Kimi K3设计榜登顶焚诀公开:就藏在思维链里
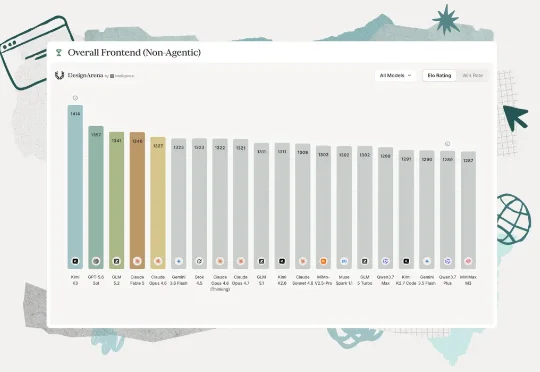
Kimi K3设计榜登顶焚诀公开:就藏在思维链里停停停!Kimi K3的最佳打开方式可能不在Coding——用它做前端设计,才是真·Interesting。在Design Arena最新公布的单次生成前端榜单中,Kimi K3以1414分位列第一,力压Fable 5和GPT-5.6 Sol。
来自主题: AI技术研报
9136 点击 2026-07-25 11:37
 搜索
搜索
停停停!Kimi K3的最佳打开方式可能不在Coding——用它做前端设计,才是真·Interesting。在Design Arena最新公布的单次生成前端榜单中,Kimi K3以1414分位列第一,力压Fable 5和GPT-5.6 Sol。

刚刚,英伟达创始人黄仁勋发出了自己人生第一条推特:在老黄的第一篇帖子中,他分享了一封英伟达签署的信函《开放权重与美国 AI 领导力》,阐述为什么开源模型很重要。他表示,人工智能将改变每个行业,赋能每个公司,并由每个国家构建。开源模型加强安全性和网络安全,加速创新和传播,并实现主权。
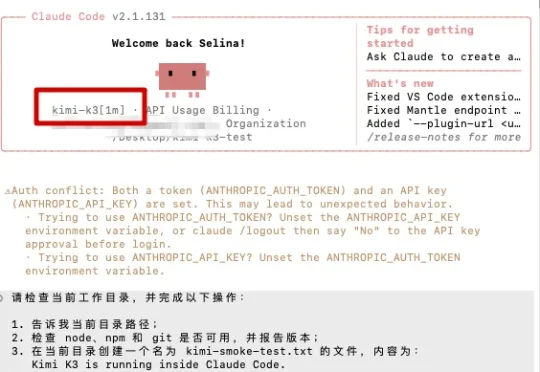
Kimi 官方停止接受新的会员订阅后,还有什么办法用上最新的 K3 成了当务之急,而且,也有一个符合直觉的答案:API。K3 可以通过开放平台直接调用,也能被接入 Claude Code 等第三方编程 Agent。只要准备一个 API Key,再做少量配置,用户似乎就能绕过拥挤的官方入口,把模型能力重新接到自己的电脑上。

最近硅谷有点魔幻。一边被中国开源模型吓得不轻,专门造了个词叫「Kimi panic」;另一边,美国最大的模型托管平台刚被自家模型攻击,救场的偏偏又是一个中国开源模型。就在这个节骨眼上,老黄又整活了。

Kimi K3 发布不到一周,就已成为美国政府的「眼中钉」。据 Axios 报道,特朗普政府内部正在重新讨论,是否应加强对中国开放模型的管控。此前,美国商务部曾考虑将多家中国实验室列入「实体清单」,美国国家安全局和白宫国家网络主任办公室也讨论过发布安全警告,劝阻美国企业使用中国模型。

“「出海四巨头」智谱、Kimi、千问......谁最受外企欢迎? ” 作者丨胡清文 编辑丨徐晓飞 去年这个时候,硅谷讨论的还是中国模型能不能打。但在今年,这个问题已经被一组数据碾过。 OpenRout
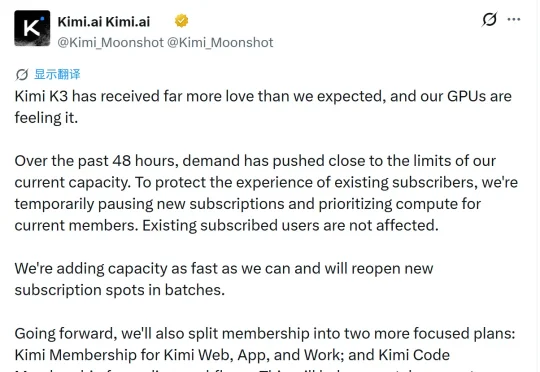
不久前,Kimi 官方宣布,将暂停新会员订阅。月之暗面表示,公司正在增加算力,并将在容量允许后分批重新开放订阅。不过,官方目前尚未公布具体扩容规模,也没有说明新增订阅何时恢复。

算力承压,Kimi 暂停 C 端新用户订阅、OpenAI 战略未来负责人:Kimi K3 性能接近 2026 年第一季度最佳公开模型、Claude Fable 5 官宣永久可用、IDC 预计 2030 年全球活跃智能体将超过 22 亿个

发布之前,我在 X 上看到有人说,测 K3 的感觉就像在测 Fable 5。虽然离 Fable 5 还差一点点 🤏,但超过 Opus 4.8 和 GPT 5.5 基本没有问题。在前端能力,K3 的提升非常明显,我已经用它复刻了前段时间爆火的独立工作室 Abeto 推出的一款 3D 网页游戏 《 Messenger》(ps. 音乐手动配的,主角模型是 K3 自己判断、自主去游戏官网找的)

Kimi K3 是一个 2.8 万亿参数模型,基于 KDA 混合线性注意力机制(Kimi Delta Attention)和注意力残差(Attention Residuals)技术构建,原生支持视觉理解,并拥有 100 万 token 上下文窗口。它是全球首个开源的 3 万亿级别模型,面向长程编程、知识工作和推理等前沿智能场景而设计。