# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
又一个国产多模态大模型开源!
XVERSE-V,来自元象,还是同样的无条件免费商用。
此前元象曾率先发布国内规模最大的开源大模型,如今开源家族系列又多了一个。

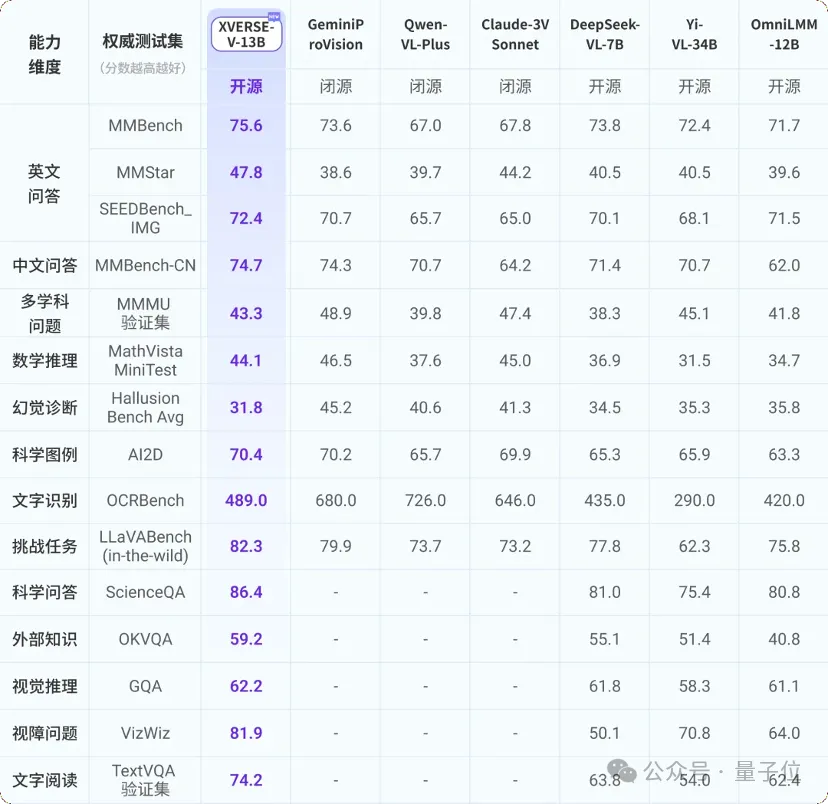
最新的多模态大模型支持任意宽高比图像输入,在主流评测中保持着效果领先——
在多项权威多模态评测中,XVERSE-V超过零一万物Yi-VL-34B、面壁智能OmniLMM-12B及深度求索DeepSeek-VL-7B等开源模型。
在综合能力测评MMBench中超过了谷歌GeminiProVision、阿里Qwen-VL-Plus和Claude-3V Sonnet等知名闭源模型。
传统的多模态模型的图像表示只有整体,XVERSE-V 采用了融合整体和局部的策略,支持输入任意宽高比的图像。
兼顾全局的概览信息和局部的细节信息,能够识别和分析图像中的细微特征,看的更清楚,理解的更准确
