# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
印度的AI狂想与尴尬
在当下AI的热潮中,除了中美两大巨头,还有一个来自东方的大国,试图在人工智能的竞争中抢占先机——是的,它就是我们那个神奇的邻居,印度!
根据最新的Kantar研究报告,印度目前已经有7.24亿人已经用上了AI(未必全是GPT这类大模型)。
在官方层面,对于生成式 AI 产业这事儿,印度也是兴趣极大。
就在去年8月,印度联邦内阁批准了为人工智能、网络安全和数字技能发展投入1490.3亿卢比(约合130.7亿人民币)的计划。

在这样的刺激下,今年1月,印度终于诞生了一家自己的大模型独角兽公司——Krutrim。推出大模型仅一个月后,该公司就以10亿美元的估值融资5000万美元。
然而,印度AI这场盛宴,表面上锣鼓喧天,但一掀开锅盖,里面的“菜色”可就一言难尽了。
先说说“参赛选手”吧,印度在AI企业数量上,跟中国一比,那差距可不是一星半点。
中国这边,不仅有百度、阿里、腾讯这些巨头推出了文心、盘古这样的的大模型,还有一堆短小精悍的团队,比如月之暗面、智谱AI、百川智能和Minimax,也都搞出了拿得出手的自研模型。
而印度呢,大模型相关的公司少得可怜,自研模型更是凤毛麟角。

根据Tracxn和印度人工智能协会的数据,印度在大模型领域的公司数量不到10家,而且这些公司主要忙着做对话AI、智能助手和一些特定行业的应用,基本不碰基础模型的研发。
至于印度目前唯一一个自研模型Krutrim AI ,也同样充满了“咖喱味”。
不仅被曝出来有套壳ChatGPT的嫌疑,并且根据使用者的体验报告,Krutrim AI在使用时,仅允许输入 424 个字符(不包括空格),而且有时在交互过程中还会突然懵逼,连自己是谁都忘了。
实际上,对于印度AI的前景,去年早有人做了预判。
2023 年 6 月,Sam Altman 在印度被问及,如果印度团队花1000万美元搞出大模型,能和OpenAI竞争吗?Altman 回答:没戏。
印度,这个在IT圈里响当当的大国,居然在AI方面如此拉胯,属实让人感觉有点意外。
咱们平时老觉得,这AI大模型,说白了就是个高级点的程序,不比那些又要精密机械、又要复杂化工的产品,得一步步爬产业链的阶梯。
按理说,只要掌握了算法加数据,再凑上几个写代码的高手,理论上应该手到擒来才对。而印度人在代码、编程这块,那可是出了名的能干。
且不说当下谷歌、微软的CEO皮查伊、纳德拉都是印度人,就连当初写下名震AI界的那篇《Attention is All You Need》的硅谷八子中的两人,也是印度裔。
同样地,今年震撼AI界的Sora,其核心研发人员中,就包括了一名来自印度的技术天才Aditya Ramesh。

Aditya Ramesh还参与开发了DALL-E
就连特斯拉的自动驾驶负责人Ashok Elluswamy,超级计算机Dojo前负责人Ganesh Venkataramanan也同样来自印度。
按理说,编程、软件方面的人才那么多,搞AI应该很有优势啊,那为何印度在大模型方面如此拉胯呢?
其实,这种“只需要几个聪明人” “万事俱备只差一个程序员”就能搞出来的“低门槛”技术,某种程度上是一种产业上的错觉。
这种错觉就像:“在汽车方面很强大的国家,理应轻松搞出网约车平台”,但现实是,它们就是搞不出来,例如德国、日本虽然是传统汽车强国,但你见过哪个牛气冲天的网约车平台是从他们那儿冒出来的?

在德国,Free Now这样本土的网约车APP,2023年的用户数只是区区350万左右。
其实,无论是网约车,还是大模型,都不是表面上看起来那样,只需要几个聪明的程序员鼓捣几下,就能弄起来的。
因为这背后涉及的东西,表面上看只是一堆程序、代码,但实质上却和一个国家的基础科研、基础设施,市场群体,以及数字化程度有着千丝万缕的联系。
就拿网约车来说,基础科研方面,网约车涉及了GPS、定位算法一类的东西;在基础设施方面需要有覆盖极广的高速网络;在市场端要有大量经常性乘车出行,且熟练上网的人口来支撑。

