# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
重磅消息!Stable Diffusion 3,大概率会在明天开源。距离2月SD3的横空出世,已经过去了4个月。如果此事为真,生图圈子第一个出现开源碾压闭源的奇景!强大的MMDiT全新架构,将彻底改变AI生图的格局。现在,全体AI社区都在翘首以盼。
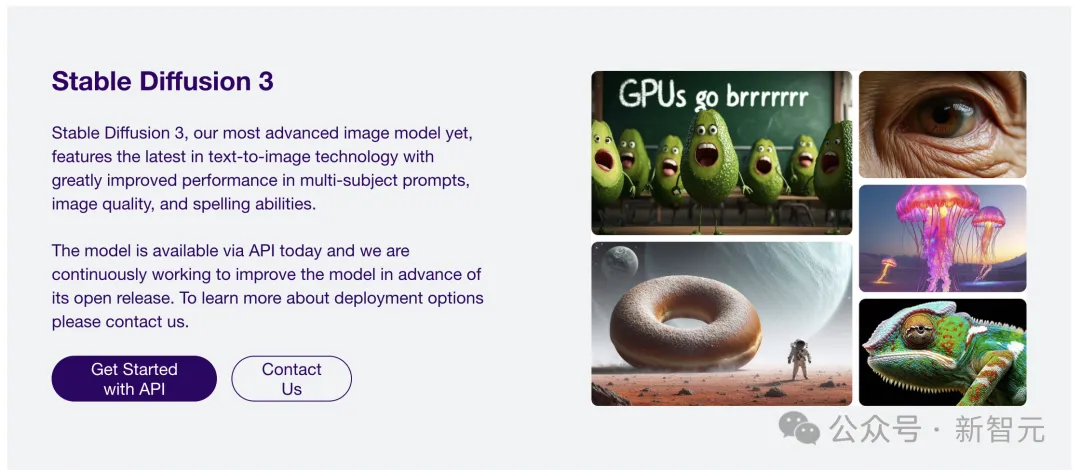
万众瞩目的Stable Diffusion 3,终于要正式开源了!
几天前,在Computex 2024大会上,Stability AI联合首席执行官Christian Laforte正式官宣:SD 3 Medium将在6月12日公开发布。
据悉,之后还会开源4B和8B的版本。

消息一出,网友们就激动地奔走相告。

种种迹象表明,SD3明天的开源应该是铁板钉钉了。
目前,ComfyUI已经提交了对SD3支持的版本。
网友表示,如果此事是真的,那可就太疯狂了,生图圈子将成第一个开源碾压闭源的赛道!
这边AI生图王者Midjourney刚刚放出功能更新,网友们就在评论区纷纷留言:SD3一旦开源,你们就完蛋了。

网友们纷纷搬好板凳,坐等SD3的权重发布了。


两个月前,Stable Diffusion 3一横空出世,立刻在人类偏好评估中斩下DALL-E 3和Midjourney v6,一举成为该领域的SOTA。

因为攻克了AI图像生成领域著名的「正确性」测试,SD3一时名声大噪,引发了极大热度。

虽然放出的模型效果惊艳全网,但选择开源也让公司的收入入不敷出。随后就是满身黑历史的CEO跑路、人才出走等负面事件,让Stability AI这头独角兽的前途风雨飘摇,一度陷入欠下1亿美元的「卖身」传闻。
在鼎盛时期的Stability AI收到过不少橄榄枝,却断然拒绝收购。然而亏损超3000万美元、拖欠1亿美元账单的事实,揭示了所有开源公司共同的困境——
如果选择将代码、权重和产品API免费开放,即便保留部分高级功能,也很难吸引到付费用户。

