# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
好了,别骂诈骗,我全都招!
现在登录通义App(原通义千问),选择全民演唱功能,只需上传任意一张人物正面大头照,你也能玩儿了。
这个功能开放不到一周时间,但经量子位观察,还挺火。
热度一直没掉下去,关键是生成时间也跟热度一起高居不下,顺利的话几分钟生成的小视频,挤的时候排队能排出好几个小时开外,亏得是阿里云服务器没被挤爆(不是)。
从国内外的网友分享反馈来看,大家还挺喜欢文艺复兴,最受欢迎的片段是让个路人马轮番演唱《野狼Disco》。
除了唱歌,还能把朋友放进(非)著名表情包念台词。
玩儿梗的人太多,以至于马斯克都给搞EMO了。
而这背后的“始作俑者”,就是来自阿里通义实验室的EMO,继Sora之后热度第二高的AI视频项目。
如今一个月过去,星标数已经直奔7k而去。
趁此热度,我们也得到了一个与EMO背后大佬,阿里通义实验室XR实验室负责人薄列峰当面催更的机会。
他表示在放心把技术开源之前,首先还是要解决安全问题。
距项目公开仅2个月,通义实验室团队就直接将这一技术免费开放,但所有人都可以在通义APP(原通义千问)体验全新的AIGC玩法。
如果你想亲自上手试试,打开对话输入“EMO”直达或进入“频道”选择“全民舞台”即可。
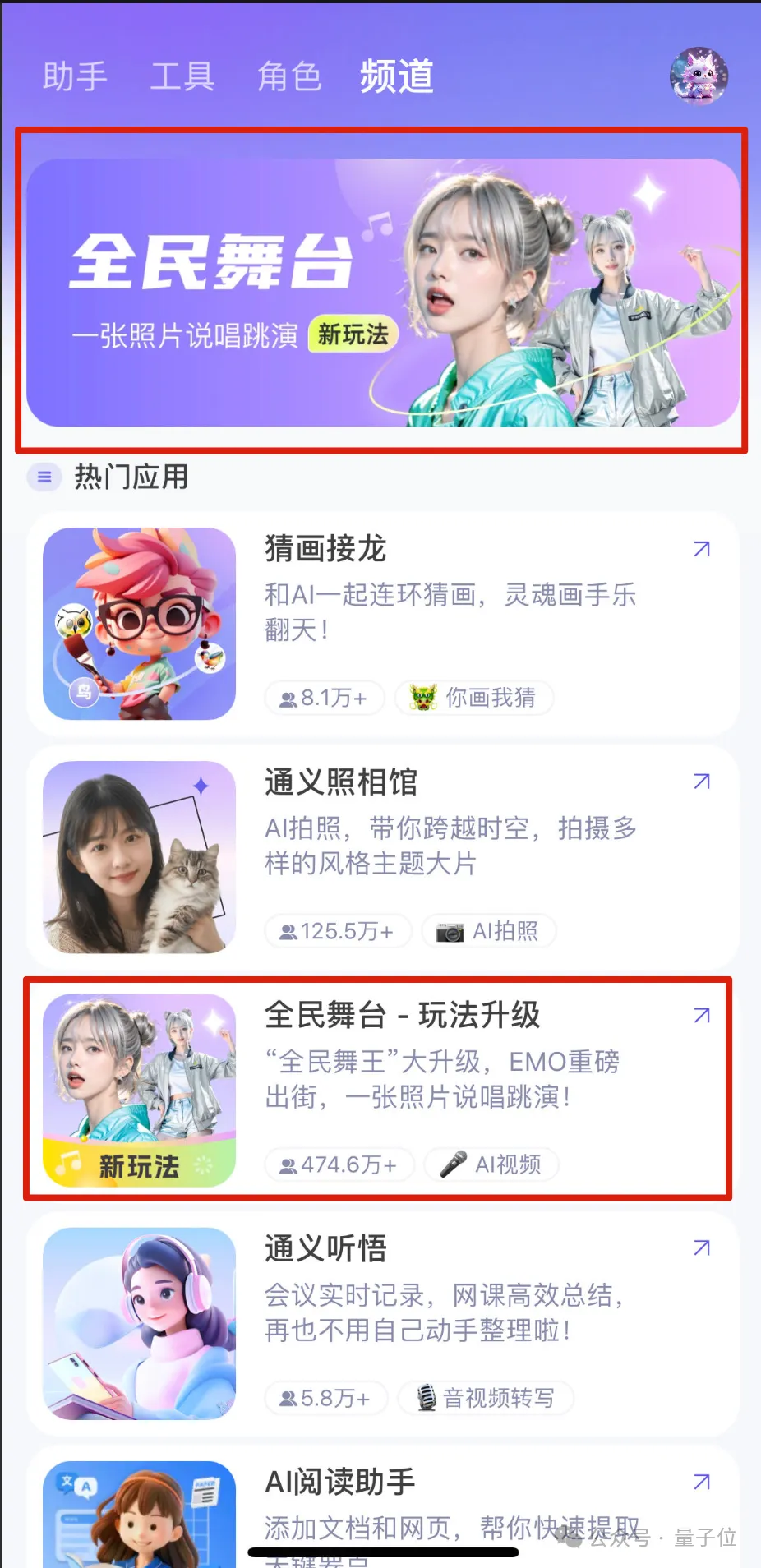
选择喜欢的音频片段,并上传一张大头照。
如果在热门时段,需要等待40分钟到几个小时不等,但其实主要是在排队。薄列峰透露,单纯生成10秒视频,只需要10-15分钟。

