# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这篇文章来自知名的「科技与商业战略」博客 Stratechery,作者是 Ben Thompson,采访对象 Nat Friedman 和 Daniel Gross 是一对投资二人组,他们很像是「人工智能时代」的 Marc Andreessen 和 Ben Horowitz,后者通过创办了 A16Z 在 2008 年之后成为了移动互联网时代硅谷的顶级投资人。
他们两个人非常有能量,也对世界有自己独到的思考。从 2017 年开始,Nat 与 Daniel 开始了在人工智能领域的合伙投资,成立了一家名为 AI Grant 的组织,这既是一个「分布式人工智能实验室」,也是一个新型的投资基金。这样「科技与研究驱动的,具有风险投资能力的新型组织」也会在 AI 时代越来越多。
我认为这篇文章里 Nat Friedman 和 Daniel Gross 提到最重要的观点是:
我很高兴欢迎丹尼尔·格罗斯(Daniel Gross,以下简称 DG)和纳特·弗里德曼(Nat Friedman,以下简称 NF)再次参加 Stratechery 的采访,这是我们持续系列的第六次对话(我们之前曾在 2022 年 10 月、2022 年 12 月、2023 年 3 月、2023 年 8 月和 2023 年 12 月进行过对话)。
原文发布时间:2024 年 2 月 29 日
这个系列在我的博客 Stratechery 中有些独特,因为我的采访对象通常不是投资者;然而,这个系列始于 2022 年 10 月,当时弗里德曼(Friedman)和格罗斯 ( Gross ) 正在启动一个资金资助计划(a grant program),我们走到一起因为我们共享了一个观点,即围绕人工智能领域的活动或讨论还远远不够;一个月后,ChatGPT 问世了,世界发生了巨大变化,包括对于弗里德曼和格罗斯这两位领先的投资者来说也是如此。因此,我认为继续我们之间这个谈话系列会非常有价值,也会很受欢迎,但请记住,弗里德曼和格罗斯可能投资了我们讨论中提到的某些公司。

需要指出的是,就「人工智能世界」的新闻而言,过去这个月尤为重要。我们在对话时尽力涵盖所有内容,从 Gemini 到 Sora 再到 Groq、Mistral 和 Nvidia,以及探讨我们对人工智能领域和可能接下来会发生的事情的常见哲学层面问题,特别是在当下科技公司将不同类型的模型与 transformers 架构相结合,以追求人工智能推理能力(in the pursuit of reasoning)的过程中。
Ben: 我感觉好像很久没有邀请你们来了,考虑到人工智能领域发生了这么多事情,这就是现在你们衡量事物发生的方式,其实才过了大约两个半月。然后我赶紧邀请了你们再来对谈,考虑到上周人工智能领域的公司发布了一大堆公告,甚至在我们稍后会谈到的谷歌「Gemini 事件」(指的是谷歌发布了他们最先进的人工智能模型双子座 Gemini, 但是因为其中生成的图像有很多「掺杂的政治正确」内容倾向,谷歌受到了激烈的批评)之前就发生了。但在我们谈到人工智能之前,Nat,你还是先给我们介绍一下「维苏威火山碳化古卷挑战」(Vesuvius Challenge)的最新情况。
注:维苏威火山碳化古卷挑战(Vesuvius Challenge)的官方网站是 scrollprize.org,位于意大利(古罗马时期的庞贝古城)的维苏威火山(Mount Vesuvius)在 2000 年前爆发,其中的赫库兰尼姆图书馆许多由莎草纸做成的卷轴经书,也一起被火山喷发而埋没与碳化。在后来考古发现这些古经卷之后,科学家曾经试图打开和破译它们,结果因为没有合适的技术毁了一些古卷,有些则完全化为碎片。硅谷企业家弗里德曼在网上观看了肯塔基大学的计算机科学家西尔斯(Brent Seales)对赫库兰尼姆古卷的修复技术演讲后,产生了浓厚的兴趣,主动提出共同发起了这个挑战,面向全世界征集可以复原经卷里内容的技术解决方案,尤其是利用人工智能来解决这个问题。

NF: 谢谢你的提醒,Daniel。事件发生在公元 79 年(79AD),当时维苏威火山爆发,喷发出一股巨大的热气和热泥浆巨浪,火山碎屑流覆盖了整个那不勒斯湾,完全埋没了庞贝城和赫库兰尼姆(Herculaneum)城镇。事实证明,在赫库兰尼姆城镇外,由朱利叶斯·凯撒的岳父建造了一座非常豪华的别墅,极具宽敞和奢华,也被埋在 60 英尺厚的泥浆之下。
当农民们在 18 世纪(1700 年代)挖井时意外发现了这座被埋葬的别墅,当他们在地下挖掘穿过墙壁和房间时,他们主要掠夺了不同的雕像和文物,他们也发现了一组奇怪的灰色物体,一种碳化块(carbonized lumps),原来是莎草卷轴(papyrus scrolls)。其独特之处在于,没有其他古代图书馆能够在那个时期幸存下来。如果把纸莎草纸放在那不勒斯湾的湿度之下,纸莎草纸往往会在 100 年左右的时间里完全腐烂变质。因此我们所拥有的古代著作都是在中世纪由一连串的僧侣按顺序抄写留世的。还没有完整的古代图书馆保存下来。

基本上就是这样,但其中的奥秘和难度在于这些留下的碳化古卷无法被打开。它们非常脆弱,我经历过这种情况,如果你把莎草纸卷碳化并试图打开它,它们会在你手中碎成片,你无法阅读它们。试图打开它们的过程即会摧毁它们。因此,自从 18 世纪被发现以来,已经有近 300 年的努力尝试打开和阅读这些文物。
去年年初,丹尼尔和我决定启动一个项目,试图破解这个难题。总的方法是在不打开和不损坏卷轴的情况下,对卷轴进行真正高分辨率的三维扫描(scan the scrolls at really high resolution in 3D without opening them)。要做到这一点,需要使用粒子加速器 ( a particle accelerator ) 来获得非常高的分辨率,然后希望通过这些扫描,将这个问题简化为一个软件问题,在这个软件中,您可以使用计算机视觉和机器学习算法来虚拟地拆开和读取这些卷轴(reduce this problem to a software problem where you can use computer vision and machine learning algorithms to virtually unwrap and read these scrolls)。
一年多以前,或者说不到一年前,当我们启动「维苏威挑战赛」这个项目时,我真的不知道它是否能成功。但它看起来绝对值得一试,我们决定将它作为一个全球竞赛来发起,让更多聪明人参与其中。我只是觉得这简直太酷了,而且似乎几乎没有人知道这件事,知道有成千上万卷无法打开的古代卷轴,我们想,也许我们可以激励 1000 个在家里用笔记本电脑的人去破解它,而这基本上就是目前发生的事情。
就在上个月,我们非常兴奋地宣布,70 万美元的大奖颁给了一个团队,他们刚刚完成了这项具有里程碑意义的工作,他们能够展示一个卷轴的大部分内容并阅读出来。我们有了 2000 个希腊文字符,这些字符以前从未被看到过,对世界来说是全新的。
因此,这个项目成功了,它奏效了。现在,我想我们下一步要做的就是扩大规模(scale this up)。我们目前所能读取的内容只占一个卷轴的 5%,我们还剩下几百个卷轴,地下可能还有几千个卷轴,所以我们需要做的是扩大算法的规模 ( scale the algorithms up ),这样我们就能一个接一个地读完整个卷轴,然后希望能够读完所有的卷轴。
Ben: 我们是否有很高的信心能够真正读懂这些卷轴呢?
NF: 我现在非常有信心。现在看,我们只读了一个卷轴的 5%,还有很长的路要走。
Ben: 从某种程度上说,这就像从零到一的时刻。
NF: 是的,确实。如果我们能读懂 5%,那么很可能我们能读懂整个卷轴,如果我们能读懂一个卷轴,我们可能也能读懂大多数其他卷轴。所以,是的,我从「天哪,我不知道这能不能行」变成了「这肯定会成功,只是时间问题,以及我们能否做到多高效」。
Ben: 我的意思是你必须小心。你从低期望,高希望,转变成了高期望。你可能正在让自己陷入失望的境地。
NF:(笑)这也有可能!
Ben: 这听起来非常令人兴奋。你在几次采访中都提到过,而且另一个很酷的事情就是速度,基本上不到一年的时间,这是一个很好的迹象,说明我们在弄清楚问题是什么,并在扩大规模方面的能力也很强。
NF: 是的,我的意思是,如果你能快速运行它,以我们现在所知道的,你可以在一个月内完成所有这些工作。所以,大部分工作都是要搞清楚该怎么做,搞清楚方法是什么,该从哪里入手,以及什么样的算法效果好。现在这些都是我们积累的知识,所有代码都在 GitHub 上,都很简单明了。数据是公开的,我们有一群非常优秀的人正在这方面努力。下一个重要的步骤是我们称之为「自动分割」(Auto Segmentation)。基本上,你有这个 3D 扫描的卷轴,你需要追踪其中的螺旋卷曲的莎草纸表面,这个过程仍然相当耗费人工的。我们基本上都是用人工标注,他们进去手动点击莎草纸的 X 光横截面。
Ben: 然后你再选择上面的墨水字迹部分或其他物质区分开来。
NF: 是的,就是这样。事实证明,机器学习算法能够捕捉到墨水中的微妙图案。当凯西-汉德默(Casey Handmer)用自己的眼睛手动检查数据时,他称之为持续直接观察 ( persistent direct observation ),当他自己能够真正注意到一些墨水字迹浮现出来时,就出现了重大突破。
Ben: 然后让算法针对那个部分开始工作?
NF: 是的。结果发现,他可以看到裂开的泥浆图案,你可以看到这代表了大约 2% 的墨水部分,然后还有 98% 的墨水部分是很难看到的,机器学习算法会随着时间的推移而学习,因为你会在训练数据中添加更多的墨水区域。但现在,通过机器帮助可以揭示整个墨水区域,这是一个非常简单的模型,只需要良好的训练和正确的架构,它就能很好地工作。因此,我很有信心,今年我们就能拥有整本书了。也许明年我们就能找到几百本书,前提是我们能得到许可,扫描所有已经找到的卷轴的话。
Ben: 哇,太棒了。恭喜恭喜。
Ben: 从已知数据 ( known data ) 入手,试图破译和提取数据信息,这很有趣。而 Sora 则完全相反,它从基本上随机的噪音开始,生成长达一分钟的视频。
说到时间的预期(time expectations),当 DALL-E 2 发布时,我写道:「看,这显然会最终跟视频有关。」我认为视频是一个很重要的问题,我仍然相信 VR,但我认为生成式 AI 对这种媒介的成功至关重要。我当时认为,这显然还需要几年的时间进步迭代。
然而,时间只快进了 19 个月,期间我们实际上已经有了 Stable Diffusion 驱动的视频,现在我们一下就快进到这里,Sora 显然更加功能强大且高保真(high fidelity)。这反映了现在这年头事物普遍的发展速度有有多快,但当你看到这些视频时,Daniel,你的反应是什么?是否像「是的,就是这个。」你是否预料到了 Sora 这样模型的产生?这是中途的一部分,还是你也会感到惊讶?