如果在这种情况下,SD3依然坚持开源,叫Stability AI一声「开源英雄」绝不为过。
强大的架构、更好的明暗对比度、提示遵循、训练结果、模型合并、图像分辨率……SD3的开源给我们带来的贡献可太多了!
现在,所有人都在翘首以盼。
Stable Diffusion3的开源,为何意义如此重大?
在reddit的StableDiffusion社区,一位网友给出了以下总结,让我们从非技术视角,理解SD3的重要性,以及对AI社区的重大影响。

作者表示,自己希望能让外行人都明白,为何Stable Diffusion 3如此重要。
曾经Stable Diffusion的开源,就改变了游戏规则
VAE(变分自编码器)非常特别,因为它让提供了16个通道的特征和颜色数据供我们使用,而之前的模型只有4个通道。
下面的四张图显示出,这将产生多大的影响。

Emu论文地址:https://arxiv.org/pdf/2309.15807
这也就意味着,模型在训练时会捕获更多细节。
不仅模型的质量会更好,而且实际上会带来更快的训练速度,从而使主要的MMDiT模型(也就是实现生成的主要模型)能够更好地捕捉细节。
感兴趣的读者可以阅读下面这篇技术性解读:

文章地址:https://huggingface.co/blog/TimothyAlexisVass/explaining-the-sdxl-latent-space#the-8-bit-pixel-space-has-3-channels
与旧的模型相比,新的16通道VAE在512x512分辨率下的表现,可以说令人难以置信——即使在较小的图像尺寸下,通道维度上的特征数量也足以捕捉到很好的细节。
为了更好地说明这一点,我们可以用视频领域的标准来做个类比——
VHS和DVD都是标准定义的480i/480p,但DVD显然捕捉到了更多细节,甚至在硬件和软件的升频器上表现也很好。

或者,可以用复古游戏玩家的说法来类比——
- 复合视频线(Composite cables) -> SD1.X的VAE
- S-Video线 -> SDXL的VAE
- 组件视频线(Component cables) -> SD3的VAE

因此,将VAE应用到如今我们的AI工作流程中,一切都将变得更加高效。
在视频生成方面,则可以在低分辨率下训练以适应虚拟内存(VRAM),然后通过分辨率增强流程来保留细节。
众所周知,训练文本编码器可以提升基于SD1.X模型和SDXL模型的性能。
然而在这位网友看来,从长远来看,这其实是低效的,因为在实际应用中存在大量的微调和模型合并。
这会在推理过程中导致大量的重新加权,从而引起混乱,使得在创作过程中捕捉细节变得更加困难。
虽然在小规模应用中可以这样做,但随着社区的扩大,训练文本编码器就变得极其繁琐了。
从技术角度来看,CLIP模型本身就很难训练和微调,因此如果尝试同时处理三个模型,可能会面临一场艰难的苦斗。
而现在,我们或许根本不需要微调文本编码器了!
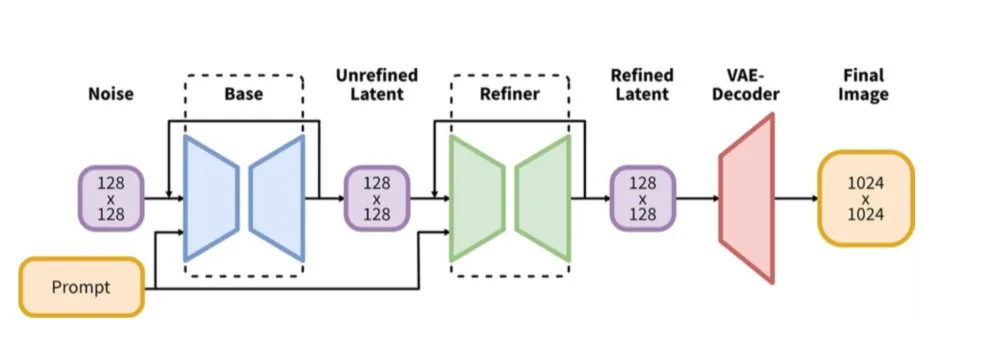
第一个原因是,VAE相比旧模型,捕捉了更多的细节。
第二个原因则是,无论我们使用哪种变体,SD3都经过了适当且鲁棒的caption训练,以捕捉大多数人认为重要的所有细节。
在SD3中,可以让新的架构和VAE为我们捕捉这些细节,这样我们就可以更好地利用多个LoRA模型,实现更鲁棒的生成。
目前,生成式AI社区和LLM社区之间还缺乏一定的协作。
在这位网友看来,随着MMDiT架构更好地与LLM社区对齐,会有更多的开发者进入生成式AI社区,带来大量丰富的研究和方法。
这将造成的影响,或许是十分重大的。

