# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近 Open-Sora 全新开源的 1.2 版本,可以生成最长 16s 的 720p 高清视频,官方视频效果如下:
这个生成的效果确实惊艳,也难怪后台那么多读者想要上手体验。
对比一众闭源软件,需要排长队等候内测资格,这个完全开源的 Open-Sora 显然更加易得。但是,在 Open-Sora 的官方 Github 上,密密麻麻全是技术和代码,要想自己部署体验,且不说模型对硬件要求高,配置环境时对使用者的代码功底也是不小的挑战。
那么有没有什么办法,让 AI 小白用户也能轻松使用 Open-Sora 呢?
先上结论:有,而且可以一键部署,启动后还能零代码控制视频长度、画幅、镜头等参数。
心动了吗?那就让我们一起看看,要如何实现 Open-Sora 的部署。文末有保姆级的详细教程和使用地址,无需任何技术背景就能操作。
基于 Gradio 的可视化方案
有关 Open-Sora 的最新技术细节,我们曾经做过一篇深度报道。在报道中,我们重点讨论了 OpenSora 模型的核心架构和其创新的视频压缩网络(VAE)。在那篇文章末尾,我们提到,潞晨 Open-Sora 团队提供了可以自行一键部署的 Gradio 应用。那么,这个 Gradio 应用具体是什么样呢?
Gradio 本身是一个 Python 包,专为机器学习模型的快速部署而设计。它允许开发者通过定义模型的输入和输出,自动生成一个网页界面,从而简化了模型的在线展示和交互过程。
我们仔细阅读了 Open-Sora 的 GitHub 首页,发现该应用将 Open-Sora 模型与 Gradio 有机地结合起来,提供了一个优雅简洁的交互方案。
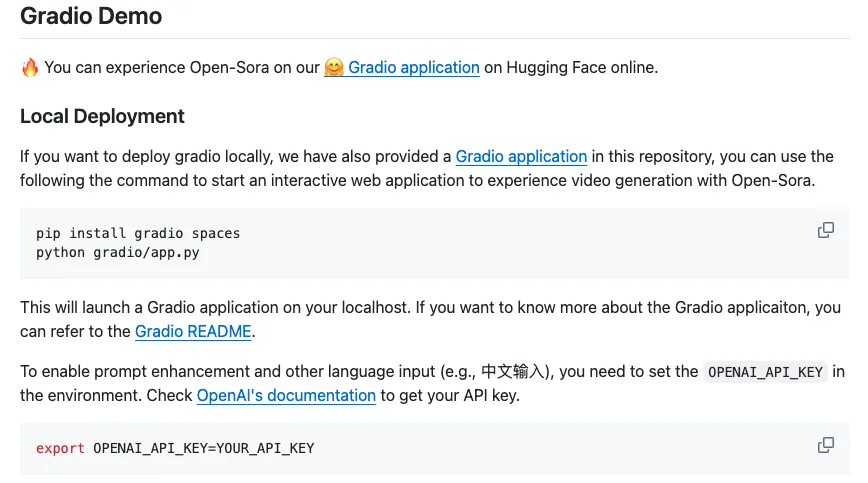
它采用图像界面,使操作更简单。在界面中,用户可以自由修改生成视频的时长、长宽比和分辨率等基础参数,同时还能自主调节生成视频的运动幅度、美学分数和更高级的镜头移动方式。它还支持调用 GPT-4 对 prompt 进行优化,因此,可以同时支持中文和英文文本输入。
在部署好该应用后,用户在使用 Open-Sora 模型时则不需要编写任何代码,只需要输入 prompt 和点击替换参数,即可尝试不同的参数组合生成视频。生成的视频也将直接展示在 Gradio 界面中,可以直接在网页端下载,无需配备复杂的路径。

图片来源:https://github.com/hpcaitech/Open-Sora/blob/main/assets/readme/gradio_basic.png
我们注意到,潞晨 Open-Sora 团队已经在 Github 中提供了将模型与 Gradio 适配的脚本,并且也提供了部署的命令行代码。然而,我们仍需要经历复杂的环境配置,才能成功运行部署代码。如果我们想完整体验 Open-Sora 的功能,尤其是生成长时间高分辨率(比如 720P 16 秒)的视频,更是需要性能好显存大的显卡(官方使用的是 H800)。Gradio 方案似乎没有提到如何解决这两个问题。
这两个问题乍看十分棘手,却能被潞晨云完美地解决,真正实现了无需技术轻松部署。如何上手?机器之心这里有一份超简单的教程。
超简单的一键部署教程
在潞晨云上部署 Open-Sora 有多简单呢?
首先,潞晨云提供多类型的显卡,其中,A800 和 H800 这样的高端显卡也可以轻松租到。经我们测试,这种 80GB 显存的卡,单卡就可以满足 Open-Sora 项目的推理需求。
其次,潞晨云为 Open-Sora 项目配备了专属镜像。这个镜像就像可以拎包入住的精装房,全套运行环境可以一键启动,省去了复杂的环境配置环节。
最后,潞晨云还有超优惠的价格和超人性化的服务。一张 A800 的卡每小时价格不到 10 元,初始化镜像的时间全部不计费,云主机随时关机停止计费。换句话说,不到 10 元 / 时,即可充分享受 Open-Sora 带来的惊喜体验!除此之外,我们还放了一个 100 元优惠券的获取方式在文末,赶紧注册账号薅上券,跟着我们的教程开整吧!

