近端策略优化(PPO)和直接策略优化(DPO)等多种技术。在 SFT 中使用的提示质量以及 PPO 和 DPO 中使用的偏好排名对于提升模型的性能至关重要。通过对这些数据进行精细筛选和对人类标注者提供的内容进行多轮质量审核,我们实现了模型质量的重大提升。
利用 PPO 和 DPO 技术从偏好排名中学习,也极大提升了 Llama 3 在逻辑推理和编程任务上的表现。我们发现,当模型面对一个难以回答的推理问题时,它有时能够生成正确的推理过程:模型知道如何得出正确答案,但却不知道如何确定这个答案。通过偏好排名的训练,模型学会了如何选择正确的答案。
Llama 3 很快将在所有主要平台上推出,包括云服务提供商、模型 API 提供商等
我们的基准测试显示,Tokenizer 提供了改进的 Token 效率,与 Llama 2 相比,Token 数量减少了高达 15%。此外,分组查询注意力 (Group Query Attention, GQA) 现在也已经添加到 Llama 3 8B 中。因此,我们观察到尽管模型比 Llama 2 7B 多出 10 亿参数,但由于改进的 Tokenizer 效率和 GQA,推理效率与 Llama 2 7B 相当。
Llama 3 8B 和 70B 模型标志着我们计划为 Llama 3 发布的开始。还有更多的内容即将到来。
我们所开发的最大型模型超过 400B 参数,尽管目前这些模型仍在训练阶段,但我们的团队对它们展现出的潜力感到无比激动。在未来数月,我们计划推出一系列具备全新功能的模型,这些新功能将包括多模态、支持多语言对话、扩展上下文窗口的长度,以及全面提升的综合性能。此外,Llama 3 训练完成后,我们也将发表一篇详尽的研究论文,以分享我们的成果和发现。
为了展示这些模型在持续训练中的当前进展,我们觉得可以提供一些我们最大大语言模型(LLM)发展趋势的测试成绩。请注意,这些数据是基于仍在训练阶段的 Llama 3 模型的一个早期成绩,并且这些功能并不包含在我们今天发布的模型中。
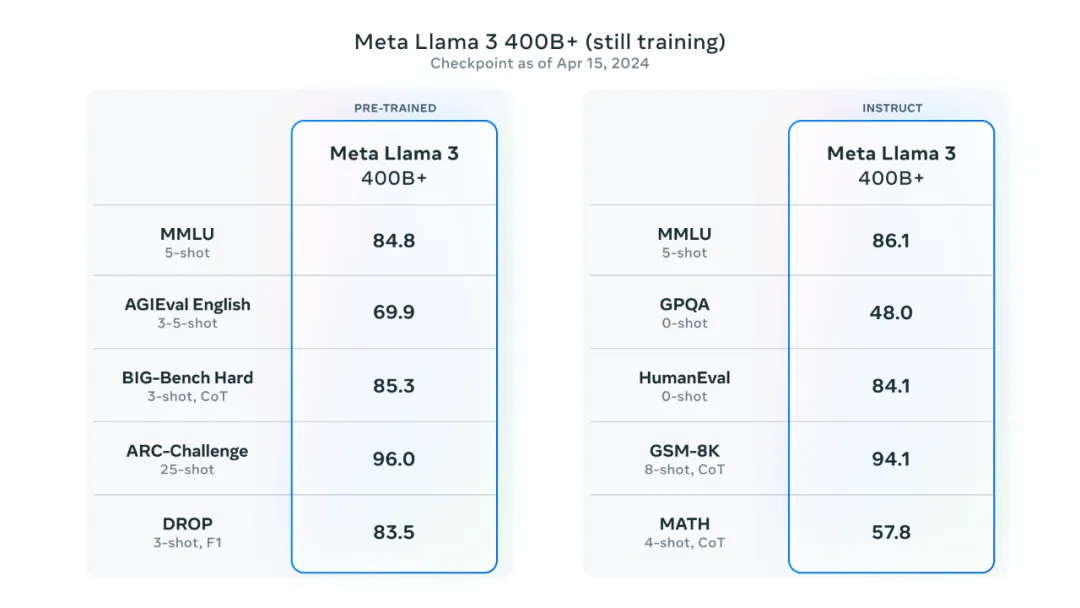
详细评测细节:https://github.com/meta-llama/llama3/blob/main/eval_details.md
我们已经将我们的最新模型集成到 Meta AI 中,我们认为这是世界上领先的 AI 助手。它现在采用 Llama 3 技术构建,并且可以在我们应用的更多国家中使用。
你可以在 Facebook、Instagram、WhatsApp 和 Messenger 上使用 Meta AI 来完成任务、学习、创造以及连接对你重要的事情。我们在去年的 Connect 大会上首次宣布了 Meta AI,现在,全世界更多的人可以以前所未有的多种方式与之互动。
我们正在美国以外的十几个国家推出英语版的 Meta AI。现在,人们可以在澳大利亚、加拿大、加纳、牙买加、马拉维、新西兰、尼日利亚、巴基斯坦、新加坡、南非、乌干达、赞比亚和津巴布韦访问 Meta AI。
网页版也同步上线:meta.ai。还可以登录以保存你与 Meta AI 的对话,以供将来参考。
想要与好友共度一个美好的夜晚?不妨向 Meta AI 求助,让它为你推荐一家既能欣赏日落又能享用美味素食的餐厅。在策划一个周末的短途旅行吗?向 Meta AI 询问,它会帮你找到周六晚上举行的音乐会。考试临近,需要临时冲刺复习?向 Meta AI 提问,它会向你阐释遗传特征的运作原理。刚刚搬进你的首个公寓,准备开始新生活?向 Meta AI 描述你想要的家居风格,它将为你的家具选购提供一些灵感图片。
Meta AI 也可以在 Facebook、Instagram、WhatsApp 和 Messenger 中搜索。你可以在不离开应用程序的情况下访问来自整个网络的实时信息。假设你正在 Messenger 小组聊天中计划一次滑雪旅行。使用 Messenger 中的搜索功能,你可以要求 Meta AI 查找从纽约到科罗拉多的航班,并找出最不拥挤的周末去——所有这些操作都无需离开 Messenger 应用程序。
当浏览 Facebook Feed 时,也可以访问 Meta AI。看到感兴趣的帖子?可以直接从帖子中要求 Meta AI 提供更多信息。所以,如果你看到一张冰岛极光的照片,你可以问 Meta AI 一年中什么时间最适合观赏北极光。
我们正在提升图像生成的速度,让用户能够通过 Meta AI 的「imagine」功能,即时根据文字描述生成图片。从今天起,这项新功能将在美国地区的 WhatsApp 和 Meta AI 的网页版上以 beta 版推出。
您在输入文字的同时,就能实时看到图像逐渐呈现——每输入几个字母,图像就会随之变化,让您亲眼见证 Meta AI 如何将您的想象变为可视的现实。
现在生成的图片质量更高、更清晰,并且更擅长在图像中融入文字。无论是专辑封面设计、婚礼指示牌、生日装饰还是服装搭配灵感,Meta AI 都能够迅速且更出色地将您的创意点子转化为生动的图像。它还会给出有用的提示和创意,帮助你对图像进行修改和迭代,让你从最初的构想出发,不断优化设计。
惊喜还不止这些。如果你发现了一张特别喜欢的图片,还可以请 Meta AI 为其添加动画效果,以新的风格重新演绎,甚至转换成 GIF 格式,方便您与朋友们分享。
本文来自微信公众号“Founder Park"




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
