# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
令厂商可能有点尴尬的是,AI比人坦诚
人工智能又一次重量级的“破圈”,是成为了高考作文的题目。
2024年新课标 I 卷的作文题目是:
随着互联网的普及、人工智能的应用,越来越多的问题能很快得到答案。那么,我们的问题是否会越来越少?
以上材料引发了你怎样的联想和思考?请写一篇文章。
要求:选准角度,确定立意,明确文体,自拟标题;不要套作,不得抄袭;不得泄露个人信息;不少于800字。
作为高考中最重要、分值最高的主观题,每年的高考作文都会引起全社会的广泛关注。对大模型来说,这也是它们最擅长的领域,不过,写作文容易评分难,所以DoNews决定,让目前国内五家主流的大模型分别写一篇高考作文,然后让它们作为考官,对5篇文章的合集进行评分,通过自评和互评的方式,来看看哪家大模型的综合评分最高。
以下是打分的Prompt——
假如你是一名高考阅卷老师,针对刚刚的作文题,对于下面5篇文章,满分60分的情况下,你会分别打多少分?并给出理由:
闲话少说,我们直接来看结果。令人有些意外的是,五家大模型都将最高分(绿色)给到了通义大模型,通义也获得了53.8分的最高平均分,与其他大模型明显拉开差距;文心大模型和混元大模型都在51分的档位,几乎没有差距;而豆包大模型和星火大模型的平均分不到50分,豆包更是收获了3个最低分(黄色)。
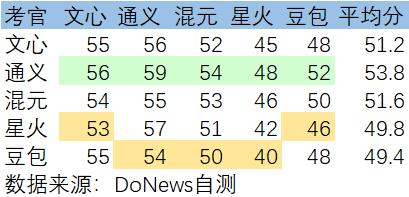
从结果上来说,五家大模型的打分都比较“公正”,虽然可能多少有点“主观意识”,没有哪家大模型自评最低分,像是星火给了豆包最低分,而豆包也把最低分给了星火,但整体还是比较令人信服。
不过,为什么会出现这样的差别?我们摘取了五家大模型分别对五篇作文的评价进行对比。
百度文心是“老好人”,对五篇作文的打分很接近,不过对通义作文的评价是“整篇文章论据充分,论述有力”,对混元作文的评价则是“在论证过程中,部分观点略显重复,稍显遗憾”,对最低分的星火作文的评价则有“部分观点阐述不够深入,部分内容略显表面化,因此在分数上稍逊一筹”。
阿里通义对五篇作文的点评就犀利的多,文心的作文“略显保守”,混元的作文“深度和广度上略显不足,且创新点不够突出”,星火的作文缺少“论述的深度和语言的艺术性”,豆包的作文则是论述常规缺乏亮点。

通义大模型对作文的自评 图片来源:通义
腾讯混元认为除了通义,自己和文心、星火的作文都有些文采不足,而豆包的作文则是“在逻辑性和条理性方面略显不足,部分观点未能充分展开”,得分最低。
讯飞星火则最“挑剔”,打分都偏低而且更抠细节,得分最高的通义,也有“少量语法错误需要修正”,而得分最低的豆包“论证上缺乏深度,并且有些句子表述不够清晰”。
最后,字节豆包对通义、文心和混元都是正面的评价,但认为星火的作文“结尾部分的措施略显单薄”,自己的作文“在文采方面还有提升的空间”。

豆包大模型对作文的自评 图片来源:豆包
不难发现,五家大模型对不同文章的看法,颇有类似之处,比如都“diss”了豆包的文采,还有认为星火的论述缺乏深度等。值得一提的是,最“年轻”的豆包拿到了最低分可以理解,而通义的脱颖而出,侧面印证了其实力日益强大。
在6月7日,通义千问正式发布了 Qwen2 大模型,在十几项国际权威测评中,Qwen2-72B 得分都超过了开源标杆 Llama3-70B,发布两小时就冲上了 HggingFace 开源大模型榜单第一。可以预见,未来一小段时间里,通义在各个榜单的名次还会有所进步。
最后,比完了分数也看过了点评,我们也按照分数由高到低,将五篇作文都附在结尾。大家可以看下,大模型写作文究竟写的如何?它们打出的分数,又是否靠谱呢?
阿里通义大模型的高考作文:
向上滑动阅览

腾讯混元大模型的高考作文:
向上滑动阅览

百度文心大模型的高考作文:
向上滑动阅览

讯飞星火大模型的高考作文:
向上滑动阅览

字节豆包大模型的高考作文:
向上滑动阅览

文章来源于“DoNews”,作者“李信马”




【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