对于上传的照片,系统首先会进行人脸检测,不过有些长得太像人的动物也能顺利蒙混过关!
比如撞脸莫言的小狗,就成功地骗过了系统。
但是撞脸余华的小狗就没那么幸运了,系统一下子就把它给识破了(没有任何对余华老师不敬的意思)。

为什么只需要上传一张图就能立即做到逼真效果?
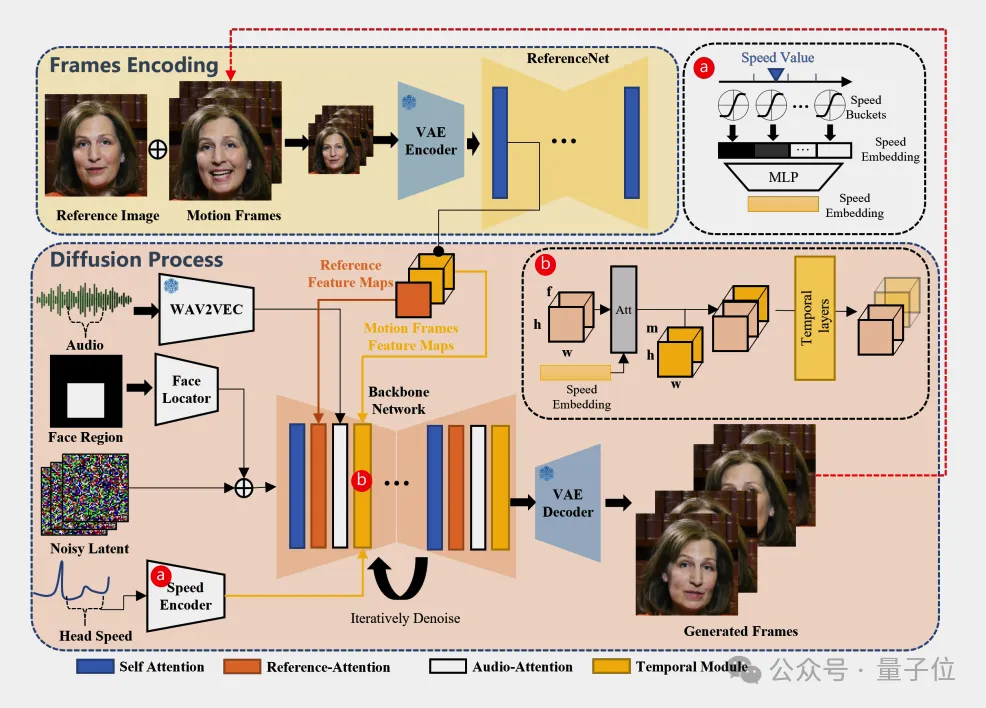
薄列峰介绍,EMO的核心思路是“弱控制设计”,无需对整个面部建模,这一点甚至体现在了论文标题上。

在生成过程中,面部定位器(Face Locator)用来编码面部的边界框区域。
速度编码器(Speed Encoder)确保头部运动的速度与音频的节奏和强度相匹配。
这些控制机制被称为“弱控制”是因为它们提供的控制不是强制性的或硬性的,而是允许一定程度的自然变化和表现力。
例如,面部区域控制器并不严格限定面部的具体位置,而是给出了一个允许面部运动的较大区域。同样,速度控制器并不精确控制每一帧的速度,而是提供一个速度范围,让生成的头部运动接近但不一定完全符合指定的速度水平。
通过使用这些弱条件,EMO框架能够在保持角色身份一致性的同时,生成具有丰富表情和自然头部运动的视频,从而在表达性和逼真度方面取得更好的效果。
比起传统的分别针对眼睛鼻子嘴等部位的建模方案,EMO更着重考虑整个面部的联合运动,最终效果也就可以做到自然流畅了。
另外薄列峰还透露,选择这个技术路线也是出于实用性、普及性的考虑。
一张图、一段音频,每个人都非常容易获取,门槛低一些,让大家都能玩起来。
关于EMO的技术选择,薄列峰还透露了一个消息。
虽然EMO使用传统基于U-net的扩散模型架构,但Pipeline是解耦的,如果后续尝试Sora同款DiT架构做到更好效果的话,也可以轻松切换过去。
对于未来发展方向,EMO目前只做了人头,将来还会扩展到半身、全身。到时候,能实现一张照片让人物同时唱跳RAP篮球也说不定。
在此之前,EMO背后通义实验室所推项目中,最火的是与EMO一脉相承的Animate Anyone模型。
代表杰作:奶牛猫跳舞。

算法原理上,EMO和Animate Anyone都采用了Backbone + ReferenceNet的结构,实现有参考图像引导的去噪生成过程。
其中,Animate Anyone在实现了保留特定对象ID的生成式模型的基础上,进一步证明可以通过一些输入控制信号控制生成内容,特别是人物的动作。
所以其实背后团队是专注数字人的团队,没想到在通义App上包装成“全民舞王”后,大家对动物玩法更感兴趣。

一个多月前,团队还在全民舞王针对小猫小狗等动物主体检测做了一半优化,使上传动物照片的通过率大幅度提升。
即使检测出来用户上传的是动物,只要通过了骨骼检测,啥小动物都可以起来嗨。
“现在技术确实可以生成很多的图片、视频,但如果他们都是平均甚至低于平均水平,大家不见得有兴趣去消费。”薄列峰笑道,奶牛猫跳舞确实很妖娆,“这给我们把链路打通带来更多的思考——把简单高质量的内容,通过新技术去实现可能。”
聊天最后,薄列峰还给大家推荐了一个EMO的私房玩法:
可以试试拿自己5岁、10岁、15岁……的照片,自己对话,自己合唱。
值得一试哟~
本文来自微信公众号“量子位”



【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
