# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
LeptonAI是贾扬清的创业项目,正如 slogan "Build AI The Simple Way" 所表明的,LeptonAI的目标是简化 AI 模型的部署。
简单来说,LeptonAI 提供了 Python SDK 和云计算平台。Python SDK 可以让没有AI领域知识的普通开发者调用2~3行命令就能部署一个AI模型,然后用一个curl语句或几行Python代码就能完成客户端请求;而 LeptonAI 云平台提供了CPU,GPU和存储资源,开发者可以把创建的AI模型部署到这里,就能提供公开对外的AI服务。
AI模型创建支持 HuggingFace,也就是说可以将 HuggingFace 上海量的模型集成到自己的应用中。同时 LeptonAI 也支持从 GitHub 仓库创建 AI 模型,给了开发者更多的选择。
经过一段时间的体验后发现,LeptonAI Python SDK 设计的很优雅,用起来很舒服,而云平台的操作也很丝滑,有贾扬清大神亲自操刀写代码,SDK和云平台的质量绝对是信得过的。
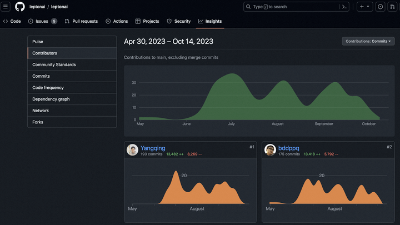
贡献代码最多的是还是贾扬清
那 LeptonAI 是否解决了一些 AI 部署中的痛点问题呢?我认为是的。根据之前的经验,跑一些 AI 开源模型成本还是挺高的。
简单来说,跑一个开源模型,需要下面这些流程:
需要安装Conda虚拟环境
拉取开源代码源码
安装依赖 Python 包
下载 Checkpoints
跑 Demo 命令或 UI
就算整个过程中没有遇到问题,整个流程走下来,跑起来一个模型至少也得半个小时。
而实际情况可能更糟糕,大概率会遇到下面的问题之一或者之N:
开源代码没有指定Python版本,用新/老版本的Python运行报错
开源代码没有指定CUDA版本,用新/老版本的CUDA,运行报错
当前操作系统对应的CPU和GPU组合未经测试,运行报错
编译Pytorch所用的cuDNN版本和系统现在的cuDNN版本不一致,Pytorch插件编译报错
依赖 Python 包版本冲突,需要某个特定版本才能正常工作
之前代码运行正常,更新某个包版本后运行报错
默认 Demo Python 脚本运行报错,需要查看源码定位修复问题
某些OP不支持half精度,运行报错
某些OP不支持mps后端,运行报错
网络状况不佳导致 GitHub 拉取代码失败,HuggingFace 下载模型失败
...
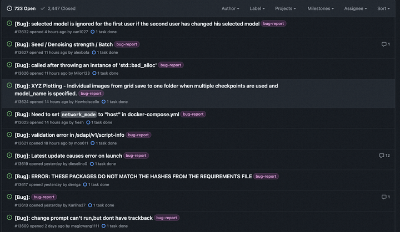
以 stable-diffusion-webui 这个著名的AIGC库为例,光带bug-report标记的issue就有3000多个:
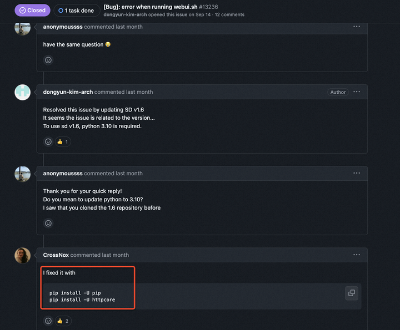
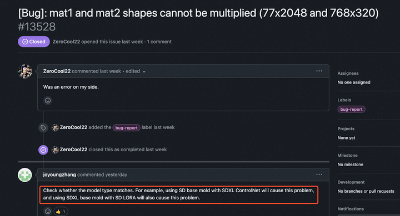
随便看几个例子,都能发现上述这些问题的身影:
也就是说,大家在 AI 部署中遇到了非常多的问题,而不是没有问题。
因此简化 AI 的部署,是很有意义的方向,做的好的话,能减轻很多人的痛苦。根据我的经历,在使用 LeptonAI 部署模型时,我还没遇到过上面提到的这些问题(当然现在使用的次数也还比较少)。
LeptonAI 的盈利模式也很清晰,虽然 Python SDK 和 HuggingFace 上的模型都是开源的,但由于 LeptonAI 提供了云服务来部署算法,因此可以通过云服务的硬件资源(GPU,CPU和存储)来收费,在 Lepton Python SDK 将部署问题大大简化后,降低了AI应用的门槛,可能会出现更多的开发者来提供更好的创意,做出更多更棒的App,产生更加实际的业务成果。如果AI算法真的能提供实际的业务价值,那应用开发者肯定愿意将收入中的一部分给到 LeptonAI 平台
但这里也有一个问题:LeptonAI Python SDK 似乎是可以部署到任意的云计算平台的,也就是说如果阿里云、亚马逊云提供的 GPU 价格更低,那开发者可能就会迁移自己到这些平台,也就是用 LeptonAI Python SDK,但不用你的 GPU 资源。在这个角度下,LeptonAI到底能不能赢得用户,产生正向收益,还不好说。
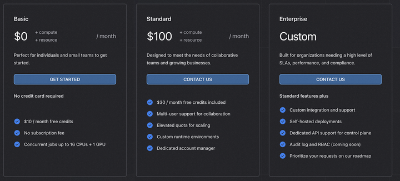