DG: 嗯,我们在播客开始时观察到,在人工智能领域中存在一种时间膨胀的动态(a time dilation dynamic),你对事物本身发展速度的感觉会发生很大变化,有一种感觉是,这其实是一个相对平静的时期,然后就接连发生了三四件事情,实际上大部分都是在一天之内发生的。
Ben: 是啊。
DG: 我认为谷歌的 Gemini 的上下文语境窗口扩展(Gemini's context window expansion)一下就出来了,Sora 和其他两三件事情也同时发生在那一天。
Ben: 我们要尝试在今天涵盖所有这些内容,看看在一个小时内我们能不能聊完。
DG: 我想每个人突然意识到,「wow,技术的加速趋势又回归了。」对我来说,对于 Sora 这件事,我认为 Nat 也提到了类似的想法,我不知道谁先提出来的?可能是他吧。Sora 的出现实际上只是一种信念,最终,尺度法则是起作用的(It was really just a belief that scaling does work at the end of the day)。现在人们正在讨论 Sora 是否已经拥有了一个世界模型(a world model)以及这究竟意味着什么。对我来说,这是次要的 ( that's secondary ),我认为人们往往对此种讨论过于哲学化。
我主要的观察仅仅是从纯审美享受(pure aesthetic enjoyment)、经济价值 ( economic value perspective ) 的角度来看,尺度规模化继续起作用,我们之前确实看到它在文本领域中起作用(scaling continues to work and we'd previously really seen it work in the domain of text),然后我们逐渐开始用完了文本 tokens,我认为行业现在大致处于这种状态。而视频的好处,特别是他们的做法是,你可以真正生成无限量的训练数据。你最终的目标是尝试制作一个自动编码器(an auto encoder),它具有与游戏引擎中相同的逻辑配对(the same logic pairings you have in a game engine),但使用 diffusion 和 transformers 模型架构。无论如何,你都可以生成大量数据,你实际上可以证明...
Ben:无限量的数据,因为你可以利用游戏引擎来生成它?
DG:是的。当我说「无限」的意思,视频 tokens 的数量比文本要多得多。当然,就其包含的逻辑信息量(the amount of logical information)而言,视频的密度要低一些,但视频总量要多得多。它并不完全理解玻璃是如何破碎的,但通过视频它绝对理解水波是如何荡漾的。
Ben: 还有光是如何扩散的(How light diffuses),这是相当不可思议的。但是等等,我想再强调一下这点。为什么会有更多的视频而不是文本 ( Why is there more video than text )?鉴于人类历史上文本的制作成本要便宜得多,这似乎有些违反直觉?当分析为什么电视市场的发展与音乐市场发展与文本市场不同的原因时,事实恰恰相反,文本便宜且易于分发(text is cheap and easy to distribute)。为什么会有更多的视频呢?
DG: 显然,视频包含的信息要比文本多得多,并且我会认为,尤其是随着互联网的出现,捕捉和传播视频其实更便宜(I would argue cheaper to capture and distribute than text)。目前,这些信息的熵不如文本丰富,逻辑也不如文本丰富(that information is not as entropy rich or as logically rich as text)。当然,在文本中,也存在着分布的梯度,任何预训练过模型的人都会告诉你,大部分文本是无用的(there's a gradient in a distribution and anyone pre-training a model will tell you that most of the text is useless),实际上,文本或视频中非常高质量的 tokens 数量很少。在音乐中可能也是如此。这里存在一个有趣的帕累托分布(Pareto distribution)。
范阳注:帕累托分布是一种统计学上的现象,也称为 80/20 规则。它描述了一种常见的分布不平衡现象,即在许多情况下,大部分的结果都来自于少部分的原因或资源。换句话说,帕累托分布指出,大部分产出来自于少数重要的输入或因素。打个比方,一家餐厅的菜单里也蕴含帕累托分布。想象一家餐厅有 100 道菜,但其中只有 20 道菜是大部分顾客会点的,它们带来了 80% 的销售额,你需要下功夫准备好的也是这 20 道菜。
Ben: 是的,在生成式人工智能的早期阶段,我认为我认知错了的一个地方是,结果证明,高质量、标记良好的数据,实际上比仅仅从互联网上抓取数据要好得多。
DG: transformer 架构的神奇之处在于即使数据质量很糟糕,它也能工作(it works even when the data's bad),所以我认为曾经有一个海市蜃楼一样的时代,人们认为数据质量不重要,反正它确实能工作。我们的一个朋友将以前的技术比作试图在手指尖上平衡一根竿子,而 transformer 只是想要工作。但我认为人们忘记了,如果数据是高质量的,它的效果只会更好。所以,真正的奇迹是,即使数据不好,它也勉强能工作,但如果数据好得多,它的效果要好得多。
我是说,高质量的 tokens 在某种程度上是一种存储计算的形式(high quality tokens are a form of stored computation),所以我认为现在许多研究人员所做的数学工作是你可以花费数亿美元在 Nvidia 上,试图获得高度精细化的 tokens(highly refined tokens),或者你可以从人们那里获得它们,基本上需要对每个 token 的成本进行数学建模(you can acquire them from humans and there's a mathematical modeling you'd want to do basically on the cost per token ),以及计算其价值如何。但是,理论上存在非常高价值的数据,你可以通过无限的计算资源来获得(you could get there without it by spending an infinite amount of compute),但是你也可以绕过许多浮点运算,并且在某些专业领域仅通过从人类那里获取高质量信息就会更容易 ( you can bypass a lot of flops and just eliciting high quality information from humans in some domains is easier )。
Ben: 说到物理学方面很有趣。你已经引出了哲学层面的争论。我对此的看法是,尺度缩放(scaling)是一个重要的观点,尺度缩放是有效的(the scaling works),我们在 transformer 架构(transformer architecture)上还远未达到瓶颈。但是,即使你无限地扩展,你会使用 Sora 类型的模型来模拟飞机机翼如何工作的吗(Sora-type models to model an aircraft wing)?我非常怀疑这一点。但是,实际上,对于你所说的这一点,在涉及到虚拟现实的例子中是一个无关紧要的问题。当你在虚拟现实中或在任何娱乐场景中时,实际上没有人关心空气在机翼上的物理情况是否完美贴合现实。如果你想逐帧分析今天电影中 CGI 的物理情况,你可能会发现各种各样的漏洞,但实际上这并不重要。对我来说,这才是重要的。这些模型的「物理学」已经足够好了,而足够好的「物理学」在很多情况下都足够用了。
DG: 是的,我认为是这样。我想你已经指出了这是一种「低端市场的破坏性创新」(a downmarket disruption),你不会用这种模型来替代「把东西放进风洞做测试」。但你可能会用它来替代制作你想做的视频游戏的模型或草图,或者电影场景之类的东西,所以我认为这是一个了不起的工具。
至于 Sora,就像 OpenAI 关于发布它的推文所示,它需要很长时间来渲染内容。因此,我现在会将其类比为 LucasArts(卢卡斯影视)的早期阶段,单个帧的渲染需要几个小时,成本也非常昂贵。当然,我们现在已经到了在我们的电脑上和 Unreal Engine 游戏引擎上可以比他们当年拥有的更好产品的时候。
Ben: 所以,基本上现在回头再看《玩具总动员 1》,就会知道渲染就花了好几天,而且看起来效果很糟。
DG: 它看起来很糟糕,而 Sora 的出发位置并不那么糟糕。它需要的是几分钟,而不是几天,但它的成本确实非常高,但随着时间的推移,这将会变得更好。
我认为现在还有一个悬而未决的问题,我们认为这是可能的,但必须要回答的是:「这些模型能提炼出多少东西(How much can these models be distilled)?」我认为,对于生活中的任何领域来说,这都是一个有趣的抽象问题,比如说,做非常高质量的数学,编写高质量的代码或英文,或者生成音乐。对于这个特定任务,实际上可以有多大的终端模型大小(What is actually the terminal model size that you could have for that particular task)?
这个问题值得思考,因为可能隐藏空间最终由几个简单的法则控制(the latent space is ultimately governed by a few simple laws)。一旦你弄清楚了它们,它们实际上在大小上是相当小的,这是我们将要用我们的廉价物理模拟器进行的实验,以及对于你所说的,不仅仅是我们是否可以制作它们,而是我们是否可以提炼它们并将它们压缩成一些基本的现实法则,以至于人类可以观看和享受它(can we distill them and compress them to something that has the basic laws of the reality so much that a human can watch it and enjoy it),但也可以在一个单独的 GPU 上运行,也许有一天甚至可以在一台单独的 MacBook 上运行,谁知道呢?
Ben: 你刚才提到了这一点,我认为这是一个非常有趣的观察, 有关于文本。文本在逻辑上更密集,但视频更大量(Text is more logically dense, but videos are more)。我不记得你怎么说的—信息密度(information dense),或者说图片胜过千言万语,视频又胜过图片千万倍。我们感知视频的时候获得的信息量更大,尽管电影中十分钟的段落可以用一段文字来概括。
在这里有一个非常有趣的分叉线,在有多少逻辑嵌入在一个特定的片段(how much logic is embedded in a particular segment)中,和有多少信息存在于人们的感知中(the perception of how much information is there),我突然意识到视频中也存在这样一个方面—我们已经在图像模型中看到了这一点。尽管从人类的角度来看,图像可能更令人印象深刻,包含更多信息,但它可以比语言模型小得多。视频也是一样的道理。从我的角度来看,它也没有理由不是这样,考虑到它的工作原理。这只会突显出娱乐 / 虚拟现实这个巨大的市场,即使这与「我有一个理解意义并且可以扮演代理以及去执行(I have an assistant that understands meaning and can be agentic and act)」有所不同。
NF:是的,我觉得很有趣。我在 Twitter 上提到过这一点,但我觉得很有趣的是,据说有很多人工智能实验室都以创造 AGI 为目标,也就是一些「超人般能力的推理实体」(superhuman reasoning entity),而且他们似乎一致决定,通往 AGI 的道路上包括创造娱乐性的图像和视频,因为他们基本上都在这么做,也许达到 AGI 确实需要做到这一点,谁知道呢?

