# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Meta AI刚刚在社交媒体X上宣传自家的大模型NLLB,全称为No Language Left Behind,这个AI模型能够翻译200种语言,包括资源匮乏的语言。

更重要的是,NLLB模型可以免费提供给非商业用途。
这项研究刊登在了本周的Nature上,题为「Scalling neural machine translations to 200 languages」。

论文地址:https://www.nature.com/articles/s41586-024-07335-x
No Language Left Behind,意为「不让任何一门语言掉队」,是非常有人文关怀的技术描述。
Nature的社论也着重强调了这一点,发表了评论文章,称赞Meta的这次发布。

缩小语言之间的数字鸿沟
在全世界使用的近7000种语言中,大约有一半被认为面临灭绝的危险,一项研究预测,语言消亡的速度可能会在40年内增加两倍。
少数语言在互联网上占据主导地位,据统计,一半以上的网站都是英文的,前十种语言占据了80%以上的互联网内容。
NLLB模型最大的价值在于,它提供了一种扩大「资源匮乏」型语言机器翻译规模的方法,这些资源匮乏的语言几乎没有可获取的数字资源。
通过艰辛的努力,Meta技术人员开垦了大片「无人区」——在它现在可以互翻的200多种语言中,许多语言是第一次被机器翻译。
包括南非的茨瓦纳语、达里语,阿富汗所使用的一种波斯语,波利尼亚的萨摩亚语等等。

这是非常有建设性的事业,因为这有助于缩小这些被忽视的语言与在线的更流行的语言(例如英语、法语和俄语)之间的数字鸿沟。
它可以让资源匮乏语言的使用者能够用他们的母语在线获取知识,并可能通过引导这些语言进入数字时代来避免它们的灭绝。
人类专家助力NLLB
NLLB模型的研发团队来自Meta AI、加州大学伯克利分校和约翰霍普金斯大学。
这些出色的科学家们共同开展了这个「不让任何一门语言掉队」计划,他们选取了维基百科文章中出现的语言,但在线可用的示例翻译句子不足100万个。
这项工作将之前迭代的语言数量增加了一倍,并提高了翻译质量。
NLLB团队聘用了专业译员和审校人员,创建了39种语言的「种子」数据集,并开发了一种技术,使他们能够挖掘网络数据,创建其余语言的并行数据集。
他们还为每种语言生成了一个包含约200个「有毒」词汇的列表,以识别可能构成仇恨言论的翻译。
人类专家的参与既耗时又昂贵,但却至关重要。如果没有他们,算法将只能使用AI生成的低质量数据进行训练,然后在迭代过程中重复这些低质量和错误内容,进一步降低模型表现。
没有参与Meta AI计划的英国爱丁堡大学民族学/语言学教授William Lamb表示,这种情况已经发生在苏格兰盖尔语中,这个语言的大多数在线内容都是由人工智能生成的。

William Lamb
苏格兰盖尔语是Meta计划中资源较少的语言之一,好在其内容都是经过专业翻译的。
对于缺乏某些词汇的语言来说,人类的专业知识也很重要。
例如,许多非洲语言没有专门的科学概念术语。Decolonise Science研究项目聘用专业翻译人员将180篇科学论文翻译成6种非洲语言。
该项目由Masakhane发起,这是一个由对自然语言处理感兴趣的研究人员组成的基层组织。
模型架构与性能
NLLB是一种利用跨语言迁移学习的单一大规模多语言模型,NLLB开发了一个基于稀疏门控混合专家(Sparsely Gated Mixture of Experts)架构的条件计算模型,使用针对资源匮乏语言定制的新挖掘技术获得的数据进行训练。