潞晨云网址:https://cloud.luchentech.com/
首先,进入网址在潞晨云上注册账号。一进入主页面,就可以直接看到算力市场的可租赁机器。领上优惠券,或者充值 10 元钱,就能跟着潞晨云的用户指南,开始建立云主机。
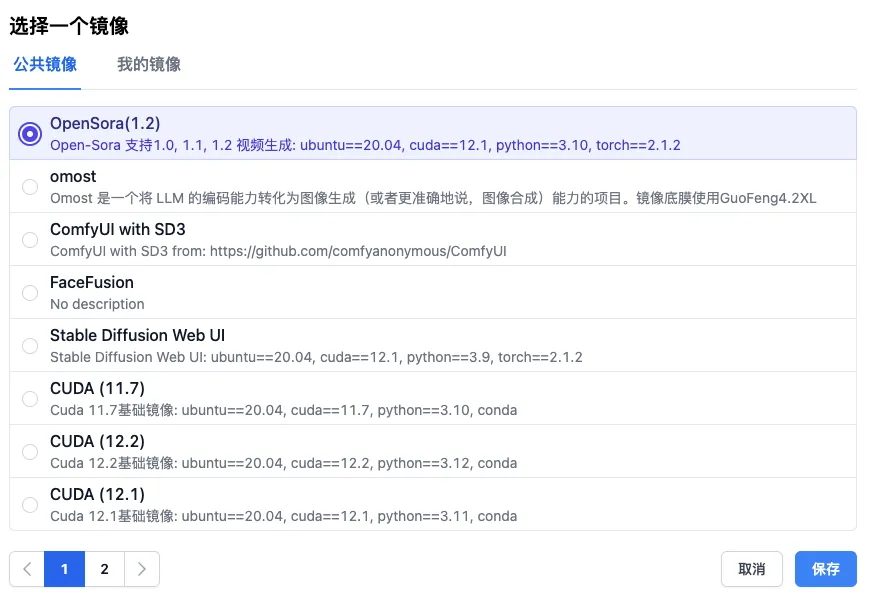
第一步是选择镜像。一打开公共镜像,点开第一个就是 OpenSora (1.2),真是方便至极。
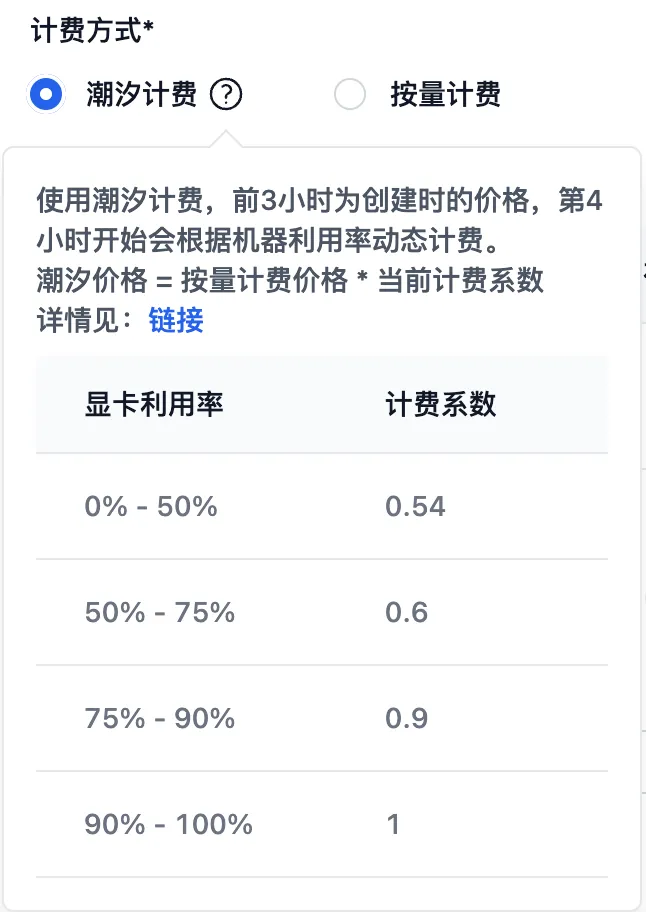
第二步是选择计费方式。计费方式有两种,潮汐计费和按量计费。我们试用后发现潮汐计费更省钱,在空闲时段 A800 的价格还能更低!
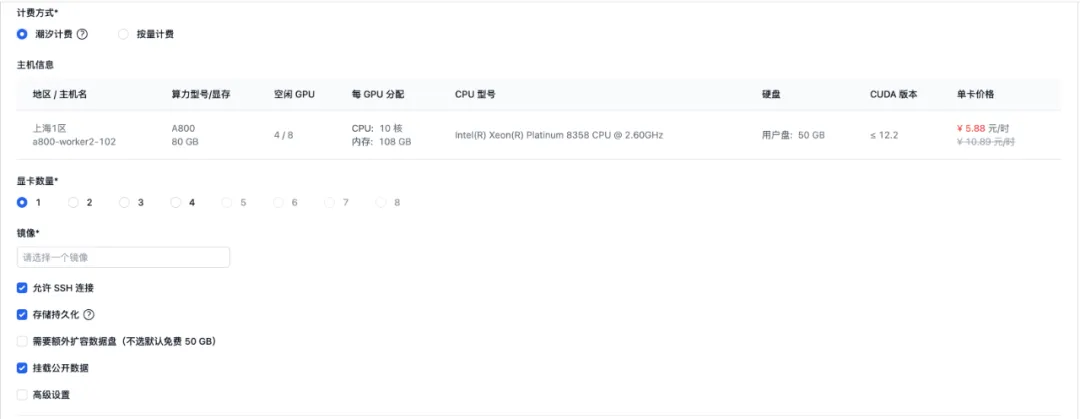
对于 Open-Sora 的推理,一张 A800 足够了,我们选择了 1 卡配置,并且允许了 SSH 连接、存储持久化,还挂载了公开数据(包括模型权重)。这些功能都不额外收费,还能提供更多便利,超级良心。
选好后点击创建,云主机启动的时间非常短,几十秒内机器就起来了。这段时间是不计费的,所以如果遇到比较大的镜像等待时间较长时也不必担心费用问题。

