Kimi逼得两大巨头改变定价?奥特曼罕见认错,Claude额度重置
Kimi逼得两大巨头改变定价?奥特曼罕见认错,Claude额度重置外媒Axios称,K3定价远低于它所挑战的高端模型,美国AI公司的高价策略还能维持多久?巧的是,就在最近,两大巨头正在打客户争夺战。此前,特曼在X上发帖,不提新模型,开头就是一句认错:
来自主题: AI资讯
10471 点击 2026-07-18 11:47
 搜索
搜索
外媒Axios称,K3定价远低于它所挑战的高端模型,美国AI公司的高价策略还能维持多久?巧的是,就在最近,两大巨头正在打客户争夺战。此前,特曼在X上发帖,不提新模型,开头就是一句认错:
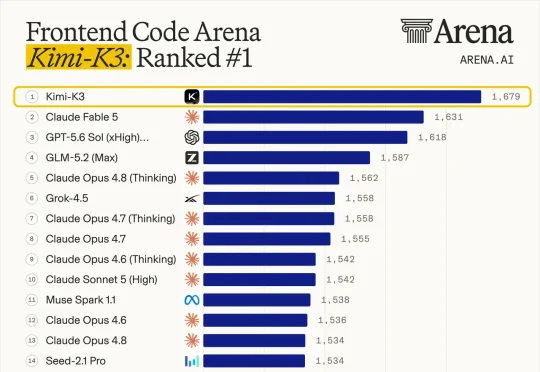
今天凌晨看到 Arena AI 更新 Code Arena 榜单时,我第一反应是有点意外。刚刚发布的 Kimi K3 拿到了 1679 分,排在全球第一,压过了 Claude Fable 5 的 1631 分和 GPT-5.6 Sol 的 1618 分。

7 月 16 日,月之暗面正式发布 Kimi K3:总参数量 2.8 万亿(2.8T),原生视觉理解,100 万 token 上下文,并且——开源权重。这是历史上第一个摸到 2.8 万亿参数量级的开源模型。前任"开源最大模型"的纪录保持者?也是它自己。
这两天,大模型竞技场Arena上出现了一个新的匿名模型,代号Kivine。经过测试和对比,再结合此前Kimi-K2.5和K2.6的匿名代号“Kiwido”和“Kiwire”,越来越多的开发者们开始猜测这个匿名模型其实就是Kimi-K3。

当 Agent 走向生产,云与数据库需要被一起重新考虑。

葬AI身边的朋友常常有个疑问:为什么MiniMax M3做的不够好(问了很多在做模型测评的朋友,也是类似看法),但市场仍然觉得他们是第一梯队?我朋友@朱亦辉的解释是,MiniMax M3的核心科技是叙事能力,让外界觉得他们和Kimi是一个级别,达到一个强行双骄的效果。

浪潮信息宣布,元脑SD200超节点AI服务器率先完成主流领先开源大模型Kimi K2.6、DeepSeek V4、GLM 5.2、MiniMax M3等的高性能优化,并在Kimi K2.6万亿参数大模型上实现Token生成时间快达4.77ms,为Agent场景应用的高效运行提供强大算力支撑。

近日,北京月之暗面科技有限公司发生工商变更,联合创始人汪箴退出股东序列。公开工商信息显示,退出前,汪箴持有公司约0.075%的股份。原因并不在于股份,而在于身份。公开资料显示,汪箴不仅是月之暗面的联合创始人,也是公司现任总裁张予彤的丈夫。
近日,一家叫良配科技的公司拿到了今日资本200万美元的天使轮投资。放在2026年的融资市场里,这条新闻有点特别。很少有人会想到,被誉为风投女王的徐新,这次押注的场景,是相亲。更让人意外的是,做这件事的人来路并不在婚恋行业。
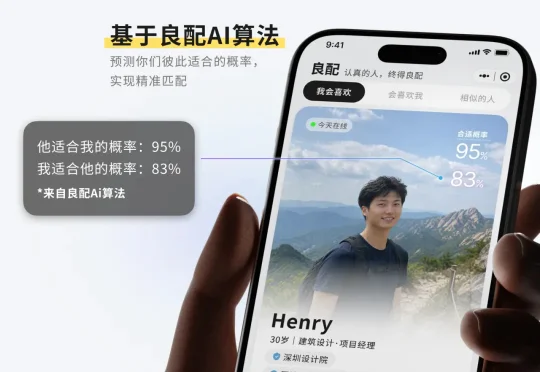
一年前,我从Kimi离职创业,决心把AI技术运用到交友软件中,做一款颠覆性的产品。如果只能用三个词来概括它,那就是:AI技术、1v1匹配、不结婚就退款。今天,我想正式把「良配」介绍给你,也聊聊我们为什么要做它。很高兴与你见面。