此外,团队还设计了多项架构和训练改进,以在对数千项任务进行训练时抵消过度拟合。
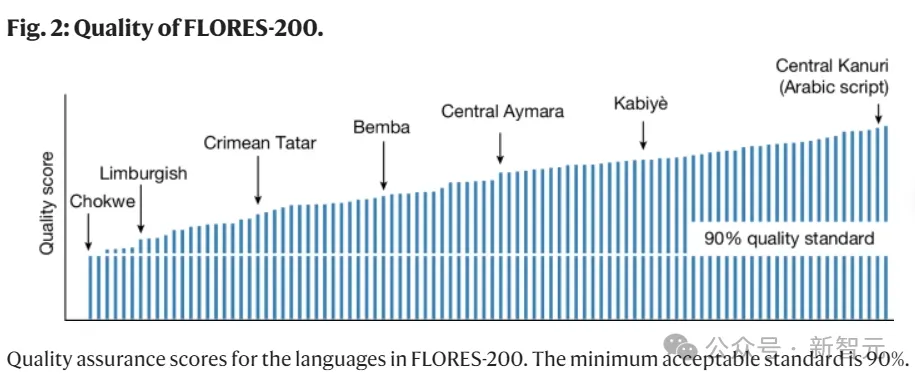
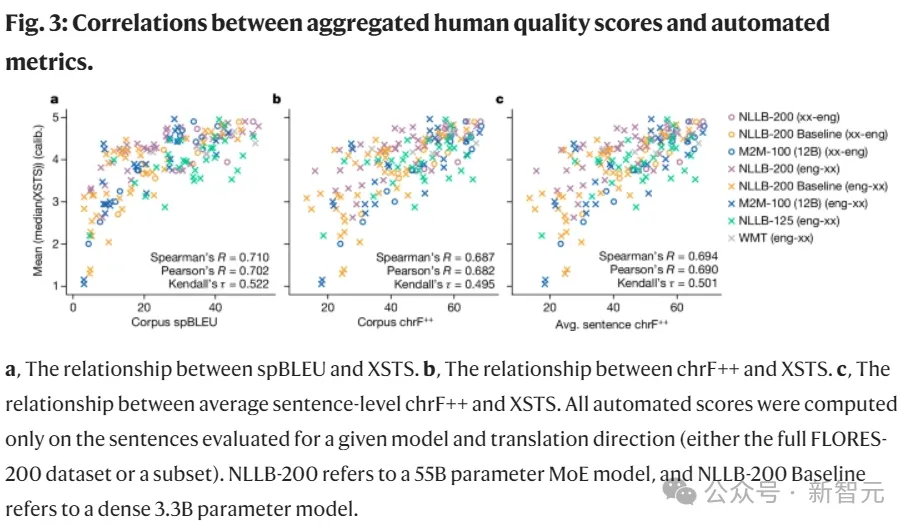
为了检测模型的性能,团队使用了专门创建的工具——自动基准(FLORES-200)、人工评估指标(XSTS)和涵盖模型中全部语言的「毒性」检测器,评估了超过4万个翻译方向。
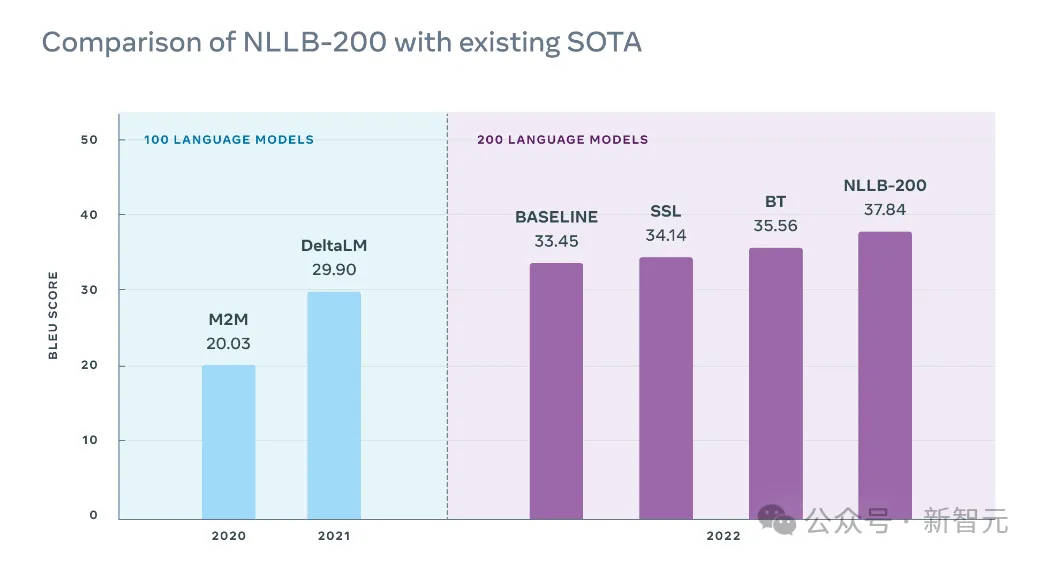
与之前的SOTA相比,根据BLEU(Bilingual Evaluation Understudy,一种基于分数的双语评估方法)评分,NLLB模型翻译质量平均提高了44%。
NLLB成功地将神经机器翻译(NMT)扩展到了200种语言,并将这项工作中的所有发现免费提供给非商业用途,为通用翻译系统的开发奠定了重要的基础。
NLLB-200首次面世是在2022,自被推出以来,我们已经可以看到该模型在多个方向上的影响。
维基媒体报道称,NLLB是维基百科编辑使用的第三大机器翻译引擎(占所有已发布翻译的3.8%)。与其他机器翻译服务相比,使用NLLB-200翻译的文章删除率最低(0.13%),翻译修改率最高不到10%。
模型发布之后——必不可少的社区互动
自动化翻译方法确实可以为资源匮乏的语言带来活力,但前提是大模型的研发公司能够与使用这些语言的人持续进行互动。
机器学习模型的好坏取决于它们所输入的数据——这些数据主要由人类创建,而光靠专家的翻译,是远远供不应求的。
这也是研究人员和技术公司必须将使用这些语言的社区纳入进来的原因之一。不仅是在创建机器翻译系统的过程中,也包括用户使用这些系统的过程,以反映真实情境下的人们如何使用这些语言。
Nature的研究人员表示,随着机器翻译工具的发展,其背后的公司必须继续与技术所服务的社区互动,否则就有可能浪费该技术的承诺。
他们担心如果大公司不这样做,会加速这些语言及其相关文化的消亡。
如果没有真实语言社区的参与,机器翻译工作可能会成为另一种形式的「降落伞科学」(parachute science),即高收入国家的研究人员对低收入国家的社区的利用。
加拿大温哥华岛北岛学院的语言复兴专家、Kwakwaka'wakw族人Sara Child表示——

「这些词语、句子和交流都没有了语言中编码的价值观和信仰。随着人工智能将更多语言推向数字空间,我担心我们会失去更多自我」。
在急于建立通用翻译系统的过程中,我们绝不能忽视人的因素。
文章来源于“新智元”,作者“新智元”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