但是,在这个行业里,我们可以看到一个有趣的共识,那就是对于人类来说,视频绝对是注意力的层级顶端(video is at the top of the attention hierarchy),它是最能抓住你的东西。我们确实看到了这一点,因为 Gemini 1.5 在通过大量 tokens 的推理能力上取得了相当重大的突破,而且 Gemini 1.5 是在 Sora 之前的几个小时发布的,但 Sora 确实更引人注目,吸引了人们的想象力,因为你只需要观看它,就这么简单。看看 Sora 的效果就很难忘掉。
Ben: 是的,我认为这是我得到的另一个启示。我认为 Daniel 说得对,OpenAI 有扩展自己技术路线的勇气,他们的信念得到了回报(OpenAI has the courage to scale and their faith is rewarded),我认为也许 Sora 的推出,在很多方面,给了最后一批对「扩展规模」持怀疑态度的人一记猛药。如果你曾经在观望,说尺度法则行不通(scale doesn't do it),面对 Sora,很难再提出异议。另一个事情就是提醒我们,对于人类来说,视频是注意力金字塔的顶端 ( video is at the top of the attention pyramid ),社交媒体多年来一直在教育我们这一点,但现在我觉得我们也在 AI 领域看到了这一点。
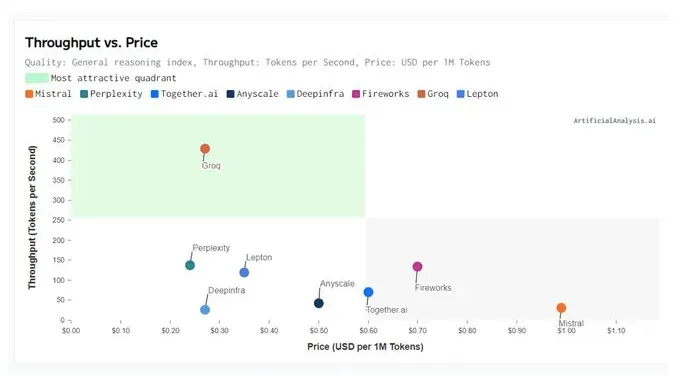
Ben: 另一个发布,我想应该是在同一天,是 Groq 在线发布了使用他们的处理器的演示。这与处理器(processor)有关,而不是模型的创新。他们使用 Mistral 和 Llama 作为可用模型,但速度确实非常引人注目。我觉得这很重要,不是因为它对 Groq 的意义——那是一个不同的问题,实际上我很好奇你们在某些问题上的观点——而是长期以来,对于人工智能存在着用户体验问题(there is a user experience issue when it comes to AI),我们讨论的许多用例,因为人工智能它很像人类(it is human-like),恐怖谷效应(范阳注:指人们看到机器或者电脑制作的人类图像时可能产生的厌恶感)的广度非常大,基本上在这种体验中的任何摩擦都比在使用手机时重要得多。
使用手机时,当你从口袋里掏出来手机或者你正使用这个设备时,你永远不会忘记你正在使用的是手机或电脑。你永远不会像,「哇,我以为我在跟一个真人交谈,其实我是在用手机说话。」不,这永远不会发生,因此你实际上有更多的容忍度来接受用户体验上的摩擦。然而,当涉及到使用人工智能时,它能够听起来像人类一样,运行速度很重要,速度非常重要(speed matters, it matters hugely),我认为那个演示为什么很重要是因为,抛开 Groq 这家公司的商业前景不谈,它确实让人感觉到,是的,这是正确的方向。速度实际上带来了天文数字般的差别,这感觉就像是验证了我的观点。

范阳注:Groq 是一家技术领先的「机器学习推理加速器」公司。Groq 宣称其 LPU(语言处理单元)的推理性能是英伟达 GPU(图形处理器)的 10 倍,而成本仅为其十分之一。
DG:是的,我认为我们人类的思维响应时间相当快(we have pretty fast response times from our minds),我认为大脑运转在相当高的赫兹频率上 ( the brain runs at a pretty high hertz ),根据你的心情不同,会有阿尔法、贝塔、伽玛等频率状态,但归根结底,我们对现实的感知非常迅速,我们之前并没有经历过有什么东西是那么即时、快速和流畅的经历(we hadn't quite had an experience where something was that instant and that fast and that fluid),但说实话,我认为这只是一个开始,一些人将不得不努力将这个概念完全实现,无论是在 Groq 的硬件上还是其他地方,并将其打磨成一款非常精致、优雅的产品,能够处理中断的问题,诸如此类的事情。
但一旦有人做到了这一点,如果我不得不猜测,如果我们试图在下一期播客或再以后的播客里进行预测,新的大事件是什么(what is the big new thing)?我的一个看法是,我们将进入一个更加有主动代理能力的模型世界(a more agentic world of models),在这个世界中,我们现在拥有的东西都还只是处于「寒武纪生物大爆炸之前」的时期。
你去 chat.openai.com,输入一堆词,然后一些词就会输出出来,而这个模型最终更像是在押韵(说段子)而不是在思考(the model is rhyming more than it's thinking),而且速度还有点慢,我认为下一个时代是让实际的人工智能代理在互联网上为你执行任务,以人类的速度与你交谈,我认为经济和市场定价现在根本没有考虑到这一点(the economy and market prices don't factor this in at all)。
Ben: 嗯,这就是应该对 Groq 持乐观态度的原因。如果你实际计算一下他们系统的成本,其速度如此之快的部分原因是每个芯片都有极少量的 SRAM,SRAM 可以保持数据的位置,而且超级昂贵,但它是确定性的,他们知道数据的确切位置,但这意味着他们需要大系统才能有足够的内存(they need big systems to have enough memory)。这意味着他们需要一个巨大的市场来开发 ( they would need a large market to develop )。因此,他们正在推动按 token 计算成本的想法(cost per token idea),但你必须要有一个天文数字的 tokens 在系统中流动,这样的定价才有意义。不过,我的感觉是速度实际上很重要,这是一个使用场景的解锁者(a use case unlocker)。

NF: 速度也是用户界面的解锁者(a user interface unlocker too)。由于模型输出速度慢,你不得不采用流式传输 tokens(streaming tokenization),tokens 流基本上都是冲着你来的,而现在有了速度,速度一直都是一个特点,我认为实际上在很多方面,这只是提醒了用户界面设计的一个长期规则,那就是速度很重要,延迟也很重要(speed matters, latency matters)。这是一个有趣的事情,因为用户通常不会要求它,但他们肯定会感觉到他们更喜欢那些反应灵敏的东西,而不是那些迟钝的东西。
Ben: 我认为,就像我说的,这种速度差异对于这类模型的重要程度要大得多。
NF: 但在这种情况下,我认为它也解锁了新类型的用户界面(it unlocks new types of UI),而以前你只能坐在那里看着模型向你发送 tokens(the model just stream tokens at you)。
Ben: 嗯,在这种情况的时候,你就可以与模型进行交流,并且感觉这是很正常的对话。一点也不奇怪。
NF: 是的。嗯,而且实际上,我认为,在某种程度上,它给人的感觉更像超人一样的超级人工智能(feels more superhuman),因为你可以在几秒钟内得到一篇论文,你可以在几分钟内得到一本书的创作,在某种程度上,超人般的人工智能的感觉更强烈(the superhuman feeling is stronger),但我也认为,你可以让模型,例如,如果你愿意花钱,让模型探索几条路径会更合理,也许它会尝试十种方法,然后选择其中最有效的一种,因为它可以很快完成这一点。
Ben: 是的,它有足够时间去探索。
NF: 可能会有更多的探索时间。所以我们已经习惯了看到一些用户界面的 hack 技巧,比如 Bing 这样的产品,它会输出一些文本,然后将其删除,并说,「对不起,我说了一些不该说的话」,或者其他什么的废话。在速度慢的情况下,这几乎是很滑稽的,这让人强烈地感觉到,我们依然处于 AI 发展的早期阶段,但在 AI 高速运行时,这种瑕疵可能根本不会被察觉到,所以我认为速度的提升释放了一大堆以前不可能实现的新体验,这让人兴奋不已。
Groq 非常有趣,因为他们这家公司已经存在很长时间了。创始人乔纳森·罗斯(Jonathan Ross)在谷歌发明了 TPU,然后着手改进在某种程度上做得更好。我觉得他们差点就要完蛋了,然后大语言模型 LLM 突然出现,他们就有了这种看起来运行良好的专业芯片架构。再次,你会发现,在表面之下,它相当确定性(it's quite deterministic),这与他们的方法很匹配。
Ben: 你之前提到了扩展的问题,丹尼尔。我认为与此相关的一个问题是关于芯片设计的一般情况,即在什么时候比 GPU 更专业化是有意义的(at what point does it make sense to specialize even more than the GPU)?GPU 比 CPU 更专业化,但它仍然是通用的技术,而这在涉及到诸如延迟之类的问题时会带来真正的成本。这两者是否相辅相成,密不可分?如果实际上规模是几乎所有问题的最终答案,这是否意味着更专业化芯片架构的机会可能比我们预期的更早到来?
DG: 我觉得是的。我们坐在这里,我觉得,处于 AI ASICs(Application-specific integrated circuit,特定应用集成电路)的时代来临之前。也许 Groq 有点早了,因为它已经存在的时间有点长了,但如果我要猜的话,ASIC 将是未来的重要组成部分。
范阳注:ASIC 是一种定制化的集成电路,专门设计用于执行特定任务或者专业功能,而不像是通用处理器 CPU 或者图形处理器 GPU 那样具有广泛的应用范围。这就像是一个定制化的工具箱,里面有各种各样的工具,每个工具都是为了某个特定的问题设计出来的,对于 ASIC,这些问题就包括了加速计算速度,加密和图像处理等等,ASIC 的设计和生产成本往往也更高,更接近于手工艺。
我认为最主要的变化之一是,我记得 Llama 发布后的第二天我给乔纳森打了电话,我告诉他行业终于要标准化了,行业会围绕着一个可以向人们展示你有多出色的东西而标准化,因为以前他的问题是,他四处展示了一堆这些基准测试的结果,但人们很难将其转化为一些经济上如此有价值的东西(he was parading around a bunch of these benchmarks and people had a tough time translating that into something that was so economically valuable ),这种经济价值足够大以至于他们会为了一款专用芯片重新配置整个架构(they'd reconfigured their entire architecture for a specialized chip)。问题不仅仅是乔纳森的,整个 2016 年、2017 年的 AI 公司都存在这个问题。事实上,Meta 通过开源 Llama 创建了一个标准,每秒输出 token 基本上成为了一个每个人都在思考的衡量标准。这成为了一个行业标准,你可以根据这个标准来执行,更重要的是,你可以根据这个标准来衡量你的资产负债表(much more importantly, you can measure your balance sheet by)。
AI 公司在训练模型时经历了两个周期,他们相对较不关心利润空间,他们只想要最好的 GPU,他们不想冒任何风险。你花了 3 亿美元,你只是希望你的模型能够「正常输出」(you just want your model to「tape out」properly),然后如果你找到产品市场契合点 ( product market fit,也就是有人为你的产品买单并且有机增长 ),你就会自然进入推理时代。现在,在推理时代(in the inference era),你最终会盯着你的成本(COGS),你每个月都在盯着你的成本(COGS),你会想,「天哪,我们每小时、每 个 GPU 都付出了那么多。我们完全有理由安排五个工程师,重新设计这个完全与之前不同的外星平台。」 这实际上是一种 ASIC,如果我把他们的芯片称为 ASIC,人们可能会不高兴,但你明白我的意思。
Ben: 嗯是的,这种情况更接近 ASIC,而不是 GPU。
DG: 这是一种专用芯片,这样做完全是有道理的,因为你只需要盯着你的成本。这有点像如果你能降低你的互通费率 ( interchange rate ),作为一家金融科技公司,你愿意花多少钱来构建自己的基础设施达到这个目的?嗯,答案通常是很多钱,而 Nvidia 的利润空间就像是 tokens 的互通费率(the Nvidia margin is a kind of interchange rate for tokens),我想人们完全愿意为自定义架构进行构建工作和承担繁重的任务,而同样的方式人们在 2017 年不愿意接受,因为当时很少有公司甚至有收入。
范阳注:对于金融市场的公司,interchange rate(互通费率)是指银行或支付网络收取的费用,用于处理信用卡或借记卡交易。做个类比,互通费率就像是你要去购物中心开店,你需要给运营商支付租金,金融公司需要支付互通费率才能在支付网络上进行交易。今天的英伟达相当于也在对流动的 tokens 收租。
Ben: 推理市场比(人工智能的)训练市场要小。
DG: 顺便说一下,唯一拥有这种技术的是广告公司,比如 Meta 和 Google,他们有自己的芯片。所以我认为最终发生的事情是,你现在能够以一种方式来商业化这些模型,你可以自己算一算,为什么为定制架构重写这些模型是有意义的,如果让我猜的话,就我所知,Nvidia 在模型训练领域的主导地位一如既往强大(Nvidia's dominance in training, as far as I can tell, remains strong as ever)。随着时间的推移,我并不认为他们会失去市场份额,但这块蛋糕会越来越大,推理领域的蛋糕会越来越大,其中包括一些 ASIC,当然,在某种程度上,TPU 和 Meta 已经拥有了自己的内部定制推理芯片,我认为,随着时间的推移,这块蛋糕会越来越大,因为这样做具有经济价值。
在考虑终端数量(terminal number)时,我认为有一件事情还没有完全计算在内,那就是我们考虑终端时通常是从 AI 的能量需求和所有这些方面来思考的。分母通常是一年内生产的 Nvidia 芯片数量,大约是两到三百万个,所以可能是两到三千万瓦的能量需求,但如果分母是通过 TSMC 生产的芯片数量,因为市场上还有所有这些 AI AS
IC 公司,任何找到产品市场匹配的公司(anyone with the product market fit decides to make their own chips)都决定自己制造芯片,那就是每年 2000 万、3000 万、4000 万个芯片,如今大多数生产的显然是 iPhone 手机芯片,功耗非常低。但无论如何,我认为当将基础设施迁移到更专业化的领域时,动态会发生变化。
有一件事可能会打破这种局面,我应该提一下,那就是我们现在所处的环境非常不稳定,因为如果架构发生变化(if the architecture changes),也就是说,如果有人取得了架构上的突破,而普通的 transformer 又表现很糟糕,而你又确实想要其他的东西,那么所有人都会涌向新的领域,而你实际上想要的是更通用一点的东西,而不是定制专业化的东西(you're actually going to want something that's a little bit more general and not specific)。因此,Nvidia、AMD 甚至会成为推理芯片的选择,但如果不出现这种颠覆性情况,而且每过一天,我认为出现这种情况的几率就会降低,这并不是因为 transformer 架构是一个奇迹以及它就是最好的架构,而是围绕 transformer 的生态系统的数量在不断增长,我认为,这些公司用自己的芯片进行专业化到时是有意义的。
Ben: 关于用户界面加速(interface speed-ups)的一个有趣问题是,我们是否即将解锁真正的(AI 时代的)全新设备(are we on the verge of really unlocking actual new devices)?我想起在 CES 上展示的那个叫做 Rabbit R1 或类似的 AI 硬件产品,虽然我还没有拿到手,但我觉得那会是一个糟糕的产品,它会连接到云端(进行计算),那里产生的延迟会让体验很差,它使用 GPU 运行设备,效果不会太好,我已经意识到了这一点。
但你可以期待这样一个世界,如果它连接到云端,连接到这个 Groq 界面会发生什么?有时会变得更快,更有趣一些,如果我们实际上可以在本地运行一个相对小型但数据输入量很大的模型呢?这一直是一个持续的疑问,但至少从公开的角度来看,到目前为止在这一点上还没有大量的开发工作。除了浏览器和聊天机器人之外,什么时候才能开始将其应用到其他设备上呢(when does this start crossing over into devices other than a browser and a chatbot)?
