# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

生成式人工智能已经触及峰顶了吗?
在大模型正火的时候提这个问题,似乎不合时宜。
毕竟,随着数据和模型规模的增大、计算能力的增加,我们似乎不再怀疑拥有超强人工智能的未来。
——但是!来自University of Tübingen、剑桥和牛津大学的最新研究,用实验告诉我们:没有指数级数据,就没有Zero-shot!

论文地址:https://arxiv.org/pdf/2404.04125
换句话说,模型要想达到AGI水平,所需的训练数据量是我们无法提供的。
根据实验数据,模型未来的性能提升将越来越缓慢,最终会因为拿不到指数级的数据而触及瓶颈。
——所以,你以为大模型真的实现了zero-shot,真的在吸收和记忆的基础上,涌现了推理甚至创新,实际上都是人家见过千万次,早已倒背如流的答案。
你以为是素质教育出英才,其实人家走的是题海战术、应试教育路线。
Youtube上239万订阅的Computerphile频道,根据这篇文章的结果发表了类似的看法和担忧,立时受到广泛关注。
视频地址:https://www.youtube.com/watch?v=dDUC-LqVrPU
当前,由于大模型展现出的zero-shot learning能力,人们乐观地预计大模型的性能可以相对于训练数据呈指数级增长,——这也是人们对AGI抱有期望的原因。
就算再退一步,两者呈线性关系,我们也能接受,毕竟只要多花时间、多花钱、多喂数据,到达了某个临界值之后,大模型就将无所不能。
