# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
咳咳,在开始讲之前,先跟差友们宣布个事儿:

这自然的语气,隐约还能听到些换气声,是不是已经有差友快上钩了。
但大伙可别真以为世超要暴露真声,其实这段音频,是我用 AI 做出来的,从打开网址到做好整段音频,统共用了都没两分钟。
可能已经有朋友猜到世超用的是啥 AI 工具,就是最近刚火出圈的那位,ChatTTS 。
刚开源没几天,它的 GitHub 就有一万多颗标星,而且还在继续噌噌猛涨,就在世超在写稿的时候,亲眼看到它突破 2 万大关。。。
网上的热度也贼高,光是 b 站,随便一搜 ChatTTS ,就能弹出一大堆视频来,不是在教大伙怎么安装,就是在夸它有多逼真。
甚至连热度都传到国外了。

其实像 ChatTTS 这类文本转语音( Text to Speech )的工具,市面上一抓一大把,各家做 AI 应用的企业,基本上都有文本转语音的功能。
但和它们不一样的是, ChatTTS 主打的是,最自然地还原人声。
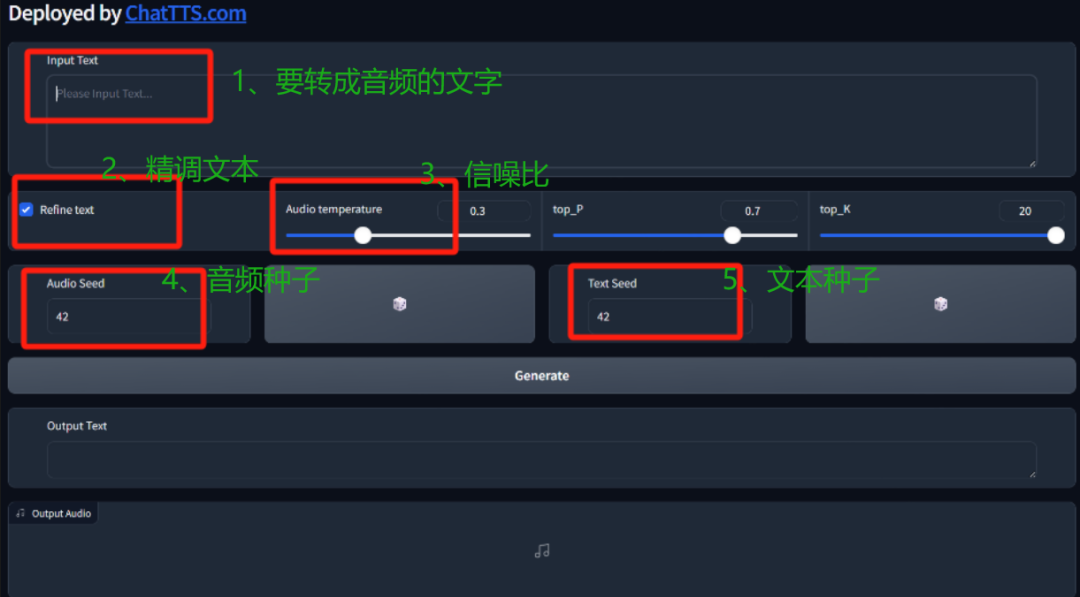
它网页版上的参数调节按钮,有一大半都是为了让生成的音频,更像咱们真人说话。
就比如,精调文本按钮打开之后,最后生成的音频里,会自动加一些口语化的连词,或者换气、笑声啥的,还有信噪比,就是为了还原说话时的背景音。
世超随便输了段话给 ChatTTS ,没动它的默认设置,生成的效果的是下面这个样子。
乍一听,还以为是办公室哪位同事遛火锅回来的吐槽。看下输出的文本,它是在最后一句的中间和结尾,自动加了两个气口。
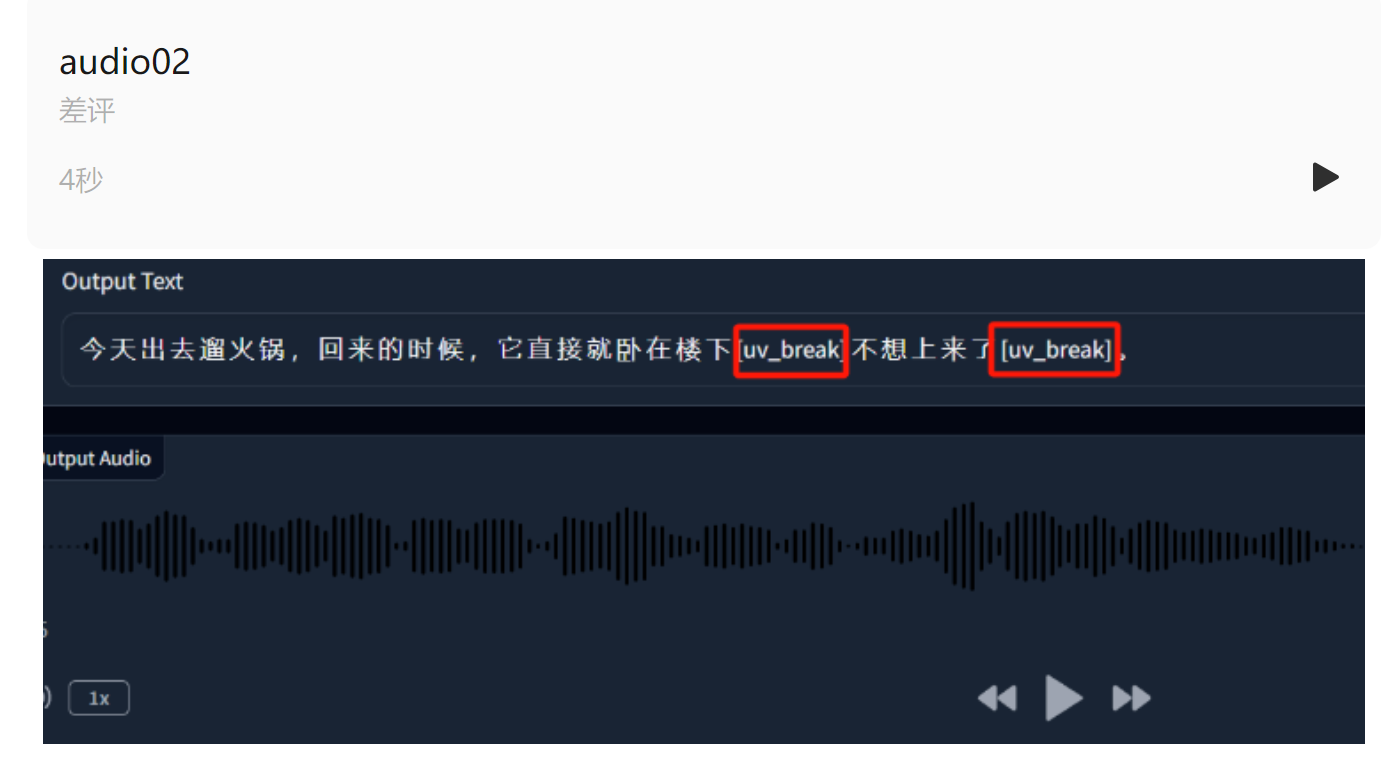
不过要多听几遍,还是能在里面找到些 AI 味儿。
如果嫌生成的效果一般,我们也可以自个儿去手动设置,在输入文本里加 [ uv _ break ] 或者 [ laugh ] ,就能直接控制气口和笑声。
还是上面那句话,世超直接在结尾加上个 [ laugh ] ,整句话都会更自然一点,结尾那个笑声,还能咂摸出一点无奈的味儿。
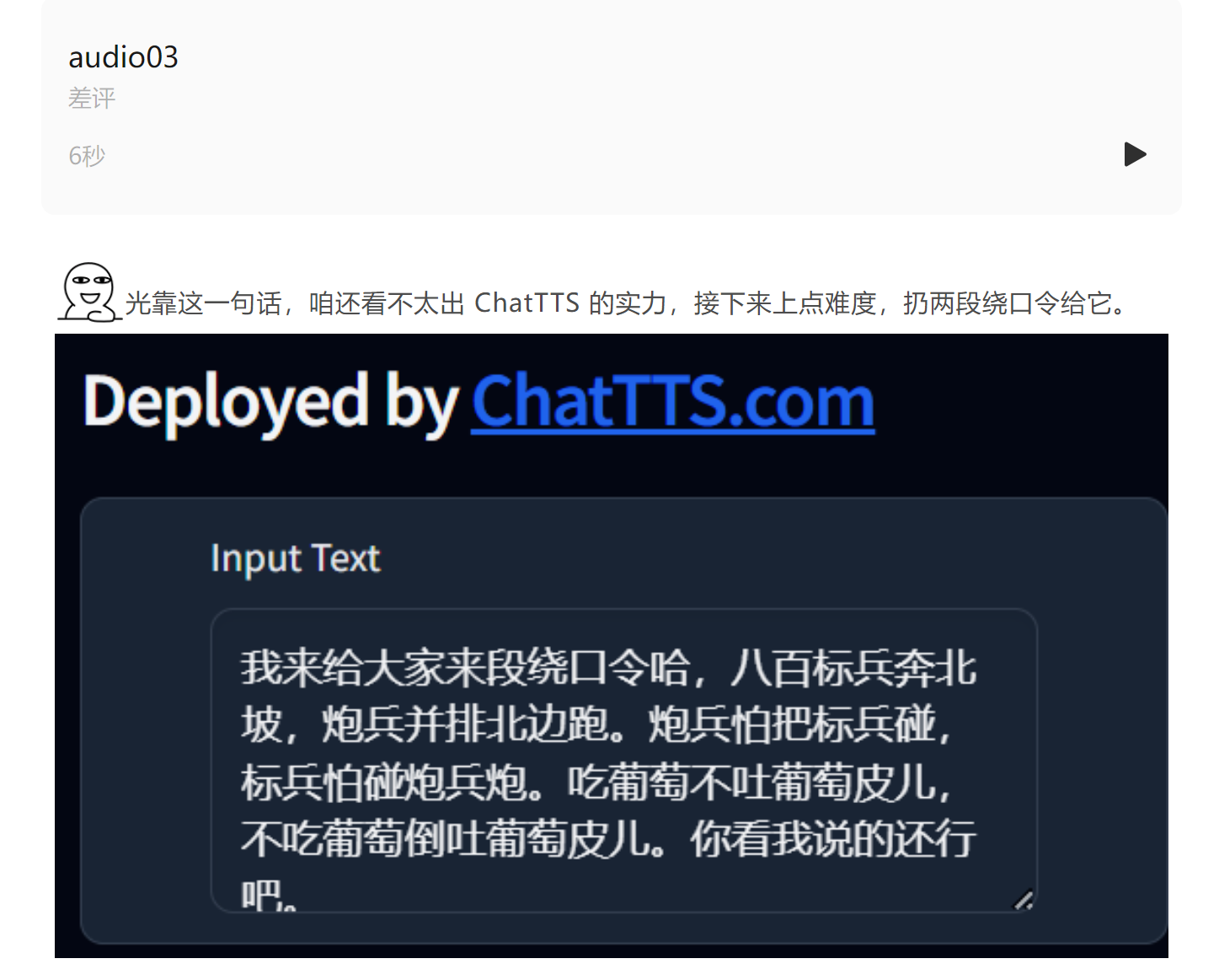
要是给咱们没练过的人来,指不定得口胡几次,没想到 ChatTTS ,模仿这个挺有一手。
讲到后面,它是直接一口气说完的,跟咱快忘词儿的语调相比,不能说十分像吧,起码也有个七八分了。
甚至为了让最后那句 “ 你看我说的还行吧 ” 更自然点,它还自己手动加了个词儿( 那个 )。

