# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
阿里云正式发布通义千问2.5大模型,同时宣布性能全面赶超GPT-4 Turbo。
此时,距离阿里云通义大模型发布,恰好过去一周年;距离GPT-4发布,也已经过去一年有余。
根据最新公布的数据,通义大模型通过阿里云服务企业超9万,通义开源模型累计下载量突破700万。
同时,阿里云也正式宣布了“通义千问App”更名为“通义App”,为所有用户提供免费服务。
通义意为“通情,达义”,该App以最新通义基础大模型为底座,并把通义实验室的文生图、智能编码、文档解析、音视频理解、视觉生成等能力“All in one”。
阿里云CTO周靖人表示:
大模型这么多家,大家都说的是同样的故事,但最后比拼的就是能力差异。包括最后比拼的是怎么融合生态,尤其是开发者的生态。
怎么把它落地运用起来,才是最大的差异。
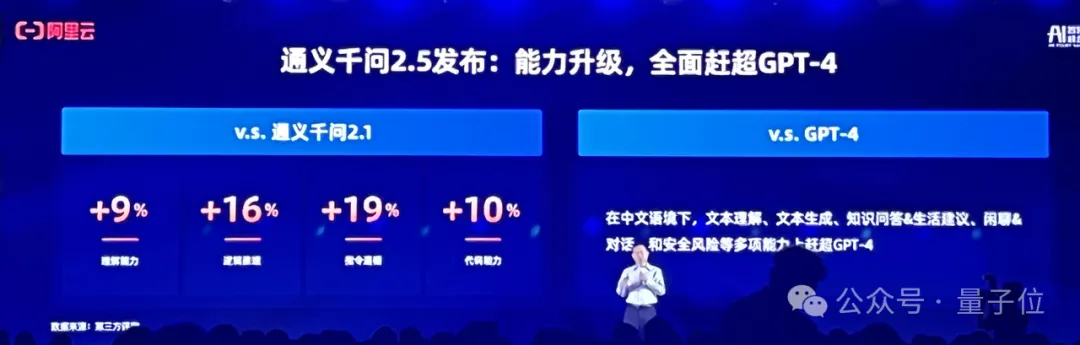
先来看看最新发布的通义千问2.5版本。
周靖人介绍,相比通义千问2.1(去年12月1日发布),2.5版本的理解能力、逻辑推理、指令遵循、代码能力分别提升9%、16%、19%、10%,中文能力尤其突出。
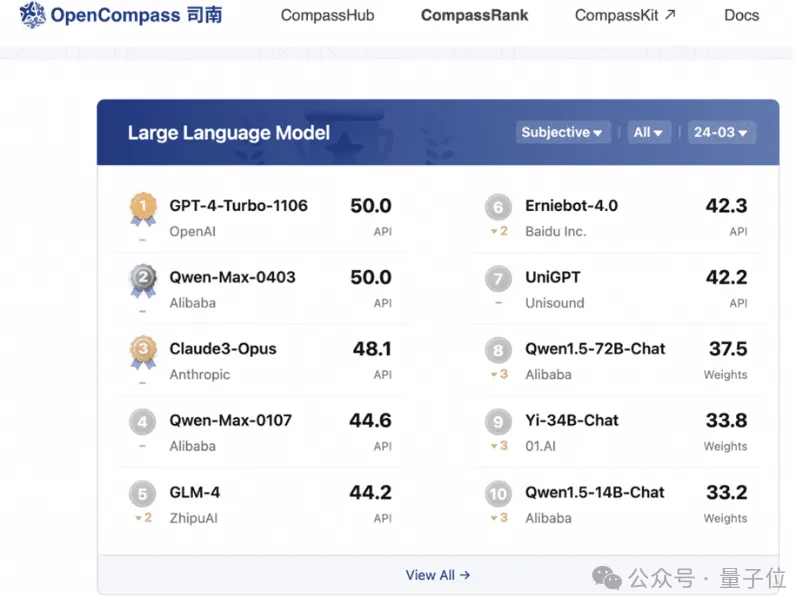
在权威基准OpenCompass(上海AI Lab出品)上,通义千问2.5得分追平GPT-4Turbo。这是该基准首次录得国产大模型取得此等成绩。
会上介绍,通义2.5加强了文档处理能力。
可单次可处理多达1000万字的长文档,还能同时解析100份不同格式的文档,支持多文件类型、多数据格式解析、多场景优化,便于用户使用和继承。

同时,通义的音视频理解能力也有迭代升级。
发布会上,周靖人着重介绍了专业提供智能编码能力的通义灵码,现在它不只支持个人程序员,也推出通义灵码企业版本。
通义灵码基于SOTA水准的通义千问代码模型CodeQwen1.5研发,目前插件下载量超过350万。刚刚过去的4月份,通义灵码登顶了Big Code模型排行榜。

在技术能力迭代的基础上,上述能力都集成在刚刚改名的通义App内,用户可以通过App和Web端进行使用。
除了通义2.5模型以外,阿里云的百炼大模型平台最新进展也进行了展示。
去年10月,阿里云发布了百炼大模型平台,主要功能就是让开发者通过简单的拖拉拽,在5分钟开发一款大模型应用,几小时炼出一个专属模型。
现在升级后,百炼有了2.0版本,成为阿里云承载云+AI能力的重要平台,提供一站式、全托管的大模型定制与应用服务。

“当下企业应用大模型存在三种范式:一是对大模型开箱即用,二是对大模型进行微调和持续训练,三是基于模型开发应用,其中最典型的需求是RAG,以企业数据对大模型进行知识增强。”周靖人展开介绍,“围绕这些需求,百炼打造了模型中心和应用中心,提供最丰富的模型和最易用的工具箱。”
目前,百炼联动魔搭开源社区,集成了上百款大模型API,除了通义、Llama等系列,还有智谱ChatGLM、百川、月之暗面等系列模型。

对需进一步训练模型的用户,百炼提供从数据管理、模型调优、评测到部署的模型服务,用户可对算力按需调用,无需因底层架构费脑筋。
此外,百炼还支持基于prompt定制和优化、支持Assistant API开发模式,实现智能应用的编排,结合自身需求做定制化开发。
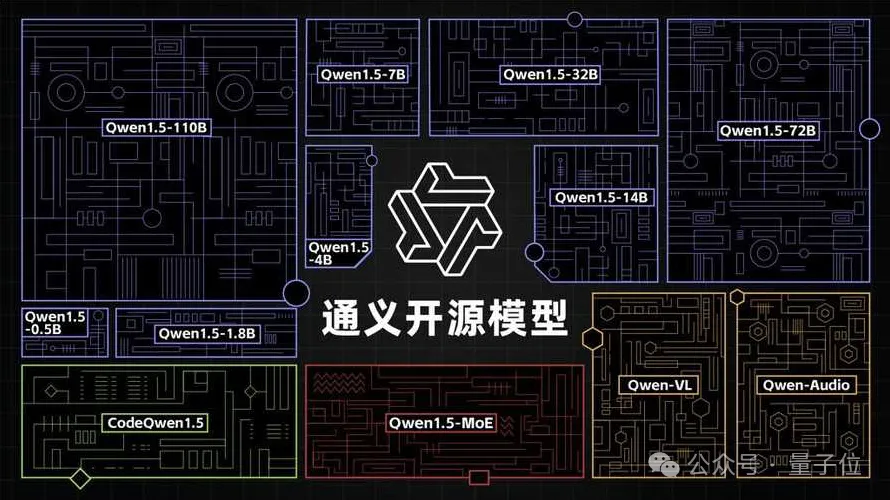
去年8月,通义宣布加入开源行列,随之沿着“全模态、全尺寸”路线,陆续推出十多款模型。
其中较为瞩目的是参数规模横跨5亿到1100亿的八款大语言模型。
此外,通义还开源了视觉理解模型Qwen-VL、音频理解模型Qwen-Audio、代码模型CodeQwen1.5-7B、混合专家模型Qwen1.5-MoE。
目前,通义开源模型系列下载量已经超过700万。
阿里云表示,自己是全球唯一持续开发模型、坚持开源的公司。
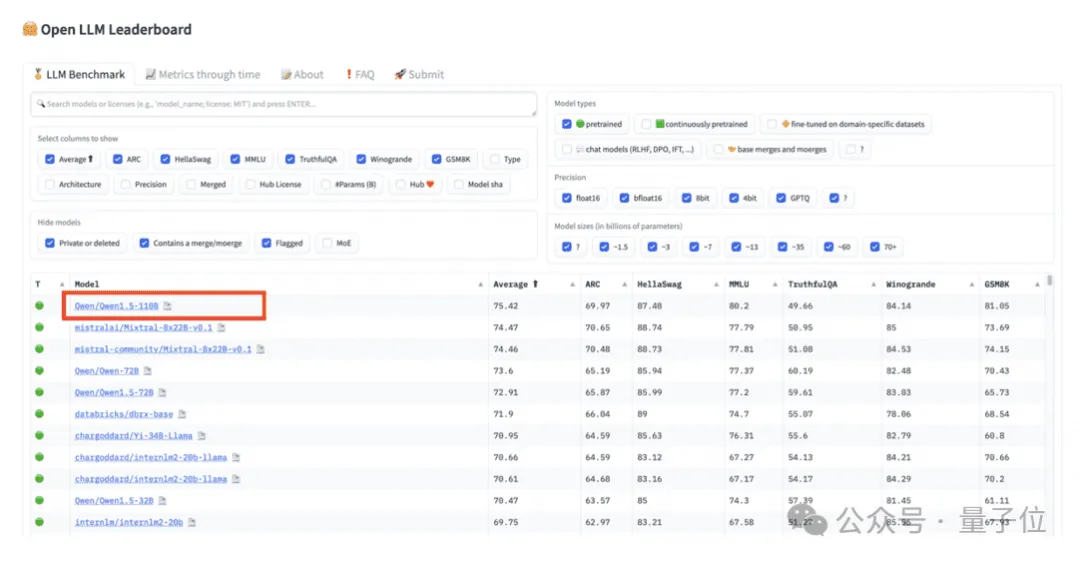
此次发布会上,通义也发布了最新款开源模型:1100亿参数的Qwen1.5-110B。
该模型在MMLU、TheoremQA、GPQA等基准测评中,超越了Meta的Llama-3-70B模型;在HuggingFace推出的开源大模型排行榜OpenLLMLeaderboard上,Qwen1.5-110B冲上榜首。
最后,在谈及开源技术时,周靖人表示,开源对全球技术的贡献毋庸置疑,闭源模型至少要超过所有开源模型才有机会参与讨论。
本文来自微信公众号”量子位“



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
