# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现在,AI 大模型可以真正与物理世界结合了。
该大模型体系分为 10 亿级参数的 Pangu E 端侧模型,百亿级参数的 Pangu P,千亿级的 Pangu U,以及万亿级的 Pangu S 版本,在全系列、多模态、强思维三个方面实现了升级。
盘古 5.0 可以与物理世界结合,理解包括文本、图片、视频、雷达、红外、遥感等多种模态的信息。它已在高铁故障检测等工业领域、具身智能等技术探索领域落地,因而受到了人们的关注。

随着鸿蒙 HarmonyOS NEXT Beta 版本的发布,小艺也升级成为智能体,面向全场景设备提供语音对话、图文识别、服务建议、设备智慧能力和设备互联管理功能。依托昇腾的算力和盘古大模型,HarmonyOS NEXT 拥有了系统级 AI 能力。
在大会主 Keynote 环节上,诺亚方舟实验室主任姚骏对盘古大模型 5.0 背后的技术进行了详解。

在过去的一年里,华为对盘古 3.0 进行了全面的升级,如今的盘古 5.0 具备了更丰富的多模态和更强的思维能力。基于华为云 AI 算力平台,盘古 5.0 提高了训练效率。在新模型的介绍中,华为主要从数据、参数和算力三个方面介绍了大模型的训练过程。
数据合成
首先是数据方面的工作,在 5.0 版模型的训练中,工程团队从追求数据量和提高数据清洗质量的数据工程,向科学使用数据的思路进行了演进。新的目的是提升数据的利用率,并且用更优质的数据来激活模型中更多的能力。
华为着重介绍了两个关键技术。
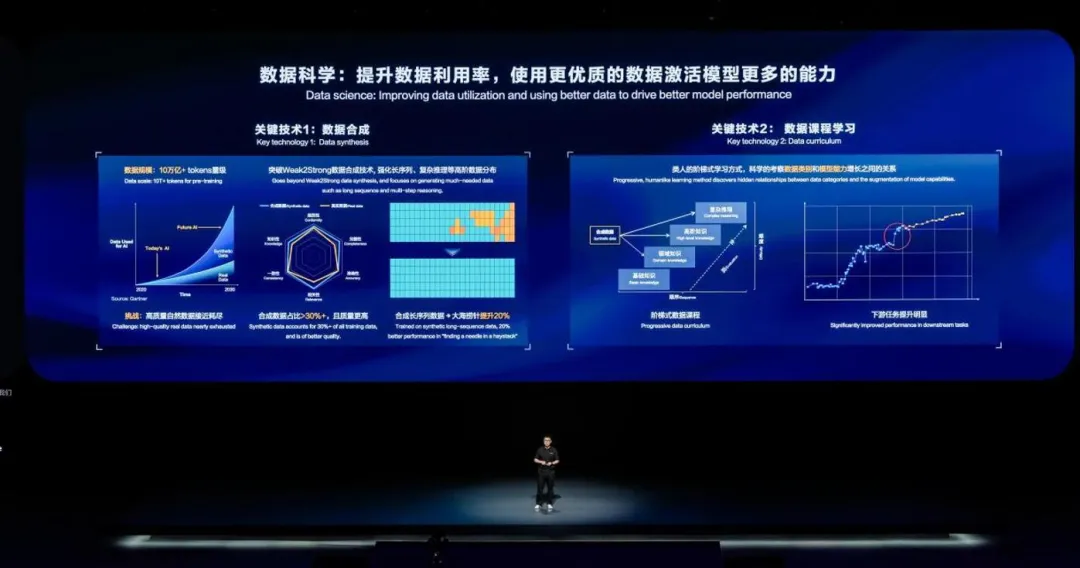
首先是数据合成,现在,业界大模型训练数据的规模已经从万亿级 tokens 迈入十万亿 tokens,到达这个量级以后,业界公开的高质量数据的增长就难以跟上模型体量增长的速度了。
华为认为在未来,合成数据会在更大规模的模型训练中占有一席之地,从而弥补高质量自然数据增长不足的空缺。从盘古 3.0 时代的 3T Tokens 的数据,到盘古 5.0 时,数据的容量已达到 10T Tokens,其中合成数据占比超过了 30%。在其中,华为探索了优质的、面向高阶能力的数据合成方法。简单来说,就是以弱模型辅助强模型的 weak2strong 方法,迭代式的合成高质量的数据,保证合成数据有不弱于真实数据的完整性、相关性和知识性。
在华为提供的能力图中可以看到,合成数据的质量从各个维度都略强于真实数据。