此前,LLM社区就创建了很多应用于生成式AI的伟大方法(比如LoRA就是从文本建模中派生出来的),然而,由于架构之间缺乏互操作性操作性(当前SD使用的是UNet,SD3使用的是Transformer块),会让许多人望而却步。
如果两个领域的开发者和研究者开始合作,扩展许多跨领域的多模态功能,比如文本、图像、音频、视频等,比如会创造出许多独属于开源社区的非常棒的体验。
自从Stable Diffusion诞生以来,我们可以在眨眼间生成图像、视频、音频,甚至3D模型。
如今在谷歌Scholar上,关于Stable Diffusion的论文已经有7500多篇了。
微调方法、ControlNet、适配器、分段方法等理论,在SD上应该会比从前的架构表现得更好。
而且因为架构简单,模型会变得更易访问和使用。
事实上,由于SD3的强大图像-文本对齐和VAE,有些方法可能我们再也不需要了。

比如在音频扩散、视频扩散和3D扩散模型领域,就可以在新架构上用这些方法训练,进一步提高模型的质量和鲁棒性。
显然,ControlNets和适配器会变得更好,因为SD3实际上是使用多模态架构构建的。
这也就意味着,SD3在不同模态之间,会有更好的关系理解。
如今我们在构建新方法时,就可以在同一空间内利用这些模态,再结合上更好的文本理解和强大的VAE,SD3的前途简直不可限量!

赶在2月份的时候,Stable Diffusion迭代到了第3个版本。
然而仅一个月的时间,背后核心团队却被曝出集体离职。
更让人意想不到的是,身为CEO的Emad也紧跟辞职,退出了董事会。

显然,SD3随后的开源,也变得迷雾重重。
当时,外界的猜测是,Stability AI的动荡是Emad一手酿成的。

彭博对20位现任前任员工、投资者等采访了解到,Emad在治理公司方面缺乏经验,组织结构混乱。
更有甚者,公司还习惯性地拖欠工资和税款。
Emad近日又成立了一家初创公司Schelling AI,专注去中心化AI系统
其实, 在23年底,公司内部不稳定的现象已经出现了苗头。
作为联创之一的Cyrus Hodes便起诉Emad是个「骗子」。
他指控,在公司进行重大融资几个月前,Emad曾诱骗自己以100美元价格出售15%股份。
其实,Stability AI创立之后,便以模型「开源」深受社区关注和好评。
它先后发布了多款模型「全家桶」,包括语言模型Stable LM、视频模型Stable Video Diffusiion、音频模型Stable Audio。
而比起具有里程碑意义的Stable Diffusion,一代和二代模型系列在开源社区有300-400万下载量。
在开源背后,需要的是Stability AI不断开启「烧钱」模式。
但显然,这种入不敷出的方式,根本无法支撑这家公司持续性发展。
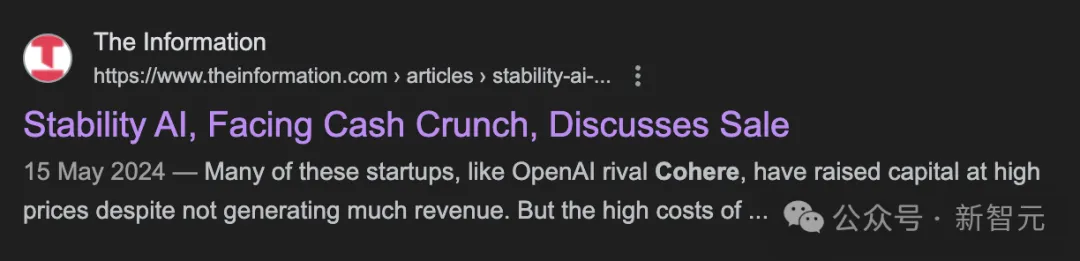
前段时间,Information爆料称,Stability AI第一季度的营收不足500万美元。而且,公司亏损超过了3000万美元,还对外拖欠了近1亿美元的巨额账单。
更有传闻称,Stability AI正寻求卖身。
而在SD3发布之后,官方宣布称在对齐之后正式开源,结果等了3个多月,依然只是API的开放。
有Reddit网友在线发起了提问,为Stability AI寻求赚钱出路,以保证SD3能够顺利放出。