但是,这篇论文指出,实际上训练数据(样本或概念的数量)和性能(在下游任务上对应概念的表现)呈对数关系。

也许现下的模型还能在一段时间内快速提升,但以后会越来越难,付出的代价也会越来越大,
——比如万亿token换来1%的性能,比如GPT-5,6,7的性能可能没啥差别。
文章通过大量的实验得到了类似的数据和图表,

这些曲线的走向一致,证明了在当前的情况下,无论用什么样的训练方法、什么样的数据集、执行什么样的下游任务,都难逃对数关系的魔咒。
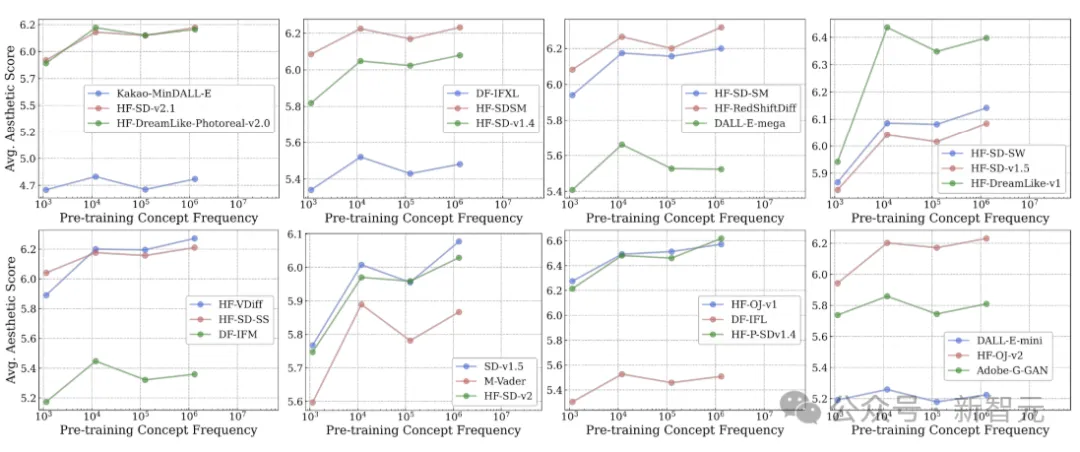
而且,虽然这篇工作针对于多模态模型,但LLM也会有相同的问题,比如我们熟知的幻觉就是一种表现形式,面对训练数据中没有的东西,LLM就开始胡编。
另一方面,训练数据的分布往往都是不均匀的,有些种类的数据频度高,那么对应到推理结果上的表现自然就好。
这种情况被称为长尾分布(Long-Tail Distribution),指在分类任务中,训练数据的分布呈现长尾形状,少数类别拥有大量样本,而大多数类别只有很少的样本。
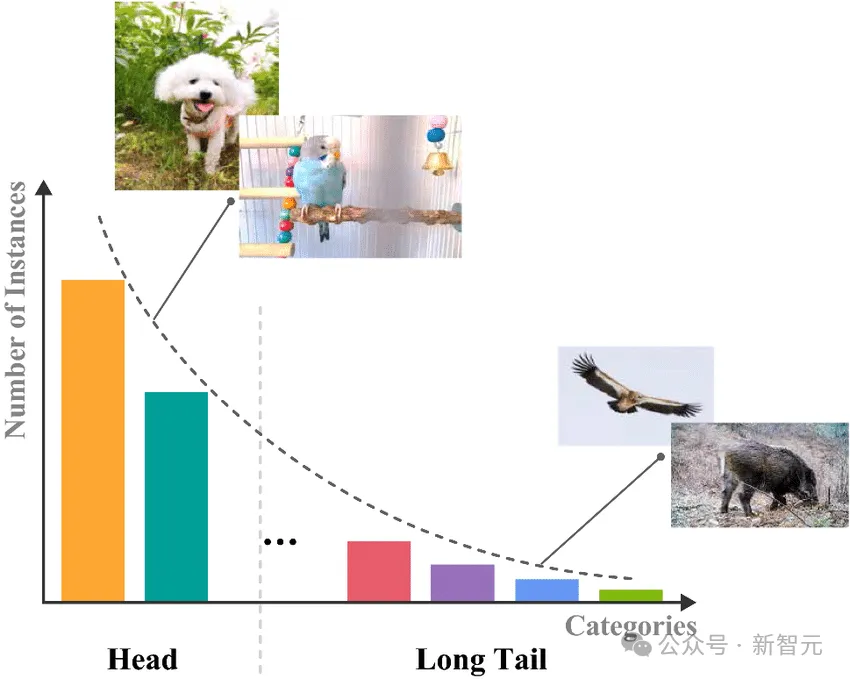
这种现象在现实世界中很常见,也就加剧了前面提到的指数级数据的难题。
当下模型的训练数据主要来自于互联网,咱也不知道数据是不是已经被吃得差不多了,反正这种指数级关系总会有无法满足的一天。
未来,我们可能需要「something else」,比如新的方法、新的数据表示、或者是不同于Transformer的新架构。
除了油管上一天23万的播放量,Hacker News上也是热闹非凡。
「这感觉像是当前人工智能炒作的最坏结果」。

