# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近,许久没有新动向的马斯克放出了大消息——他旗下的人工智能初创公司xAI将投入巨资建造一个超算中心,以保证Grok 2及之后版本的训练。这个「超级计算工厂」预计于2025年秋季建成,规模将达到目前最大GPU集群的四倍。
前段时间,OpenAI、谷歌、微软相继开大会,AI圈子的竞争如火如荼。
这么热闹的时候,怎么能少得了马斯克。
前段时间忙着特斯拉和星链的他,最近好像开始腾出手,而且不鸣则已、一鸣惊人,直接放出一个大消息——自己要造世界上最大的超算中心。
今年3月,他旗下的xAI发布了最新版的Grok 1.5,此后一直有关于Grok 2即将面世的传说,但却迟迟没有官方消息。

难道是因为算力不够?
没错,亿万富翁可能也买不到足够的芯片。今年四月他曾亲自下场表示,没有足够多的先进芯片,推迟了Grok 2模型的训练和发布。

他表示,训练Grok 2需要大约2万个基于Hopper架构的英伟达H100 GPU,并补充说Grok 3模型及更高版本将需要10万个H100 芯片。
特斯拉第一季度的财报也显示,公司此前一直受到算力的限制,当时马斯克的计划还是年底前部署8.5万个H100 GPU,将xAI从红杉资本和其他投资者那里筹集的60亿美元中的大部分都花在芯片上。
目前每台H100的售价约为3万美元,不算建造费用和其他服务器设备,仅仅是芯片就需要花掉28亿美元。
根据马斯克的估算,这个芯片储量训练Grok 2绰绰有余。
但可能老马思考了一个月之后,觉得这一步迈得还不够大,不够有突破性。毕竟xAI的定位是要和OpenAI、谷歌这种强劲对手正面掰头的,以后想训练模型可不能再因为算力掉链子。
于是,他最近公开表示,xAI需要部署10万个H100来训练和运行Grok的下一个版本。
而且,xAI还计划将所有芯片串联成一个巨大的计算机——马斯克称之为「超级计算工厂」(Gigafactory of Compute)。
老马这个月已经向投资者表示,他希望在2025年秋季之前让这台超级计算机运行起来,而且他将「个人负责按时交付超级计算机」,因为这对于开发LLM至关重要。
这台超算可能由xAI与Oracle合作共建。这几年来,xAI已经从Oracle租用了带有约1.6万个H100芯片的服务器,是这些芯片最大的订单来源。
如果不发展自己的算力,未来几年xAI在云服务器上很可能就要花费100亿美元,算下来居然还是「超级计算工厂」比较省钱。
这个「超级计算工厂」一旦完工,规模将至少是当前最大GPU集群的4倍。
比如Meta官网在3月发布的数据显示,他们当时推出了2个包含2.4万个H100 GPU的集群用于Llama 3的训练。
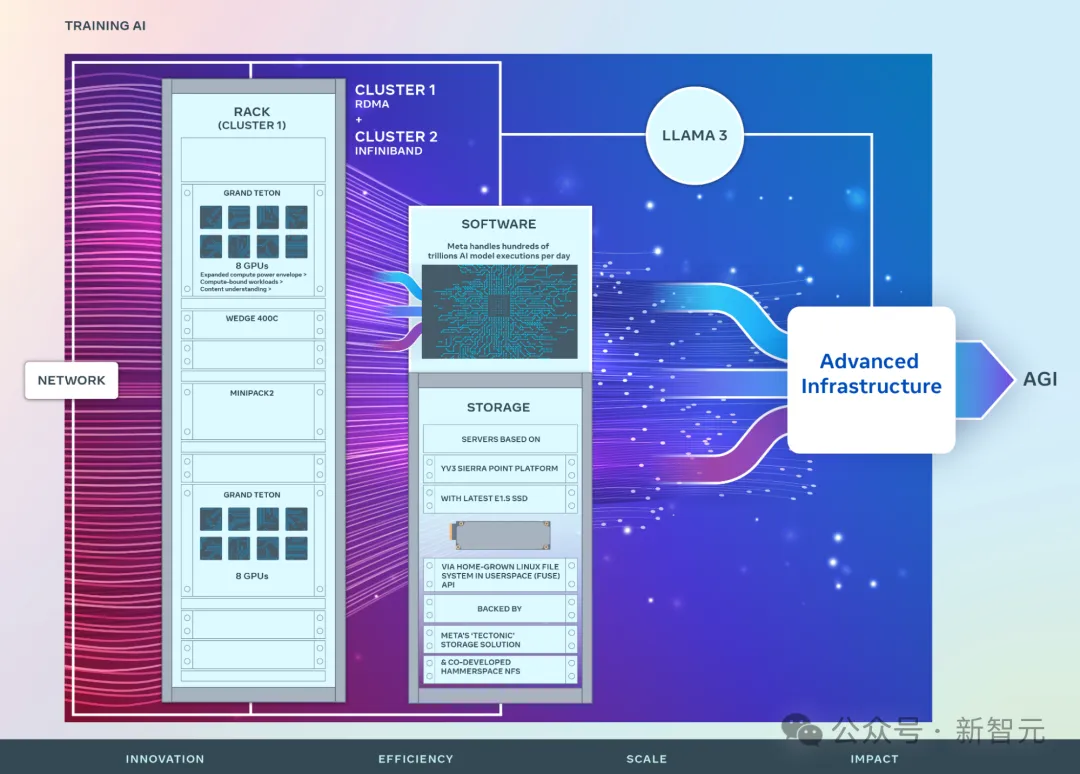
虽然英伟达已经宣布今年下半年开始生产并交付全新架构Blackwell的B100 GPU,但马斯克目前的计划还是采购H100。
为什么不用最新型号的芯片,反而要大批量购入快要淘汰的型号?这其中的原因,老黄本人向我们解释过——「在今天的AI竞争里,时间很重要」。
英伟达会每一年更新一代产品,而如果你想等我的下一个产品,那么你就丢失了训练的时间和先发优势。
下一个达到里程碑的公司会宣布一个突破性的AI,而接下来的第二名只在它上面提升0.3%。你要选择做哪一种?
这就是为什么一直做技术领先的公司很重要,你的客户会在你上面建设并且相信你会一直领先。这里面时间很重要。
这就是为什么我的客户现在依然疯狂的在建设Hopper系统。时间就是一切。下一个里程碑马上就来。
然而,即使一切顺利,「超级计算工厂」在马斯克的「个人负责」下按时交付,这个集群到了明年秋天是否仍然有规模优势,也是一个未知数。
扎克伯格今年1月曾经在Instagram上发帖,称Meta到今年底将再部署35万个H100,加上之前的算力总共相当于60万个H100,但他并未提及单个集群的芯片数量。
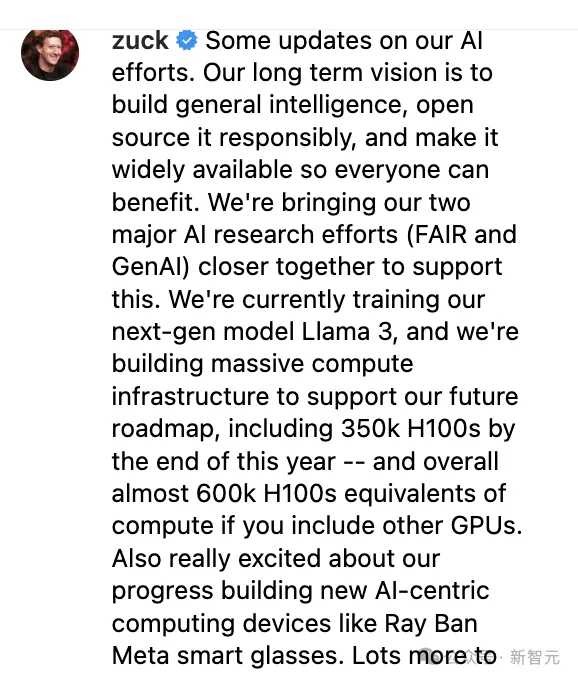
但这个数字没过半年就几乎翻了一番,5月初Llama 3发布前,有消息称Meta已从英伟达额外购买了50万块GPU,总数达到 100 万块,零售价值达300亿美元。
同时,微软的目标是到年底拥有180万个 GPU,OpenAI甚至更加激进,希望为最新的AI模型使用1000万个GPU。这两家公司也在讨论开发一个价值1000亿美元的超级计算机,包含数百万个英伟达GPU。

