# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
ChatGPT一夜爆火,掀起了产业界对于AI大模型的追逐,也吹响了“百模大战”的号角。为了与OpenAI的ChatGPT抗衡,各方纷纷下注。电商巨头亚马逊近期也开始在AI领域频频发力,并向 OpenAI的头号对手Anthropic豪掷了40亿美元(约合292.34亿元人民币)。而这项投资被认为是迄今为止亚马逊在生成式AI领域中最大的一项投资。
不过就在亚马逊宣布上述投资几天后,Anthropic再次传出了融资动向。10月4日,有消息称Anthropic尝试找谷歌以及其他投资人谈判,计划再募集20亿美元(约合146.17亿元人民币)的新资金,投后估值或预计达200-300亿美元之间。该公司的新估值将是今年3月40亿美元的5倍以上。让这家成立不到两年的AI初创公司风头一时无两。
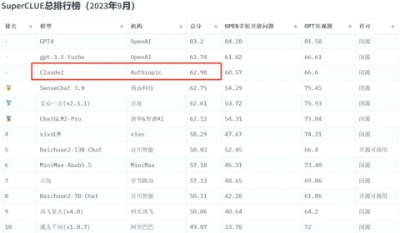
受到谷歌、亚马逊青睐的Anthropic究竟有何背景?先来参考一下中文通用大模型综合性评测基准SuperCLUE发布的9月榜单。测试结果显示,Anthropic推出的Claude 2总分仅次于OpenAI的GPT-4和GPT-3.5,位列第三。
9月SuperCLUE总排行榜上Claude 2位列第三
(图片来自于cluebenchmarks.com)
除了在社区榜单上的优势排名外,Anthropic的创始团队也不一般。创始人Dario Amodei和Daniela Amodei兄妹俩,在创业前均来自OpenAI,并在其中担任重要职位:Dario是研究副总裁,Daniela是安全政策副总裁。其中,Dario早在OpenAI创立之初便加入了,堪称其元老级人物之一。另外几位如Jared Kaplan、Sam McCandlish、Tom Brown等核心研究员也都来自OpenAI,并且均参与过GPT-2与GPT-3 的开发。这些GPT系列产品的早期开发者在2021年成立了Anthropic。
随着ChatGPT的发布,Anthropic也不甘示弱,仅用两个月时间便推出了可与之对标的类ChatGPT产品——Claude,又在7月初完成了Claude 2的升级,速度惊人。有业内测评显示,在综合性能上,Claude 2与GPT-3.5相当,但与GPT-4仍存在差距。在文件上传、长文本处理上,Claude 2优势明显,可将上下文处理的token数量扩展到10万个,相当于7.5万个英文单词。Claude是GPT-4容纳token量的3倍,Claude 2更可处理数百页技术文档,甚至是一本书。在逻辑与计算上,Claude 2与GPT-4性能已不相上下,但代码生成和问题推理方面较弱。凭借着文本处理数量上的巨大优势,Claude可与现阶段商用的大模型进行差异化竞争。
Anthropic在技术圈认可度也很高,被认为是OpenAI的强劲对手,其致力于解决大语言模型现有的难点,并在AI安全技术、大模型的潜在危害性、大模型的可解释性等方面进行了大量研究。对此,Anthropic提出了宪法式AI方法,为AI系统设定宪法原则,以区别于人类反馈强化学习RLHF方法,利于实现更精确、更自动化的AI行为监督和控制。宪法式AI方法将避免未来AI过于智能,危及人类的情况,为人类监督和管理AI提供了方案。
基于上述在AI合规领域的独特优势,Anthropic将AI安全技术视作其产品和解决方案的核心卖点之一。而这一商业定位与OpenAI等竞争对手有着显著区别,有可能在AI安全市场上抢到先机。
大模型是个吞金兽。为了持续迭代升级,Anthropic希望未来两年能够再筹集50亿美元以训练更为复杂的模型,而此次亚马逊提供的40亿美元则将用于训练Claude-Next——Anthropic的新一代大模型。新的大模型生成能力预计是当前最强AI的10倍。在应用上,Claude-Next将以行业落地为主,目标是切入到十几个主要行业里。
此前Anthropic的年营收大约为1亿美元,随着与亚马逊的合作展开与深入,预计2023年的全年营收有望翻倍,增长至2亿美元,月营收约至1700万美元。到2024年底,Anthropic年营收将有望达到5亿美元,是其估值的1/200倍,远远超出OpenAI的营收能力。
