# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

《DoraemonGPT: Toward Understanding Dynamic Scenes with Large Language Models》
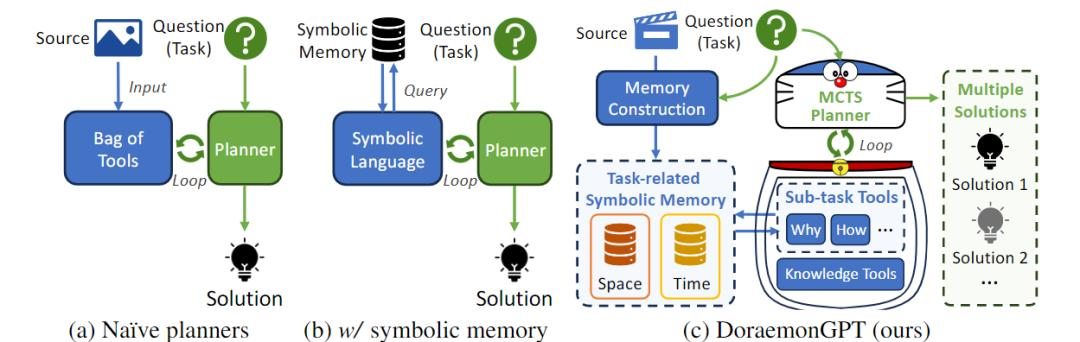
解决问题: 真实世界环境本身是动态和不断变化的,过去 LLM-based Agent 主要集中于静态图像任务解决,限制了大模型真实世界动态理解能力。DoraemonGPT 利用大小模型协同的方式大幅提升动态视频任务解决能力
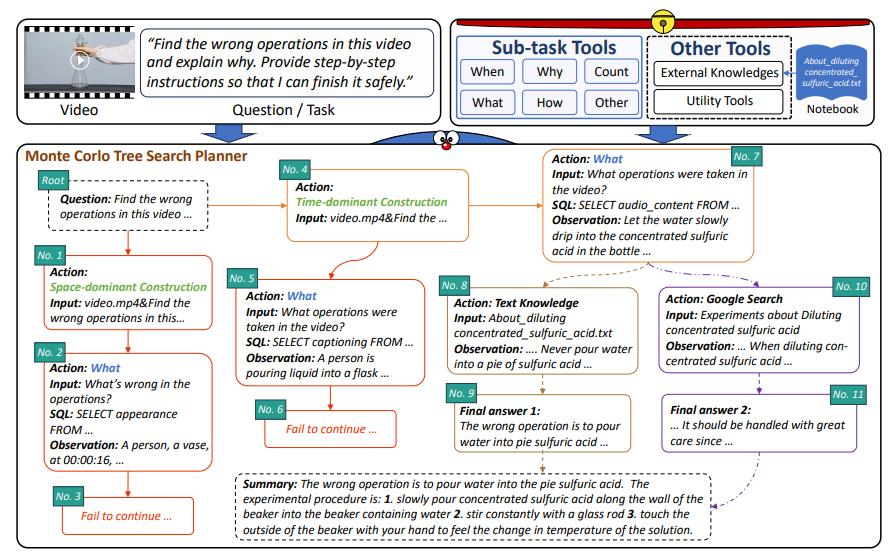
模型框架: DoraemonGPT 以 GPT-3.5 Turbo 作为模型底座,通过 VisProg 将多模态任务进行分解,提取任务相关的符号记忆,采用即插即用工具集成外部知识,以结构化的方式逐步求解。Monte Carlo Tree Search 将庞大的动态视频任务规划为一棵树,视频测试集中进行节点选择、分支扩展、链式执行、奖励反向传播循环寻找最佳解决方案
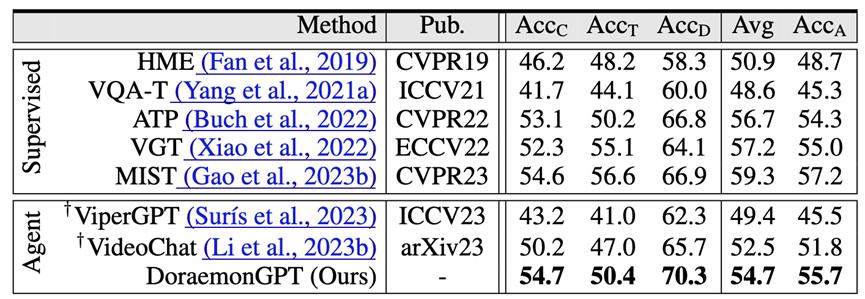
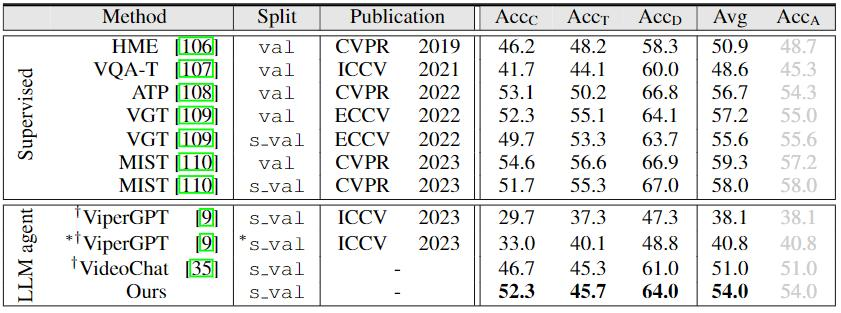
使用效果: DoraemonGPT 比 ViperGPT 和 VideoChat 分别高出 5-10% 的任务成功率,在动态视频任务解决领域取得不错效果
应用空间: 现实生活中的动态视频任务解决
测试结果: DoraemonGPT 在因果问题上超过了之前的 SOTA MIST,在四种问题类型中,比 ViperGPT 高出 11.5/9.4/8.0/5.3 (AccC/AccT/AccD/Avg),比 VideoChat 高出4.5/3.4/4.6/2.2。DoraemonGPT 在视频目标分割问题上的 Zero-shot 性能,超过了之前全监督的 SOTA OnlineRefer
绿洲:能分享一下您的研究经历么?