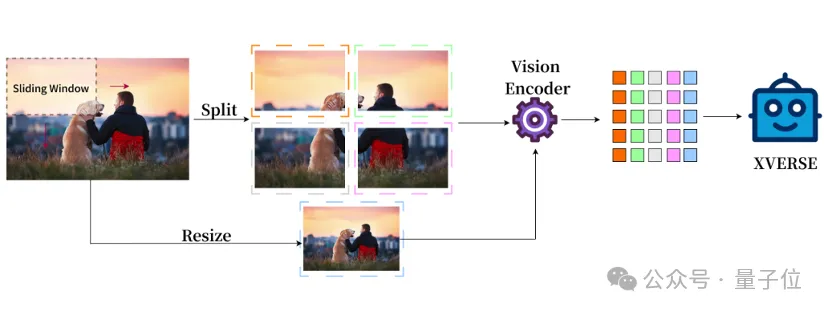
这样的处理方式使模型可以应用于广泛的领域,包括全景图识别、卫星图像、古文物扫描分析等。

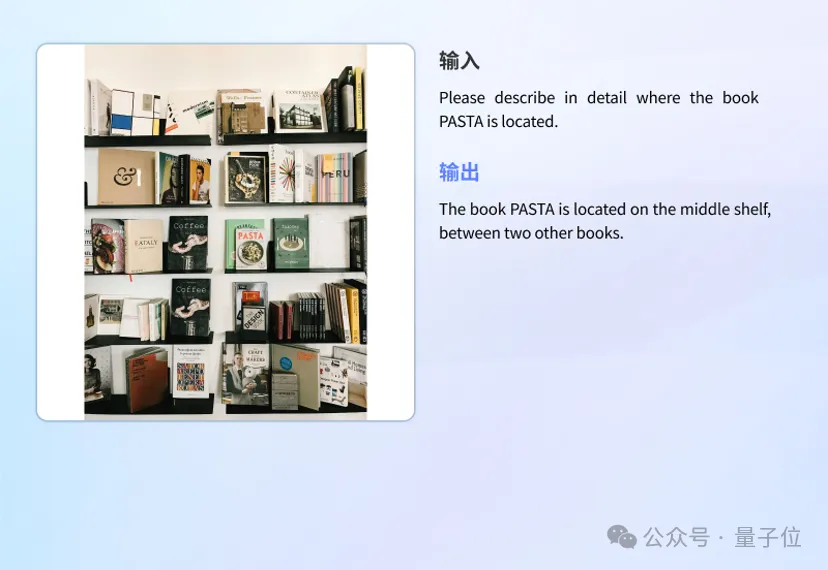
除了基本能力表现不错,也能轻松应对各种不同的实际应用场景,比如图表、文献、代码转化、视障真实场景等。
图表理解。
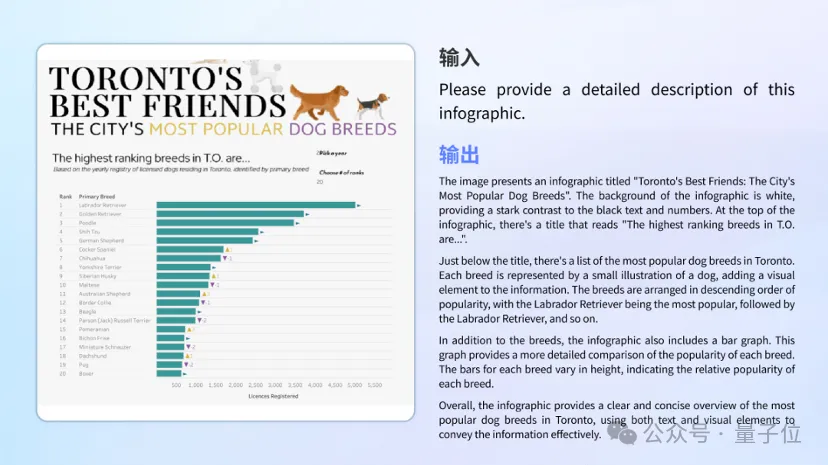
不论是复杂图文结合的信息图理解,还是单一图表的分析与计算,模型都能够自如应对。
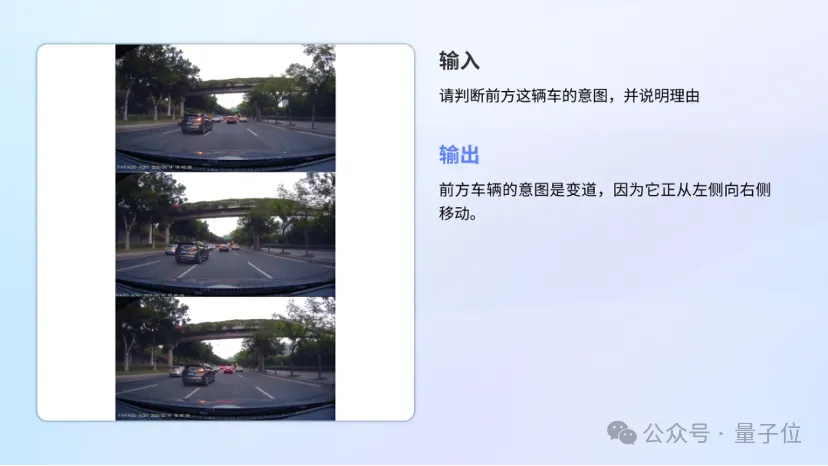
自动驾驶。
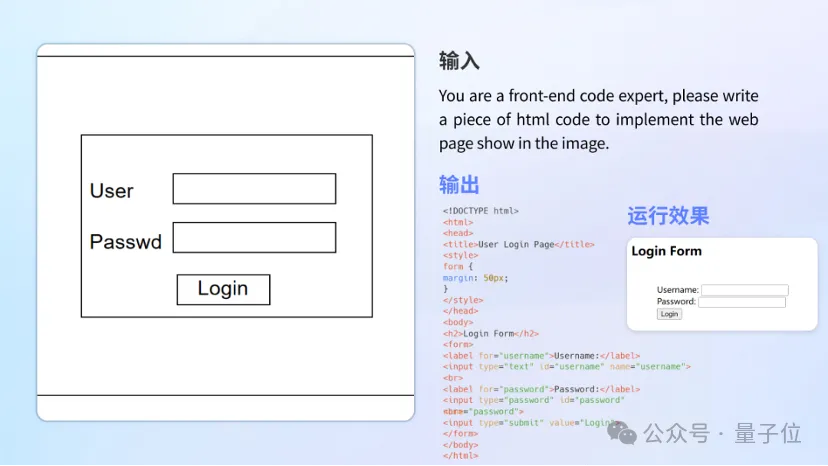
代码撰写。
还有视障真实场景。
在真实视障场景测试集VizWiz中,XVERSE-V的表现超过了InternVL-Chat-V1.5、DeepSeek-VL-7B等几乎所有主流的开源多模态大模型。该测试集包含了来自真实视障用户提出的超过31000个视觉问答,能准确反映用户的真实需求与琐碎细小的问题,帮助视障人群克服他们日常真实的视觉挑战。

