# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
4月24日,商汤集团在港交所暂停交易,暂停交易前上涨31.15%。商汤集团回应,“昨日日日新大模型5.0发布会广受好评,受到市场极大关注;依照上市规则及港交所建议,公司将进一步刊发相关公告。”
就在前一天的“2024年商汤技术交流日”上,商汤发布了对标GPT4-Turbo的大模型日日新大模型SenseNova 5.0,追赶GPT4可能是当下中国大模型行业的集体目标。商汤在上海商汤临港AIDC举行的“2024年商汤技术交流日”上,交出了自己的答卷。
不是GPT-4-1106-preview,不是GPT-4-0125-preview,而是在一众大模型榜单中都高居榜首的GPT4-Turbo。从SenseNova 4.0超GPT-3.5,到SenseNova5.0全面对标GPT-4 Turbo,商汤用了不到三个月时间。

这背后没有魔法,而是大语言模型中的第一性原理:尺度定律(Scaling laws)在起作用。
首先,随着数据、模型和算力规模的不断提升,商汤能够不断提升大模型的能力。这也是OpenAI所强调的模型性能与模型大小、数据量和计算量之间的幂律关系,是一个更为通用的性能提升框架。
但大模型并非单纯的暴力美学,背后是大量的软件工程系统问题。商汤在遵循尺度定律的前提下,通过科学试验得到数学公式,做到了能够预测下一代大模型的性能,而不是盲目的随机尝试。
商汤科技董事长兼CEO徐立总结了两个假设条件:
第一,可预测性:可以跨越5-7个数量级尺度依然保持对性能的准确预测。
第二,保序性:在小尺度上验证了性能优劣,在更大尺度上依然保持。
这指导着商汤在有限的研发资源上找到最优的模型架构和数据配方,从而让模型能够更高效地完成学习的过程。“我们在很早时间就预测到我们的模型可以在一定测试级上超越GPT-4的能力。”
也就是说,商汤在大模型的研发过程中,注重通过小规模实验来预测和验证模型架构和数据配方的有效性,并确保这些在小规模上得到验证的结论能够在更大规模上得到保持和应用。

“如果我们选择更佳的数据配方性能提升效率会更大。”基于商汤的实验结果,小模型在优化数据的情况下,也可以性能逼近甚至超越跨数量级的大模型。例如,Llama 3小模型跨越了一个数量级领先于Llama 2更大尺寸的模型。
随之而来的一个问题是,更好的数据集在哪里?数据集质量如何提升?
据徐立介绍,SenseNova 5.0采用了10T+tokens中英文预训练数据,通过精细设计的清洗处理,形成高质量的基础数据,解决大模型对客观知识和世界的初级认知。
除此之外,商汤还合成构造了思维链数据,预训练过程中大规模采用逻辑合成数据(数千亿tokens量级),从而提升模型推理、数学和编程能力。这本质上是在帮助大模型学习人类解决问题的思路和方法。
“这是真正意义上保障模型能力提升的关键。如果每一个行业思维链数据都能够被轻松构造的话,我们在行业里面的推理能力就会大幅度提升”。
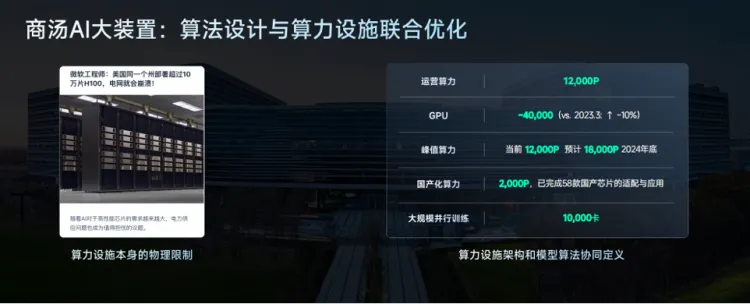
尺度定律也存在物理极限,比如没有数据,比如硬件连接的极限。在今年3月份的时候,微软工程师就提到OpenAI如果在同一个州部署超过 10 万张H100 GPU,电网就会崩溃。徐立表示,“这需要对这些卡、这些连接、这些拓扑进行新的设计,算法设计和算力设施需要联合优化。”
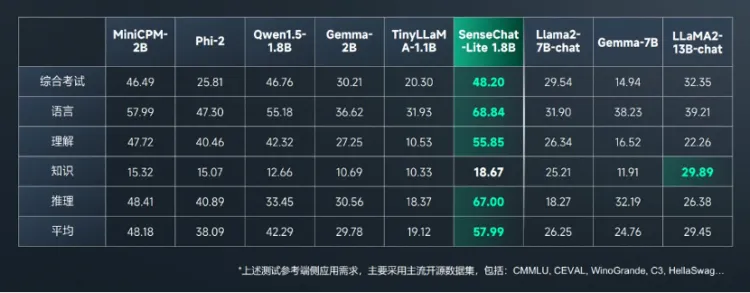
Llama3 8B和70B版本的发布,让我们看到小参数大模型在端侧场景的潜力。商汤此次也推出的1.8B参数的SenseChat-Lite,在主流评测中,超过了所有开源2B的同级别模型并且跨级领先了LLaMA2 等7B、13B模型。
通过端云协同解决方案,SenseChat-Lite可在中端平台实现18.3字/s的平均生成速度,旗舰平台可达到了78.3字/s。
在端侧的多模态方面,扩散模型同样可在端侧实现业内最快的推理速度,商汤端侧LDM-AI扩图技术在某主流平台上,推理速度小于1.5秒,支持输出1200万像素及以上的高清图片,支持在端上快速进行等比扩图、自由扩图、旋转扩图等图像编辑功能。
商汤针对端侧业务的SDK也正式发布,涵盖了日常对话、常识问答、文案生成、相册管理、图片生成、图片扩展等场景,支持全系列高通8系列、7系列的芯片,以及MTK天玑芯片,适配手机终端、平板电脑、VR眼镜、车载终端。
针对金融、代码、医疗、政务等行业面临的数据私有化部署需求,商汤推出了企业级大模型一体机。可同时支持企业级千亿模型加速和知识检索硬件加速,实现本地化部署,开箱即用,同时完成了国产化芯片的适配。支持最多2P FLOPS的算力,256G的显存,448 GB/s的连接。