好在,ComputeX大会上,终于等到了SD3的官宣开源。
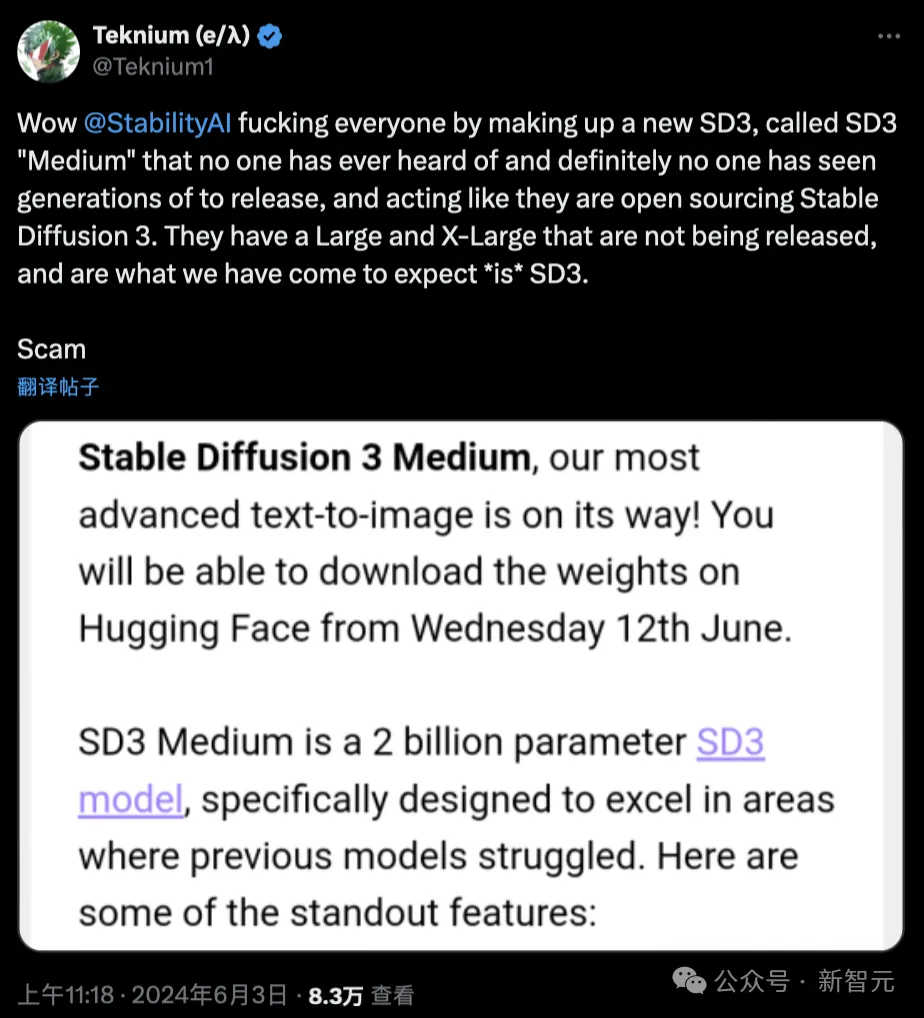
一些网友纷纷收到了Stability AI邮件,即将开源的SD3 Medium是一个20亿参数的模型。