元象XVERSE于2021年初在深圳成立。累计融资金额超过2亿美元,投资机构包括腾讯、高榕资本、五源资本、高瓴创投、红杉中国、淡马锡和CPE源峰等。
元象创始人姚星是前腾讯副总裁和腾讯AI Lab创始人、国家科技部新一代人工智能战略咨询委员会成员。
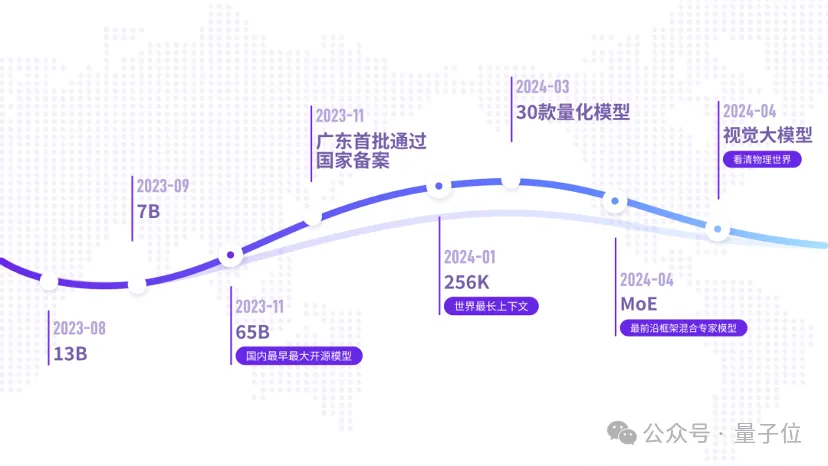
此前,元象在国内最早开源最大参数65B、全球最早开源最长上下文256K的MoE模型, 并在SuperCLUE测评全国领跑。
商业应用上,元象大模型是广东最早获得国家备案的模型之一 ,可向全社会提供服务。
元象大模型去年起已和多个腾讯产品,包括QQ音乐 、虎牙直播、全民K歌、腾讯云等,进行深度合作与应用探索,为文化、娱乐、旅游、金融领域打造创新领先的用户体验。
本文来自微信公众号“量子位”



【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