具体到云平台的收费模式,采用 SaaS 中比较常见的基础版免费、Pro版收费的方式。基础版是每个月会给用户会赠送10美元的券,可以方便个人开发者和小的初创团队对进行前期的简单实验验证。标准版每个月100美元,还有企业可以定制:
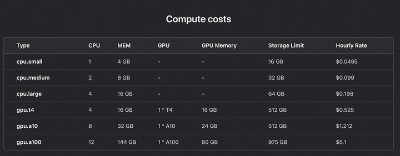
计算资源的收费情况:
算一下是不便宜的。所以免费用户记得用完及时关掉服务,否则很快10美元就用光了(现在是默认没有请求1小时后停止部署的服务)。
从现在的信息看,LeptonAI 现阶段的目标市场应该是欧美,目标客户应该是个人开发者或者中小公司,因为定价是美元,支付采用Stripe,这些都是国内用户不太方便使用的。
其实国内使用还有另外一个影响很大的因素:HuggingFace 目前在国内网络访问不了(实在想不通有什么理由封禁HuggingFace),上面的AI模型都是用不了的,想要部署 HuggingFace 上的模型要费一些周折。
另外 LeptonAI 最近开始公开内测了,想要试玩的朋友可以在官网注册账号申请。
在公测的Blog中,介绍了几位创始人之前的项目经历,最后也自豪地宣称他们是"make building awesome AI applications as simple as possible"最好的人选。
正如 Caffe 开启了深度学习框架的新时代,希望 LeptonAI 也能开启 AI 部署的新时代,未来如何发展,让我们拭目以待。
后面会从网站提供的自部署模型体验、部署HuggingFace上模型、部署GitHub上自己开发的模型几个部分进行展开。
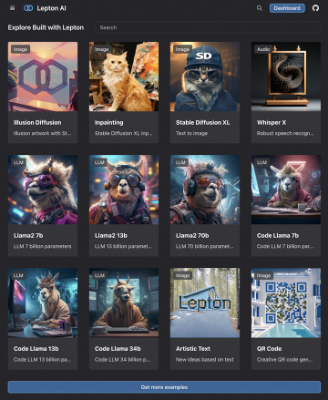
https://www.lepton.ai/playground 提供了很多LeptonAI自部署的开源模型,如SDXL,Llama 2, Code Llama等,跟HuggingFace平台功能类似。基于LeptonAI SDK,开发者可以在自己的GPU服务器上快速地搭建这些模型服务。
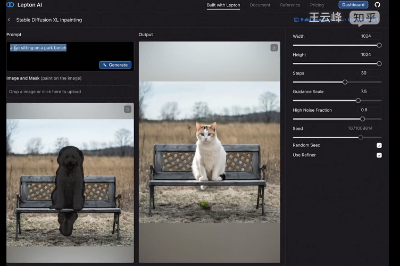
下面的视频截图就是展示了以SDXL Inpainting为例,上传一张图像,mask掉一些区域,再结合一句Prompt,就能补全出对应的区域:
Lepton的含义是轻子,是一个物理学概念,根据维基百科:
轻子是一种不参与强相互作用、自旋为1/2的基本粒子。电子是最为人知的一种轻子;轻子又分为两类:“带电轻子”与“中性轻子”。带电轻子包括电子、μ子、τ子,可以与其它粒子组合成复合粒子,例如原子、电子偶素等等
公司命名为 LeptonAI Inc,科技属性拉满。
LeptonAI Python SDK 的基本模块是 Photon (光子),基本上可以理解为算法模型,如 SDXL,Llama2 都可以看作是 Photon。
Lepton 一个独到的地方是,将所有不同来源的算法模型统一到Photon对象中,比如HuggingFace上的一个模型可以用来初始化Photon,也可以从GitHub上的源代码来初始化Photon。
基于这种简化,所有算法模型都能通过统一的对外接口来展示,方便了模型的部署。当然为了简单统一的接口,源码内部就需要对不同来源的模型进行适配,是以内部代码的复杂度增加来换取对外接口的简洁一致。
更准确、详细的内容,请参考官方文档。
使用LeptonAI的Python leptonai 包可以进行方便的Photon创建和部署。
首先用pip 安装 leptonai 包:
pip install -U leptonai
输入 lep --help 查看是否安装成功。 LeptonAI 的 CLI 命令是 lep,包含所有你需要的功能,如 Photon 创建、部署,登录云平台等。
为了在 LeptonAI 云平台部署模型,确保你已经申请拿到了公测权限。
4.1 基于 HuggingFace 现有模型
官方文档展示了在 LeptonAI 云平台部署 GPT-2 的操作流程,但由于GPT-2效果一般,实际上用处不大,这里以目前效果比较好的SDXL为例来展示如何部署HuggingFace到自己的 LeptonAI 实例上。
首先是用 lep photon create 创建 Photon:
lep photon create --name sdxl --model hf:hotshotco/SDXL-512