不过,有人对此质疑道,「Stability AI愚弄了所有的人,他们开源的是一个名为『SD3 Medium』的模型,其实内部还有Large和X-Large版本还未发布,这才是人们期待的真正的SD3」。
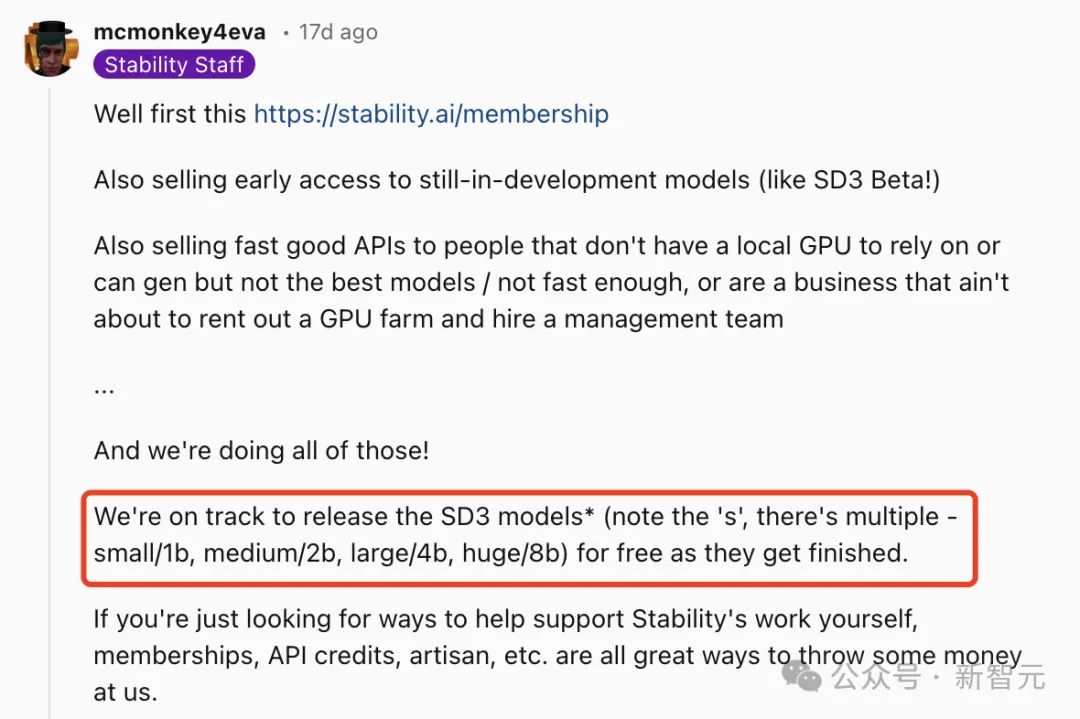
关于更大版本的开源,Stability AI自家员工表示,40亿、80亿参数的版本未来都将会陆续上线。
SD3的诞生已经在图像质量、多个对象、拼写能力方面,都得到了显著提升,让AI生图再创新里程碑。

发布当天,前CEO Emad承诺道,SD3未来将会开源,目前还在测试阶段。

甚至,它还涌现出了对物理世界的理解。
紧接着3月,Stability AI公布了新模型最详实的技术报告。
论文中,首次介绍了Stable Diffusion 3背后核心技术——改进版的Diffusion模型和一个基于DiT的文生图全新架构!