华为提出的 weak2strong 可以进一步加强合成数据中特定的数据,例如自然数据中偏少的长序列、复杂知识推理等的数据,进一步通过这些数据来加强模型的特定能力。在训练的过程中,华为使用了大量合成的长序列数据,提高了模型在大海捞针长序列测试中的表现约 20%。
华为也展示了数据方面的课程学习,利用相对较小的模型对不同数据进行快速的 AI 评估,区分不同数据类别在学习过程中的难易程度。进一步根据阶梯式课程学习的原理,先让大模型学习相对来说基础的课程,再逐渐的加大高难数据的比例,模型能以更加类人的方式从易到难地学习知识,实现更加可控、可预期的能力涌现。
模型架构升级
在盘古 5.0 中,模型架构也获得了升级,华为提出了昇腾亲和的 Transformer 架构 - 创新的 π 新架构。
如下图左所示,原始的 Transformer 架构和其它的深度模型一样,也存在一定的特征坍塌问题。华为研究人员通过理论分析发现,Transformer 中的自注意力模块(即 Attention 模块)会进一步激化数据的特征消失。
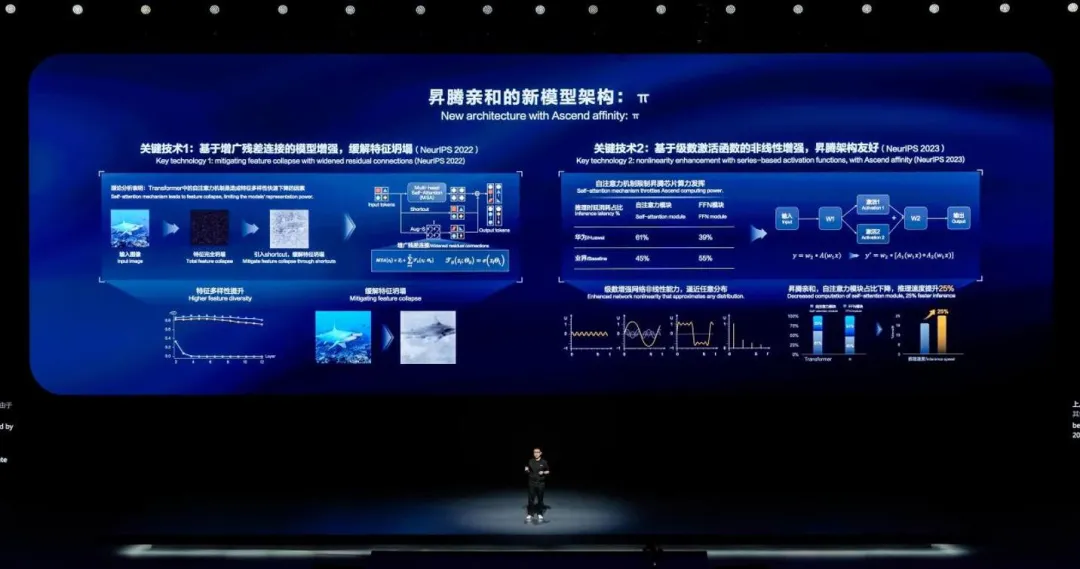
利用计算视觉和 Transformer 结合的例子来演示这个特征问题,左边是一张鲨鱼的图,如果我们用原始的 transformer 架构来处理,模型一深就会带来特征的完全坍塌,基本无法还原输入图像,看起来就是中间黑乎乎的一块。业界因此为原始的 Transformer 增加一条残差连接,这样就能略微的缓解特征坍塌问题,右边的图中可以模糊地看到还原图像中有一点鲨鱼的影子,但是这个鲨鱼的特征整体仍然不太明显。
在新的盘古 π 架构中,华为诺亚、北京大学等研究人员进一步提出了增广残差连接的方法。通过引入非线性的额外残差,更进一步的加大来自不同 Token 的特征,使数据的特征的多样性得以在深度的 Transformer 中得到维持,进而大幅提升模型的精度。

论文链接:http://dx.doi.org/10.13140/RG.2.2.34314.64966
PanGu-π 的工作,已经被国际机器学习顶会 NeurIPS 2023 录用。
在上图下方的图实验结果中,还原的鲨鱼图像效果更好了,可知模型对数据的表征和学习能力得到了大幅的加强。
另一方面,Transformer 包含 2 个关键模块,FFN 和自注意力模块。华为表示,其自研的昇腾芯片擅长于处理 Transformer 中的 FFN 模块,而对自注意力模块(Attention 模块)的效率不高。因此在 π 架构中,华为改造了模型中 FFN 模块中的激活函数,用一种新的级数激活函数的方式来代替。这种新的方式增加了模型的非线性度,增加了 FFN 的计算量,但是也可以帮助我们在精度不变的情况下减少自注意力模块的大小。经过此种优化,大模型在昇腾芯片上推理速度也由此提升了 25%。