这场算力之战,最后谁会胜出呢?

应该是英伟达吧。
而且不仅仅是H100,英伟达CFO Colette Kress曾经提到过一份Blackwell旗舰芯片的优先客户名单,包括OpenAI、亚马逊、谷歌、xAI等等。
即将投产的B100,以及英伟达之后将要一年一更的芯片,将会源源不断地进入科技巨头们的超算中心,帮助他们完成算力的升级迭代。
马斯克在谈到特斯拉的算力问题时也补充说,虽然迄今为止芯片短缺是AI发展的一大制约因素,但电力供应在未来一两年将至关重要,甚至会取代芯片成为最大的限制因素。
包括新建的这家「超级计算工厂」的选址,最需要考虑的因素也是电力供应。一个拥有10万GPU的数据中心可能需要100兆瓦的专用电力。
要提供这种量级的电力,xAI总部办公室所在的旧金山湾区显然不是理想的选择。为了降低成本,数据中心往往建在电力更便宜且供应更充足的偏远地区。
例如,微软和OpenAI除了计划那个耗资千亿美元的超算,也正在威斯康星州建造大型数据中心,建设成本约为100亿美元;亚马逊云服务的数据中心则选址在亚利桑那州。
「超级计算工厂」一个非常可能的选址,是特斯拉总部,德克萨斯州奥斯汀市。
去年特斯拉宣布建造的Dojo就部署在了这里。这台超算基于定制芯片,帮助训练AI自动驾驶软件,也可以用于向外界提供云服务。
第一台Dojo运行在1万个GPU上,建造成本约为3亿美元。马斯克4月表示,特斯拉目前共有3.5万个GPU用于训练自动驾驶系统。

在数据中心进行模型训练是一个极其耗电的过程。据估计,训练GPT-3的耗电量为1287兆瓦时,大约相当于130个美国家庭每年消耗的电量。
注意到AI电力问题的CEO不止马斯克一人,Sam Altman本人曾向初创公司Helion Energy投资3.75 亿美元,这家公司旨在利用核聚变提供一种更环保、更低成本的 AI 数据中心运行方式。
马斯克则没有押注在核聚变技术上,他认为,AI公司很快将开始争夺降压变压器(step down transformer),可以将高压电流转换为电网可用的电力,「从公用电网获得的电力(例如 300 千伏)降至 1 伏以下是一个巨大的下降」。
芯片之后,AI行业需要「transformers for Transformers」。
参考资料:
https://www.theinformation.com/articles/musk-plans-xai-supercomputer-dubbed-gigafactory-of-compute?rc=epv9gi
https://www.inc.com/ben-sherry/elon-musk-touts-nvidia-dominance-predicts-a-giant-leap-in-ai-power.html
https://finance.yahoo.com/news/jensen-huang-elon-musk-openai-182851783.html?guccounter=1
文章来自于微信公众号 “新智元”,作者 “新智元”