论文地址:https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf
与之前的版本对比,SD3明显在图像质量生成上,实现了很大的改进,不仅支持多主题提示。
最重要的是,文字拼写的效果也变好了。

这一切竟是因为,其背后框架的改进和创新。
它用上了与Sora同样的DiT架构,灵感来源于纽约大学助理教授谢赛宁的研究。
而在以前的Stable Diffusion版本中,并未采用Transformer技术。

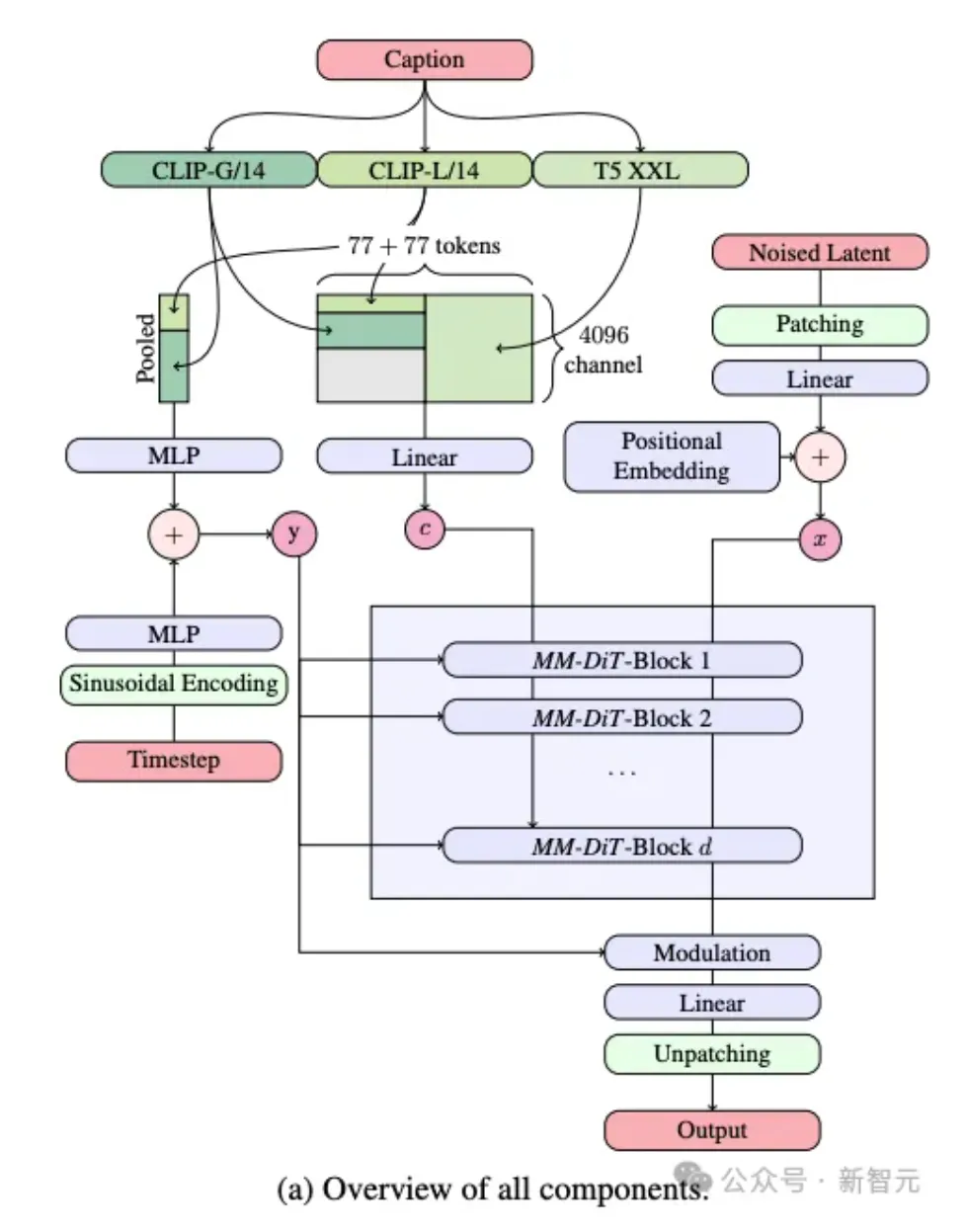
在文生图的任务中,SD3需要同时考虑文本+图像两种模态。
因此,研究者提出了一种全新的架构,称为——MMDiT(多模态Diffusion Transformer),专为处理这种多模态的能力。
具体而言,模型采用了三种不同的文本嵌入模型——两个CLIP模型和一个T5 ,来处理文本信息。