网友表示,我们基本上已经把整个互联网都喂给模型了,这几乎是目前能得到的最大的数据集,而且由于AI生成的垃圾数据也在不断进入互联网,以后可能也不会有更大更好的数据集了。
给大模型喂这些数据花费了数十亿美元,却只得到了有一些用处,又没有太大用处的人工智能。——如果这些人力物力财力花在别的地方,我们可能会过得更好。
对于人工智能产生垃圾数据所带来的影响,网友们表示赞同。

也有网友认为,数据还是有的,但是很多人正在利用技术手段,拒绝人工智能爬取自己的数据。
「这意味着谷歌搜索变得更糟,生成式AI变得更糟,互联网变得更糟」。
还有网友表示,相比于互联网上那点数据,现实世界要复杂几个数量级。

不过,对于Computerphile在视频中表达的略显悲观的结论,有大佬表示质疑。
前谷歌高级工程师、现任RekaAI CMO的Piotr Padlewski认为:
首先,缩放定律告诉我们,模型越大,获得相同性能所需的样本就越少。
其次,这篇论文研究的是零样本学习(zero-shot),而不是in-context learning。即使是训练数据中不常见/不存在的主题,只要在上下文中提供示例和说明,LLM也能理解。

「我认为没有人期望LLM能在zero-shot的情况下证明出P=NP,可能发生的情况是利用Agent找到所有相关文件并从中学习。」
「首先需要开发更好的算法和智能体,但我们也需要更好的基础模型。」
目前,人们对于AI发展的一个主要争论是,规模的扩大能带来真正的泛化能力吗?看了一辈子猫狗的大模型真的能认识大象吗?
——大模型的zero-shot似乎已经为自己正名。
Zero-shot learning (ZSL) is a fascinating machine learning scenario. In ZSL, an AI model is trained to recognize and categorize objects or concepts without having seen any examples of those categories or concepts beforehand.
不需要在训练集中出现某个分类的样本,凭借已经学到的语义信息,就可以识别从来没有见过的类别。
比如下面这个例子,模型在之前的训练中学到了马的形状、老虎的条纹和熊猫的黑白色,
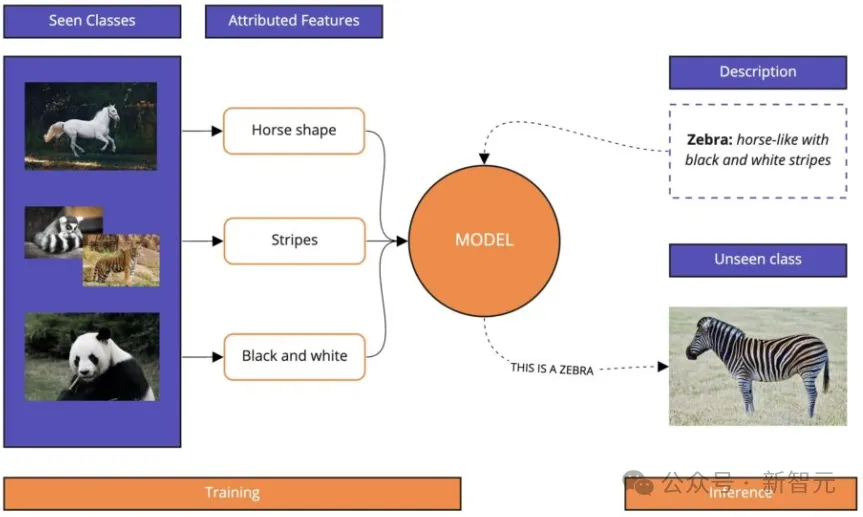
这时你再告诉模型:斑马长得像马,并且有黑白相间的条纹,模型就可以在从没有见过斑马的情况下对其进行分类。
当前,CLIP模型是零样本图像识别,和图像文本检索的事实标准,而Stable Diffusion则是零样本文生图的事实标准。

CLIP:把文本decoder和图像decoder(VIT)对应到同一个嵌入空间
——不过这种zero-shot的泛化能力,究竟在多大程度上是靠谱的?或者说:这种能力的代价是什么?
为了回答这个问题,研究人员决定用实验数据说话。
首先,问题涉及两个主要因素的比较分析:
(1)模型在各种下游任务中的性能
(2)测试概念在其预训练数据集中的频率
研究人员从涵盖分类、检索和图像生成的27个下游任务中,提取出4029个概念,根据这些概念来评估模型性能。
概念:定义为试图在预训练数据集中分析的特定对象或类别。
对于零样本分类任务,概念表示类名,例如ImageNet中的1000个类别(金鱼、黄貂鱼等)。
对于图像文本检索和图像生成任务,概念表示测试集标题或生成提示中出现的所有名词,比如在标题「一个男人戴着帽子」中,提取出「男人」和「帽子」作为相关概念
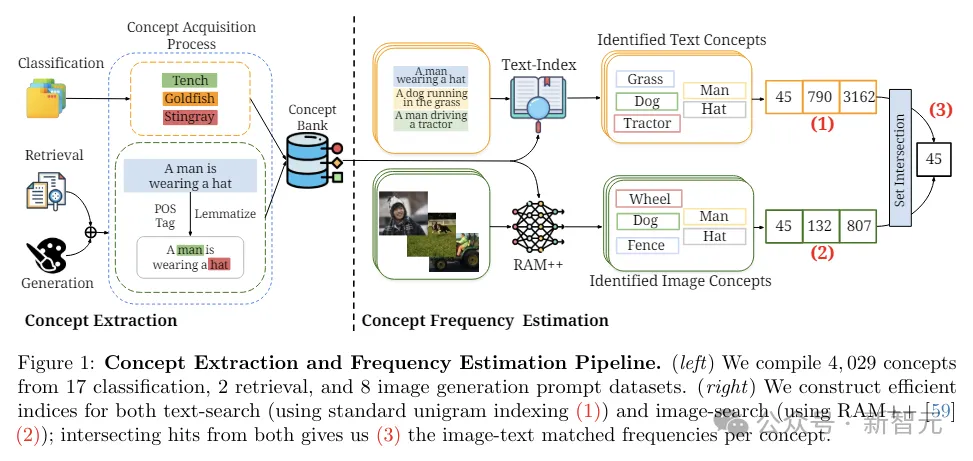
实验选取了五个具有不同尺度、数据管理方法和来源的大规模预训练数据集(CC-3M、CC-12M、YFCC-15M、LAION-Aesthetics、LAION-400M),以及具有不同架构和参数大小的10个CLIP模型,和24个文生图(T2I)模型。