同样地,AI领域虽然不像某些产业有复杂的供应环节,但依然有着自身的产业链。
分为上中下三游,每一个环节背后都对应着必不可少的科研、市场或数字化程度等因素。
具体来说,AI产业的上游,就是基础研究层面,例如机器学习算法、神经网络架构等等,这方面需要大量跨学科的,基础理论方面的人才;但可悲的是,当今的印度在AI领域,直接在最顶层就被抽掉了理论和科研的人才基础。
印度在AI基础科研人才方面的缺失,原因主要有二点:
1、IT外包带来的“毒蛋糕”效应;
2、国内拉胯的基建。
这里先说下第一点。
在1990年代那会儿的时候,印度遭遇了严重的外汇危机,赤字占到了其GDP的8.5%左右。为了破局,印度政府不得不进行了一系列市场化的改革。
而改革中最重要的一点,就是鼓励私立教育机构的发展,特别是那些专注于工程、管理、信息技术等应用型学科的学院和大学。
这些以市场为导向的私立学校,很快就瞄准了一个特别香的赛道——IT外包。
这是因为,从成本和收益比来看,印度当时的基础设施、工业能力太差,而且十分缺乏资本,搞制造业属于费力不讨好的行当。
倘若培养制造业的技术人才,毕业后的就业率会十分难看。
相较之下,IT外包这种活,不仅属于轻资本,不需要大动干戈地搞基建、建工厂,并且由于印度人英语好,劳动力又廉价,做起来简直就是一本万利的绝佳买卖。
于是,从90年代起,各种以信息技术为主的应用类专业,就开始在印度的学校中野蛮生长。
而这样的局面,也造就了今天印度科研“重应用,轻理论”的局面。
例如在2021年的一份报告中,印度工程和技术专业的学生,占到了总招生人数的约70%。
但在基础科研方面,根据《自然指数》(Nature Index)的数据,在2022年,中国在自然科学方面的成果约为20050项,美国是21473项,而印度只有1280项。
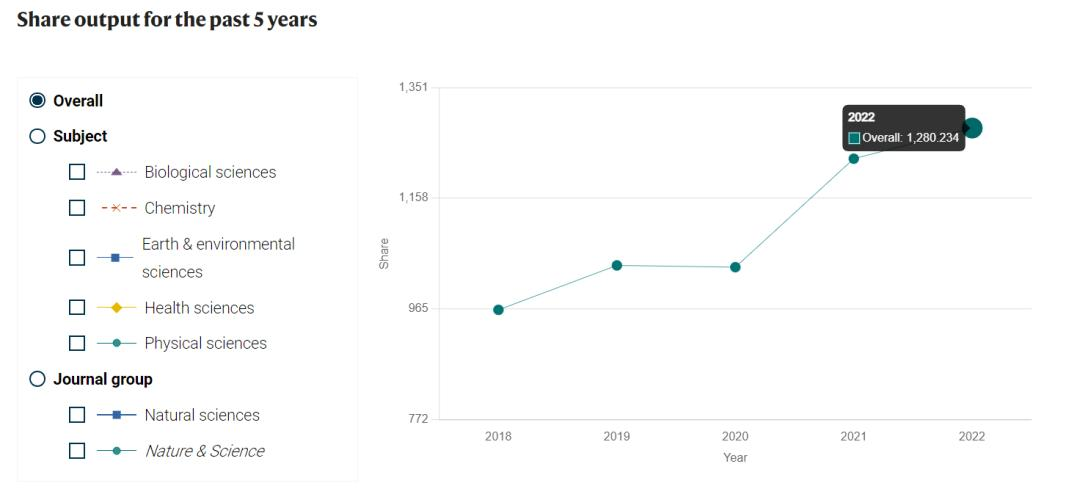
来源:Nature Index
虽然印度后来也意识到了这种模式的弊端,也想过要改变,但是,两个重要的原因,让印度放弃了“浪子回头”的打算。
首先一个原因,是美国人给得实在太多了。
随着90年代美国的计算机巨头开始全球扩张,印度的IT人才,从大量的大外包订单中获得了巨额报酬。
到了1990年代中期,印度IT从业人员平均年薪大概是8000—12000美元左右,到2000年初期,进一步上升至3万—5万美元,同时期的印度普通农村家庭,年收入仅为300-500美元。而城市低收入阶层家庭的年收入,也仅为600-800美元。