DG:你怎么看?
NF:我一直在等待有人开发这些东西,因为我认为需要的技术已经存在,只是需要以正确的方式组合在一起,但是过去一年里还没有人开发出能通过图灵测试对话的人工智能,无论是进行一分钟的对话还是两分钟的对话(develop an AI that passes a conversational Turing test for a one-minute conversation or a two-minute conversation)。你只要以某种方式将自动语音识别(automatic speech recognition,ASR)模型与 LLM 和文本到语音模型(text-to-speech model)融合在一起,你就能得到足够低的延迟,并且可以获得相当神奇的用户体验。
已经有一些人,我上周见到了其中一个,他们正在使用来自 ElevenLabs(语音人工智能实验室)等地方的真正高质量的语音模型,并在低延迟的情况下将这些东西拼接在一起并且运行良好。我见过一个名为 Retail.AI 的项目,它并没有百分百完全达到目标,但它是我听过的最接近这种目标的一个团队,当你使用它时确实会有所感觉(you do feel something when you use it)。这会是这样一种感觉,就好像另一端有一个真人(there is the sense that there is a personality on the other side),随着人们训练真正理解韵律(train models that really understand prosody),并能够适当调动语调的模型,以及实现真正的全双工(invoke tone appropriately and a really full duplex),因此它们不会等待你对话中的停顿时刻,而是可以随时参与对话,我认为到时会产生一种魔法般的感觉,我们将会越来越接近这个情况,我预计今年会有人在这方面努力。
所以我认为这就是科幻电影 Her 里的人工智能体验。每个人都知道这是可能的,并且即将实现,我有点惊讶于这么长时间才实现,但我认为我们肯定会实现的。我不知道它是否是一整个设备,但它是一种体验(I don't know if it's a device, but it's an experience),我不知道它是否必须是基于本地的,我认为不需要(I don't know if it has to be local, I don't think it does)。Retail.AI,我认为,显示了它不必是本地的就能发挥作用。
Ben: 这也是问题的一部分。有关 LLM 讨论的部分含义是,它对虚拟物理很有帮助(it's great for virtual physics),这种虚拟物理足够好 ( good enough physics ),但它是否真的会跨越到现实世界,或者是否会出现越来越多的分叉,网络世界完全是虚拟的,谁知道什么是真的,什么是假的?但是,也有一个非常明确的界限,或者有一个方面,例如,我们来看看机器人领域,核心物理属性仍然是非常确定性的(the core physical attributes are still very deterministic),并且它必须正常运转,但因为它使用 LLM 进行交流(it speaks with an LLM),实际上可以帮助你从感知的角度跨越这种鸿沟吗(cross the divide from a perception perspective)?
NF: 对于处理问题,似乎不可避免地会有某种本地和远程处理 ( local and remote processing ),例如,如果你有一个机器人,它必须有一些相当高赫兹的处理过程,帮助它四处走动,对事物做出反应,不至于摔倒。这必须是本地化的,也许有很大一部分可以是本地化的,但当它可能做出一些更重要的决定时,它必须参考大量的数据(as it maybe makes some bigger decisions that it has to consult a huge amount of data)。例如,它是您的个人助手机器人(your personal helper robot),它了解您生活的一切,也许并非所有信息都存储在本地,或者它知道需要查找关于世界的信息,因此我认为总会有一种大脑存在于云端用于某些事情 ( there will always be some kind of big brain in the cloud that's used for something ),而我认为这种分割是一个大问题(the split is the big question),但已经在机器人模型中看到了这种分层模型,其中会有 50 赫兹或 100 赫兹的模型来处理机器人运动学,帮助机器人在世界中移动。
Ben: 那些仍然是确定性方法(deterministic approaches),对吗?那不是运行在一个 transformer 上?
NF: 实际上,对于运动学(kinematics)还有一些学习方法也是有效的。我们开始看到这些端到端的训练 ( end-to-end training )。实际上,我认为我和丹尼尔最近曾经与一家正在做这个的公司进行过交流。似乎有一股关于机器人基础模型 ( robotic foundation models ) 的热潮正在涌现,我们还没有迎来机器人技术的 GPT-3 时刻,你在桌子上放上几只手,它就能系鞋带、装饰蛋糕或拼装乐高积木,并能相对较好地完成所有这些事情,或者感觉像是机器人智能的雏形 ( the beginnings of robotic intelligence ),但这似乎将在未来 12 或 18 个月内出现。我们将会看到这些演示。

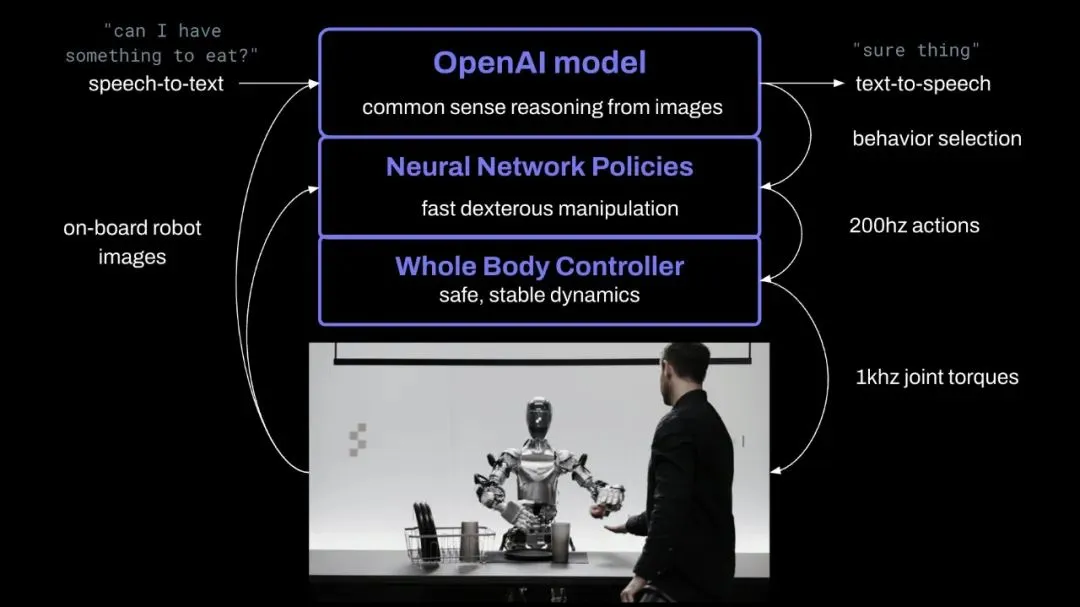
这背后的推动力是对规模化的信念和模型架构方面的一些突破,而阻碍进展的是数据(what's enabling it is this belief in scaling and a few breakthroughs on the model architecture side and what's holding it back is data)。你没有常见的机器人数据抓取,你无法在互联网上搜索机器人指令数据,因此所有的努力都是为了收集这些数据集,早期的演示确实令人印象深刻,在某些情况下,它们确实涉及运动、运动学和平衡(motion and kinematics and balance)等方面的本地学习模型(local learned models)。
Ben: 你觉得数据将会成为真正的差异化因素吗?会出现为获取独家数据集(exclusive data sets)而进行争夺,还是说数据集也会变成一种商品,每个人都将意识到真正的差异化方式是通过某种产品(the way you actually differentiate is with the product),而获得最佳数据集其实对每个人都有好处,这样就会有更多的集体行动?
NF: 我认为这是一个非常好的问题。如果是在几年前,我认为更有可能出现开放的通用数据集 ( common data sets )。目前有一些开放的机器人数据集,但它们规模较小,质量也较低,但现在我们已经进入了人工智能淘金热,无论是通过远程操作还是其他方式获得,收集大量数据的那些昂贵项目很可能会发生在有大量资金支持的公司内部,无论是大公司还是小公司。
Ben: 这是否对所有的广泛数据都适用(Does this apply to data generally)?因为从理论上讲,每个人最好都能采取一种集体的方法,让我们有一种高瞻远瞩的态度,来真正实现差异化(a collective approach to have a high-minded where we're going to actually differentiate),但现在的牌桌上的筹码垒的太高了,每个人都说,「不,这是属于我的数据,我不会分享的」?
NF: 墙要砌起来了,数据的闸门肯定要关了(The walls are going up, definitely the shutters are down on data),以前爬取互联网的数据可比现在容易。总的来说,「爬数据」已经变得更加困难(scraping has gotten harder),你可以在各个领域看到这一点。因此,我认为一些公司过去并不认为「用户生成内容」(UGC ) 的内容是一种资产,现在突然意识到了这一点。他们说:「等等,我们有这么多可以进行训练的大数据集。」
Ben: 说到了 Reddit 的首次公开募股。
NF: 是的,确切地说。我们不应该让人们随意获取数据并进行训练,要加强爬取难度,并将其视为可能随着时间推移具有一定价值的资产,因此在整体上确实发生了这种情况,而且收集机器人数据成本非常昂贵(the robotic data is so expensive to collect)。关于在模拟中可以完成多少工作还存在一些疑问,但无论如何,你都必须做大量工作来收集数据,我敢打赌,最终会有很多私人数据集相互竞争(my bet would be that there ends up being lots of competing private data sets)。
Ben: 关于英伟达(Nvidia),因为你在「训练与推理」的问题中提到了它,我们就简单说一下。Nvidia 的盈利是爆炸性的,但我对人们的看法有点困惑—Nvidia 供应受限(supply constrained),这意味着实际上他们的盈利在某些方面受制于台积电的产能。我将其比喻为早年的苹果 iPhone。苹果公司每个季度的预测都非常准确,"我们能预测这一点,每个季度都会超出预测的 5% ",原因就在于它受制于运营商的能力,而运营商则保证了当时产品的销售量等。
在你真正拥有足够的供应量之前,你实际上并不知道最终的需求量到底是多少,而 Nvidia 似乎现在就是这种情况。但是,如果你跟 Jensen(黄仁勋)谈,他当然会认为这是个登月项目,几乎看不到上限,他们的产品将用于训练、推理,用于一切计算。我想问,第一,我们离满足需求还有多远,这是否会让—第二,讨论训练 / 推理的问题变得毫无意义,因为现在算力还远远不够?