第三步,我们从云主机页面点击 JupyerLab, 进入网页。一进去就给我们打开了一个终端。
我们输入 ls,查看云主机的文件,可以看到 Open-Sora 这个文件夹就在初始路径处。

由于我们使用的是 Open-Sora 专属镜像,我们无需额外安装任何环境。最耗时的这一步被完美地解决了。

这时候,我们直接输入运行 Gradio 的命令,就可以快速启动 Gradio,真正实现了一键部署。
Bash
python gradio/app.py
速度非常快,只要十多秒,Gradio 就跑起来了。
不过,我们发现,这个 gradio 是默认在服务器的 http://0.0.0.0:7860 上跑,要想在自己本地的浏览器用,得先把自己的 ssh 公共秘钥加入到潞晨云的机器中。这一步也很简单,只要进入下面这个文件,粘贴本地机器的秘钥进去就行。
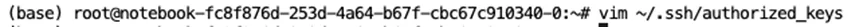
接着,我们还需要写上本地完成端口映射指令,我们可以照着这个截屏中的指令来写,大家使用的时候需要替换成自己云主机的具体地址和 port。
接着,打开对应网页,很快就出现了可视化操作界面。
我们先随意输入了一个英文提示,点击开始生成 (用了默认的 480p,速度会快一些)。
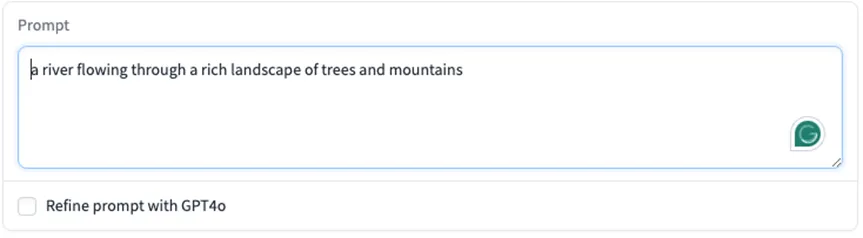
a river flowing through a rich landscape of trees and mountains (一条河流流经茂密的树木和山脉)
很快生成就完成了,耗时约 40 秒。生成结果整体还不错,有河有山有树木,和指令符合。但是我们期待的是雄鹰从高处俯瞰的效果。