除了巨额的订单诱惑,另一个重要原因,就是印度拉胯的工业、基建,让很多基础科研方面的工作缺乏必要的硬件。
这里一个很反直觉的现象是:AI方面的研究与实验,其实与其他基础科研一样,是十分注重硬件设施的一种研究。可不只是凭编程高手倒腾几下算法那么简单。
要维持大模型的运转,就得有大量的GPU,以及相应的数据中心,而这背后,则必须有充足的电力、能源,以及稳定的、高速的网络基础设施,用来进行数据的传输。
可偏偏印度在这些基础设施方面,表现属实不太行。
一个明显的差距是,2023年,在超大规模数据中心数量上,印度只有大约18个超大规模数据中心,而中国的公开数据是有接近100个。
而超大规模数据中心,正是衡量AI算力的一个重要指标。

这样的差距背后,是支撑和维系数据中心运作的一系列配套设施,包括了电力、网络,冷却系统等等。
在这方面,印度同样被中国甩了好几条街。
首先在能源方面,中国的超大规模数据中心的能耗,在2023年估计达到了约180-200 TWh,而印度只有大约10-15 TWh。
之所以如此,是因为印度在电力方面的基建,实在太捉急了。
根据印度民意调查机构2022年对超过2万人的调查显示,三分之二的家庭表示会突然遭遇停电,三分之一的家庭更是每天固定“小黑两小时”。

这电都不够老百姓家里灯泡亮的,还想养AI这尊电耗子?
除了电力,在网络基建方面,同样是在2023年,中国5G基站总数已超过248万个,覆盖率超过96%,而印度的数量只有30万,覆盖率仅达到了30~40%。
而在更为关键的冷却系统方面,中国在直接液冷、浸没式液冷等先进液冷技术方面处于领先地位(采用率30%)。相比之下,印度大多数数据中心仍采用传统的空气冷却系统,缺乏对液冷技术的广泛应用(采用率10%左右)。

以上种种拉胯的基建,都让印度的计算机科学人才,即使想回国为AI事业效力,也会面临“巧妇难为无米之炊”的困境。
于是,印度聪明的年轻人,最后往往只能含泪打包行李,漂洋过海去美国实现科研梦。
2023年,约6万名印度计算机理论人才选择了海外发展,约占本土计算机理论人数的40%,相较之下,中国的流失率只有15%。
一面是美国抛来的巨额IT外包订单,一面是国内拉胯的基建,两者的相互作用下,印度只能在“科技施工队”的路上越陷越深,难以自拔。
而这种顶层理论人才的差距,直接决定了印度在AI领域所能取得的上限。
如果说,印度在AI产业链上游的问题,主要是基础理论人才的缺失,那么在AI产业链的中游,也就是模型训练方面,印度的困境,主要是难以为大模型的优化和迭代提供足够的数据。
而印度在这方面,有个最大的硬伤:就是社会的整体的数字化程度太低。

虽然印度网民人数听起来是挺唬人的,快9亿大军了,但这里有个重要的区别,就是网民数量并不等于一个国家数字化的程度。
现在经常用AI的朋友,估计可以感受到,目前ChatGPT这类AI,最大的用武之地,往往都是一些信息、数据特别密集的场景。
例如像什么长篇报告总结,专业研报分析,或是帮忙处理一些庞杂的代码之类的。
这样的场景,通常包含了大量的数据、信息,而数据或信息的量多到了一定地步,到了人脑觉得负担太大的时候,人们就会觉得AI很有必要了。
从这个角度上看,数字化程度越高的社会,和AI的契合度就越高。

反之,在一个数字化程度较低的国家里,人们在日常活动中产生不了那么多数据,或是即使产生了数据,这样的数据也是大多是以“线下”的形式存在,那AI就很难有用武之地。
从这个角度来看,所谓的数字化程度,绝不仅仅是“网民数量”这一表面的指标,而是指在日常生活中,人们工作、买东西、学习、看病这些活儿能多大程度在网上解决;企业是否能用数字化的手段提高效率。
虽然现阶段,印度网民的数量是挺多了,但仔细深究起来,他们每天在网上都干了嘛事儿?
根据著名的会计和咨询公司KPMG在印度分布的统计,印度网民目前每天上网的主要活动中,社交网络、即时通讯和视频娱乐等领域最多,占到了总上网时间近90%左右。

但在娱乐化的内容外,其他活动频次就明显低了很多。
如果按使用频率来统计,印度只有56.3%的用户通过网络进行了在线购物,而在中国,这样的比率达到了83%。
除此之外,在网约车平台这些生活服务方面,印度本土的和网约车平台Ola,在2022年全年的订单量约为3.7亿单,而同一时期,中国滴滴出行的订单量则达到了370亿单,是其一百倍以上。

