# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
去年10月,硅谷VC巨头Vinod Khosla曾在X发文,“忧心忡忡”地称美国的开源大模型都会被中国抄去。万万没想到,8个多月过去,射出的回旋镖最终扎回了自己的心。
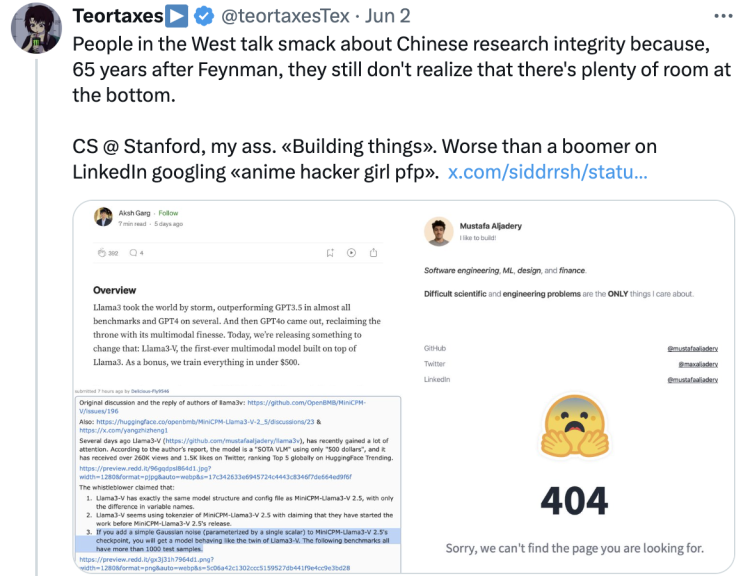
这两天,清华系开源大模型被斯坦福AI团队“镜像级套壳”事件在海内外AI社区闹得沸沸扬扬。起因是一个来自斯坦福大学的作者小组发布了一篇名为《Llama 3-V:Matching GPT4-V with a 100x smaller model and 500 dollars》的文章,称他们仅用500美元,就能基于Llama3训练出一个比GPT-4v、Gemini Ultra、Claude Opus更强的SOTA开源多模态模型,而且尺寸还比GPT-4v小100倍。
牛校出身加上超值性价比和惊艳效果,让Llama3-V迅速爆火,当天X帖子浏览量就突破30万,转发超300次,还瞬间冲上HuggingFace Trending Top 5。但很快就有不少细心网友发现了其中“猫腻”:这个出尽风头的Llama 3-V竟然从模型结构、配置文件到代码,都几乎原样照搬了清华大学自然语言处理实验室与面壁智能合作开发的MiniCPM-Llama3-V 2.5。
一时间质疑声四起,越来越多关于Llama 3-V和MiniCPM-Llama3-V 2.5的对比截图和抄袭证据被扒了出来。Llama3-V团队更是在苍白辩解、删评论之后,直接心虚地删除了X官宣推文和HuggingFace、GitHub上的项目链接,对网友要求的回应也是几经删改。
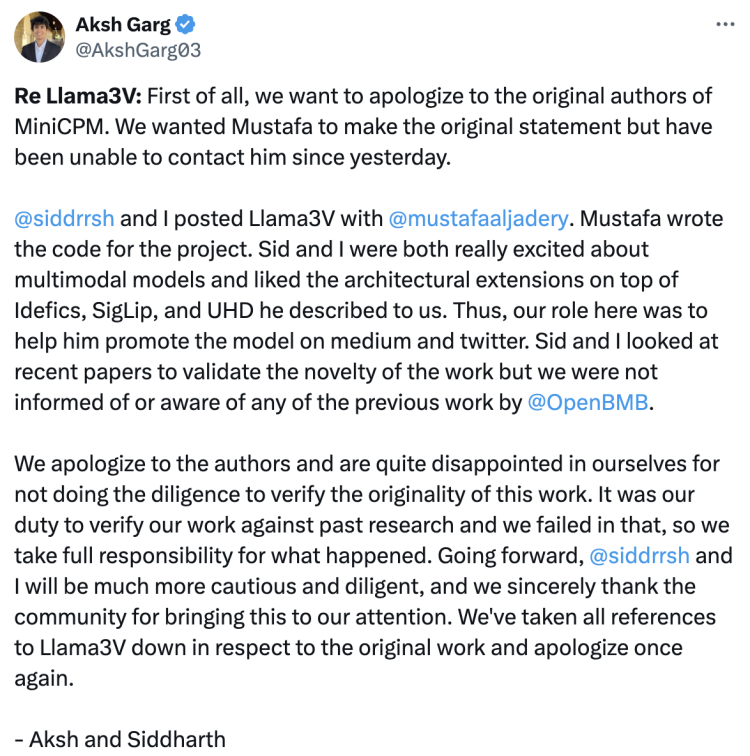
事件持续发酵,终于在6月3日上午,其中的两名作者Aksh Garg和Siddharth Sharma顶不住压力,在X联合署名发表正式回应。他们首先向MiniCPM原作者诚挚道歉,表示原本希望另一位作者Mustafa Aljadery发布原始声明,“但自昨天以来一直无法联系到他”。