大集群训练
华为进一步介绍了通过大集群训练盘古 5.0 的情况。
从千卡集群到大集群,主要挑战来自两方面:首先,训练千亿、万亿模型需要同时进行数据并行、模型并行和流水线并行,期间计算单元在流水线并行的等待时间称为 Bubble。千卡集群的 bubble 通常在 10% 左右,而大集群的 Bubble 就到了 30,大大影响了集群算力利用率。另外,大集群中,并行通信在集群间会有大量的路由冲突要解决,导致集群利用率线性度只有 80% 左右。

为了解决这个问题,技术人员首先将大块计算和通信按照数学上的等价,切分成多个小块计算和通信副本。系统会编排多个副本间计算通信的执行顺序,小块的计算和通信更容易被隐藏在计算中。在这其中,编排上还有 NP 难问题的自动寻优优化、正反向流水交织等关键技术。此外,华为还优化了大集群调度与通信,通过 rank table 编排算法,将大流量放到节点内或同一机柜级路由器下,避免跨路由器冲突,同时对源端口进行动态编排,实现集群通信路径完全零冲突。
基于以上方法,华为可以有效隐藏 70% 以上的通信,bubble 从 30% 降低到 10%,有效实现了大集群的近线性加速比。整体上,集群的训练 MFU(模型计算算力利用率)相比 256 卡的 60%,大上只降低了 10%,可以达到 50% 左右,这些优化大幅提升了训练效率。
姚骏表示,这些自动并行方案已集成到了华为 AI 框架中,成为了训练全栈解决方案的一部分。
盘古大模型 5.0 的能力提升
盘古 5.0 扩展了多模态能力。
一直以来,多个模态的高效对齐是训练多模态大模型的一大挑战。其中,视觉编码器是多模态大模型处理输入的第一步,用于将不同类别、大小的图像输入到同一个表征空间,相当于语言模型的 Tokenizer 。因为领域的不同,传统处理图像,视频,文本和图表时,需要用各自的独立的编码器各自接入多模态大模型,这造成了模型容量浪费和计算冗余。
华为提出统一视觉编码,将不同的编码器能力蒸馏到一个统一视觉编码器中,可以大大提升编码效率。和同参数量业界 SOTA 模型相比,由于利用了不同领域之间内的共通知识,新的编码器在自然图像能力基本持平,文档理解能力上有显著提升。这种方案现在也成为了业界的主流编码范式。
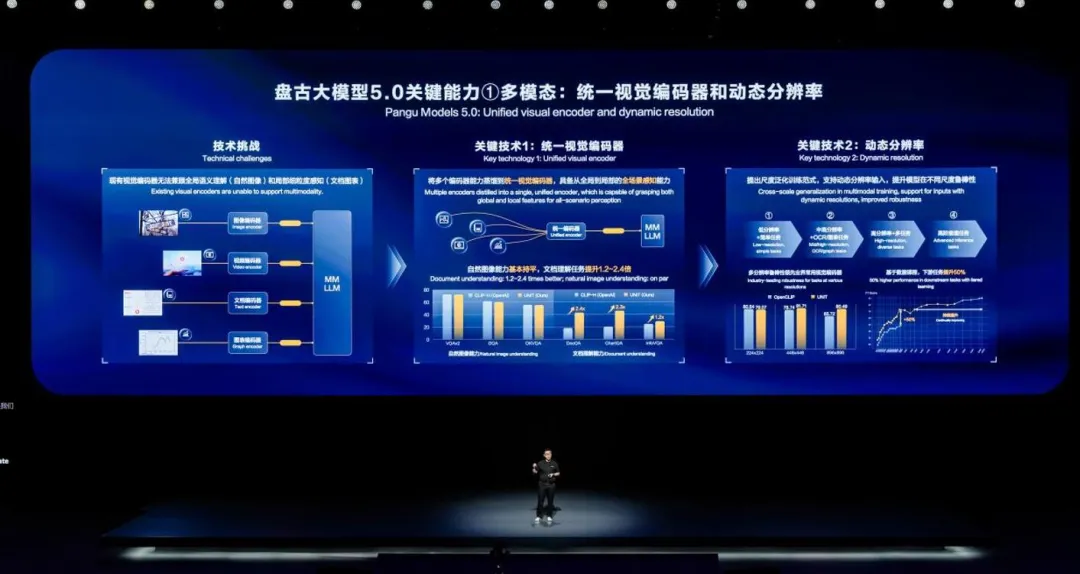