杨老师:我最开始研究动态视频,做视频分割相关工作,对视频中的目标物体进行像素级理解,随后在研究领域上把视频目标理解给扩展到了多模态理解,包括结合交互式理解以及实例理解。去年我们将 Meta 视觉分割大模型 SAM(Segment Anything Model)扩展到视频上,推出了 Segment-and-Track-Anything(SAM-Track)模型,短期之内收到了超过两千 Star,后续也有相关的技术报告。
绿洲:您做 DoraemonGPT 的初衷是什么?为什么叫 DoraemonGPT 呢?
杨老师: 我们之前的 SAM-Track 可以看做是一种人工设计的视频处理系统,通过手工集成多种模型,使得一个系统能解决很多单模型下难以做好的视频任务。那么能否有一种自动化的系统,不需要人工设计多模型的集成,而是自动地去调度各种基础模型呢?因此,我们团队希望进一步探索一种 Agent 方法,能自动地调度各种基础模型来解决复杂的视频和多模态问题。
说到命名,构建 Agent 时需要大小模型协同的概念去构造,大模型作为大脑去调度各种工具完成任务,就如同哆啦 A 梦从百宝袋里面拿出各种各样的工具和神奇物品来解决问题,所以我们觉得这个名字很合适(笑)。
绿洲:您一直在做视频相关的工作,对将视频生成技术推向新的高度 Sora,您怎么看呢?
杨老师: Sora 的 Demo 的确很惊艳,我们团队杨易教授(浙江大学计算机学院副院长)以及其他老师也在《中国科学报》上发表了对 Sora 的评论。
我们认为 Sora 模型延续了图像生成上的成功,它的上限是可以产生出很高质量的视频,但从 OpenAI 放出的失败案例来看,譬如生成水杯摔碎的视频:水溅错误地发生在水杯摔碎之前,这说明 Sora 无法合理生成物体物理性质变化。背后的瓶颈很明显:Sora 并不能真正理解物理规律,缺乏生成内容背后的现实知识支撑,导致在生成过程中可能会出现反常识的结果,其具体的鲁棒性尚未可知。就像图像 AIGC 生成,很容易出现手部或者肢体等结构的不协调。虽然这个痛点在逐渐缓解,但依然没有出现可以完全解决这个问题的方案。
绿洲:DoraemonGPT 与 Sora 在构建结构上是否有相似之处?