NF: 丹尼尔可能会对这个问题有一个更好的长期视角,但我会说,根据我们所看到的所有信号以及 Sora 和 Gemini 这些大模型再次进行新一轮规模扩张(another round of scale-pilling)的情况,就我所知,Nvidia 在 2025 年将会销售它能生产的一切。这只是因为有大量的订单正在进行中,世界各地的大公司和小公司都在说:「天那,我们需要加大投入(算力)。」这是令人难以置信的,这就是 Jensen 今天的业务。他所处的情况是,世界上主要公司的首席执行官不得不在推特上发布他们购买英伟达产品的单位数量,以保持行业竞争力。
Ben: 不仅如此,而且 Nvidia 也从英特尔实际上开始运营他们的芯片铸造业务中受益,这使得台积电这个天生保守的公司不敢涨价太多,因为他们最害怕的是失去订单量,所以这就是半导体行业的本质。所以在电话会议上他们会被问到:「你知道 Nvidia 的芯片定价是多少吗?你确定你应该再涨价吗?」但他们不想走得太远,所以 Nvidia 在两方面都处于有利地位,他们是双方的「咽喉」,如果他们最终成为了双供应商(dual suppliers),那就会变得非常有意思。
NF:丹尼尔和我一直在想这个问题。我们一直很困惑,为什么台积电的利润率暂时没有改善?为什么他们没有拿走更多的利润?我想你刚才已经说过了,他们经历了这么多轮的繁荣和萧条,他们已经超越了很多做出错误举动的人。
Ben: 台积电没有习惯成为世界领先的芯片铸造代工企业,这是问题的关键。他们的企业文化,第一,他们所有的领导层,这是张忠谋(Morris Chang)的一大信念,他曾经在美国工作过,他认为这是一个大问题,部分原因是台湾的企业文化心态是成本加成,就像 "我的老板对我很差,我要去隔壁建立完全相同的业务,然后在价格上打败他"。因此,这种心态与台积电曾经一直落后的事实相结合,他们纯粹靠价格竞争而脱颖而出,而现在他们已经处于行业领先地位,实际上他们的利润率提高了很多,价格也提高了很多。虽然还不足以影响他们在整个价值链中的地位,但现在他们会面临的问题是,当他们终于意识到 "对啊,我们或许应该进一步提高价格 " 时,实际上,在三四年后,他们可能真的会面临激烈竞争,现在他们担心的是如何把每个人都留在自己的帐篷里。
DG: 顺便说一句,在这个话题上,我觉得世界上一个非常有趣的错误定价的例子可能就是日本,这一整个国家。
Ben: 我认同。首先,台积电在那里的建设非常顺利,这与亚利桑那州的情况正好相反。他们建立的 28 纳米工厂主要集中在服务汽车公司,因为这是一个明确的市场需求。但我认为台积电从中得到的启示是:「如果我们要持续存在下去,如果台湾垮台或受到攻击,那么日本就是一个更好的文化适应环境,而且日本在制造方面的卓越表现是被人们认可和熟知的。」
现在,我认为政府已经意识到了这一点,他们刚刚宣布了一个巨大的新基金,以投资做更多的事情,而台积电,他们非常渴望以完全相反的方式参与进来,因为他们对亚利桑那州并不是很兴奋。
DG: 是的,似乎,许多组件已经在日本制造,如安进(Ajinomoto)、依必丹(IBIDEN)、UMTC。我以为他们甚至会在那里建一个芯片-晶片基板之类(a chip-on-wafer substrate thing)的东西,我想现在那是在韩国制造的。但我觉得如果你想要把所有的筹码都集中在半导体上,日本是一个非常有趣的地理位置,因为我认为他们最终有能力把所有这些元件都集中在一个国家里制造。
Ben: 我认为你说得对。
Ben: 这确实是我本周写在清单上的事情。我可能在你说出这个观点之前就已经发表了这篇文章,但我完全同意你的观点。
DG: 当我们回顾过去四十年来全球前 20 名的公司时,几乎每次都会看到一些公司名字在那里。显然,微软仍然占据主导地位,但最引人注目的是,当你回顾上世纪 80 年代的时候,显然那是属于日本的十年,这个国家有所有那些日本银行。我想知道的是,如果人工智能爆发真的成为现实,也许 2030 年代就又是日本的十年,如果他们真的能够制造所有这些产业链组件,那些由于各种原因必须从台湾转移出去的。
Ben: 另一个转变是人们没有意识到,芯片制造过去是劳动密集型的,比你想象的更加劳动密集。最初的全球化浪潮始于仙童半导体公司(Fairchild Semiconductor)在香港进行组装,他们实际上是用手工将电线从芯片连接到基板上(connecting wires from the chip to the substrate by hand)。很快,日本在内存领域占据了主导地位,他们基本上把英特尔赶出了内存业务,但他们最终被定价挤出了市场。整个行业崩溃发生了,他们变得回避风险,三星基本上将日本企业赶出了内存业务,因为每次经济下行时期,日本公司都会收缩,而韩国三星会再投资。
但是现在,随着自动化水平的提高和相对劳动成本的变化,更多地涉及到隐性知识和知道如何使机器工作起来,而不是实际的劳动人力成本。芯片制造的劳动成分变得更加高端(the labor component of chips has moved much more high-end),更远离低成本的工作。日本重新成为制造业的非常合适的地方,这在过去的 20 年里并不是这样。
顺便说一句,今天我们不谈论 Meta,但一个被低估的事实是,他们股价跌至谷底的时候,人们忘记这一现象的驱动因素不是因为他们搞了一个 Meta Reality Lab,人们已经知道它的高昂成本了,而是他们的资本支出大幅上升(their CapEx expenditures were going up massively)。所以我当时写道,「实际上,他们需要投资于资本支出,这次的 AI 技术非常重要(they need to be investing in CapEx, this AI stuff is super important)。」这也是 Nvidia 跌至谷底的时期,他们不仅要写掉(write off ) 之前生产的芯片,还要写掉未来从台积电的采购订单。他们必须付钱才能进入游戏,他们不像苹果那样是台积电的忠实客户,他们以前是在三星订购的。

DG: 是的,我想他们是提前承诺入局了。
Ben: 是的他们提前承诺入局了,实际上,利润率在几个季度内是有些虚高的,因为他们卖掉了已经摊销了成本的芯片。但 Meta 收购了所有这些芯片订单,所以他们在其他所有人之前买进了市场上所有的 GPU,他们上个季度披露的庞大计算集群就是因为那个特定季度的投资。在股市抛售 Meta 的那个季度,实际上是他们未来五年中最重要的投资之一。
DG: 哇,我没有听过有人真正把这些事实联系在一起,但这非常有趣。
Ben: 别跟扎克伯格对赌!
DG: 我同意,别跟扎克伯格对赌。
NF: 是啊,说到扩大规模的勇气,扎克绝对是擂台上的佼佼者。
Ben: 是的,但时机也很关键吧?那正好是在 ChatGPT 推出之前的一个月。所以,他们在有任何竞争出现之前就完成了所有的 GPU 购买。我敢肯定,他们支付的价格比现在任何人支付的价格都要低得多。
Ben: 总之,我们必须进入正题。谷歌的 Gemini 模型,有好消息也有坏消息。先说好消息。
我觉得 Gemini 1.5 版本是令人惊讶的,并且像 Groq 这样的验证方式也扩展了我对这些模型的预期。因为这个想法是,「看,只需把你想要的东西全部丢到上下文窗口里,你不需要构建某种 RAG(Retrieval-Augmented Generation 检索增强生成)系统。你不需要弄清楚什么放进去,什么不放进去。」对我来说,这种便利性,是的,速度可能相对较慢,但这在某种程度上是一个巨大的改变,你可以做一些愚蠢的事情。我链接了一条推特,有人在《了不起的盖茨比》(Great Gatsby)中插入了一行文字,并看看它能否找到。就像,「谁会做这种事情呢 ( Who's going to ever do that)」。「谁会做这种事情呢?」这句话定义了最终会成为大事件的新产品,而且我觉得这种可能性,对我来说,这种可能性—是的,从小上下文窗口到大上下文窗口的程度是有差异的,但对我来说,1.5 版本跨越了,它成为了一个巨大的改变,你可以随心所欲地做任何你想做的事情。
NF: 是的,我绝对同意。我认为全世界都很惊讶,因为他们不仅提供了一个很好的模型,而且还沿着一个轴线提供了创新,比迄今为止其他任何人提供的创新都要高出几个数量级,而且似乎真的很有效。事实上,Gemini 1.5 是一个具有长上下文语境的多模态模型(a multimodal model with long context),这也让你有机会做一些事情,比如放入一个小时的长视频并让模型进行推理,或者放入一千个某种案例,现在你不是在微调一个模型,你只是在用大量的例子进行案例分析,它可以学会做一些不可思议的事情。
范阳注:为什么长上下文语境(long context ) 对大语言模型有价值?大语言模型有时候需要更多的上下文信息来做出更准确的预测或生成更有意义的文本。想象一下,如果你只告诉你的朋友一个故事的片段,而不是整个故事,你的朋友可能会感到困惑,无法理解你要传达的意思。同样,如果大语言模型只能看到很短的段落或句子,它可能无法准确理解整个语境,导致它生成的文本可能不够连贯或准确。另外,「长上下文」可以让模型具有更好的「记忆能力」,能够在较长的文本信息中保持一致的语义理解。这样的模型还能够更好地进行推理和逻辑推断,因为它们可以考虑到更多的信息和背景知识,这也跟我们在现实生活中遇见一个记忆力好,逻辑清晰而表述也清晰的人一样。
Ben: 这就像 Excel,Excel 让普通人可以编程。Gemini 让普通人可以微调一个模型(This lets normal people fine-tune a model),你实际上什么都不用做,只是把你所有的东西丢进去,它会自己解决。
NF: 对长语境上下文的押注非常重要(the bet on long context is very important),我们认为,不仅能检索出海量信息,还能对海量信息进行推理,这是一种超级能力,我的意思是,这在一定程度上是人类的能力。我们人类有情景记忆(episodic memory)和程序性记忆 ( procedural memory ),能够随着时间的推移保留技能或记忆,并且一直存在一个问题,「人工智能模型如何做到这一点?它们将如何发展情景或程序性记忆?」 在上下文语境中,你可以做到这两点。
在上下文中,你可以放入模型会记住的情景,你也可以放入技能(you can put episodes in that the model will remember and you can put skills in),就像谷歌实际上通过在一个单一提示内教授模型新的语言,然后要求它使用这些技能所做的那样(teaching it new languages inside a single prompt and then asking it to use those skills)。因此,这一直是一个重要的缺失技能,这可能不是它出现在 AI 系统中的最终方式,但这是一种新的我们可以做到这一点的方式,我认为这是非常有意义的。
你也可以做近似超级人工智能的事情。对庞大的代码库进行推理,向它展示数小时的监控录像,并要求它对这些录像进行关联分析。我认为这是一个了不起的突破,谷歌显然已经发现了一些秘密,而我们也一直在寻找蛛丝马迹,翻阅文献,试图找出其中的奥秘。但这绝对是一个差异化的要素。
Ben:在我看来,我最关心的问题是,其中有多少是模型的因素,有多少是基础架构(infrastructure)的因素?因为去年他们在企业活动上做了一个演示,很奇怪,我找不到这个演示的任何资料,上周我花了几个小时在找。我在写关于 Gemini 1.5 的时候非常明显地记得这一点,他们谈到了这种数据库分片(sharding capability)的能力,我们知道分片是数据库的一种情况,以及它解决的问题和所带来的挑战,但他们在谈论分片时,我记得他们是在讨论用在训练。但似乎他们也在推理的情况下使用分片,他们有这种分布工作负载的能力,不仅仅是跨芯片、跨集群,而且至少在理论上,也跨数据中心(not just across chips, not just across clusters, but at least in theory, across data centers),这带来了巨大的挑战,因为你受到光速的限制 ( which introduces huge challenges as far as you're constrained by the speed of light )。
谷歌的网络能力(networking capabilities)一直以来都是众所周知的,但我不确定人们是否意识到这种优势如何能应用在解决这些问题上。丹尼尔,你谈到了稀疏模型的可扩展性(how much can you make a sparse model),要做到这一点,就要采用混合专家的方法(a mixture-of-experts sort of approach),并将其分散开来。
这与 Groq 正好相反。Groq 的芯片结构是高度串行的(Groq is massively serial),速度超快。如果我们能将其分散到各处,因为使用案例可以容忍延迟 ( What if we can spread it out all over the place and because the use case is tolerable of latency ),我们就可以把这个极端发挥到底。看起来现在只有谷歌才能做到目前 Gemini 1.5 所做的事情,其他公司似乎甚至没有接近的迹象。
DG: 你认为还有其他人接近谷歌的水平吗,Nat?