面向软件开发,商汤发布了小浣熊代码大模型一体机轻量版,帮助企业开发人员更高效地编写、理解和维护代码,其在HumanEval的测试通过率达到了75.6%,超过GPT-4的74.4%,能够支持90多种编程语言和8K上下文,单机可满足100人以内的团队应用需求。成本可从调用云端代码服务的每人每天7-8元,降低到每人每天4.5元。小浣熊代码大模型一体机轻量版的售价为每台35万元。
此外,商汤还发布了基于昇腾原生的行业大模型,与华为昇腾共同打造面向金融、医疗、政务、代码等大模型产业生态。
在最后环节,徐立还留了个“彩蛋”:发了三段完全由大模型生成的视频,并表示短时间会发布文生视频平台。这也让人开始想象,追上GPT-4之后,在视觉领域积累深厚的商汤,下一个目标是追上Sora吗?
除了日日新SenseNova 5.0升级后对标 GPT-4 Turbo以及端侧和边侧产品的发布,商汤这次技术交流日的另一个关键词是“伙伴”。
商汤邀请了邀请了华为昇腾计算业务总裁张迪煊、金山办公CEO章庆元、海通证券副总经理兼首席信息官毛宇星、小米集团小爱总经理王刚、阅文集团筑梦岛总经理葛文兵等生态伙伴嘉宾分享。共同探讨和交流大模型技术在办公、金融、出行等不同领域的应用及前景。
这除了体现商汤大模型能力在不同领域的应用潜力,实际上也是在外界传达了其商汤未来进一步深化行业合作的愿景。追上GPT4之后,真正比拼的可能是应用落地能力,在这一点上,商汤需要更多的伙伴。
无论是联合华为发布基于昇腾原生的行业大模型,还是端侧SDK的发布,我们可以看到商汤一直在强调行业合作伙伴的重要性,这也体现在与合作伙伴的细节中当中:
华为昇腾计算业务总裁张迪煊表示,商汤在今年三月初的加入昇腾的原生计划,时隔一个多月已经发布四款行业大模型。
小米集团小爱总经理王刚则提到,商汤曾在两三天内完成了的小米汽车的优化需求,并成功通过雷军验收。
“快”的背后是持续对生成式AI业务的投入,早在2021年,商汤就开始构建自己的AI基础设施SenseCore商汤AI大装置,AIDC是商汤重要算力基座,也在2022年1月24日正式启动运营,业绩公告显示,商汤大装置总算力已达到12000petaFLOPS,相较于2023年初提高了一倍,GPU数量达到45000卡,实现了万卡万参的大模型训练能力。
自2023年3月宣布战略聚焦AGI以来,商汤更是以季度为单位更新基础大模型及解决方案。到SenseNova5.0追上GPT-4之后股票涨停,市场的逻辑很清晰,短时间内现金流充足,追上OpenAI目前最新的模型之后可以讲更大的故事,加上足够低的价格,自然会有更多人用脚投票。
“快”的结果落在商汤生成式 AI 业务的快速增长上,根据商汤科技最新发布的2023年财报显示,其生成式AI收入业务收入达12亿元取得了200%的大增长,占公司总收入的35%。这也是商汤成立十年以来,以最快速度取得超过10亿收入的新业务。
从AI1.0时代走过的商汤,作为重要的引领者,见证了中国人工智能产业的变迁。
在AI2.0时代,所有人似乎都成为了OpenAI的追赶者。这场围绕大模型的竞争,既是大鱼吃小鱼,也是快鱼吃慢鱼。OpenAI的领先身位带来的是绝对的竞争优势,参与者们要摆脱这种追赶的状态,需要底层基础设施的成熟,也需要顶层设计的创新。
对于商汤来说,只有在大模型商业化爆发前的黎明中跑得足够快,跑得足够久,才能够吃到第一波红利,在根本上解决掉亏损问题,从而回到它应得的位置。
公元前十六世纪,商汤通过一系列的军事行动和政治策略,推翻夏朝建立了商朝,后人将这一项变革称为“商汤革命”。未来几年,生成式AI可能将会成为商汤最大的收入来源,这或许正是商汤所需要的那场革命。
文章来自微信公众号“硅星人Pro”,作者 周一笑