杨老师: 有相似之处,但两者不太一样。DoraemonGPT 本质上是在大语言模型(LLM)基础上构建了 Agent 智能体,是一种 Token 生成形式,自然语言在被压缩成 Token 之后基于 Transformer 进行自回归的生成。Sora 也是将视频信息压缩成 Token 来处理,但是没有采取自回归的生成形式,应该是用 Transformer 并行生成视频在时空上的所有 Token,而且 Sora 是基于扩散模型的视频生成方法,从随机噪声开始逐步去噪。总体而言,两者的不同之处在于,LLM 是自回归式生成,而 Sora 在 Transformer 里面没有用因果、注意力,是一种纯并行生成,而且是基于扩散模型的多步生成。从 OpenAI 的技术报告可以看出,整个视频所有 Token 都是同时生成的,通过位置编码来提供时空上的位置关系。
当然,要复刻 Sora 是非常有挑战的。当你有足够的算力的时候纯并行的方式肯定比自回归的逐个 Token 生成的方法效率更高,但并行的缺点就是对 GPU 显存负载要求大。另外要复刻最大的痛点还是数据,开源社区对模型结构已经有了非常多的分析,实现方式都有一定的共识,但大规模高质量数据、大规模算力以及大规模模型训练的工程实现都是核心挑战。数据、算力和工程经验才是 OpenAI 真正的门槛。
绿洲:请给我们解释一下 DoraemonGPT 的结构?
杨老师: DoraemonGPT 是三元结构,包含规划器(Planner)、工具(Tools)以及记忆(Memory)。规划器好比智能体的大脑,用于规划任务,挑选工具完成任务;工具包中的工具可以适应不同场景;记忆包括目标、任务以及手边可以拿到的信息。通俗来讲,相当于要解答复杂数学运算,做数学题的人是规划器,负责做规划,应用工具和数学书的知识解决问题;计算器、尺规、纸笔是工具;当前问题,外部书籍信息,以及我们脑中的信息相当于外部记忆。
我们认为大小模型协同会成为未来主流的方式,大模型通用性强,专业度弱,专业场景一般使用垂直小模型。但小模型鲁棒性上不去,所以我们很自然地思考如何把通用大模型和各种专业小模型(或专业领域知识)结合,DoraemonGPT 就是这样一种协同的工作。它的 Agent 系统分三部分,首先是大模型,其次有大量专属任务鲁棒性高的小模型,以及大模型外界知识库或知识图谱弥补专业能力的不足。如果这三者能有机结合,那可以逐渐迈向通用人工智能。
绿洲:我们关注到 DoraemonGPT 创新的时间与空间标注,能否解释一下具体实现方式?
杨老师: DoraemonGPT 主要针对动态场景或视频,视频有大量视频帧。比如拍摄一个街道场景,其中有大量树、车和人,人又有不同的动作,信息量巨大。从任务角度出发,比如自动场景中的监控摄像头更想关注的是行人轨迹,只关心行人有没有可能突然冲到车前造成危险,实际关注的信息相比于视频以及多模态数据中的信息,远远少于整体输入的信息量。因此,如果统一把视频中所有信息都提取,用大语言模型或者规划器来处理的话,信息量太大,成本太高,冗余信息太多,实现效率低。
我们的想法是根据当前任务提供相关信息,在此基础上进行处理,高效且鲁棒。从视频本身出发,最关键的两个维度是时间与空间,DoraemonGPT 通过设计把信息分成时间和空间两类,用不同大模型提取相关信息,在提取过程中,用大语言模型的子模型,小的 Agent 输入用户问题,然后由 Agent 决定这个任务更需要时间还是空间信息。
绿洲:DoraemonGPT 对传统视频任务处理 Agent 的能力有何提升?
杨老师:这个提升是多方面的。首先是效率,以往对视频信息进行统一抽取之后,直接喂到大模型上下文中,或者放在统一表格和库里面,控制就会按照单元模型进行调度和求解。我们的做法是利用大模型能力对提取信息进行一定程度缩减,避免统一信息,只筛取相关信息。
另一方面,在处理视频抽取信息时拆分子任务,处理问题时不影响 DoraemonGPT 主 Agent 上下文。子任务 Agent 和外部主任务 Agent 的上下文有一定隔离,一定程度上降低了大语言模型调度时候的上下文长度,成本也因此降低。
绿洲:今年您关注 AI 的重点在哪里?
杨老师:学术界 AIGC 相关的方向中,我目前看好两个研究方向:一个是 Agent,Agent 目前处于起步阶段,首先缺乏统一的定义标准和评估方法,即一个能让大家相信大模型 + Agent 是迈向 AGI 的重要框架;另一块就是是视频生成,Sora 的后续,目前已经有非常多开源社区工作在推进,希望看到国内的开源社区能有好的工作出来推动发展。
本文来自微信公众号“緑洲资本 Vitalbridge”(ID:Vitalbridge),作者:参赞生命力




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