--name 是自定义的 Photon 名字,--model 是Photo 下载模型的地址,可以是一个HuggingFace模型名字,也可以是一个GitHub地址。
这里用 hf: 开头表示 HuggingFace 上的模型,<user_name>/<model_name>表示模型的路径。
这里会从 HuggingFace 上拉取模型信息,所以需要能访问 HuggingFace。国内访问hf有问题的小伙伴可以用GitPod这个神器。
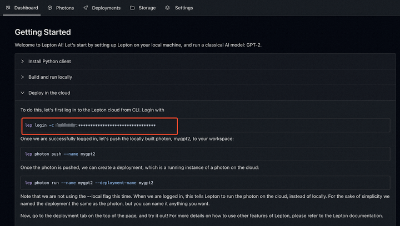
然后为了部署模型到云平台,需要登录 LeptonAI 的 dashboard,查看自己的key,复制 lep login 命令:
lep login -c xxx:xxxxxxxxxxxxxxxx
登录成功后,就可以用 lep photon push 命令将本地创建好的 Photon 推送到 LeptonAI 云平台:
lep photon push --name sdxl
然后在 Dashboard 网页上进行操作,对 Photon 进行部署:
部署完成后,就相当于有了一个公网可以访问的AI服务,通过下面的Python命令就可以访问这个服务:
import io
from PIL import Image
from leptonai.client import Client
LEPTON_API_TOKEN = "xxxxxxxxxx"
client = Client("xx", "sdxl", token=LEPTON_API_TOKEN)
data = client.run(
num_inference_steps=25,
prompt="a photograph of an astronaut riding a horse",
seed=42,
)
# 将服务返回的 bytes 数据保存为图片
image_data = io.BytesIO(data)
image = Image.open(image_data)
image.save("output_image.jpg")
同理也可以用 Python 的 requests 包来发送请求,这样的好处是客户端就不需要安装 LeptonAI 的 Python包了,毕竟它的依赖还是比较多的,下一个例子中会展示requests的用法。
LeptonAI 也支持从 GitHub 创建 Photons,只要你的代码类继承了 lepton的Photo基类,就都可以正常部署,对于许多想要新建自己算法的人来说是个好消息。下面用一个简单的提取图像边缘的例子来展示怎么自定义算法并且部署到 LeptonAI 云平台。
我的代码仓库在 https://github.com/vra/canny-lepton-photon,实现在 canny.py:
import io
from io import BytesIO
import requests
from urllib.request import urlopen
from leptonai.photon import Photon, PNGResponse
# 需要继承 Photon 类
class Canny(Photon):
"""Canny 边缘检测算子"""
# 这里的依赖 Package 会在创建 Photon 时自动安装
requirement_dependency = [
"opencv-python",
"numpy",
"Pillow",
]
# 用这个装饰器表示这个一个对外接口
@Photon.handler("run")
def run(self, url: str) -> PNGResponse:
# 将第三方库的 import 放到实际执行代码中,否则如果本地没有这些包,
# 在创建 Photon 时报错
import cv2
import numpy as np
from PIL import Image
# 读取图像数据
image = np.asarray(Image.open(io.BytesIO(urlopen(url).read())))
# 进行边缘检测
edges = cv2.Canny(image, 100, 200)
edges = Image.fromarray(edges)
img_io = BytesIO()
edges.save(img_io, format="PNG", quality="keep")