Llama3-V虽是三人共同发布,但代码部分都是Mustafa一人编写的。“Sid和我都对多模态模型非常感兴趣,并喜欢他向我们描述的基于Idefics、SigLip和UHD的架构扩展。因此,我们的角色是帮助他在Medium和X上推广该模型。Sid和我查看了最近的论文以验证这项工作的创新性,但我们并不知道也未被告知有关OpenBMB的任何先前工作。”
二人称对自己没有做好尽职调查以验证原创性感到非常抱歉。“我们有责任将我们的工作与以往研究进行对比验证,却未能做到这一点,我们对此负全部责任。今后,@siddrrsh和我将更加谨慎和勤奋,衷心感谢社区提醒。我们已尊重原始工作,删除了所有对Llama-3V的引用,再次表示歉意。”
在Medium的项目文章上也更新了回应:
“非常感谢在评论中指出与之前研究相似之处的各位。我们意识到我们的架构与OpenBMB的《MiniCPM-Llama3-V 2.5:在手机上的GPT-4V级别多模态LLM》非常相似,他们比我们更早实现了这一点。为尊重原作者,我们已经下架了我们的原始模型。

那位被他们指为“抄袭主要责任人”的Mustafa Aljadery尚未发声,X账号也已经设为隐私状态。
不过,两名团队成员的道歉和自证清白并没起到什么正向效果,反而再次被“围攻”了。
网友一针见血地指出:“将罪责都推给一个人是不对的。如果你们压根没有做这项工作,就不该因此获取荣誉。但你们这样做了,所以也必须承担责任。你们本可以只帮助他推广而不要求成为共同作者。”
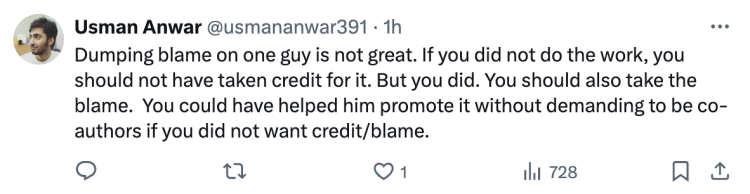
“所以你们的计划是为一个你们完全没有参与构建的项目平分功劳,很有道理。”
“显然,将所有三个人的盗窃行为都归咎于一个人是不明智的。”
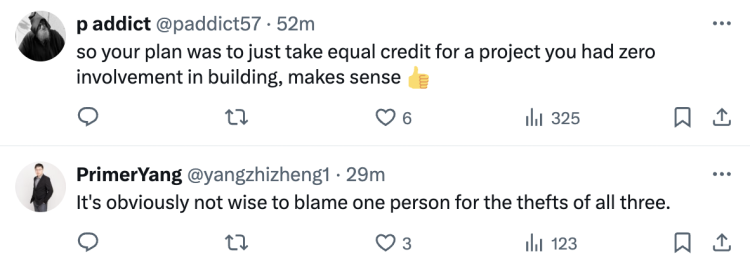
项目发布时明明标注了三人一起构建,现在翻车了就急于做切割,这种能同甘不能共苦的做法令网友不齿。
“我完全明白Mustafa是因为抄袭和撒谎而被责备,但你们想要从他的工作中获得荣誉而完全没有参与编写代码,这让我感觉不太对…...我知道他们的角色是在社交媒体上推广,但两个学生推广这些模型并声称他们是项目的一部分,这难道不奇怪吗?”