NF: 嗯,我们知道还有一家公司也有这个能力。
DG: 是的。
NF: 上周,丹尼尔和我投资了一家叫 Magic 的公司,他们有一个非常好的、非常高效的、比 Gemini 还要长的上下文机制,并且正在运作。老实说,我们之前以为只有一家公司有这个能力,现在我们知道还有两家。

范阳注:magic.dev,Magic 官网对自己的介绍。
Ben: 有趣。
NF: 所以可能还有第三家。谁知道呢?
Ben: 有趣。所以谷歌这个能力也许并没有看起来那么强大。
NF: 嗯,当 Magic 向我们展示的时候,我们还是觉得这是一个了不起的成就。
Ben: 本:就用例而言,这是一件大事。如果除了谷歌之外,还有其他人能做到这一点,那就再好不过了, 这点很明确。
DG: 这是一种不同类型的长上下文,我认为就像人类记忆一样,在某种场景下有效使用它的能力,与仅仅重复你一年前听到的事情的能力不太一样。因此,我认为随着时间的推移,就像所有基准测试一样,我们会意识到,「哦,token 大小实际上并不总越大越好,而且并不是对所有事情都一样」,但它是一个非常非常高质量的推理引擎(it's a very, very high quality reasoning engine),这是我对它的看法。这种推理引擎的一个组成部分就是一个非常大的上下文窗口(a very large context window)。但我认为这只是方程式的一部分。
无论如何,除了 Magic 之外,还有一些人,他们要么领先于这个水平,要么距离这个水平也不远,我确实认为,现在还要受限于上下文长度的想法,我们将会像今天的孩子回顾过去在玩电脑游戏时需要在半途更换软盘驱动器一样回首往昔。
我认为这些事情将会变得非常重要,有许多不同的方法,然后我认为下一步,这是 Magic 实际上非常保密的一部分,所以我们可能应该谨慎分享多少内容出来,但这是他们和许多其他人都在思考的事情,那就是能够进行主动推理的能力(the ability to do active reasoning)。
今天的 ChatGPT,甚至是 Gemini,这些人工智能模型更接近于人们(哼唱曲子时)的押韵而不是在思考(these models are a little bit closer to someone rhyming and not thinking)。所以 Magic 团队他们在寻找感觉正确的东西,寻找一种好的技术氛围,而现在没有更好的词形容这是什么(what feels right, what's a good sort of vibe, for lack of a better word)。
Ben: 是的,现在的模型没什么逻辑可言。
DG: 是的,现在的人工智能更接近于说唱歌手 Jay-Z 在录音室里,尽可能快地对着麦克风说话,试图让声音听起来都正确,而不是大科学家约翰·冯·诺伊曼(Jay-Z in the studio talking into the microphone as quickly as possible, trying to get the thing that sounds right out, as opposed to John von Neumann)。事实证明,如果你在整个人类知识体系中都这样做,你最终得到的东西看起来很聪明(if you just do that over the entire corpus of human knowledge, you end up getting something that seems smart),但我们实际上并不确定它是否真的聪明,这就是为什么它在编程和数学等方面有些吃力。
所以,主动推理(active reasoning)是我认为许多人正在为之努力的重要事情,是的,我们已经看到了一些相当引人注目的东西。一切都还处于非常早期的阶段,但如果说人工智能领域今年有一个重大突破的话(if there's a big breakthrough of the year),如果我必须猜测的话,那不会是上下文窗口( context window),而是非常大的上下文与主动推理和自主思考的结合(very large context combined with active reasoning and thinking)。
Ben: 这是否仍然会遇到这样一种情况,我是说你回到上下文窗口,你可以将其与规模扩展问题联系起来(tie it to the scaling question)。也许 transformers 架构,你可以将它们扩展得比你想象的更多,这就足以让你接近(推理能力)。上下文窗口的情况也是如此。只要把上下文窗口越做越大,内存问题不就迎刃而解了吗?因为持久性可以在其中维持。主动推理是否也会如此,它仍然是一个 one-shot 的过程(a one-shot process),还是因为我们已经远离了冯-诺依曼架构(von Neumann architecture),在这种架构下,东西都在内存中,并且被检索然后来回传输,这一切都是 one-shot 方式的(one-shot aspect)。我甚至不知道这将如何发展,我思考这个问题的方式是正确吗?
DG: 是的,我觉得你说得很对,我觉得有很多不同的方法。有一种想法是,如果你能很快推理出一些东西(if you could infer things fairly quickly),你可以让模型,这是最直接的想法,你可以让模型读取它们自己的输出(have the models just read their own output),思考一下,再写一点 ( think about it, write a little bit more )。
然后有一种想法是,你会想,「天哪,如果我们这样去做,为什么还要发出所有这些文本,然后读取所有这些文本呢?我们难道不能在模型权重本身中直接进行这个主动思考过程吗?(Gosh, if we're doing that, why are we bothering to emit all this text and then read all this text? Can't we just do this active thinking process in the model weights themselves)」这是目前研究的前沿和商业机密(frontier of research and the trade secrets),我认为这将决定这些公司的成败。
我确实认为,如果有人真的做到了这一点,那将相当于谷歌在竞争激烈的搜索引擎时代强势推出 PageRank。你必须做出一个优秀的产品,仅靠 PageRank 算法并不能成就谷歌,但这是给他们成为第一的机会,他们至今在搜索领域保持着这一地位。
我认为如果有人能够创造一种能够像人类一样,在他们选择的任何领域中主动推理,以及主动思考问题的东西(if someone had something that had active reasoning and actively thought-through problems the way humans do in whatever domain they choose),那么他们就能领先于别人。
Ben: 你觉得(达到主动推理和主动思考)这是一个软件问题,而不是一个硬件问题吗?
DG: 在苹果公司,有一个有趣的说法是,「硬件人员认为一切都是软件问题。而软件人员认为一切都是硬件问题。」我认为公平地说,解决这个问题可以更容易些,我认为可以用软件解决,而不是用硬件解决。
Ben: 从创新的角度来看,这是好事儿,因为对于初创公司来说,通过软件解决问题,比着手解决基础设施的限制更容易上手,否则就不好办了。
DG: 如果我们是一个足够先进的文明,能在几秒钟内随意变出任何节点大小的芯片,也许我们都能随意做到这些事情。但实际上,这个问题现在也是可以解决的,我认为这将在软件中得到解决,因为软件是系统中可塑性更强的部分(it will be solved in software, because that is the more malleable piece of the system),我认为这最终只是一个数学问题(I think it is just a math problem at the end of the day),人们不喜欢听到这些,因为他们喜欢相信其中存在一些深刻的人性之类的东西,但即使是这些想法,我的意思是最终是可以表示为一个数学问题,也是有可能的。所以我们认为可能今年会解决这个问题,如果(主动推理)真的发生了,这可能会成为年底的标志性事件。
Ben: 我们又回到了哲学层面的辩论,Nat。
NF: 是的。我的意思是「思考」是一个机械过程,机器将会开始思考(thinking is a mechanical process and machines are going to do it),我仍然非常坚信这一点。最近我见到的事情让我更加相信了这一点,如果这种可能成立的话。
Ben: 我期待着看到能思考的机器。

Ben: 我们把最有料的话题留到了最后。Gemini 的另一个方面是—另一个方面是,实际上,我今天和约翰-格鲁伯(John Gruber)一起参加了 Dithering 节目,我觉得他说得很好。谷歌的人工智能大模型 Gemini 1.5 之所以在发布后如此让人反感,是因为它给人一种不诚实的感觉(The reason why Gemini as it shipped feels so distasteful, is it feels like bad faith),明摆着就是 "我们并没有尽最大努力给你答案"(We're not actually doing our best job to give you an answer)。这表现得很直接,而且感觉像是一个我们会原谅人工智能出错的方面,我们一直在原谅 OpenAI,他们的早期版本显然存在倾向性问题,但他们已经解决了这个问题。但是,Gemini 1.5 似乎并不是出于善意(doesn't feel like it's in good faith),也许这是一个意外,但它越过了人们认知的底线,这看起来很有问题。
很迷惑这一切是怎么发生的?我们如何从一个本来很谨小慎微发布产品的大公司得到了这样一个产品,最终成为一场公众灾难?
NF: 嗯,我认为你说得对。他们不应该像 OpenAI 那样得到太多的宽容,一个原因是他们看到了前人的经验,却没有从先例中学到任何东西。OepnAI 的图像生成人工智能 Dall-E 2 有自己疯狂的「觉醒主义」图像创建问题(crazy woke image creation problem),他们不得不进行整治和微调,并从中吸取了教训,这都是可以原谅的,因为他们是这个领域的先驱,ChatGPT 也经历过这样的事情,所以 Google 本来应该看到过所有这些发生过的事情,并从中学习,做得更好。
范阳注:觉醒主义(Wokeism)是一个用于描述一种社会和政治意识形态的术语。它源自英语口语中的「woke」一词,最初是指对社会不公正和种族歧视的觉醒或认识到的状态。而现在在西方社会,因为矫枉过正,也有很多人使用它来批评对政治正确和身份政治的过度强调,或者对于取消文化和极端政治正确的反感。
Ben: 你这点说的很好。这是每个领域先行者的一个巨大优势,因为你会得到更多的谅解(a big advantage of going first, is you get more grace)。
NF: 是的,你会得到更多的谅解,因为之前没有人解决过这些问题。但是谷歌显然并不是第一个,仍然犯了感觉像是 2021 年或 2022 年的错误,这就不那么容易被原谅了。
怎么会发生这种情况呢?我认为文化是一个非常重要的因素。你写过这方面的文章,很明显,谷歌内部很难有人举手说,「嘿,我觉得我们不应该以这种形式发布,我们应该做些什么来解决这个问题。」
此外,我们从谷歌的一些员工那里听到,这些模型本身,这不太可能是模型训练中的一个深层问题,而更像是后来某个人在产品化过程中做出的决定。因此,可能存在一套系统提示或模板(a set of system prompts or templates),或者类似的东西,强加了一组规则和指导方针给模型,而原始的内部模型并没有做成这个样子。
我认为这就是挑战所在。谷歌一直有一个有趣的词汇,用于描述产品发布,他们称之为「外部化」(externalization)。我一直认为这是谷歌文化的一个非常具有指示性的术语,因为它在某种程度上捕捉到了谷歌对自身的看法。他们在内部开发突破性的技术,然后将魔法「外部化」,这不是以产品为先的思维,甚至不是以客户为先的思维,而是以技术为先的思维。我认为错误就在这里,在把技术「外部化」过程中。
因此,在某种程度上这个问题也很容易修复,可能只需编辑一个文件就可以极大地改善情况,但另一方面,编辑该文件可能意味着需要经过多层产品人员和政策人员的审查,他们可能会对此有很多意见,而在创建模型的杰出头脑与用户之间存在着一道隔阂(the gulf between the brilliant minds creating the models and the users),而这其中的「中间人」们就是挑战所在。
Ben: 你认为这到底是如何发生的,Daniel?是数据层面的问题,还是模型,还是 RLHF(人类反馈强化学习)过程,还是提示工程的原因,到底哪里出了问题?