没关系,调整了指令再来一次:
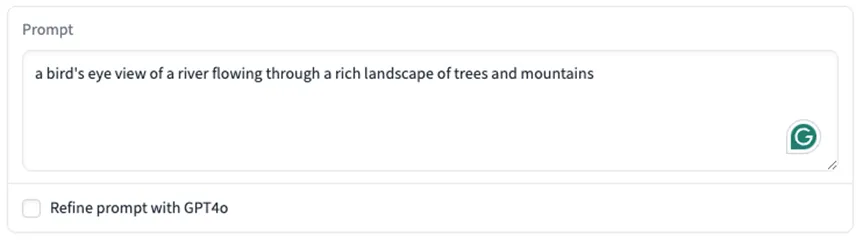
a bird's eye view of a river flowing through a rich landscape of trees and mountains (鸟瞰河流流经树木和山脉的丰富景观)
这次生成的内容果然带上了鸟瞰效果。不错,这个模型还是很听话的。

如前文所说,gradio 界面上还有很多其他选项,比如调整分辨率、画幅长宽比、视频时长,甚至还能控制视频的动态效果幅度等,可玩性非常强,我们测试时使用的是 480P 分辨率,而最高可支持 720P,大家可以逐个尝试,看看不同选项搭配的效果。
想要进阶?微调也能轻松上手
此外,继续深挖 Open-Sora 的网页,我们发现他们还提供了继续微调模型的代码指令。使用自己喜欢的类型的视频微调模型的话,就能让这个模型生成更符合我的审美要求的视频了!
让我们用潞晨云的公开数据中提供的视频数据来验证一下。
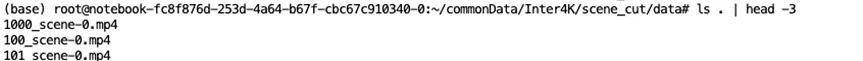
由于环境全都是配置好的,我们只需复制粘贴训练指令。
torchrun --standalone --nproc_per_node 1 scripts/train.py configs/opensora-v1-2/train/stage1.py --data-path /root/commonData/Inter4K/meta/meta_inter4k_ready.csv
这边输出了一连串模型训练的信息。

训练已经正常启动了,居然只要单卡就能训!
( 踩坑提示:在此之前我们遭遇了一次 OOM, 结果发现程序挂了以后显存依旧被占用,然后发现是忘记关闭上一步 Gradio 的推理了 ORZ,所以大家用单卡训的时候一定要记得关掉 Gradio,因为 Gradio 上面加载了模型一直在等待用户输入来进行推理)。

以下是我们训练的时候 GPU 资源占用情况:
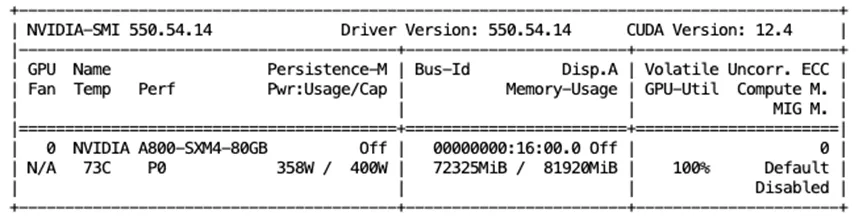
简单算一笔账,训练一步大约耗时约 20 秒,根据 Open-Sora 提供的数据,训练 70k 步(如下图所示),那他们耗时大约在 16 天左右,和他们文档中声称的 2 周左右相近(假设他们的所有机器各完成一个 step 的时间和我们这台机器相似)。

在这 70k 步中,第一阶段占 30k 步,第二阶段占 23k 步,那第三阶段其实只训练了 17k 步。而这个第三阶段,就是用高质量视频进行微调,用来大幅度提升模型质量,也就是我们现在想要做的事情。

不过,从报告中看,他们的训练使用了 12 台 8 卡机器,所以如果我们用潞晨云平台训练和第三阶段相同的数据量,大约需要:
95 小时 * 8 卡 * 12 台 * 10 元 / 小时 = 91200 元
这个数字对于测评来说还是有点门槛的,但是对于打造一个专属的文生视频大模型来说也太划算了。尤其是对于企业来说,基本不需要什么前期准备工作,按照教程一步步走,就可以用不到十万块的价格甚至更少完成一次微调。真的很期待能看到更多 Open-Sora 在专业领域的强化版!
最后,放上我们前面提到的 100 元优惠券福利活动~尽管我们本次测评成本不到 10 元,但是羊毛该薅还得薅!
从潞晨云官方资料看到,用户在社交媒体和专业论坛(如知乎、小红书、微博、CSDN 等)上分享使用体验(带 #潞晨云或 @潞晨科技),有效分享一次可得 100 元代金券(有效期一周),换算成我们测评时生成的这种视频,相当于五六百个~

最后,我们整理了相关的资源链接放在下面,方便大家快速上手。想要立刻尝试的小伙伴们,点击阅读原文即可一键传送,开启你的 AI 视频旅程!
文章来源于“机器之心”




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