除了会说中文外, ChatTTS 也能整上两句英文。
世超输句肖申克的经典台词 “ Hope is a good thing and maybe the best of things.And no good thing ever dies.” 进去,它能顺溜生成语音。
至于效果嘛,世超觉得,没说中文自然。。。

当然,作为在咱们这儿土生土长的 AI ,说中文比说英文自然也情有可原。
不过让世超意外的是,虽然英语一般,但在学 ABC 中英夹杂, ChatTTS 是真有点天赋。
世超随便在台词里加了一些网上很火的英文梗,它直接把里面的精髓给模仿出来了。
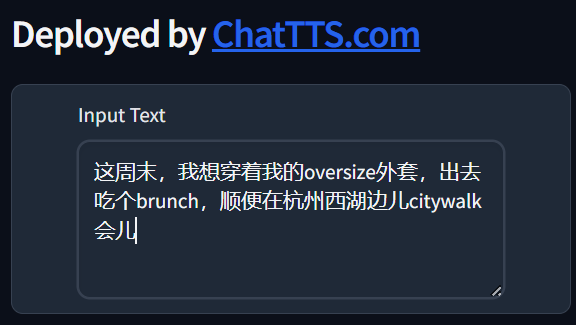
仅能准确切换中英文,口气啥的也都像模像样,而且该补充的连词也都补充了。硬要挑刺的话,就是最后那句有点卡壳,但平时咱说话,谁没有秃噜嘴的时候。

试到这儿,世超已经稍稍被 ChatTTS 给折服了。。。然鹅,就在咱准备再深度探索探索时,它一连给咱来了好几次大翻车。
就比如我想试试不精调文本,看看 ChatTTS 会生成怎样的音频,结果倒好,它直接罢工,输入的一大段话,它只读第一个字。
试了好几次都是这效果。。。
( 因为输出的问题,iOS系统可能会打不开这段音频。)

而且如果整段文字里有阿拉伯数字, ChatTTS 也识别不了,得我们手动切换成中文数字。
更离谱的是,只要字数一多起来,它就开始浑水摸鱼,支支吾吾只从大段文字里挑着念,甚至有时候都能把它们的 GPU 给干宕机了。
像是世超想让 ChatTTS 帮差友们读下这篇文章的开头,它就已经撑不住了。。。
这都还不算啥, ChatTTS 有个最大的缺点,就是咱们不能事先知道选择了啥音色,只能在 “ 音频种子 ” 里输入数字盲选,或者掷骰子抽卡。
合着就是碰运气呗。。。
不过关于这些 “ BUG ” ,研究团队也有它们的说辞。一句话概括就是,为了防止 ChatTTS 被有心之人利用,他们没放出最好的模型。
据他们的说法,目前开源的和网站上用的,都是用4 万个小时数据训练出来的模型,还没经过监督微调( SFT )。
并且为了防止 AI 诈骗,他们还在这些训练数据里,加了少量的高频噪声,数据用的也都是音频质量不太高的 MP3 格式。

团队手里呢,其实还有个更大杯、性能更好的模型,用10 万小时数据。
ChatTTS 真实的实力,应该是官方视频里展示的那样。像咱们上面展示的那几个例子,它都能做得更好,比如中英文夹杂的句子,视频的示例比咱试的要丝滑得多,而且整个人声的清晰度,也比世超在线生成的强。
按照设想,它之后还能接入语言大模型,能直接和 AI 来个面对面交谈。

甚至光是凭几分钟的音频,它能直接把乔布斯、泰勒 · 斯威夫特的声音给克隆出来。

之后再进化进化,结合 ChatGPT 和对口型的 AI ,让它帮忙直播带货估计都没人能看得出来了。
当然有好处是一方面,但世超想说的是,说到底这 AI 还是模仿人说话的,要是被有心之人给利用了,带来的后果可不是一点好处就能抵消的。
像去年,就发生了好几起关于 AI 诈骗的案例,被骗好几百万的都有。而现在 AI 音频越来越逼真,等于说诈骗的门槛是越来越低了。
还有版权风险,也算是这类音频 AI 的一堵墙。前段时间,寡姐还因为声音版权的问题,公开撕了 OpenAI ,以 OpenAI 下架相关音色告终。
甚至在今年早些时候,美国田纳西州还立了个法,不让用 AI 模仿人声。
总之,在音频 AI 这块儿,还有很多窟窿要被补上。。。
但说句心里话,世超还真挺希望这模仿人说话的 AI 能尽快落地的,要能接到公众号上就更好了。
毕竟这 “ 听一听 ” 功能里的机械音,听着是真叫人难受。。。
文章来源于“差评”,作者“世超”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