纵观业内,Anthropic已成为当前硅谷最受资本欢迎的AI公司之一,整体估值接近50亿美元,仅次于OpenAI,位列第二。
AI大模型生成能力的每一次跃迁,对于算力的需求来说,都会呈现指数级增长。这势必引发对底层算力基础设施以及大量资金的追逐,也注定了这是一场科技巨头之间的惨烈大战。在这波AI浪潮下,美国科技巨头各逞其能,早已从单纯比拼大模型产品,延展至大模型结合算力的核心基础能力较量。对于亚马逊、微软、谷歌作为全球云服务的三大巨头而言,则是对云端计算与服务的实力新考验。另外,以特斯拉为代表的产业新势力,同样跃跃欲试,正在快速杀入战局。此时的竞争焦点逐步变为抢人(开发者和使用者)、抢资本和抢生态上。
从AI大模型迭代,到算力消耗,再到资本投入,吸引更多的开发者和使用者,形成AI云服务生态,最终收获商业回报。这是科技巨头们期待看到的良性循环。互联网时代,亚马逊在云服务领域处于领先地位,但在AI时代,由于在AI大模型和算力方面的滞后,其云服务市场份额面临着微软、谷歌的蚕食。微软与OpenAI、谷歌与DeepMind的结合,使微软云Azure、谷歌云GCP相比亚马逊AWS,不只有了AI附加值,还有固定的业务出口,具备明显的竞争优势。这也成为亚马逊砸钱Anthropic的重要原因。
微软:2019年投资了OpenAI,2023年初加码投资100亿美元,对OpenAI持股比重49%,藉由ChatGPT热潮,微软完成了从最初的软件提供商到云服务商再到AI领导者的角色转换。同时,微软也试图将投资OpenAI的成功复制到其他AI初创企业,遂又战略性投了Inflection AI、人工智能独角兽Adep。同时与开源AI大模型Meta/Facebook LlaMA 2合作,在开源与闭源AI大模型两边下注,以提升微软云Azure竞争力。
谷歌:尽管有DeepMind与谷歌大脑合并,但仍然不影响谷歌对Anthropic持续下注。OpenAI的强势崛起,令谷歌“鸭梨山大”,今年2月便投了Anthropic 4亿美元,获得其10%股份;10月初,传Anthropic与谷歌等投资方沟通,准备新一轮至少20亿美元融资。另外,谷歌继推出LLM聊天机器人Bard后,又宣布推出新版AI模型Gemini,曾被认为是当前GPT-4最强劲的挑战者,但具体表现仍有待验证。
亚马逊:属于AI后发跟进者,5年前错失了与OpenAI的合作机会,让微软成为这轮AI时代“尝鲜人”;在对Anthropic投资中,又比谷歌晚了半年左右时间,今年9月下旬才向Anthropic初步投资12.5亿美元,之后最多可增投至40亿美元。目前,亚马逊持有Anthropic少数股权,Anthropic估值尚未确定。如果亚马逊这笔投资顺利完成,将是其在AI相关领域里的最大一笔投资。
Meta:同样是AI后发者。Meta从最初的投入元宇宙,转而布局AI,宣布推出大型语言模型LLM的第一个版本LLaMA。为扭转后发局势,Meta抛出了“开源免费”的大招。与微软、谷歌先通过大模型优化现有产品(例如,微软将OpenAI接入BING、Office和Azure,谷歌将AI技术应用在搜索、Workspace、地图等)不同,Meta期待通过AI构建出更具前瞻性的元宇宙,野心不容小觑。
特斯拉/xAI:马斯克曾是OpenAI创办人之一,但现在已退出并成立了新的AI公司xAI,目标是了解宇宙真正的本质,试图要打造一个“好的通用型人工智能(AGI)”。2023年8月28日,已上线1万块英伟达H100 GPU组成的超级计算机集群,将用于训练特斯拉自动驾驶系统FSD与其他各种AI应用。另外,特斯拉Dojo超级计算机将于2023年7月正式开始量产,进一步强化算力基础设施。特斯拉自研芯片D1作为Dojo核心,基于台积电7nm制程与先进封装技术打造,2023年特斯拉在台积电投片量约5000片12寸晶圆,预计2024年将翻倍至1万片;未来,特斯拉有可能像亚马逊AWS云服务一样,将Dojo对外开放。
