# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
有AI,就没搜索。
国内的大模型厂商落地C端,都盯上了AI搜索。
随着5月30号,腾讯宣布推出基于混元大模型的APP“腾讯元宝”,并基于搜狗搜索引擎,上线AI搜索功能。几乎当下所有主流的大模型都在AI搜索上插旗占位。
这其中包括两类,一类是做AI的,一类是做搜索的。
Kimi是大模型内嵌搜索的一个典型代表,从Kimi联网之后,不少用户表示“几乎替代了百度”,搜索更高效了。豆包、文心一言、通义千问、腾讯元宝均属于此类。
另一类则专门推出了AI搜索产品,比如360搜索、秘塔搜索、天工AI搜索、百川AI搜索百小应、百度简单搜索等等。
这其实是一个很讽刺的现象。要知道上个互联网时代,相比于电商、团购这种模式上的创新,搜索是高精尖的技术活,李彦宏捧着一堆技术专利回国,能存活下来的搜索公司更是凤毛麟角。
没想到,到了大模型时代,谁都能来分一杯羹。
国内搜索引擎“一超多强”的格局已经固化多年,当所有人朝着AI搜索进攻,无疑是在往百度多年打下的城邦上扔石头,而百度将如何应战,似乎又能成就一段好看的攻防战。
毕竟隔壁谷歌已经在Google I/O上对看家的搜索业务进行了全面的AI改造,如今,要看百度的魄力如何了。
不客气的说,国内的AI搜索产品,都在抄Perplexity。
这家2022才出来创业公司,被称为是首个AI原生的对话式搜索产品,也被抬举为谷歌最大的对手。
▲ 图源:Perplexity官网截图
和传统的搜索引擎不同,Perplexity通过自己的算法从不同的信息源中搜索并提供结果,其界面简洁明了,提供了多种实用的功能,使用户能够更轻松地获取所需的信息。
主打的就是一个高效。
同时它还包括了多个模块,如探索模块、搜索模块、学术模块、视频模块和社交媒体模块,允许用户根据需求搜索特定领域的信息。也就是说,它不仅能搜索、导出价值报告,还能分类存储,便于用户回溯。
比高效更高效,更解决了当下浏览器有搜索没记忆的短板。
创新式的用户体验让Perplexity迅速获得了市场认可,每月接近有1000万月活用户使用。在不到两年的时间里,获得了英伟达、亚马逊等不同科技巨头的6轮融资,估值可能达到25亿到35亿美元。
而这样一个广受用户和资本市场追捧的新一代搜索产品,居然只是基于GPT-3.5的API调试出来的结果。
王小川不只一次讲过,中国大模型的机会是:“基于不够好的模型,做出更好的产品。”
好了,现在这个机会也被国外抢了先。如同Sora爆火之后,中国开始做自己的Sora一般,AI搜索产品也开始纷纷效仿Perplexity,毕竟创新力虽然差一些,但1:1的工程式复刻,它们还是很在行的。
抄的最像的是秘塔搜索。不止是在UI设计上对Perplexity的照搬,也“抄”到了它的灵魂,体现了一种“中国式高效”。
▲ 图源:秘塔搜索界面截图
秘塔在搜索的过程中,可视化了整个搜索流程(虽然这没什么用,但用户就爱看这个),并将搜索结果整理成大纲,相关事件、相关组织、相关任务和信息来源都可以清晰查到。