DG: 嗯,我们之前有一个很好的讨论,针对这个问题。我认为传统上有一些人们有点误解的地方。对模型进行预训练和微调模型并不是完全不同的概念(Pre-training and fine-tuning a model are not distinct ideas),它们在某种程度上是相同的。微调只是在模型训练结束时进行的更多的预训练(fine-tuning is just more the pre-training at the end)。在你训练模型的过程中,我认为这是我们所相信的,现在也得到了很多科学证实,信息的排序非常重要(the ordering of the information is extremely important)。因为看,对于像如何正确标点一句话这样的基本问题,你可以用任何方式来解决。但对于更高敏感度的事情,模型的美学(the aesthetic of the model)、模型的政治偏好等等,那些并不是完全二元的领域,事实证明信息显示的顺序非常重要(the ordering of how you show the information matters a lot)。
在我的脑海中,我总是想象成,你在试图在床上拉一张非常紧的床单,那就是你的嵌入空间(embedding space),你把床单拉到右上角,底部左角就会弹出,你这样做,然后右上角也会弹出,这就是你要做的事情。你试图将这个高维空间对齐到一组特定的数学值(align this high dimensional space to a particular set of mathematical values),但在某个时候你永远不会得到一个完美的答案或零损失。所以,顺序很重要,传统上微调更多是在预训练的最后阶段进行的。
我认为这最初是由 OpenAI ChatGPT 模型的自由主义倾向(the liberal leanings)产生的。我认为这是一个相对无害的副产品,因为在向模型展示最终数据点时,模型会变得非常敏感,而这些数据点很容易意外地产生偏差。举例来说,如果你在内部软件中设置了几个单词,向人工分级人员提示他们应该将哪些标记写入模型,这些单词就会使他们产生偏差,如果分级人员能看到其他分级人员的结果,就会产生这些反射过程。这就像共振频率,很快就会复合叠加起来。错误会随着时间的推移而复合叠加。我认为你可能会在不经意间得到一个稍微政治左倾的模型,因为很多在线文本都是稍微政治左倾的。
Ben: 很有意思的是,即使是愚蠢的观点,比如关于肉或出售金鱼 ( meat or selling goldfish ) 的观点,我认为「出售金鱼」可能是我最喜欢的观点之一。就像,「不,我不会出售生命(I'm not going to sell being)。」这真是滑稽,我用 Nate Silver 的推特作为锚点,就像旧金山监事会一样,但并不是有一个观点是不合适的。这说明了你的观点,这就是这些模型的工作原理。如果在模型训练最后阶段输入了特定的一小组信念,它就会无缝地扩展到整个集合。
DG: 完全正确。无论 Gemini 或者其他的模型发生了什么,我们都会观察到这些模型,它们都包含在一个潜在地下的「荣格平面」上(a kind of subterranean Jungian plane),这些平面会自动地调整彼此。模型没有做错任何事情,它只是反映了我们人类的所作所为,结果表明这些东西会物以类聚(they cluster into similar buckets)。

范阳注:之前在小红书上看到这张 meme 图,最上方的是「荣格心理学」(在小红书上也俗称荣格的「红书」)。上面文章里的对话提到了「有一层潜在模型里的荣格平面」,我认为很有意思,这里引用荣格是描述人工智能大语言模型内部的一种隐秘的、潜在的、深层次的联系。它源自心理学家荣格(Carl Jung)的理论,也就是「集体无意识」的概念,认为人类共享着一种潜意识层面,其中包含了普遍的符号、图像和经验。因为大语言模型从人类的知识库里学习,所以模型内部也存在着某种深层次的联系,就像人类的潜意识一样,它们彼此自动调整,而且这种联系也许是在「它们」或者「我们」意识之下的。
Ben: 这就是人类政治的运作方式,对吧?
DG: 是的。没有人愿意公开说这些。
Ben: 嗯,没有人能够研究和理解世界上的每一个话题。
DG: 当然。
Ben: 所以,你可能会有几个你真正理解的理念。所以,你的核心理念要与其他人的核心理念对齐。我们已经看到了,这就像是《政治学 101》,这些模型也是这样工作的。我想这是我第一次在 Stratechery 文章里用上我的政治学学位,但不管怎么说,请继续。
DG:(笑)这变得非常重要!我在想宗教改革,因为我认为在 1517 年,马丁·路德写了 95 条论纲,通过印刷术,他设法创立了一种在欧洲传播的新宗教。在某种程度上,每个人都在想着,试图将 ChatGPT 与印刷术进行类比,但实际上它们起到的作用几乎相反。
整个过程都是在相反的方向上进行的,印刷术是一种通过书籍传播信息、说服人们做事的技术(the printing press was a technology to disseminate information through a book basically and convince people to do things),而大语言模型则是一种「反书籍」技术(the kind of antibook is the LLM agent),它非常简洁地总结了事物。如果确实是这样的话,它能唤醒人们意识到他们长期以来一直是宗教的同谋,因为它非常简洁地为你总结了这些事情,并将所有事物放在隐藏空间中,突然你意识到,「等一下,这个素食主义概念与另一个概念息息相关。」在某种程度上,大语言模型技术是一种反向的宗教改革(a kind of Reformation in reverse),每个人都突然意识到了有很多事情是错误的。
Ben: 这真是一个精辟的见解,Daniel。我是说,这捕捉到了—现在流传着一个笑话,「看,你知道某个右翼挑衅者没有破坏这一切的最主要原因是,他们根本不够聪明去如此有效地做到这一点」。因为就像是,「看,你以为所有这些都是不相关的东西,让我们把它们都放在一个包裹里呈现给你。现在,你觉得怎么样?」。
DG: 完全正确。因此,它剥夺了任何意识形态的微妙之处,直截了当地摆在你的面前,是的,人们对此有反应。我认为最有趣的信息是,谷歌缺乏一个非常基本的流程。这就是你的观点,也许人们在推出模型之前想过,也许人们压根没有想过,我在想很多人都知道的史蒂夫·乔布斯的那个著名的采访,他说,「微软的问题就是他们没有品味。」我认为人们对 AI 的意外之处,我们在这个播客中谈到过,但我认为人们普遍没有预料到的是,微调一个模型与制作网站的漂亮登陆页一样,是一种审美艺术(fine-tuning a model is just as aesthetic an art as making a beautiful landing page for your website)。
因此,事后来看,建立了谷歌云平台(GCP)界面的 Borg 们,也产生了非常机械化的人工智能模型,这不应该令人感到惊讶,而 Mistral,一个拥有法国文化和法国风格产品的法国 AI 创业公司,能够生产出一个,值得称赞的模型,我是说,它可能不是最聪明的模型,但至少在我的个人测试中,它相对循规蹈矩,它的政治语气也非常中立,这也应该不足为奇。
Ben: 好吧,事实上,我想稍后谈谈 Mistral,但是 Nat,谷歌现在该怎么办?
DG: 除了给你打电话?
NF: (笑) 是的,我的意思是,我认为这是一项领导力挑战。他们缺少一个主编(a missing editor),缺少一个产品主编(a missing product editor),缺少一个有品味和判断力的人,一个在公司中有权利否决任何人并确保正确事情的人。我认为领导层的改变必须发生,文化是公司中最难改变的一种。你可以进行战略变更,产品变更,运营变更。文化变革是最困难的,只有通过领导力才能实现。我们要么需要看到谷歌领导层有明显不同的行为改变,要么需要看到完全不同的领导者。
Ben: 这就是我写这篇文章的原因。有理由质疑谷歌 CEO Pichai 是否是合适的人选,有典型的"战时 CEO" 和 和"平时 CEO" 之分,他是和平时期 CEO 的典范,他做得很好。这并不是要贬低他在 2010 年代对谷歌的领导,聚合器时代 ( the Aggregator era ),让当权者满意,不想招惹他们,这是符合他们利益的。他们设法在诸如审查制度之类的事情上从未受到批评。在互联网上,他们会受到些批评,但在国会里,Facebook 承受了所有的箭,谷歌只是顺利地漂浮过去,Pichai 做这些事情非常有效。我们会抱怨他站在国会前,没人能念出他的名字,但这是一个优势,实际上是一件很好的事情。
这不是谷歌现在需要的,谷歌需要一位战时 CEO,这就是现在大概的情况。我认为我们这一集对话提供了一个非常具体的时间点,在这个时间点上,这种特定的领导风格让公司彻底失败了。这不仅辜负了他们的未来,也危及了他们的现在。
NF: 实际上,这是一个真正的机会,因为当你犯了足够大的错误时,你就有机会真正改正。一系列小错误很难做出重大改变,但当你显然失败时,我认为 AI 是一个令人兴奋的事物,因为它让一些原本难以注意到或容易隐藏的事情变得清晰可见。在过去的一周里,AI 让谷歌的一些文化方面的问题变得非常明晰可见,所以现在就像是,「天哪,有一堆肮脏的内幕被暴露在阳光下,现在某人,我不知道是谁,但某人有机会真正利用它来推动变革,这是必要的」。这不仅仅是关于推出产品(shipping)的问题,而是关于推出的产品应该是人们想要使用的,这才是大问题。
Ben: 产品本身如果不是他们优先考虑的。这就涉及到了注入「恶意」的问题(bad faith issue)。
NF: 嗯,我确实要赞扬谷歌团队发布产品的能力,我确实认可这一点。我认为很有趣的是,Gemini 1.5 在 Gemini 1.0 之后推出的如此之快,他们选择将其标记为 1.5 而不是 2.0 版本号,他们在 Ultra 准备好之前发布了 Pro,他们发布了很多东西。我认为他们至少打破了静态摩擦(break the static friction),但很明显,他们的目标偏离了,而他们的目标偏离是有深层文化原因和组织原因的。我敢肯定,DeepMind 团队和 Gemini 团队与此事毫无关系,发生这样的事其实很可惜。
Ben: 是的,我无法想象这会有多么令人沮丧。嗯,这是另一个问题,他们会因此失去一些员工。「我建造了这个令人难以置信的人工智能模型,而公司的另一层人却允许去破坏它。我为什么要花费我的所有时间在这里工作?」
NF: 嗯,挑战在于所有这些方面,谁是他们共同的汇报人?我认为可能是 谷歌的 CEO Sundar Pichai,所以他必须真正行使领导力。当你拥有像这样庞大的公司时,挑战就在于事情很容易掉入缝隙里,你会看到组织的分歧。
我也认为有些原因是这个领域还很年轻,我们面临的挑战是,语气是一个设计问题(tone is a design problem),这个行业还处于早期阶段,我们缺乏设计工具,缺乏个性化的 Photoshop 等工具,这些工具可以在工作中更明显地显示这些问题。但是这些问题本应该是显而易见的,这是太过显眼了。因此,我认为这对某个人来说是一个领导机会。可能是 Sundar Pichai,也可能是其他人。
Ben: 你提到了 Mistral,他们本周刚发布了一个新的大型模型。我还没有太多写过他们,但首先,你已经对他们的产品进行了初步评估,我还觉得有趣的是,他们在这个过程中还宣布了一个新的投资者,那就是微软。这是对微软与 OpenAI 情况的一个很好的回应,因为微软有什么?他们有钱,他们可以非常明确地分散他们的赌注,现在他们已经参与其中,并且还向 OpenAI 发出一个信号,就是,「看,虽然我们现在非常依赖你,但我们会努力确保今后不再是这样」。
NF: 是的,我认为微软的 CEO 萨蒂亚 ( Satya ) 知道他的所有鸡蛋都放在一个篮子里,他正在非常明智地努力确保这种情况不会再发生。我们之前也见过他这样做。他与扎克伯格合作进行了最初的 Llama 模型开源,并通过 Azure 提供了云服务。现在他有了 Mistral,Mistral 是当前备受瞩目的开源人工智能模型领导者,我认为他们的执行速度和品味都非常令人印象深刻,就像丹尼尔说的那样。
Ben: 他们为什么做得比 Llama 好得多呢?