而在企业端,印度企业的互联网普及率仅为49%,而相较之下,中国企业的互联网普及率显著更高,达到了约95%。
这种“低数字化”的现状,从表面上看,主要是落后的基建(5G普及率不足30%)导致的,但从更深层次的原因来看,这和目前印度固有的产业结构,有着莫大关系。
在印度目前的产业结构中,服务业占了GDP的约60%左右。但其中大多是一些低端服务业,例如零售、酒店或餐饮啥的。
农业占了15%—18%,制造业还要略低一些,只有12%。
这种以农业、服务业主导的产业结构,实际上很难承载数字经济所需的复杂产业链和高附加值服务。

农业和很多服务行业,产业链往往很短且较为单一,就像种地、养牲畜,供应链相对较短。
还有那些日常的服务,比如餐馆做饭、商店卖东西、家政打扫卫生,生产链也相对单一,去干就完了呗,较少涉及复杂的上下游产业链整合或增值服务。
说白了,这样的产业,缺乏复杂的数据和信息管理需求。
这么点信息,人脑其实完全处理得过来,用不着AI。
与农业、服务业主导的社会相比,工业社会的一大特征,就是存在大量的分工与协作。
从最初的原材料处理,再到设计新产品、搞研发、组装、测试,最后还要打品牌、做营销、保证售后服务,这一套流程下来,就形成了复杂的产业链。
每增加一个环节,都能创造更多的数据和信息增量。

以新能源车的生产为例,在设计阶段,通过CAD/CAE软件进行车辆设计,以及进行仿真测试时,就会产生大量设计数据和模拟数据。
到了生产环节,生产线上的设备状态、物料流动、生产进度等,同样会产生海量实时数据。
而除了制造环节本身创造的数据流外,由于产业辐射效应,一些工业活动还会给其他看似不相关的行业,带来意外的新的信息和数据。
例如,在金融和保险行业,有基于车辆行驶数据定制的保险费用。
在广告营销行业,为了实现精准营销,企业就得利用大数据分析消费者偏好、社交媒体互动数据等,来优化广告投放。

综上所述,倘若没有工业化,社会就难以产生复杂的分工,没有复杂的分工,人们的生活中也就不会产生大量的数据、信息。
这也是为什么,现在的各个风投机构,都不怎么看好印度AI企业的原因。
去年,印度与大模型相关的AI企业,融资总额约为1.6亿美元。而在中国,仅仅月之暗面一家企业,总融资额就已经达到了30亿美元。
如此巨大的差距背后,除了对印度AI实力的担忧外,一个更重要的原因,就是AI在印度并不真正具备市场规模和潜力。
毕竟,若是放在中国的环境下,即使大模型一时难以在C端打开局面,但至少在B端,由于数字化程度较高,因此在某些定制化的、垂直的场景(如金融、医疗)中,大模型仍然能找到用武之地。

而反观印度,在社会整体低数字化的情况下,大模型除了闲聊和娱乐,还能用来干嘛?
但如果只是闲聊和娱乐,上社交媒体和刷短视频不更香吗?
当前印度在AI方面的窘境,属实表明了:当下的这场AI竞争,从浅了看,只是某一个具体技术的竞争,往深了看,是一个国家总体科研实力的较量,再看得深点,就是不同国家之间,社会发展程度、产业结构、人口素质方面的一个综合比拼。
从总体上看,数字化程度越高的国家,AI落地和普及的效果就越好。
而AI普及度越高的国家,就越能够通过收集用户的反馈数据,形成数据飞轮,进一步对模型进行优化和迭代。

而印度的尴尬之处就在于,明明自己身为一个尚未完成工业化的半农业国家,却在追求AI这样一种数字化时代的产物。
而更讽刺的是,印度越是追求AI,自己从前的“铁饭碗”被端掉的可能性就越大,因为当下的生成式AI,在很多功能上,就是直奔着取代某些高端服务业的目标去的。
例如5月21日的微软开发者大会上,微软不仅发布了搭载GPT-4o的最新版Copilot,并且还在会上演示了“帮助小白编程”的GitHub Copilot Workspace。

这是一款通过聊天实现完成程序编写的软件。这将使任何新手,即使对编程语言几乎没有了解,也能开发自己的软件。
设想一下,如果将来编程、电话客服一类的岗位,全都能被AI取代了,印度之前赖以发家的“IT外包”这条路子,还能走得通吗?
到了那时,工业基础薄弱,IT铁饭碗又被抢走的印度,该如何在AI时代生存,将成为一个巨大的问号。
文章来源于“酷玩实验室”,作者“酷玩实验室”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