盘古 5.0 在介绍多模态能力时重点展示了两个关键技术。第一个是统一的视觉编码器,它改变了以前业界在视觉的多个领域,如 OCR、自然图像、视频、文本等,都有不同的独立编码方案的困境。把这些编码器都蒸馏到一个视觉编码器,现在已经成为了业界主流的编解码方案,也提升了模型的表征能力和精度。
另一个关键技术是动态分辨率。人看世界是有不同分辨率的,但是一个 AI 模型的输入一般是固定的,很难兼顾。华为提出尺度泛化的训练范式,如下图右边部分所示。首先,使用低分辨率图片和简单任务训练基础感知能力,然后使用中高分辨率训练 OCR 和图表理解等细粒度感知能力,第三阶段扩展到更高的分辨率和更多的任务类型,最后重点突破模型的高阶推理能力。
这也是一种数据课程学习的方式,从易到难学习多模态的信息。这种方式动态的递增的方式帮助盘古 5.0 在动态分辨率的表征上超过了业界同等模型的能力,并有效的提升了新模型在下游多模态任务的能力,实现了 50% 的提升。

盘古大模型的另一个关键能力提升在于强思维,即复杂推理能力。
当前,在单步任务和文本记忆类任务,例如知识问答和考试上,大模型已经展现出超过人类的卓越表现。而在多步推理和复杂任务的处理上,AI 还没有达到人类的平均水平,这一方面涉及到的任务包括代码生成、数学运算、逻辑推理等。这体现了人类在知识的抽象和推理上的能力难以替代。
在华为的研究过程中,前一种能力被称作记忆型能力,适合于大模型用一步的快速思考进行回答。后一种复杂推理,人类处理时一般也需要步步推导,跳过中间过程的快速回答不适用于这种问题,所以大模型也需要像人一样,在这类问题上把快思考变成慢思考,一步一步分解和完成对复杂问题的处理。
从这点出发,华为提出了基于多步生成和策略搜索的 MindStar 方法。首先把复杂推理任务分解成多个子问题,每个子问题都会生成多个候选方案,通过搜索和过程反馈的奖励模型,来选择最优多步回答的路径。这样既兼顾了人类一步一步思考的形式,也兼顾了机器更擅长的策略搜索的形式。
在华为自建的难例评测集中,MindStar 方法使模型的平均能力提升了 30 分,使用了 MindStar 的百亿模型达到业界主流千亿模型的推理能力,这相当于使用慢思考能带来 10 倍以上的参数量的加成。
把 MindStar 这类强思维方法运用到更大尺度的模型上,AI 或许就能逐步在复杂推理上实现接近人类,甚至超越人的能力。
文章来源于“机器之心”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