苹果:凭借着庞大的Siri群体,似乎对此次ChatGPT风潮较为不屑,在公开发言场合也比较不爱用“AI”一词,而是较常用机器学习(Machine Learning)。整体来看,苹果的AI技术倾向用来优化现有产品的基本功能。不过,库克近日也表示:“AI 在我们产品中几乎无处不在,公司正在进行的生成式 AI 研究,我们有很多工作要做。”
具体再来看看亚马逊,其业务重点原本来自AWS的云计算业务,今年第二季度的收入增长了12.16%,达到了221.4亿美元,但利润却下降了6.12%,为53.65亿美元,经营利润率也下降了4.72个百分点,至24.23%。尽管AWS的收入贡献不算太高,但利润贡献仍占到整体的大头。显然,亚马逊凭借着全球知名云计算服务供应商的身份,其云计算贡献的利润勉强弥补了其零售业务的微薄利润甚至亏损情况。
不过,随着OpenAI与微软的深度捆绑,带动了微软云计算业务Azure的市场占有率,对亚马逊形成了极大地威胁。在近期亚马逊业绩发布会上,CEO Andy Jassy强调云计算业务在近几个季度的利润率大幅下滑,其规模效益似乎正逐渐减弱。但AWS仍是无可置疑的云基建领导者,且在客户数量、合作伙伴生态规模以及功能广度方面均处于领先位置,同时实现了最为强劲的经营表现。人们已经对生成式AI产生了极大的兴趣,但大多数人讨论最多的是应用层,特别是OpenAI通过ChatGPT所做的事情。而亚马逊在底层基座上的能力优势,显然可以成为新的发力点。
一般来说,对于希望应用大模型的企业,自研大模型需要数十亿美元以及多年的训练,这就需要大量资金和设备的支持才行。更为实惠的解决方案是,对一些已经非常强大的开源基础模型进行定制化的微调,以满足自身的多样化业务需求。据预测,到2026年,仅在企业技术方面,这种希望与AI结合的市场规模就将从2023年的近430亿美元上升到980亿美元(约合7168.5亿元人民币),市场空间巨大。
对此,今年4月亚马逊AWS发布了全托管基础模型服务“Amazon Bedrock”,以“关键基础设施提供商”的角色加入了大模型之战,希望从与微软云、谷歌云手中抢回更多市场份额。另外,亚马逊投资Anthropic的更深层次战略目标,包括Anthropic承诺使用AWS自研的AI专用芯片Trainium和AI加速器芯片Inferentia来构建平台,训练和部署未来的AI基础模型。事实上,AWS和Anthropic均表示,他们将在未来的Trainium和Inferentia技术上进行合作。
Anthropic还做出了长期承诺,计划通过Bedrock为AWS客户提供其未来几代AI基础模型的访问权限。相比于其他的一站式的大模型服务平台,Amazon Bedrock的优势在于,用户可将其与亚马逊AWS平台的其余部分集成在一起,更轻松地访问存储在Amazon S3对象存储服务中的数据,并能够从亚马逊AWS访问控制和治理策略中受益。而Amazon Bedrock的重要价值就在于此。这项服务可以让所有人都可以基于已有的大模型、专用的AI算力和工具,再结合自己的数据开始构建生成式AI应用。
可以说,生成式AI改变了云计算服务的竞争格局,使得模型、框架和应用层面的能力提供变得更加重要,同时也促进了“模型即服务”新商业模式的出现。如Amazon Bedrock平台就将大模型变成了一项可直接使用的服务,利于推动各行各业用户方便地接入和应用生成式AI。而商汤科技副总裁唐臻怡也曾向融中财经表示,未来企业可能无需自研大模型和训练,基于通用大模型的基模型底座,再结合自身行业数据,就能生出不同的参天大树。
目前,我国的AI大模型也再加速发展,百度的“文心一言”、腾讯的“混元”、科大讯飞的“星火”……数据显示,国内已至少130家公司研究大模型产品,其中通用大模型有78家。
随着大模型之战愈演愈烈,对亚马逊来说,投资Anthropic的钱已不可再省,甚至必须花出去,才能用来以小博大。而像谷歌、微软、亚马逊、英伟达这样的大厂投资者来说,为当红的AI企业支付高溢价,除了看重这些初创公司的技术前景和潜在市场外,如能顺便拓展下自身业务,增加云端服务器或自家芯片的使用,似乎就会达成一个双赢的局面。
文章来自 “ 融中财经 ”,作者 | 郑伟


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner