# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
计算机视觉是人工智能的眼睛,三维视觉的研究赋予这双眼睛探知真实空间纵深与距离的能力。
如何让机器人在复杂场景里更聪明地路径规划,与周边的一切精准交互?三维视觉模型的发展被寄予重望。
近日,智源研究院联合清北开源发布了当前最大三维视觉通用模型Uni3D,这一10亿参数的三维点云表征模型,取得了主流3D视觉能力的全方位性能突破,堪称三维基础模型中的「六边形战士」。
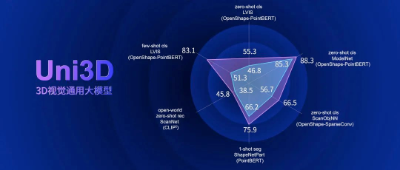
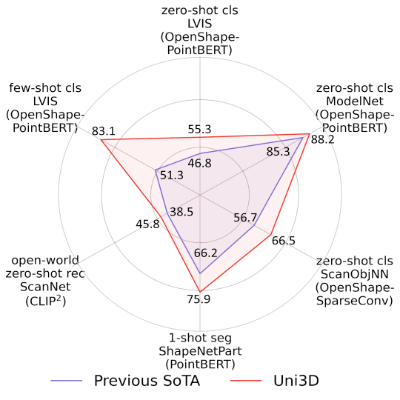
三维视觉能力雷达图:
- 在主流三维视觉榜单上全面超越此前SOTA;
- 对于衡量视觉通用能力至关重要的分类任务,以及零样本识别、理解、分割任务等,都有超预期表现。
值得一提的是,出品Uni3D的智源视觉团队,此前曾发布最强10亿通用视觉模型EVA。
而本次三维视觉模型的突破关键,正是利用ViT技术,将「最强2D」预训练基础经验升维至「最强3D」的极致推进。
论文链接:https://arxiv.org/abs/2310.06773
代码/模型链接:
https://github.com/baaivision/Uni3D
https://huggingface.co/BAAI/Uni3D/tree/main/modelzoo
作为大规模预训练表征模型,Uni3D展现出超预期的通用能力,胜任各项主流视觉能力。
全面发展,全面超越,看看Uni3D的各项成绩怎么样?
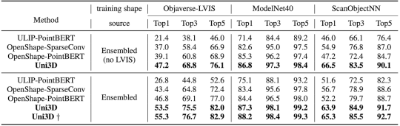
零样本分类任务下评估Uni3D,分别在ModelNet(包含15个类别)、ScanObjNN(包含40个类别)、Objaverse-LVIS(包含1156个LVIS类别中的46832个形状)三个基准下进行实验。
研究团队采用与CLIP2相同的设置在ScanNet测试集下探究Uni3D在现实场景下的零样本识别性能。
与之前最先进的SOTA方法PointCLIP、PointCLIP V2、CLIP2Point和CLIP2 相比,Uni3D表现最佳。
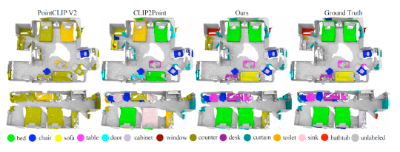
从下图可更为直观地感受到,Uni3D在ScanNet数据集上的开放场景零样本识别结果,相比其他方法更为准确,拥有强大的对真实场景的理解能力。
图中不同颜色代表了模型对于3D场景中不同物体的理解和类别识别,可以看到Uni3D对于场景的理解和真实Ground Truth(地面实况)更加接近,而先前方法如PointCLIP V2和CLIP2Point则有大量的错误识别。
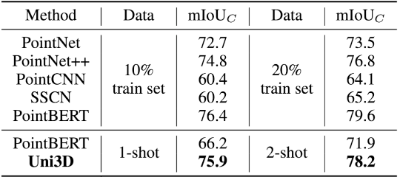
Uni3D在少样本点云部件分割任务上展示出卓越性能。下表结果显示,在各种实验条件下,Uni3D的性能都明显优于Point-BERT等基线方法。
即便只使用每类一个样本训练,Uni3D也达到了使用10%的训练数据的先前基线方法(如PointNet++,Point-BERT)的水平,在训练集的规模相对减少两个数量级的情况下,仍能显示出Uni3D更强的细粒度3D结构理解能力。
从以下在ShapeNetPart数据集的one-shot零部件分割对比图中可以看出,Uni3D可以在one-shot训练中产生更精确的分割结果。
Uni3D可以在仅见过一个训练模型的情况下,取得对测试数据细粒度部件的准确分割,如「飞机机翼」和「发动机」等,这证明了Uni3D强大的表征迁移能力。
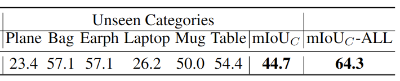
下表为Uni3D在ShapeNetPart数据集上的开放词汇语义分割结果。
对比显示,通过对「可见类别」子集中的部件进行训练后,即便对于未在训练集中见过的「不可见类别」,Uni3D也能精确分割出细粒度的部件类别,这显示了Uni3D强大的开放词汇细粒度推理能力。
将ShapeNetPart数据集分成两个子集:「可见类别」和「不可见类别」。使用「可见类别」下的形状部件的文本描述训练Uni3D,并在「不可见类别」上使用形状部件的文本描述进行零样本测试。
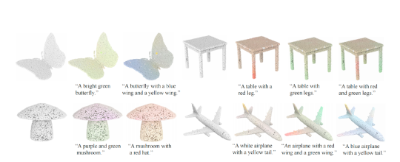
给定一个文本,Uni3D通过优化点云的颜色来提高点云和文本在特征空间的相似度,基于此实现文本操控的点云内容创作和点云绘画。
点云绘制结果,(白色模型是初始点云)。如通过给定语句「拥有一只蓝色翅膀和一只黄色翅膀的蝴蝶」来创作编辑,生成对应的3D点云模型。
Uni3D通过学习到的统一的三维多模态表征,具有感知多个2D/语言信号的能力,可以通过图像或文本输入从大型3D数据集中检索三维形状。
这是通过计算查询图像/文本提示的embedding与3D形状的embedding入之间的余弦相似度来实现了对查询的最相似3D形状的获取。
如在下图中,输入一个图像,Uni3D可以检索与这输入图像最为相似的1-2个形状。
例如上图中,如果输入多张图像,例如一张长犄角的鹿的图像和一张蛇的图像,Uni3D可以找到同时契合这两个输入图像的3D模型:一只长着角的蛇。
将之前已经成熟的「文搜图/图搜图」扩展到「文搜3D/图搜3D」,这使得检索互联网上大规模未标定的繁杂三维模型成为可能,为相关三维领域从业者、创作者搜集素材提供实用工具。
如给定文本「一个高质量的宫殿」,「钢铁侠」,Uni3D就可以从大规模3D数据库中检索到最接近该文本的多个3D模型。
智源视觉团队此前推出了最强10亿通用视觉模型EVA;Uni3D模型的发布,一举将成熟的2D视觉大模型和扩展策略的经验推广到3D视觉领域。
ViT技术在其中扮演了关键角色:
Uni3D采用与2D Vision Transformer (ViT)网络结构完全相同的骨干模型,把三维基础大模型有效扩展到十亿参数规模。
而基于和2D统一的框架,Uni3D可以使用丰富的2D预训练模型作为初始化,无须特殊复杂设计。
Uni3D:一个拥有十亿参数的通用三维视觉表征模型
对于扩大三维表征模型的规模以全面理解爆炸性增长的三维数据,现阶段所面临的主要挑战在于:
针对上述难点,智源视觉团队在构建Uni3D模型过程中提出了2项创新方法,成功将扩大语言和视觉模型的经验转化到了三维领域,为广泛的三维任务提供解决方案,为潜在的下游应用铺平了道路。
研究团队利用一个结构上等同于2D Vision Transformer (ViT)作为Uni3D的基础模型。
唯一的区别在于,将ViT中的分词器替换为一个特定的点分词器,以实现三维嵌入。点分词器首先使用FPS(最远点采样)和KNN(K最近邻)将点分组成局部块,再使用微小的PointNet提取每个块的分词的embedding,输入到Transformer。
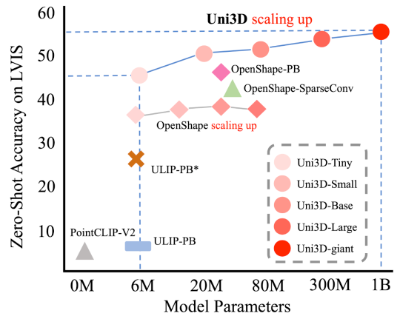
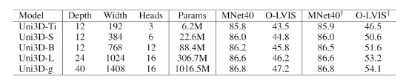
借鉴ViT的扩展策略,逐渐将Transformer从Tiny(6M)、Small(23M)、Base(88M)、Large(307M)扩展到Giant(1B),后将Uni3D的Transformer替换为不同规模的ViT,作为不同模型大小的Uni3D的扩展版本。在不同模型规模下的性能表明,扩展Uni3D的参数量可以显著提高3D表征效果。
Uni3D大模型的提出,证实了在3D表征上大模型的有效性和优势所在,也为后续3D大模型的参数量扩展提供了一条稳定且有效的参考范式。
通过增大参数量,Uni3D取得了显著的效果提升,而先前方法OpenShape在较大的参数量上则有明显的效果退化,证实了Uni3D参数量扩展策略的有效性和优势所在。
借助统一的ViT作为三维表征,Uni3D可以灵活地利用最先进的二维预训练模型来初始化Uni3D。
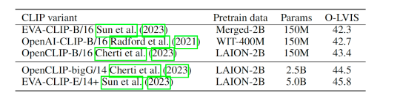
Uni3D不受特定CLIP的限制,可以灵活地将其切换到不同模型规模的现成最先进的CLIP模型,以获得更好的性能。
下图为Uni3D在不同规模的CLIP下的性能,最佳性能是通过智源视觉团队此前提出的最强50亿参数视觉语言基础模型EVA-CLIP实现的。
EVA模型学习了强大且通用的表征,可以作为跨模态对比学习(例如CLIP)的良好初始化,EVA学到的通用模式在改善和稳定Uni3D的训练中起到了关键作用。
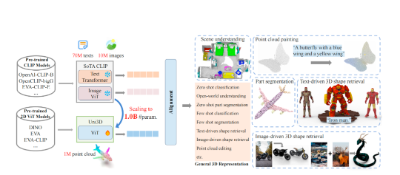
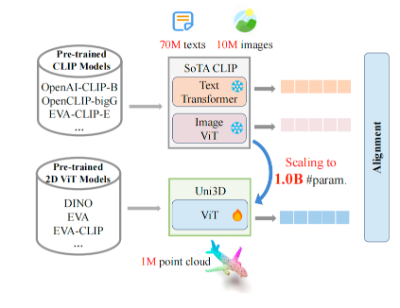
为将二维视觉和语言的理解引入到三维领域,需要训练统一的模型,以对齐语言、图像和点云的表征。
通过在二维视觉领域全面探索扩展ViT的方法,在采用统一的扩展策略下,研究团队在一个大规模数据集中,包括近百万个三维形状、1000万张图像和7000万个文本配对数据,引入了多模态对齐学习方法来训练Uni3D。
多模态对齐的示意图如图所示。Uni3D是统一三维模型,文本编码器和图像编码器来自于CLIP,它们充当Uni3D的「老师」,通过将其与学习良好的二维/语言表征进行对齐来学习三维表征并提取跨模态知识
参考资料:
https://arxiv.org/abs/2310.06773
文章来自微信公众号 “新智元”,作者 新智元


【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file