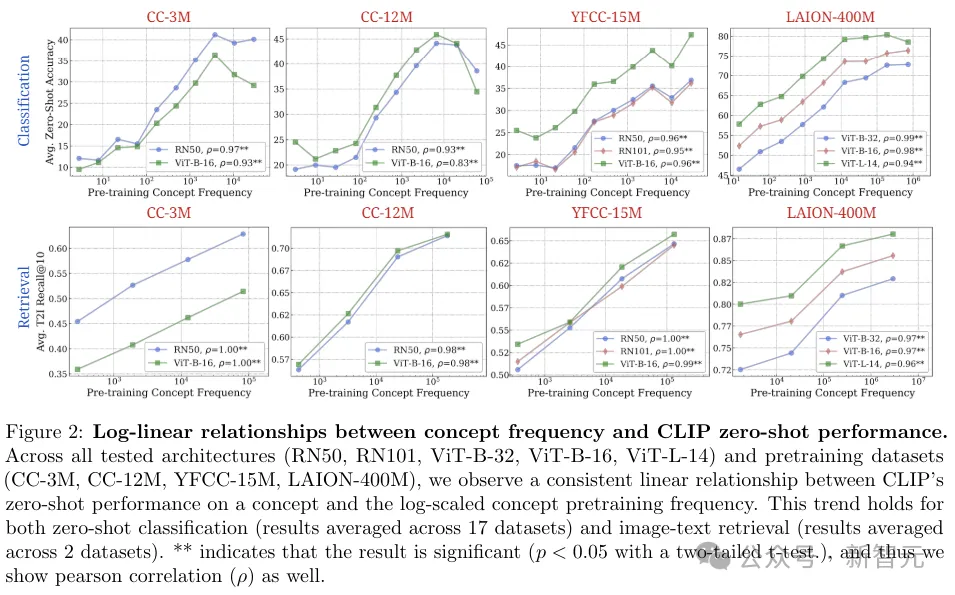
评估指标
对于分类任务,计算平均零样本分类精度。对于检索,使用文本到图像和图像到文本检索任务的传统指标来评估性能(Recall@1,Recall@5,Recall@10)。
而在文生图这边,评估包括图像-文本对齐和美学分数(aesthetic score)。
使用预期和最大CLIP分数来衡量图像-文本对齐,并使用预期和最大美学分数来衡量美观度。
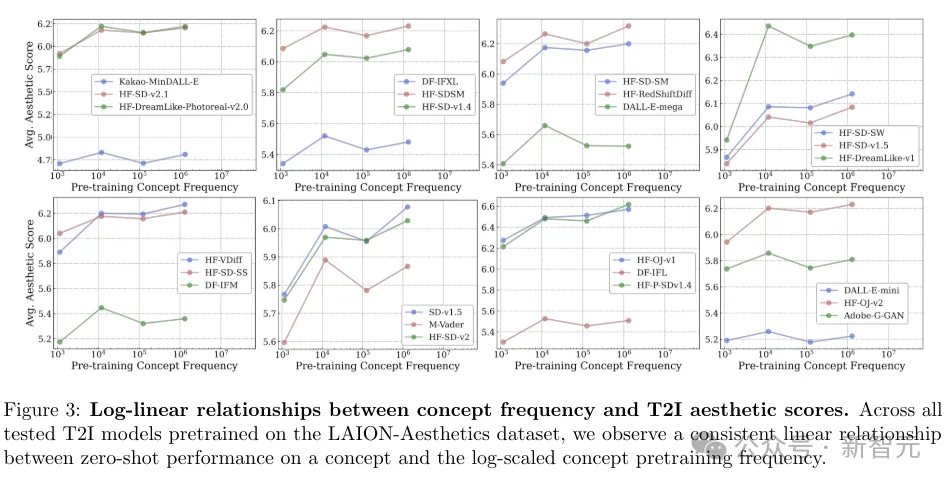
在以上的16个图中,我们可以观察到概念频率和zero-shot性能之间,存在明显的对数关系。
实验考虑了多个不同的维度:
(i)判别模型与生成模型,
(ii)分类与检索任务,
(iii)模型架构和参数尺度,
(iv)不同方法和尺度的预训练数据集,
(v)不同的评估指标,
(vi)零样本分类的不同提示策略,
(vii)仅从图像或文本域中分离的概念频率
而结果表明,对数线性缩放趋势在所有七个实验维度上都持续存在。
因此,CLIP和Stable Diffusion等多模态模型令人印象深刻的zero-shot性能,在很大程度上归因于其庞大的预训练数据集,而并不是真正的零样本泛化。
恰恰相反,这些模型需要一个概念的数据呈指数级增长,才能以线性方式提高它们在与该概念相关的任务上的性能,——极端的样本低效率。
参考资料:
https://arxiv.org/abs/2404.04125
文章来源于“新智元”,作者“新智元”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
