# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如何生成高难度、指令超复杂的视频呢?
北大与快手AI有解了,他们提出新框架VideoTetris,就像拼俄罗斯方块一样,轻松组合各种细节~
在复杂视频生成任务中,超过了Pika,Gen-2等一众商用模型。

这个框架不仅能够直接增强现有模型的组合生成,还能够支持涵盖多复杂指令、多场景变更等更高难度的长视频生成。
在文生图领域,RPG、Omost等项目已经实现了复杂的组合式多物体多场景图片生成。而在文生视频领域,组合生成自然地扩展到时间和空间维度,这样的场景还未被广泛探索。
团队首次定义了组合视频生成任务,包括两个子任务:
1、跟随复杂组合指令的视频生成。2、跟随递进的组合式多物体指令的长视频生成。
目前经团队测试发现,几乎所有开源模型,包括商用模型在内都未能生成正确的视频。
比如输入“左边一个可爱的棕色狗狗,右边一只打盹的猫在阳光下小憩”,结果生成的都是融合了两个物体信息的奇怪视频。

而使用VideoTetris,生成出的视频是这样,成功保留了所有的位置信息和细节特征。

在长视频生成中,目前的方法支持的可变指令目前还停留在“春夏秋冬”的转化,或单物体从走到跑到骑马的场景变化阶段。
团队输入一个简单的多指令:“从一只可爱的棕色松鼠在一堆榛子上过渡到一只可爱的棕色松鼠和一只可爱的白色松鼠在一堆榛子上”。
结果VideoTetris成功搞定,出现顺序也与Prompt一致,最后两只松鼠还在自然地交换食物。

这样的效果是如何做到的呢?该团队的 VideoTetris 框架使用了时空组合扩散方法
他们将一个提示词首先按照时间解构,为不同的视频帧指定好不同的提示信息。
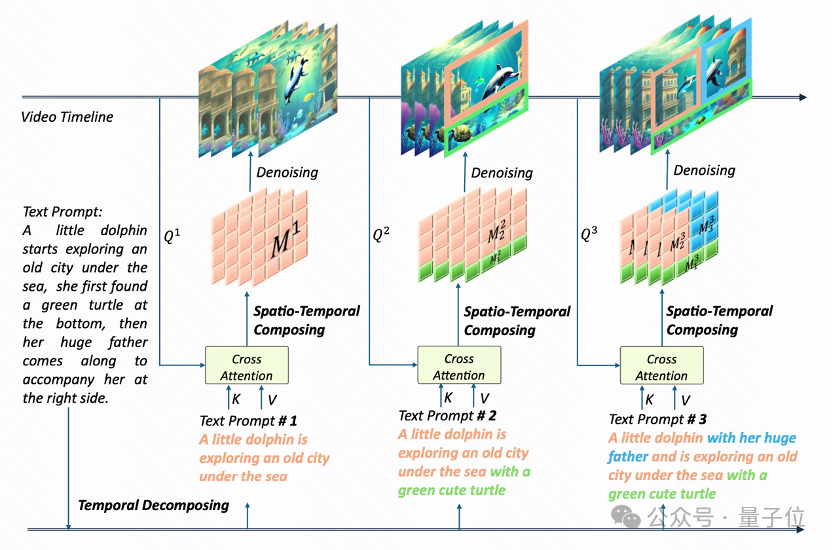
随后,在每一帧上进行空间维度的解构,将不同物体对应不同的视频区域。
最后,通过时空交叉注意力进行组合,通过这个过程实现高效的组合指令生成。
而为了生成更高质量的长视频,该团队还提出了一种增强的训练数据预处理方法。使得长视频生成更加动态稳定。
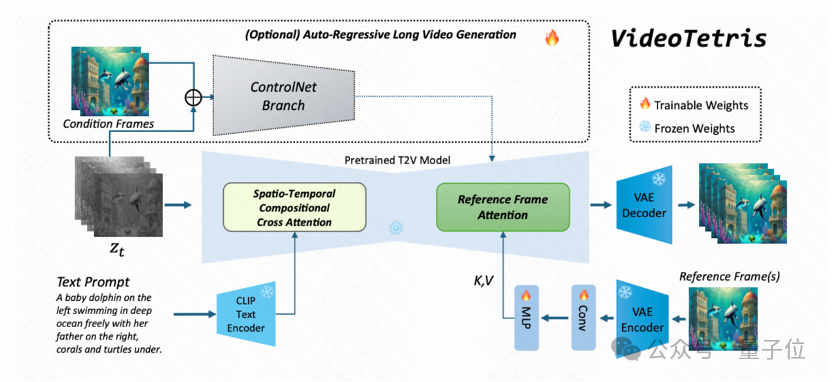
此外,还引入了一个参考帧注意力机制,使用原生VAE对之前的帧信息编码,区别于StreamingT2V,Vlogger,IPAdapter等使用CLIP 编码的方式,这样使得参考信息的表示空间和噪声完全一致,轻松获取更好的内容一致性。
这样优化的结果是,长视频从此不再有大面积偏色的现象,能够更好地适应复杂指令,并且生成的视频更具有动感,更符合自然。
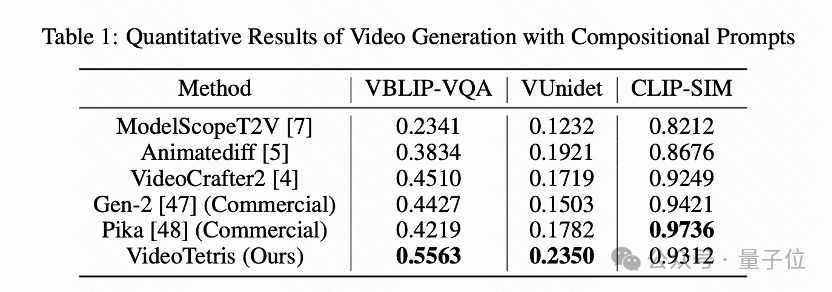
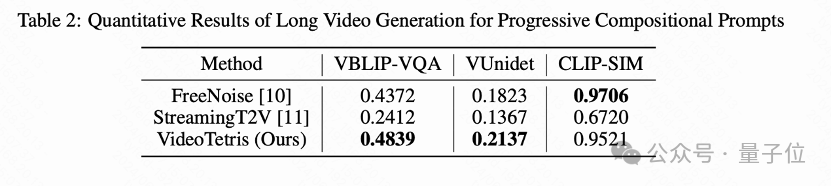
对于这种组合生成的结果评测工作,该团队引入了新的评测指标VBLIP-VQA和VUnidet,将组合生成评价方法首次扩展到视频维度。
实验测试表明,在组合视频生成能力上,该模型的表现超过了所有开源模型,甚至是商用模型如Gen-2和Pika。
据介绍,该代码将完全开源。
文章来源于“凹非寺”,作者“杨灵”




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