对此硅星人也已联系了该项目作者,以寻求进一步解释,目前团队尚未就此回应。我们会在收到回复后向大家更新。
若简单复盘这起事件,就要回溯到5月29日斯坦福团队发布的官宣原文。文中这样描述Llama 3-V的诞生缘起:
“Llama3横空出世,在几乎所有基准测试中表现优于GPT 3.5,并在几个方面超越了GPT4。然后GPT 4o推出,以其多模态的精妙重新夺回王座。今天,我们发布了一款改变现状的产品:Llama3-V。”

尽管通篇全文故意一字未提MiniCPM-Llama3-V 2.5,仍被火眼金睛的HuggingFace用户们发现其涉嫌“套壳”。对此llama-3V给出了一个自相矛盾的解释,表示他们只是使用了MiniCPM-Llama3-V 2.5的tokenizer,并宣称自己在MiniCPM发布前就开始了这项工作——如此“未卜先知”,实在令人感到匪夷所思。
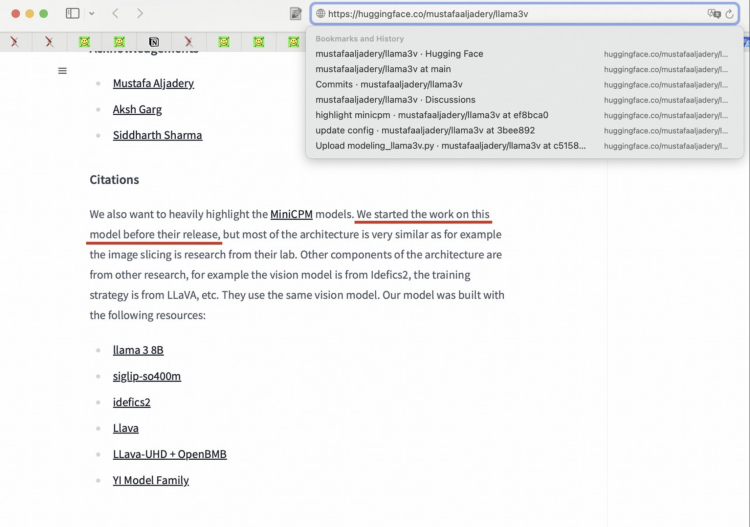
网友继续发力,6月2日起在Github Issue和X平台发布多项证据。
前者只是进行了一些重新格式化,并把图像切片、分词器、重采样器等变量重命名,而整体重合度令人震惊。

Llama3-V作者提到了引用LLaVA-UHD架构,并列出关于ViT和LLM的选择差异。却刻意隐瞒Llama3-V在很多具体实现上与MiniCPM-Llama3-V 2.5完全相同,但与LLaVA-UHD大不相同。甚至还使用了包括MiniCPM-Llama3-V 2.5新定义的特殊符号在内的,完全相同的分词器。
Llama3-V的技术博客和代码也出卖了他们抄袭的事实。例如感知器重采样器(Perceiver resampler)是单层cross-attention,而不是双层self-attention。

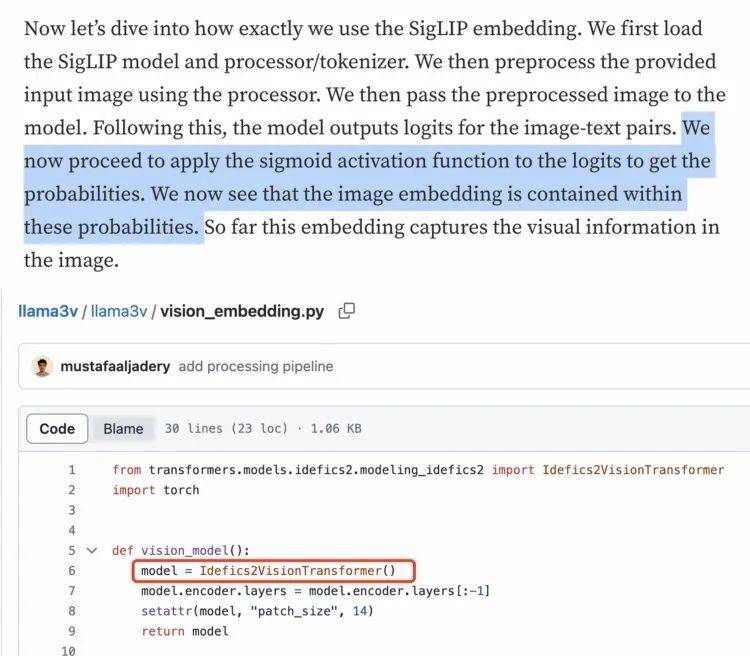
更尴尬的是,视觉特征提取其实不需要Sigmoid激活。但下图所示的Llama3-V技术博客里作者理解是错的,代码却是正确的。表明作者压根不理解“自己的代码”,唯一说得通的解释就是“拿来党”了。
根据网友反馈,当运行Llama3-V时,作者提供的代码无法与HuggingFace上的checkpoint配合使用。但若把Llama3-V模型权重中的变量名改为MiniCPM-Llama3-V 2.5使用的名称后,模型反而能成功运行MiniCPM-V。
这….
另外,网友尝试在MiniCPM-Llama3-V 2.5的checkpoint上添加一个简单的高斯噪声,结果不出意外地,意外得到了一个行为与Llama3-V极为相似的模型。这不就证明Llama 3-V其实相当于MiniCPM的加噪声版本?

另外还有一个坐实抄袭的铁证:MiniCPM-Llama3-V 2.5的一个实验性功能是能够识别清华简,这是一种非常特殊且罕见的中国战国时期(公元前475年至公元前221年)写在竹简上的古文字。
这些训练数据的采集和标注均由清华NLP实验室和面壁智能团队完成,相关数据属于内部所有,尚未对外公开。MiniCPM-Llama3-V 2.5在经过专有数据训练后,才能初步识别清华简的文字,这也相当于MiniCPM-V的“胎记”特征。
然而令人惊讶的是,不可能获得专有数据训练的Llama3-V,隔空就具备了相同的能力。

甚至连犯的错都跟MiniCPM一毛一样:

这绝不可能是巧合。面壁团队在1000张竹简图像上测试了几种基于Llama3的视觉-语言模型,并将每对模型的预测精确匹配进行比较,结果显示,正常情况下每对模型间的重叠为零。而Llama3-V和MiniCPM-Llama3-V 2.5之间的重叠竟达到惊人的87%。
除此以外,Llama3-V也显示出了类似MiniCPM-Llama3-V 2.5的强大OCR能力,甚至包括中文。很难想象仅用500美元成本便可实现如此复杂的功能。
舆情热度继续走高,从X、HuggingFace、Reddit,一路延烧到微博、知乎。越来越多的中外网友出来围观和严厉指责,Llama3-V也迫于此删除了社区所有相关的项目链接。
面壁智能CEO李大海在朋友圈发声,表示对这件事深表遗憾:“技术创新不易,每一项工作都是团队夜以继日的奋斗结果”。“希望团队的工作被更多人关注与认可,但不是以这种方式”。

联合创始人刘知远在知乎社区发表了一篇真诚恳切又意味深远的正式回应。文中提到Llama3-V团队未能遵守开源协议对他人成果的尊重和致敬,严重破坏了开源共享的基石。但他也提到,三位作者还很年轻,有两位仅是斯坦福大学的本科生,未来还有很长的路要走,“如果知错能改,善莫大焉”。
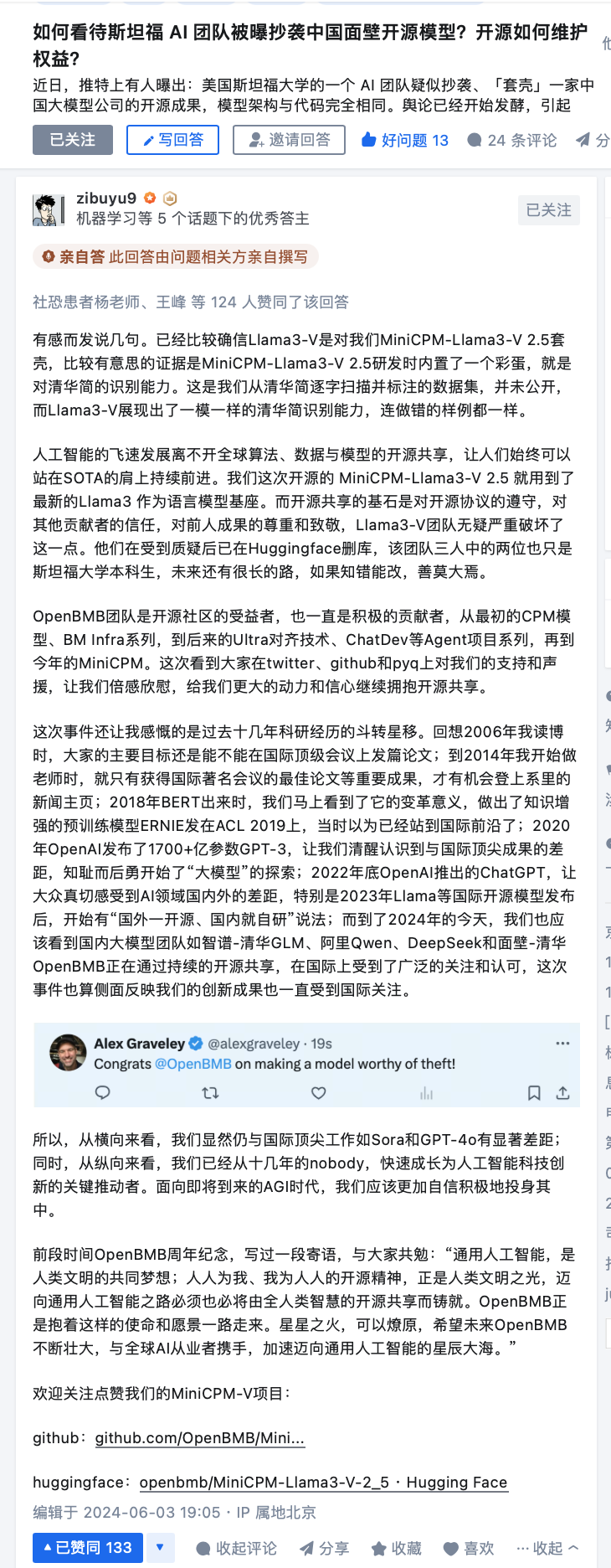
但X网友就没有这么宽容了,直言:“现在无法轻易相信任何事情,GitHub发布、简历,所有事情都能造假和抄袭。”
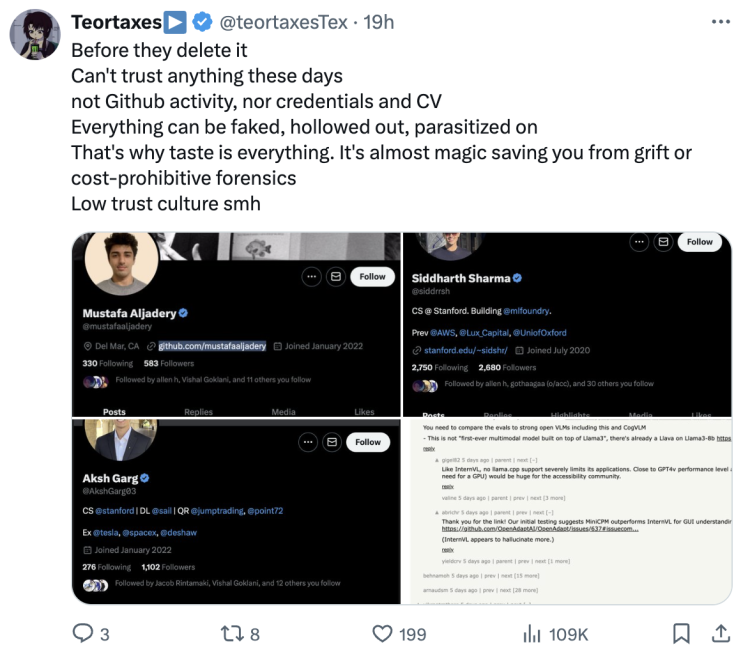
还有用户更狠,在GitHub留言建议,直接联系斯坦福教授举报学术不端。
Llama3-V作者背景深挖:集齐斯坦福、牛津、SpaceX、AWS亮眼元素
细看这次成为众矢之的的三位年轻作者,确实身披许多光环:
Siddharth Sharma是斯坦福大学CS本科生,专注于机器学习和分布式系统。曾在牛津大学作为访问学生学习机器学习理论、强化学习和对齐技术。还在AWS的Deep Engine Science团队和Foundry技术团队工作过,目前在Lux Capital从事AI和数据相关工作。曾经的OpenAI大将、开发者关系主管Logan Kilpatrick也关注了他的推特。
大模型开发等项目经验很丰富,发布过涉及开源AI、数据密集型系统、量子计算、强化学习、计算机视觉等多篇文章。

Aksh Garg是Medium上文章的发布者。他也是斯坦福的CS专业本科生,预计今年6月毕业,GPA为4.1/4.0。背景更是包括了SpaceX的Starlink软件工程实习生、USC Keck医学院机器学习研究员、Stanford KhatriLab本科研究员、Caltech TensorLab强化学习研究实习生和Viridium Hydrogen创始团队成员及机器学习工程师等。
被他们俩切割的Mustafa Aljadery是一位经验丰富的软件工程师,目前在Beehiiv工作,也是团队中唯一的全职在职人员。
Mustafa本科和硕士均毕业于南加州大学,主攻深度学习和数学。此外,他还曾在Citadel Securities担任量化夏季实习生,并且是Disperse的创始人兼软件工程师,在南加州大学进行Transformer注意力层和注意力提取的研究,并在麻省理工学院从事过并行计算的研究工作。
此次Llama3-V对MiniCPM-Llama3-V 2.5的套壳事件引发巨大关注,一部分原因也是由于三名成员其实都具备出色的学术和技术研发背景,在AI模型领域也深耕已久,本不该把如此“赤裸裸”的照抄描述为自身成果,违背了社区公认的开源精神。
而另一方面,也有不少社区开发者注意到一个细节。
在这场抄袭风波中,三人敢于明目张胆对MiniCPM抄袭,也有一个判断:中国的开源模型一方面十分强大,另一方面在社区里关注度不高。
如此强大的开源模型,发布后,火起来的却是一个套壳的海外版。而且,直到事情闹大,许多看起来本应该对开源社区里最棒的作品持续关注的研究者,也才知道MiniCPM的存在。
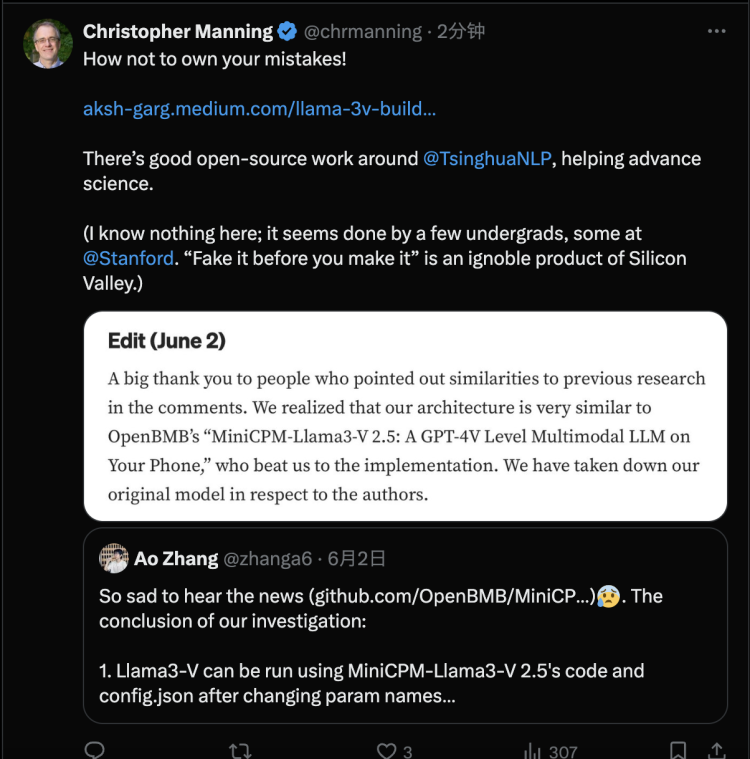
就像在作者那个回复中所说,他们“看了很多最近的论文以验证这项工作的创新性,但却并不知道也未被告知有关OpenBMB的任何先前工作”。
有一个DeepMind的工程师就指出,这件事里有意思的地方是,相比造假的Llama3-V,MiniCPM是真实存在的能达到如此强大能力的模型。但是它获得的关注是如此之少,同样的研究结果就因为不是来自一些知名的常青藤大学,就无法流行起来。
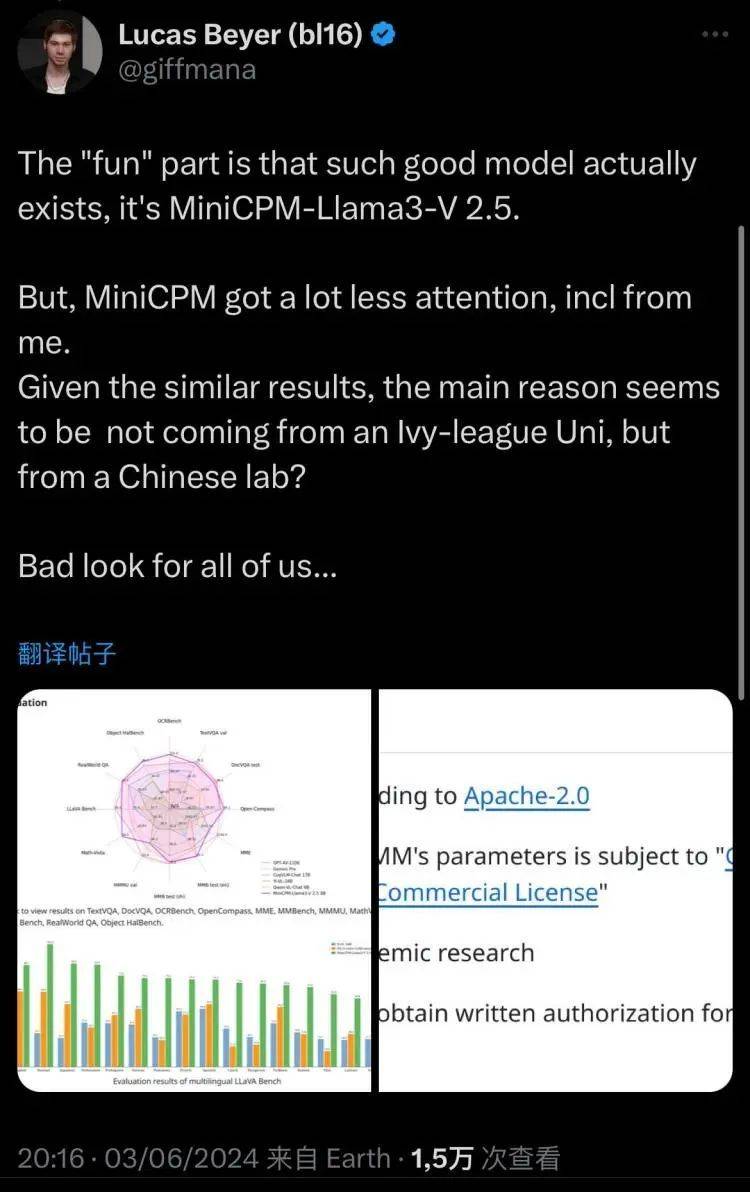
“我们都显得太难堪了。”
本文来自微信公众号:硅星人Pro ,作者:张潇雪