img_io.seek(0)
return PNGResponse(img_io)
由于GitHub不再支持命令行密码登录了,所以需要在这里创建token,然后用token替代密码来登录。 复制刚才创建的token,在环境变量中进行设置:
export GITHUB_USER={YOUR_GITHUB_USERNAME}
export GITHUB_TOKEN={THE_TOKEN_GENERATED_FROM_STEP_1}
然后创建 Photon,模型名字格式是 py:{GIT_REPO_URL}:{PATH_TO_SCRIPT}:{CLASS_NAME}:
再推送到云平台:
lep photon push -n canny
注意:可以多次修改代码,多次创建同名的 Photon,会产生不同的版本,然后推送最新的 Photon 到云平台。
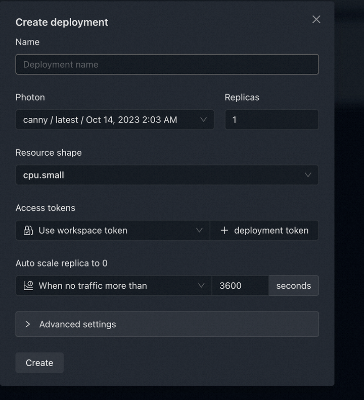
然后在云平台通过可视化界面部署,选择部署名字,部署的资源种类等:
部署完成后,就可以用下面的Python代码来推理结果:
import io
import os
from leptonai.client import Client
from PIL import Image
api_token = os.environ.get('LEPTON_API_TOKEN')
client = Client("lq87wh9y", "canny", token=api_token)
data = client.run(
url="https://i.stack.imgur.com/WsJGN.jpg"
)
image_data = io.BytesIO(data)
image = Image.open(image_data)
image.save("canny.jpg")
原始图和Canny结果图:
如果不想用LeptonAI Python包,可以用 requests网络请求包来完成服务:
import os
import requests
api_token = os.environ.get("LEPTON_API_TOKEN")
url = "https://xxxx-canny.bjz.edr.lepton.ai/run"
headers = {
"Content-Type": "application/json",
"accept": "image/png",
"Authorization": f"Bearer {api_token}",
}
data = {"url": "https://i.stack.imgur.com/WsJGN.jpg"}
response = requests.post(url, headers=headers, json=data)
with open("b.png", "wb") as file:
file.write(response.content)
或者用部署页面提供的 cURL 命令:
curl -X 'POST' \
'https://xxxx-canny.bjz.edr.lepton.ai/run' \
-H 'Content-Type: application/json' \
-H 'accept: image/png' \
-H "Authorization: Bearer $LEPTON_API_TOKEN" \
--output output.png \
-d '{
"url": "string"
}'
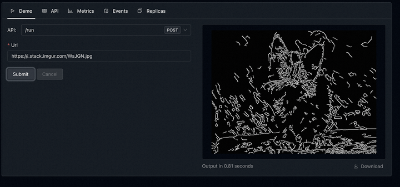
也可以在网页端 Deployment 页面的 Demo 模块中进行推理,输入图片 url 即可得到结果:
里的 Canny 算法这是一个简单的示例,实际中可以替换为任意的 AI 模型。
从这个简单的例子可以看出来,LeptonAI 将 AI 部署中的网站服务后端搭建给省掉了,让开发者专注于写算法部分,而且客户端调用服务的方式也很多,尽可能地简化了AI 服务的调用。
最后如果要深入了解 LeptonAI 的使用的话,建议还是阅读官网提供的详细的文档或者阅读 Python SDK 源码。
文章来自知乎 “点滴技术”,作者 王云峰 阿里巴巴算法工程师


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0