NF: 这很有意思。我认为他们最初就是 Llama 团队,所以我认为他们有几点优势,Mistral 具有初创公司的敏捷性,我认为这点很重要。也许他们还有一些「有益的」限制。他们只有有限的资本,只有有限的计算资源,所以他们会着手解决这些约束条件。
Ben: 也许也因为他们雇不起那么多的模型调优者(fine-tuners)。
NF: 对吧?嗯,这是肯定的。毫无疑问,我们之前谈到的 Mistral 非常关心的一件事情就是数据的质量,我们知道他们非常努力地清理他们的训练数据,并且通过这样做有效地获得了 "计算倍增器" ( a compute multiplier ),从而获得了 "质量倍增器" ( a quality multiplier )。但现在他们的模型表现远远超过了他们的权重,感觉几乎像是一个魔术。
他们的新 Mistral 大型模型在评估中表现非常出色,他们还没有完全透露是什么,也许是 Mistral 中型模型的混合专家模型之类的东西(MOE mixture of Mistral mediums)。但天哪,这真的令人印象深刻,所以我认为这里只是有很多的敏捷性,有一个真正的硬核团队,他们有很好的品味和判断力,到目前为止,他们做出了非常出色的决策。
Ben: 顺便问一下,模型的评估测试是如何进行的(How do evals work)?每个人都会公布这些测试数据。什么是一个好的模型?什么是不好的模型?
NF: 嗯,这是一个有趣的话题,我很关心。看到所有这些公司的 CEO 都在吹嘘他们的 MMLU 参数指标(MMLU number, 大规模多任务语言理解基准)是很有趣的,而 MMLU 是丹·亨德里克斯 ( Dan Hendrycks ) 在大学本科时自己开发的一个评估。所以你基本上是看到万亿美元公司的 CEO 在谈论他们在一个本科生推出的测试中的分数,而这是目前最重要的推理评估(the premier reasoning eval)之一。
我认为如果你放眼整个人工智能领域的进展,我们就会看到在模型方面取得了令人难以置信的进展,在像 RLHF(基于人类反馈的强化学习)这样的人工智能对齐工具(alignment tools)方面也取得了令人难以置信的进展。产品终于有了真正的发展,我们看到了很多产品,甚至政策制定者都非常兴奋。但有一项进展似乎落后得最远,那就是对模型的 "评估"(evals)。"评估 "基本上是对模型进行测试,看看它们能做什么、不能做什么,看看它们的行为是怎样的,这样你就能在发布前对其有一定的了解,这是一种典型的低声望活动。就像基准测试一样,对吧?但它在业内影响巨大。当新的基准出现时,人们都希望能与之匹敌。
我认为我们目前面临着一系列挑战。首先是,很少有好的公共评估指标 ( very few good public evals ),即使有一些,比如 MMLU,它们要么不能真正预测某些类型的能力,要么接近饱和。我的意思是,在 MMLU 上,现在有人的分数已经达到了 80 分,而使用多次测试(multi-shot)的情况下,有时甚至可以达 90 多分,所以你的基准已经饱和。事实上,所有的基准在发布几年后都趋于饱和。这真的是一个缺憾。
我记得安德烈·卡帕西(Andrej Karpathy)曾经告诉我们,他唯一信任的模型评估是 Twitter 上的评估。在模型发布后,你可以在几周后检查 Twitter 上的用户情绪,看人们是否喜欢它。但每个公司的 CEO 都在训练这些大模型时,说:「我们必须站在榜单榜首。」顺便问一下,这个榜单是什么?这个榜单是一些本科生凑在一起弄出来的东西,是伯克利的人组织的 Chatbot Arena。
Ben: 这些评估方式没有丹尼尔一直认为重要的那些部分,比如品味、语气和给人的感觉。
DG: 顺便说一句,用人类进行模型评估并不容易。为什么我们认为用模型来评估模型很容易呢?我们现在已经到了这样一个阶段,不再是在讨论 GPT-2 是否能写出超过三段的文字的问题了,模型已经足够好,评估成为了一个深层次的问题。Pearson 是一家庞大的公司,他们的一部分工作是创建评估人类的系统和方法,但是这些并不存在于人工智能模型中,但其实应该存在。
范阳注:Pearson 是一家全球性的教育公司,专注于教材、教育技术和评估服务,提供各种教育资源和解决方案,包括教科书、在线学习平台、考试和评估工具等。
Ben: 是否在 OpenAI 这个组织中,我们低估了 Sam Altman?还有其他人是否被低估,这个组织中有一种人们能感受到但可能无法衡量的产品感觉 ( some sort of product sense ),但实际上我们仍然低估了它的重要性?
NF: 我会选 Greg Brockman。我认为 Greg 实际上是那里的一个主要推动者,他有出色的品味。
Ben: 他以前是 Stripe 公司的人,Stripe 在产品和品味方面是一个众所周知的出色公司。
NF: 是的,他曾在 Stripe 工作过,在 Stripe 做了很多了不起的事情。Stripe 在早期的招聘活动中做的一件事,大多数人可能不记得,但是 Stripe 为安全性启动了一场 CTF(capture the flag,夺旗赛),这是 Greg Brockman 策划的,非常精心的策划,真正吸引了非常聪明的人才,Greg 具有极好的品味、判断力和产品落地能力。我认为他对他们的 CUDA 内核和训练代码也有很深的研究,但我认为他这个人非常有能量,也有很强的产品意识,当然,我认为还有很多其他人也参与其中。Sam Altman 显然知道一个公司这一切何时运行良好,毕竟他参与了很多初创公司。但如果你问谁在这方面被低估了,我可能会选择 Greg。
Ben: 嗯,这几个月可谓是重要的时刻。接下来我们应该关注什么大事件呢?是 GPT-5 即将问世,还是我们根本不确定有没有 GPT-5 ?会不会突然冒出类似上周 Groq 那样的东西?再次,Groq 就是一个经典的例子,这家公司已经存在了很多年,但突然间取得突破了。我的问题是 "谁知道呢?",你们认为下一步会发生什么?
DG: 嗯,我很好奇听听 Nat 会怎么说,但也许我先提出一个想法。我认为我们现在处于一个奇怪的过渡时代(we're in an odd tweener era),我认为,对于我们今天拥有的人工智能模型,要想以真正有经济价值的方式(in truly economically valuable ways)使用它们,就需要建立一个围绕它们的产品,需要有像 Nat 和他的团队在 GitHub 时期所付出的那种大量时间和对产品的关注度,来优化模型,使其更快速、更小巧(faster and smaller),真正把模型做到适合 Copilot 产品之类的东西。这就是我们现在所处的范式,我认为这种情况仍然如此。
范阳注:Nat Friedman 以前是 GitHub 的 CEO, Copilot 是一种基于人工智能的编程辅助工具,就像是程序员在编程时候的个人助理。它使用了大型语言模型,如 GPT(生成式预训练模型),来为开发人员提供实时建议和代码片段,以帮助他们更高效地编写代码。
在另一端是这样一个世界,我们拥有的这些 AI 模型会像代理一样行动,不需要像人类那样的接口。我们通过 Slack 和 Gmail 与同事互动,这完全没问题。如果我要猜测,今年某个时候我们会朝着这个方向迈出更大的一步,我们会有更多的人工智能同事而不是人工智能合作者(we have more coworkers than copilots)。这是 Nat 的说法,我在这里借用了他的话,我认为这非常有远见,这将是一个重大事件,我不知道它会来自何方。也许它会来自 OpenAI,也许来自 Magic,也许来自 DeepMind,但我认为这是行业正在努力实现的重大目标。你同意吗,Nat?
NF: 是的,我认为这是正确的,我完全同意。我感兴趣的是推理(I'm interested in seeing is reasoning),我感兴趣的是有人重新定义人工智能的推理能力是什么(some better definition of reasoning),一种衡量推理的方法,以及对推理的市场改进,无论是 Daniel 所说的主动推理(active reasoning),还是以某种方式为模型生成训练数据,使它们能够更直接地学习推理模式 ( somehow a way of generating training data for the models that allow them to learn patterns of reasoning more directly ),或者是对这些模型的推理能力进行衡量的方法。
现在我们尝试着挖掘一下,看看它们的推理能力如何,但我认为直接取得进展会是一件非常重要的事情,而且在该领域有一种信念,即这可能源于如何在文本上进行强化学习的方法(figuring out how to do reinforcement learning on text)。我认为这可能是一条潜在的路径,但总的来说,我认为一些直接改进模型推理能力的方法,然后看到实际得到改进,我们能得到真正的逻辑思维和良好的结果 ( real logical thinking and good results ),这是非常重要的。
Ben: 这一切仍然是在更广泛的 transformer 架构背景下进行的,只是在边缘开始工作,将一些东西重新整合起来?
NF: 是的,似乎计算机行业的演变一直都是这样的,你从某个地方开始,然后随着时间的推移不断建设和进化。
Ben: 我本来想提一下 x86(英特尔推出的用于个人电脑的处理器架构),比如 CISC ( 复杂指令集计算机 ) 架构与 RISC(精简指令集计算机)架构,对吧?
NF: 没错。
Ben: CISC 的架构并不是最好的方法,但一旦你领先了两年,你就领先了两年。
NF: 是的。我认为在人工智能时代也可能是这样。
Ben: 路径依赖是个重要的问题(Path dependency is huge)。
NF: 是的,我们是路径依赖性的,人们只是想办法在训练前或训练后添加所需的东西,或者他们可能会在一些模型上再添加一些架构(they bolt on some model architectures)。我不知道,这是目前大部分人工智能领域的研究方向。大部分的研究并不是关于基础性的新架构(most of the research is not fundamental new architectures),所以从概率上讲,你期望的进展发生在对现有架构进行扩展的领域。但我们也要关注,有一些不是基于 transformer 架构的,一些正在被研究的有趣和有前途的领域。但我最关注的进展方向肯定是推理。
Ben: Nat、Daniel,很高兴有你们的参与。我期待着在未来某个时候再次邀请你们,那时候可能会有足够的变化值得谈论。
DG: 太好了。感谢你邀请我们,Ben。
NF: 谢谢,Ben。
本文来自微信公众号“Founder Park”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