与此同时,还采用了一个自编码模型来编码图像token。
因为文本和图像嵌入在概念上有很大不同,下图右中可以看出,研究者对两种模态使用了两种不同的权重。
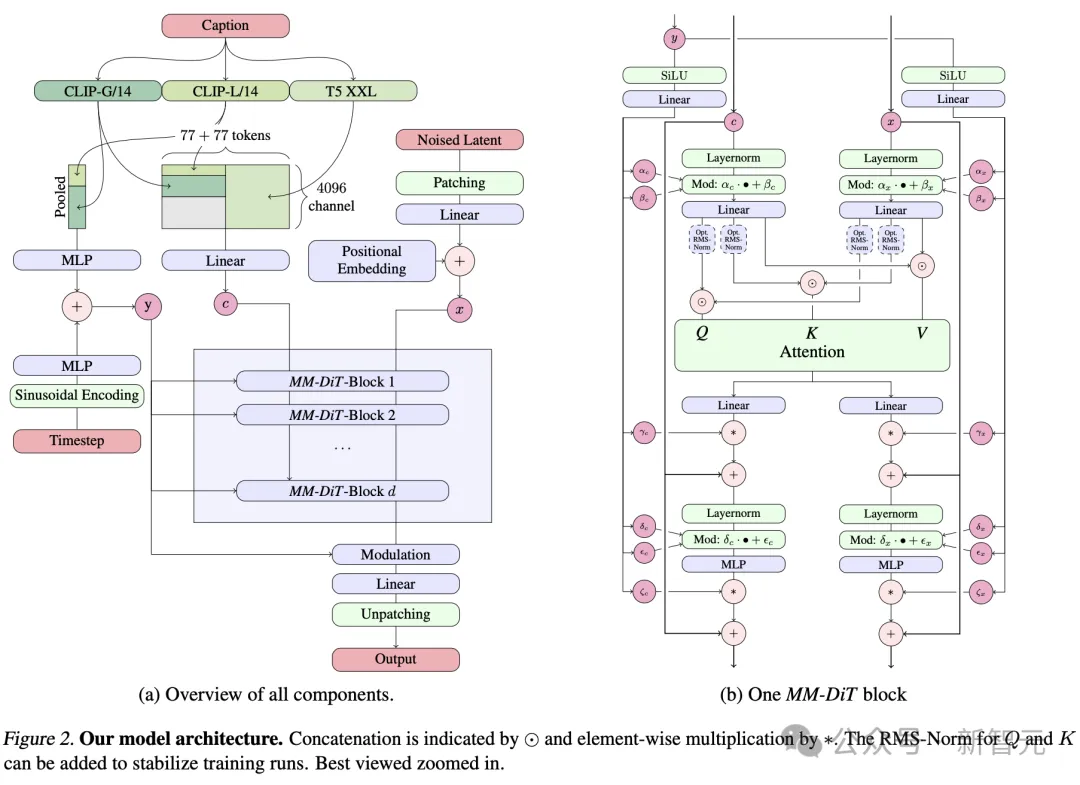
基于这种独特的架构,使得图像和文本信息之间可以相互流动和交互,从而在生成的结果中提高对内容的整体理解和视觉表现。
而且,这种架构未来还可以轻松扩展到其他包括视频在内的多种模态。
实验评估中,SD3在人类偏好评估中超越了DALL-E 3和Midjourney v6,成为该领域的SOTA模型。
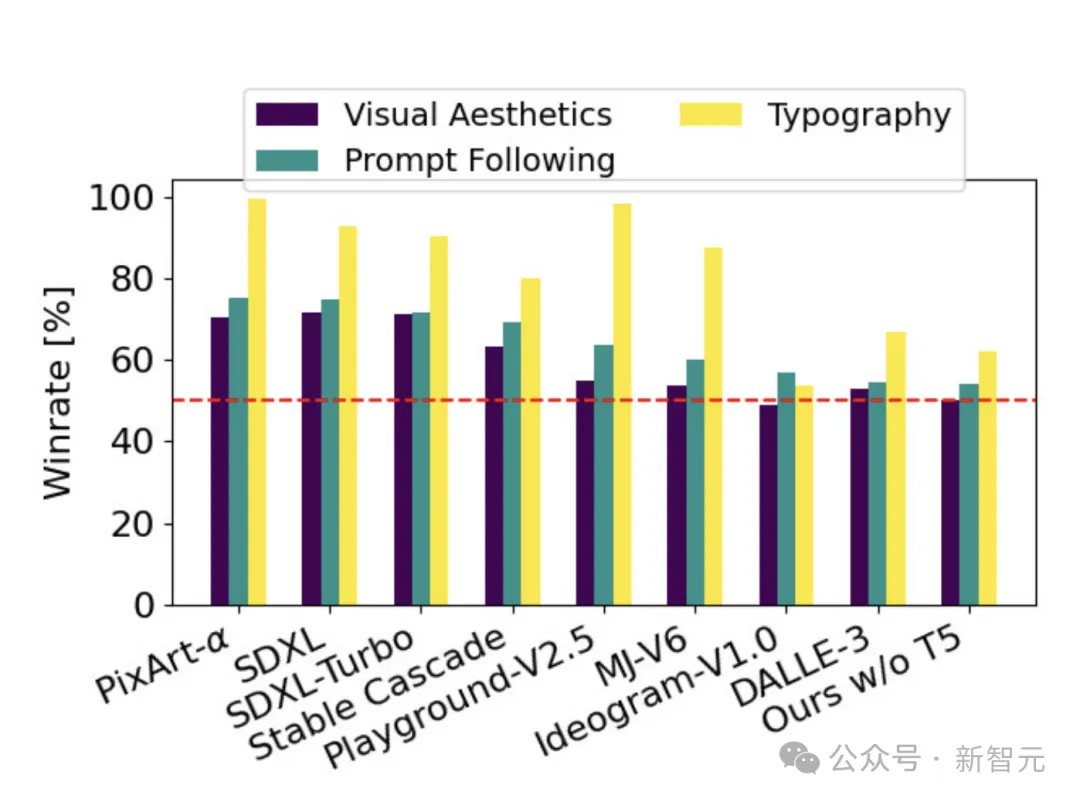
而且,SD3是一个模型系列,提供了8亿到80亿参数版本,意味着可以在终端设备可跑,大大降低了AI应用的门槛。
网友们对此激动不已,纷纷催更他们快速上线。
SD3开源倒计时开启,接下来坐等上手了。

参考资料:
https://x.com/op7418/status/1800455685068771643
https://x.com/StabilityAI/status/1797462536117444794
https://www.reddit.com/r/StableDiffusion/comments/1d6t0gc/sd3_release_on_june_12/
https://www.reddit.com/r/StableDiffusion/comments/1dcuval/comment/l80v9an/?utm_source=share&utm_medium=web3x&utm_name=web3xcss&utm_term=1&utm_content=share_button
文章来自于微信公众号 “新智元”,作者 “新智元”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