▲ 图源:秘塔搜索界面截图
相比之下,360AI搜索的结果,只展示了天工AI搜索和360搜索,显然并不全面,页面设计也相对老套。实在称不上好用。

▲ 图源:360AI搜索截图
而被360AI搜索点名了的天工AI搜索,从产品形态上更像是一个大杂烩,集合了AI搜索+对话+文生图+Agent,昆仑万维想把大模型的所有能力都塞在一款产品里。
▲ 图源:天工AI搜索官方截图
但从搜索结果来看,天工搜索不仅整理出了AI搜索的产品,在增强版中分析出了他们的功能特点、用户体验,同时比较和分析了它们的相同点和不同点,更加理解用户提问的意图。
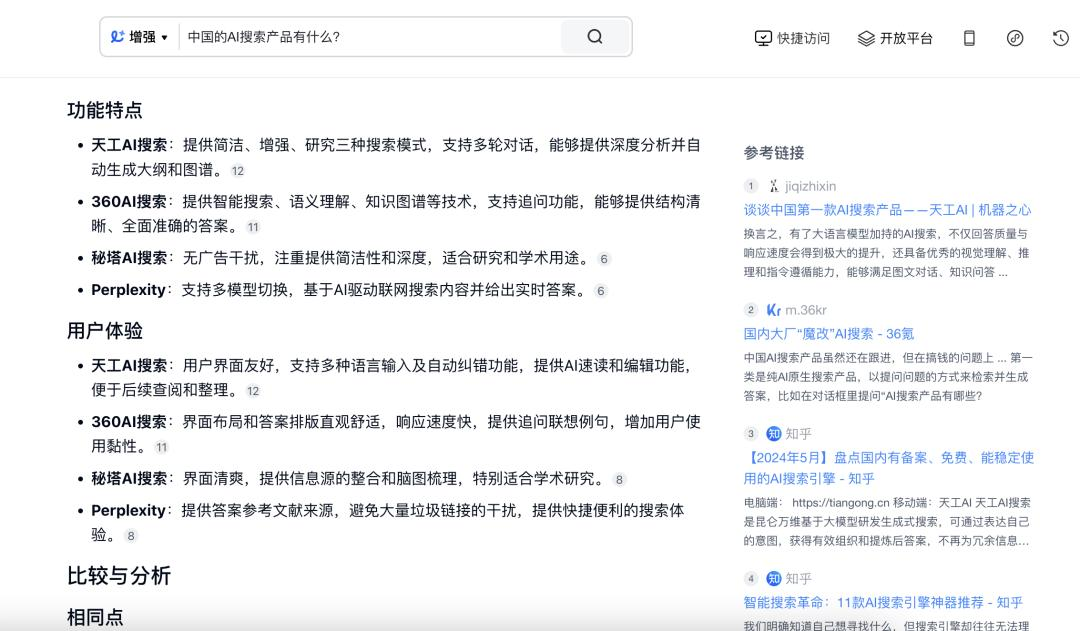
▲ 图源:天工AI搜索界面截图
我们发现,在秘塔搜索和天工AI搜索中,都存在着简洁版、深入/增强版和研究版,这三个版本的搜索量和回答逐步详细,也是参考了Perplexity的普通版本和Pro版本,并开始对Pro版收费,用户订阅是Perplexity的一部分核心收入。
虽然当下国内的AI搜索产品都是免费的,但是参考Perplexity的路径,当免费用户达到一定体量时,未来或将开始收费模式。
哦对,在众多搜索产品中,我们还抓到了一个做搜索相对有经验但是疯狂胡说八道的产品:百小应。
基于王小川曾创立搜狗积累下来的大量搜索经验,不知道是百川本身基座大模型的能力出现了问题,还是对用户意图理解的不清晰,导致了百小应把国内外的公司混合在一起,甚至还捏造了几家莫须有的出来。
▲ 图源:百小应页面截图
当然,以上这些产品(包括Perplexity),通通只能算是自称为“AI搜索”产品,从技术的逻辑来看,这是做了整理、整合、提效的工作,压根不是颠覆性的AI搜索。
仔细想想,或许我们根本就不需要AI搜索,或者说,有AI,就没搜索。
回归搜索的起点,我们需要思考,我们为什么需要搜索?什么场景会搜索?
答案是:当以人作为获取信息和生产力的主体时,我们需要搜索来获得最新的信息,我们需要通过搜索工具来服务生产环节。
搜索是人脑思考时,获取信息的一种延伸。
那如果未来AI作为生产力的主体,AI需要搜索,但人就不再需要了。
事实上在“今日头条”的阶段,人就已经在慢慢简化搜索环节,通过个性推荐来获取信息,未来只要AI够懂“我”,用户与AI直接交互,也就是一种类Kimi的搜索形态,搜索应该无处不在。
但问题也随之而来,这是一条理想化的技术逻辑,彻底颠覆了传统搜索,也就等于颠覆了它的商业模式。
说的再简单点,就是搜索广告。
所有的AI搜索产品的第一产品特点就是:没有广告。没有广告业务对于搜索引擎的影响,无异于釜底抽薪。
远的不谈,在百度刚刚发布的2024年一季报中显示,百度核心收入为人民币238亿元,在线营销收入为人民币170亿元,占总收入的71.4%。百度2023年年报中显示,全年总收入为1346亿元,在线营销收入为751亿元,占总收入的55.8%。
谷歌2024一季度总收入805.39亿美元,其中谷歌搜索及其他收入为461.56亿美元,占总收入的57.3%。
搜索广告业务对于百度和谷歌而言,是名副其实的现金牛,这么多年他们一直在财报中努力增加“广告以外”的收入,但至今为止,依然占总收入的一半以上。
事实上,从2023年3月ChatGPT席卷全球开始,微软和谷歌争的第一个赛点就是Newbing和Google Search,为什么谷歌和百度等了一年迟迟未动?或许不是他们不想改,而是不能改。
探索创业业务,加码对AI的投入需要大量的研发投入和前期成本,如果没有传统广告业务作为支撑,很快这辆马车就会跑不动了。此时百度若全面推进AI搜索,挥刀砍向的第一个就是自己,无异于杀鸡取卵。
技术的逻辑和商业逻辑开始左右互博,也陷入了两难之地。
但如果百度和谷歌“不变”,如同上文而言,大模型公司们早就按捺不住分一杯羹的心,百度已经错过了移动互联网时代,还能在自己的老本行里,被别人占了先么?
不过好在,不管是秘塔搜索还是天工AI搜索对自己的商业模式还尚未清晰。目前C端用户仍然需要通过传统搜索引擎为入口来找到AI搜索产品,以至于他们为了争抢用户,又开始在百度里“卷投流”,钱最后还是让百度赚了。
▲ 图源:百度搜索截图
目前,全球范围内,只有Perplexity作为独立的AI搜索产品开始探索商业化,但很明显,2C的订阅制收费模式只是其中的一部分。
Perplexity正在尝试2B为企业提供内部的高效知识库搜索工具的形式,以及通过用户行为来建立知识树/知识图谱,最终转型成为一个知识平台。
当我们把“有AI,就不需要搜索”的话题抛给Kimi,它给出了这样的答案:当AI可以更深入地集成到各种应用和设备中,用户可能不再需要打开专门的搜索引擎,而是直接通过语音助手、智能设备等进行信息检索。
AI可以作为个人智能助理,根据用户的行为、偏好和需求,主动提供个性化的信息和建议,减少用户主动搜索的需求。

▲ 图源:Kimi生成页面截图
产品无法对抗趋势,趋势无法对抗时代。当下的AI搜索不是技术难题,更是一场深刻的信息革命。
正如每一次技术的革新都会带来阵痛,只是每个人都不希望,自己是抛弃的那个。
文章来源于“自象限”,作者“程心”



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
